La Suite Elastic 7.0.0 est arrivée
La version 7.0 est arrivée. Cette version représente plus de 10 000 requêtes d'extraction de 861 committers. Nous vous remercions donc, vous : nos employés et notre communauté.
Envie d'en savoir plus sur cette version et de rencontrer celles et ceux qui l'ont créée ? Nous organisons un événement de lancement virtuel en direct le 25 avril 2019 à 8 h (heure avancée du Pacifique). Joignez-vous à nous pour des démonstrations de la version 7.0, un stand “Ask Me Anything” (AMA) avec des ingénieurs Elastic du monde entier, et bien plus encore.
La Suite Elastic 7.0 est disponible immédiatement au téléchargement, ou vous pouvez effectuer des déploiements complètement gérés dans Elasticsearch Service dans Elastic Cloud — la seule solution hébergée à offrir les nouvelles versions de la Suite Elastic dès le jour de leur lancement.
La version 7.0 est tellement pleine de surprises… Par où commencer ?
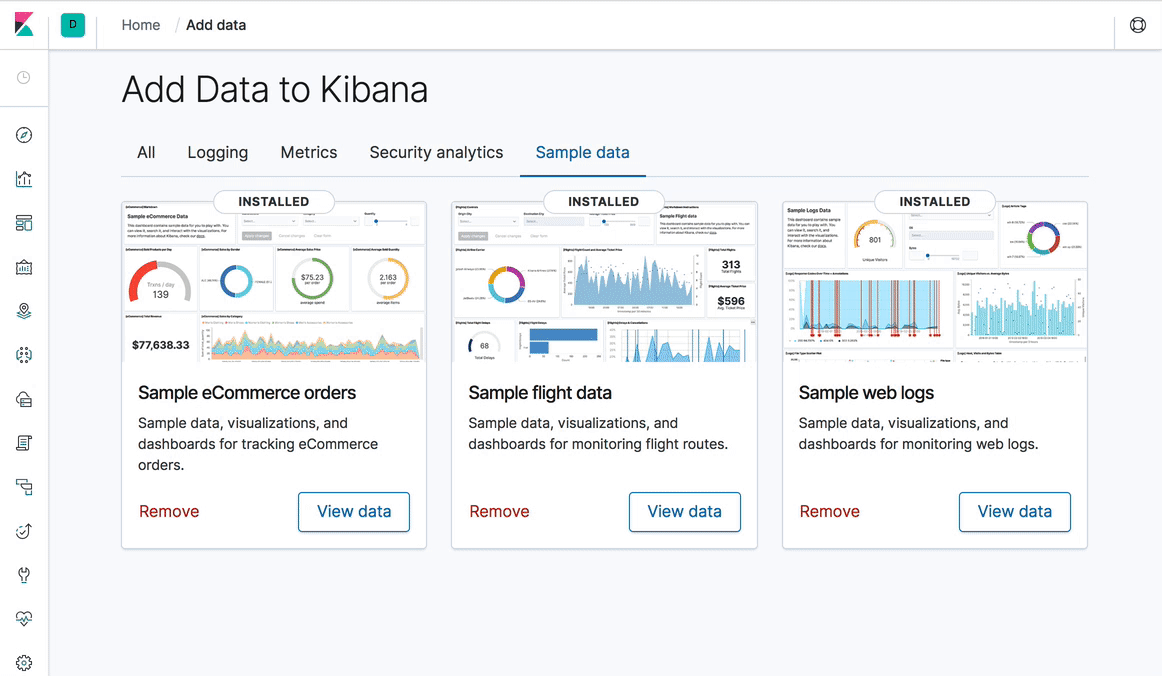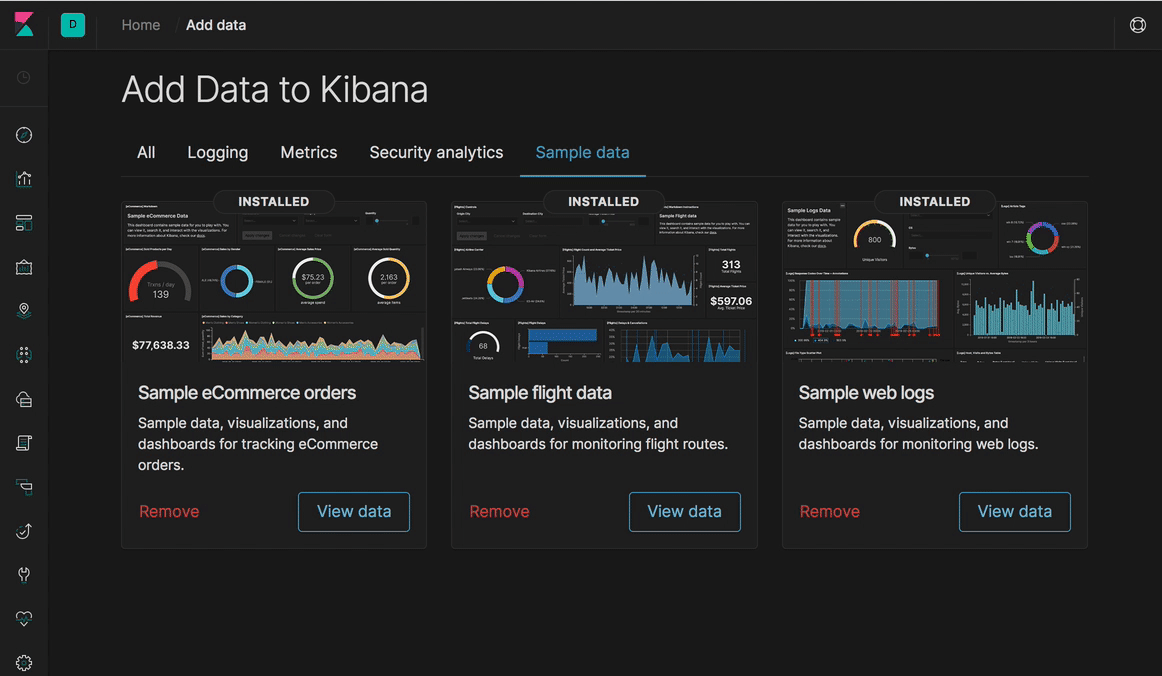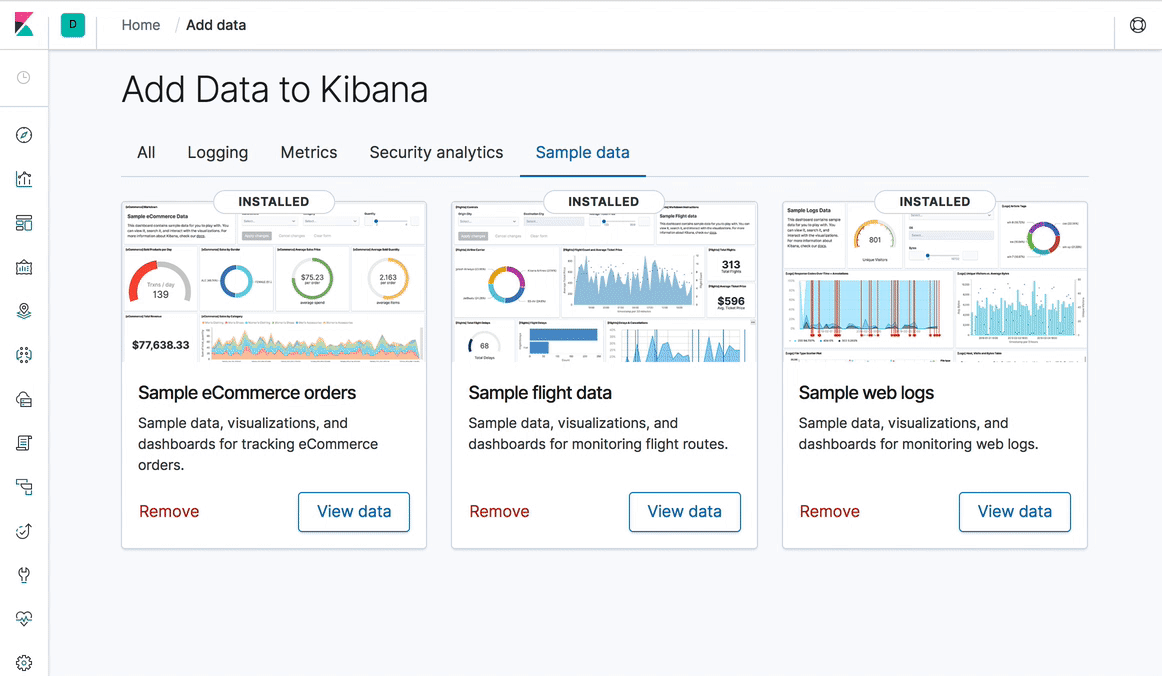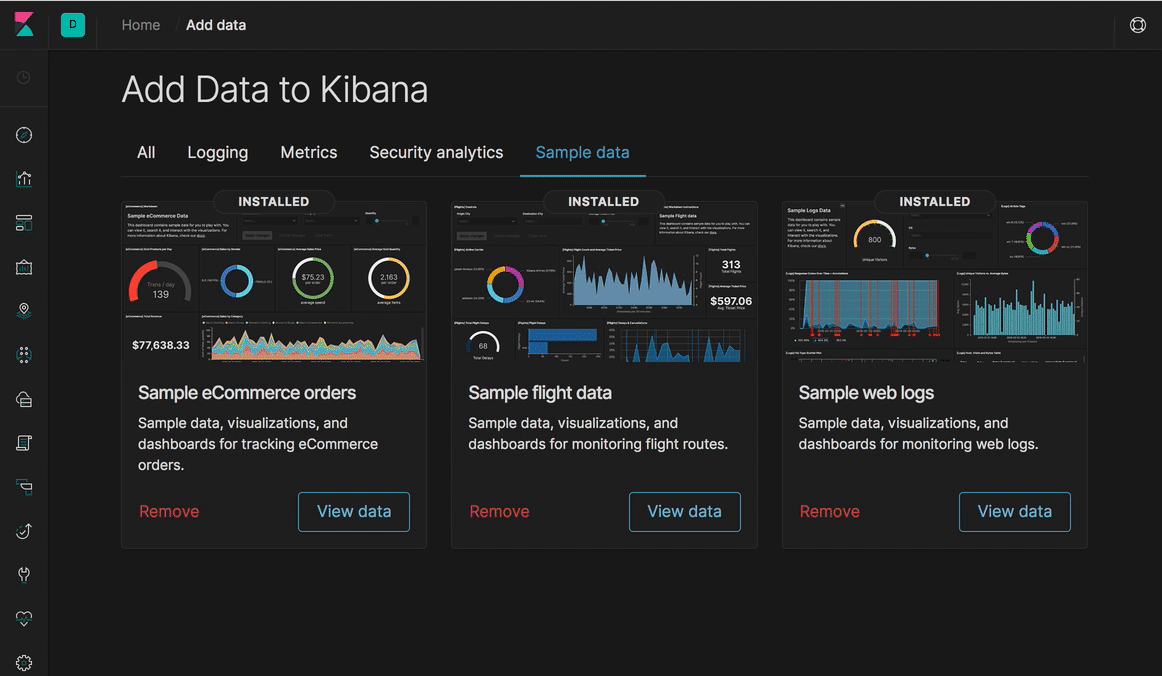
Kibana 7.0 : nouveau design, nouvelle navigation… et mode sombre !
Lors du design de Kibana 7.0, nous avons pris la décision de nous concentrer sur le contenu. Vous remarquerez donc que toute l'interface utilisateur est plus claire et plus épurée. Le changement le plus important est une transition vers une nouvelle navigation globale, qui introduit un en-tête constant pour changer les espaces Kibana, afficher les fils d'Ariane et initier les actions de l'utilisateur (par exemple, changer le mot de passe ou se déconnecter). Pour y parvenir, ainsi que pour améliorer la cohérence, nous avons créé Elastic UI Framework. Au cours de l'année dernière, nous avons transformé la quasi-totalité de Kibana afin d'utiliser ces composants. Nous avons également procédé à d'importantes simplifications à l'application des styles et des feuilles de style grâce à ces composants et aux efforts herculéens déployés par nos équipes de design et d'ingénierie.
Cette meilleure cohérence ainsi que les améliorations apportées à la feuille de style nous ont permis de rayer de notre liste l'une des fonctionnalités les plus demandées dans l'histoire de Kibana : un mode sombre dans tout Kibana. Parmi les autres avantages qu'offrent ces changements, les tableaux de bord Kibana présentent maintenant un design adapté. Il s'agit là d'une première étape permettant d'aboutir à une amélioration drastique de l'ergonomie sur les appareils mobiles.
Une nouvelle ère pour la coordination de cluster dans Elasticsearch
Dès le départ, notre objectif était de rendre Elasticsearch facile à scaler et résistant aux défaillances catastrophiques. Nous avons adopté plusieurs approches afin d'intégrer ces exigences. Nous avons notamment rendu nos nœuds individuels plus scalables et fiables et apporté une amélioration continue à notre couche de coordination de cluster, désignée sous le nom de Zen Discovery. Avec la version 7.0, nous apportons encore de grandes améliorations dans les deux domaines.
Au chapitre des nouveautés, citons une nouvelle couche de coordination de cluster complètement repensée pour Elasticsearch : elle gagne ainsi en rapidité, en sécurité et en facilité d'utilisation. Pour y parvenir, nous avons mis l'accent sur l'exactitude théorique de notre nouvel algorithme de consensus distribué, grâce à des modèles formels qui nous ont permis de valider la conception. Bien qu'il existe de célèbres algorithmes de consensus, tels que Paxos, Raft, Zab et Viewstamped Replication (VR), les exigences en matière de cluster Elasticsearch requièrent des changements de cluster plus rapides, un support technique pour faire grandir ou rétrécir facilement un cluster, et une stratégie de mise à niveau propagée pour permettre aux clusters 6.7 d'effectuer une mise à niveau propagée vers la version 7.0, des fonctionnalités que ces algorithmes de référence ne pouvaient pas fournir. Cette nouvelle couche de coordination de cluster intègre aussi un certain nombre de modifications visant à limiter les risques d'erreur humaine. Ces améliorations simplifient aussi la prise de décision et la reprise en cas de défaillance irrémédiable. Il n'est pas aisé d'améliorer en même temps la fiabilité, les performances et l'expérience utilisateur, notamment dans un composant aussi centralisé. Nous devons avouer que nous sommes plutôt fiers de notre nouvelle couche de coordination de cluster et de tout ce que nous avons entrepris pour y parvenir. Pour en savoir plus sur le sujet, consultez cet article de blog.
Les nœuds individuels dans Elasticsearch ont été conçus en tenant compte de la résilience. Le nœud rejette les requêtes si elles sont trop nombreuses ou trop volumineuses. Nous y parvenons grâce à des disjoncteurs dans Elasticsearch. Ils déterminent que le nœud ne sera pas capable de gérer une requête donnée et réagissent immédiatement en demandant au client de réessayer, éventuellement sur un autre nœud. C'est encore plus important pour les nœuds dont la taille du tas JVM est inférieure, qui deviennent plus fréquents dans la mesure où les utilisateurs passent à un modèle de cluster par entité à la place d'un cluster massif à plusieurs entités. Dans la version 7.0, nous introduisons le disjoncteur à mémoire réelle, qui permet de détecter bien plus efficacement les requêtes qui ne peuvent pas être traitées et d'éviter l'instabilité des nœuds individuels. Pour découvrir comment cette nouveauté renforce la fiabilité globale des nœuds et des clusters, n'hésitez pas à consulter cet article de blog.
Boostez la pertinence et la rapidité dans tous les cas d'utilisation
La pertinence et la rapidité sont le fondement même d'une expérience de recherche satisfaisante. Dans ce contexte, Elasticsearch 7.0 introduit plusieurs fonctionnalités essentielles pour les améliorer.
- Les principales requêtes k sont plus rapides : Dans de nombreux cas d'utilisation de recherche, il est bien plus important pour l'utilisateur de voir les meilleurs résultats k (disons, 20) que le total de résultats exacts (c'est-à-dire le nombre total de résultats qui correspondent à la requête). Par exemple, si quelqu'un recherche un produit sur un site web d'e-commerce, il est beaucoup plus intéressé par les 10 résultats les plus pertinents que par les autres 120 897 résultats qui correspondent à sa requête de recherche. Elasticsearch 7.0 (et Lucene 8.0) implémentent un nouvel algorithme. Son nom ? Block-Max WAND. Un incroyable coup d'accélérateur pour l'extraction des meilleurs résultats.
- Requêtes à intervalles : certains cas d'utilisation de recherche, par exemple, les recherches juridiques et de brevets, nécessitent de rechercher des enregistrements dans lesquels des mots ou expressions se trouvent à une certaine distance les uns des autres. Les requêtes à intervalles dans Elasticsearch 7.0 introduisent une toute nouvelle manière de structurer ces requêtes. De plus, elles sont bien plus faciles à utiliser et à définir par rapport à la méthode précédente (requêtes étendues). Les requêtes à intervalles sont également plus souples que les requêtes étendues pour rapprocher les cas.
- Function Score 2.0 : l'attribution de scores personnalisée est le gagne-pain des cas d'utilisation de recherche avancés, pour lesquels l'utilisateur souhaite un contrôle plus précis sur la pertinence et le classement des résultats. Depuis ses premiers jours, Elasticsearch offre la capacité de le faire. La version 7.0 introduit la nouvelle génération de capacité Function Score qui fournit une manière plus simple, plus modulaire et plus flexible de générer un score de classement par enregistrement. La nouvelle structure modulaire permet aux utilisateurs de combiner un ensemble de fonctions arithmétiques et de distance afin d'élaborer des calculs Function Score arbitraires, ce qui leur offre plus de contrôle sur la manière dont les résultats sont notés et classés.
Zoomez en toute fluidité dans Elastic Maps grâce à la grille géographique en mosaïque
Au fil des ans, nous n'avons cessé d'améliorer la prise en charge des données géographiques : depuis le tout premier lancement des données géographique dans Elasticsearch jusqu'à l'arrivée de la structure de données basée sur l'arborescence BKD dans Lucene et ses requêtes de formes géométriques 25 plus performantes, en passant par Elastic Maps Service, qui alimente le fond de carte mondial intégré à Kibana.
Avec la version 7.0, nous poursuivons cet investissement en introduisant une nouvelle agrégation dans Elasticsearch afin de gérer les cartes (géographiques) en mosaïque de manière à ce que l'utilisateur puisse zoomer et dézoomer la carte sans modifier la forme des données résultantes. La nouvelle agrégation de grille géographique en mosaïque regroupe les points géographiques en ensembles qui représentent les cellules dans une grille, chaque cellule correspondant à une tuile dans une carte. Avant ce changement, les marges de la forme pouvaient se modifier légèrement en raison du changement du niveau de zoom, car les tuiles rectangulaires changeaient l'orientation à des niveaux de zoom différents. Elastic Maps dans la version 7.0 utilise déjà cette nouvelle agrégation pour garantir la stabilité de l'affichage, que vous zoomiez ou dézoomiez. Qu'il s'agisse de protéger votre réseau contre les attaques, de comprendre le ralentissement des temps de réponse d'une application dans certaines zones géographiques ou de garder un œil sur la progression de votre frère sur l'un des plus longs sentiers de grande randonnée du monde, un tel niveau de précision est essentiel.
Renforcez les cas d'utilisation temporels avec un support technique d'une précision de l'ordre de la nanoseconde
Qu'il s'agisse d'indicateurs d'infrastructure, de logs d'audit de système, du trafic réseau, ou d'un Rover sur Mars, les données temporelles sont au cœur de la manière dont de nombreuses personnes utilisent la Suite Elastic. La clé réside dans la capacité à ordonner et à corréler les événements avec précision dans plusieurs systèmes et services.
Jusqu'à présent, Elasticsearch stockait uniquement des horodateurs avec une précision d'une milliseconde. La version 7.0 ajoute quelques zéros et apporte une précision de l'ordre de la nanoseconde, ce qui offre aux utilisateurs qui ont besoin de collecter des données à haute fréquence la précision requise pour stocker et classer les données avec précision. Le changement a été rendu possible en migrant depuis la bibliothèque JODA historique vers l'API de gestion du temps JAVA dans JDK 8.