Détection des modèles anormaux grâce aux relations des processus parent-enfant
Les méthodes de détection des malwares fondées sur le Machine Learning et les antivirus sont devenues tellement efficaces pour identifier les attaques sur fichiers que les utilisateurs malveillants se sont tournés vers des techniques appelées « living off the land » afin de contourner les logiciels de sécurité modernes. Ces attaques profitent de l’exécution d’outils système qui sont préinstallés sur le système d'exploitation ou souvent proposés par des administrateurs en vue de réaliser certaines opérations, comme l’automatisation des tâches administratives, l’utilisation régulière de scripts et l’exécution de code sur des systèmes distants. Il peut être difficile d’identifier les utilisateurs malveillants qui utilisent des outils de système d’exploitation de confiance, comme powershell.exe, wmic.exe ou schtasks.exe. Ces fichiers binaires sont par essence sans risque et souvent utilisés dans la plupart des environnements. Par conséquent, les utilisateurs malveillants peuvent contourner facilement la plupart des défenses de première ligne en se fondant dans le décor des exécutions régulières. Pour identifier des modèles à l’instar de telles actions découlant d’une infraction, il faut passer au peigne fin des millions d’événements sans vraiment savoir par où commencer.
Afin de lutter contre cette tendance, les chercheurs en sécurité ont commencé à concevoir des systèmes de détection capables de cibler les chaînes de processus parent-enfant suspicieux. En utilisant MITRE ATT&CK™ comme stratégie de lutte, les chercheurs peuvent écrire des logiques de détection pouvant générer des alertes lorsqu’un processus parent lance un processus enfant à l’aide de certains arguments de ligne de commande. Un bon exemple est l’alerting sur un powershell.exe généré par un processus de MS Office avec des arguments encodés en Base64. Or, ce processus chronophage requiert une expertise en domaines et une boucle de rétroaction explicite afin de régler les détecteurs bruyants.
Les équipes en charge de la sécurité utilisent des infrastructures open source d’attaque et de défense pour réaliser des simulations et évaluer les performances des détecteurs. Or, indépendamment de leur efficacité, leur logique peut résoudre une seule attaque. Toute incapacité des détecteurs à généraliser ou détecter des attaques représente une opportunité unique pour le Machine Learning.
Réflexions sous forme de graphes
Dès les premières discussions autour de la détection des processus parent-enfant anormaux, j’ai immédiatement pensé à représenter ces réflexions sous forme de graphe. En effet, l’exécution des processus peut être illustrée grâce à un graphe pour un hôte donné. Dans notre graphe, les nœuds constituent des processus individuels divisés selon leur identifiant unique (PID), tandis que chaque liaison entre les nœuds est un événement process_creation. Une liaison comprend des métadonnées importantes provenant d’événements différents, comme les horodatages, des arguments de ligne de commande et de l’utilisateur.
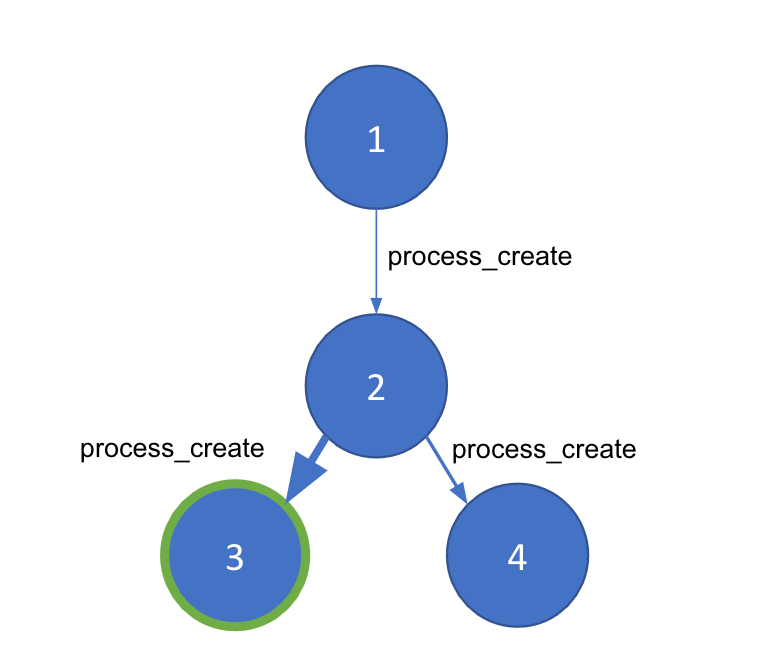
Nous disposons désormais d’une représentation graphique des événements des processus d’une machine hôte. Cependant, les attaques de type « living off the land » peuvent générer le même type de processus système que ceux habituellement exécutés. Nous avons donc besoin d’une méthode permettant de distinguer les bons processus des mauvais dans tout graphe. La technique de la détection communautaire segmente un grand graphe en plus petites « communautés » en fonction de la densité des liaisons entre nos nœuds. Pour l’utiliser, nous devons pouvoir générer une pondération entre les nœuds afin de garantir l’efficacité de la détection communautaire et sa capacité à identifier la ou les parties anormales de notre graphe. Nous optons pour le Machine Learning en vue d’atteindre cet objectif.
Machine Learning
Pour générer notre modèle de pondération des liaisons, nous utiliserons un apprentissage supervisé, à savoir une approche de Machine Learning selon laquelle le modèle est alimenté à l’aide de données étiquetées. Heureusement, nous pouvons utiliser les infrastructures open source d’attaque et de défense que nous avons mentionnées plus haut afin de générer des données d’apprentissage. Voici quelques infrastructures open source d’attaque et de défense utilisées dans nos corpus d’apprentissage.
Infrastructures d’attaque
- Atomic Red Team (Red Canary)
- Red Team Automation (Endgame/Elastic)
- Caldera Adversary Emulation (MITRE)
- Metta (Uber)
Infrastructures de défense
- Atomic Blue (Endgame/Elastic)
- Cyber Analytics Repository (MITRE)
- MSFT ATP Queries (Microsoft)
Ingestion de données et normalisation

Après avoir ingéré certaines données d’événement, nous devons les transformer en représentation numérique (voir l’illustration 2). Grâce à cette dernière, le modèle apprend à élargir les détails d’une relation entre processus parent-enfant dans le cadre d’une attaque, ce qui permet d’écarter les simples signatures d’apprentissage.
Tout d’abord, nous réalisons l’ingénierie des fonctionnalités (voir l’illustration 3) pour les noms des processus et les arguments de ligne de commande. La vectorisation TF-IDF mettra en avant l’importance sur le plan statistique d’un mot spécifique pour un événement dans un ensemble de données. La conversion des horodatages en valeurs entières nous permet de déterminer le delta entre l’heure de début du processus parent et le lancement du processus enfant. D’autres fonctionnalités sont binaires par nature (par ex., 1 ou 0 ou bien oui ou non). Voici quelques exemples de ce type de fonctionnalités :
- Le processus est-il signé ?
- Faisons-nous confiance à la personne signataire ?
- Le processus est-il irréprochable ?

Une fois notre ensemble de données transformé, nous l’utilisons pour l’apprentissage d’un modèle supervisé (voir l’illustration 4). Ce modèle permet de fournir un « score anormal » pour un événement de création de processus donné, à savoir 0 (sans risque) ou 1 (anormal). Nous pouvons utiliser ce score anormal comme pondération de liaison dans notre graphe.
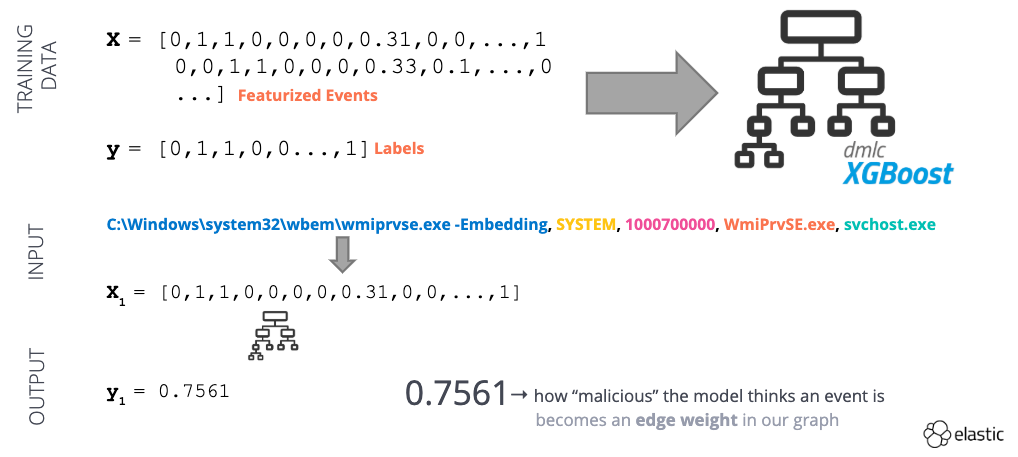
Illustration 4 : exemple de workflow de Machine Learning supervisé
Service de prévalence


Illustration 5 : probabilités conditionnelles utilisées par le moteur de prévalence
Désormais, nous disposons d’un graphe pondéré grâce à notre modèle de Machine Learning. Notre objectif est atteint, non ? Le modèle que nous avons développé est capable de prendre des décisions concernant une chaîne donnée de processus parent-enfant selon notre compréhension globale des bonnes et mauvaises décisions. Or, l’environnement de chaque client est unique. Nous allons rencontrer des processus inconnus ou des administrateurs système qui utilisent PowerShell pour toutes leurs tâches.
En résumé, si nous utilisons uniquement ce modèle, nous risquons de nous retrouver avec une montagne de faux positifs, ce qui augmentera la quantité de données qu’un analyste devra traiter. Pour éviter ce problème éventuel, nous avons conçu un service de prévalence capable d’identifier le caractère courant d’une chaîne de processus parent-enfant donnée dans l’environnement concerné. En outre, nous tenons compte des nuances locales afin d’exploiter de manière plus confiante les événements suspicieux ou de les supprimer et d’isoler les chaînes de processus véritablement anormales.
Le service de prévalence (voir l’illustration 5) se fonde sur deux statistiques dérivées d’une probabilité conditionnelle qui nous permet de faire les affirmations suivantes : « à partir de ce processus parent, ce processus enfant représente plus de X % d’autres processus enfant » ET « à partir de ce processus, cette ligne de commande représente plus de X % d’autres lignes de commande associées à ce processus ». Une fois le service de prévalence en place, nous pouvons apporter la touche finale à notre logique de détection principale appelée find_bad_communities.
Identification des « mauvaises » communautés

Illustration 6 : code Python pour la détection de communautés anormales
L’illustration 6 ci-dessus représente le code Python utilisé pour générer les mauvaises communautés. La logique pour find_bad_communities est très simple :
- Nous classons chaque événement process_create pour une machine hôte afin de générer une paire de nœuds (par ex., un nœud parent avec un nœud enfant) et une pondération associée (comme la sortie de notre modèle).
- Nous élaborons un graphe dirigé.
- Nous effectuons une détection communautaire afin de générer une liste de communautés dans le graphe.
- Dans chaque communauté, nous déterminons la prévalence d’une paire parent-enfant (par ex., chaque connexion). Nous tenons compte du caractère courant d’un événement parent-enfant dans le score anormal (anomalous_score) final.
- Si le score anormal atteint ou dépasse un seuil donné, nous mettons de côté toute la communauté afin que notre analyste l’étudie.
- Une fois chaque communauté analysée, nous obtenons une liste des « mauvaises » communautés triées selon le score anormal maximum.
Résultats
Nous avons utilisé des données sans risque et malveillantes provenant de cas réels et de simulations pour l’apprentissage de notre modèle final. Les données sans risques étaient tirées d’événements de processus Windows recueillis pendant 3 jours sur notre réseau interne. Elles provenaient d’un mélange de serveurs et de postes de travail d’utilisateurs afin de reproduire l’environnement d’une petite entreprise. Nous avons généré des données malveillantes en lançant des attaques à l’aide de toutes les techniques ATT&CK disponibles dans le cadre de l’infrastructure RTA d’Endgame. Nous avons aussi lancé des malwares dans des macros et des fichiers binaires provenant d’utilisateurs malveillants comme FIN7 et Emotet.
Pour notre test principal, nous avons décidé d’utiliser les données d’événements comme l’évaluation MITRE ATT&CK Evaluation fournie par le projet Mordor de Roberto Rodriguez. L’évaluation ATT&CK Evaluation visait à reproduire l’activité d’APT3 à l’aide d’outils FOSS/COTS comme PSEmpire et CobaltStrike. Ces derniers autorisent les techniques « living off the land » à s’exécuter en chaîne afin de réaliser des tâches « Execution », « Persistence » ou « Defense Evasion ».
L’infrastructure a pu identifier plusieurs chaînes d’attaque reposant sur diverses techniques en utilisant uniquement des événements de création de processus. Nous avons identifié et mis en avant les techniques de découverte (voir l’illustration 7) et de mouvement latéral (voir l’illustration 8) à des fins d’analyse.

Illustration 7 : chaîne de processus exécutant des techniques de découverte

Illustration 8 : chaîne de processus exécutant un événement de mouvement latéral
Diminution des données
Notre approche nous permet non seulement d’identifier les chaînes de processus anormales mais aussi de prouver l’efficacité du moteur de prévalence pour supprimer les faux positifs. En outre, nous avons pu réduire de manière significative le nombre de données d’événements qu’un analyste doit traiter. Plus précisément :
- Nous avons traité environ 10 000 événements de création de processus par point de terminaison dans le cadre du scénario APT3, soit 5 points de terminaison au total.
- Nous avons identifié 6 communautés anormales par point de terminaison.
- Chaque communauté comprenait environ 6 à 8 événements.
Prochaines étapes
Nous sommes en train de transformer cette démonstration de faisabilité en solution intégrée afin de la proposer comme une fonctionnalité d’Elastic Security. La fonctionnalité la plus prometteuse est le moteur de prévalence. Nombre de moteurs sont capables de repérer la fréquence d’occurrence des fichiers. Cependant, la description de la prévalence des relations entre les événements confèrera aux professionnels de la sécurité une méthode inédite pour détecter les menaces en recherchant les événements rares et courants au sein de leur entreprise mais aussi ceux renforcés par des mesures d’événements globalement rares.
Conclusion
L’an dernier, nous avons présenté cette infrastructure fondée sur des graphes (appelée ProblemChild) sur VirusBulletin et CAMLIS afin de ne plus avoir besoin d’un expert en domaines pour concevoir des détecteurs. En utilisant un système de Machine Learning supervisé pour transformer un graphe pondéré, nous avons prouvé notre capacité à identifier des communautés d’événements apparemment distincts dans des séquences d’attaque plus vastes. Notre infrastructure applique une probabilité conditionnelle pour classer automatiquement les communautés anormales et supprimer les chaînes de processus parent-enfant courantes. Les analystes peuvent l’utiliser pour atteindre ce double objectif. Ainsi, ils facilitent la création de détecteurs ou leur réglage et diminuent le nombre de faux positifs au fil du temps.