Réplication inter-data center avec la réplication inter-clusters Elasticsearch
Cela fait longtemps que la réplication inter-data center est une exigence des applications critiques d'Elasticsearch. Auparavant, Elasticsearch recourait à des technologies supplémentaires pour répondre à cette exigence. Grâce à l'introduction de la réplication inter-clusters d'Elasticsearch, 6.7 vous n'avez pas besoin de technologies supplémentaires pour répliquer des données dans plusieurs data centers, régions ou clusters Elasticsearch.
La réplication inter-clusters (CCR) permet de répliquer des index spécifiques à partir d'un cluster Elasticsearch vers un ou plusieurs clusters Elasticsearch. Outre la réplication inter-data center, il existe divers cas d'utilisation supplémentaires dans le cadre de la CCR, dont la localisation des données (réplication des données pour se rapprocher de l'utilisateur / serveur d'application, par exemple en répliquant un catalogue de produits vers 20 data centers dans le monde entier) ou la réplication des données à partir d'un cluster Elasticsearch vers un cluster de reporting centralisé (par ex., 1 000 succursales bancaires dans le monde écrivant à leur cluster Elasticsearch local et la réplication vers un cluster dans HQ à des fins de reporting).
Dans ce tutoriel concernant la réplication inter-data center avec la CCR, nous aborderons brièvement les bases de la CCR, nous décrirons les options d'architecture et les compromis, nous configurerons un exemple de déploiement inter-data center et nous présenterons les commandes d'administration. Pour une présentation technique de la CCR, consultez Suivez le meneur : une introduction à la réplication inter-clusters dans Elasticsearch.
La CCR est une fonctionnalité de niveau Platinum et est disponible via une licence d'essai de 30 jours pouvant être activée via l'API Essayer ou directement à partir de Kibana.
Principes de la réplication inter-clusters (CCR)
La réplication est configurée au niveau de l'index (ou est basée sur un modèle d'indexation)
La CCR est configurée au niveau de l'index dans Elasticsearch. En configurant la réplication au niveau de l'index, un grand nombre de stratégies de réplication sont disponibles, dont la réplication de certains index dans une direction, d'autres index dans une autre direction, et les architectures inter-data center granulaires.
Les index répliqués sont en lecture seule
Un index peut être répliqué par un ou plusieurs clusters Elasticsearch. Chaque cluster répliquant l'index assure la maintenance d'une copie de l'index en lecture seule. L'index actif capable d'accepter des écritures est qualifié d'index meneur. Les copies passives en lecture seule de cet index sont appelées index suiveurs. Il n'y a pas de concept d'élection d'un nouvel index meneur : lorsqu'un index meneur n'est pas disponible (par exemple, en raison d'une panne du cluster/data center), un autre index doit être choisi explicitement pour les écritures par l'application ou l'administrateur du cluster (très probablement dans un autre cluster).
Les paramètres par défaut de la CCR ont été choisis pour un large éventail de cas d'utilisation à haute vitesse
Il n'est pas recommandé de modifier les valeurs par défaut sans savoir avec certitude comment le réglage d'une valeur affecte le système. La plupart des options peuvent être trouvées dans l'API Créer un index suiveur, par exemple"max_read_request_operation_count" ou "max_retry_delay". Nous publierons prochainement un article sur le réglage de ces paramètres afin de bénéficier de charges de travail uniques.
Exigences en matière de sécurité
Comme souligné dans le Guide de prise en main de la CCR, l'utilisateur sur le cluster source doit le privilège de cluster “read_ccr”, ainsi que les privilèges d'index “monitor” et “read”. Dans le cluster cible, l'utilisateur doit avoir le privilège de cluster “manage_ccr” et les privilèges d'index “monitor”, “read”, “write”, et “manage_follow_index”. Des systèmes d'authentification centralisés peuvent également être utilisés, par exemple LDAP.
Exemples d'architectures CCR inter-data center
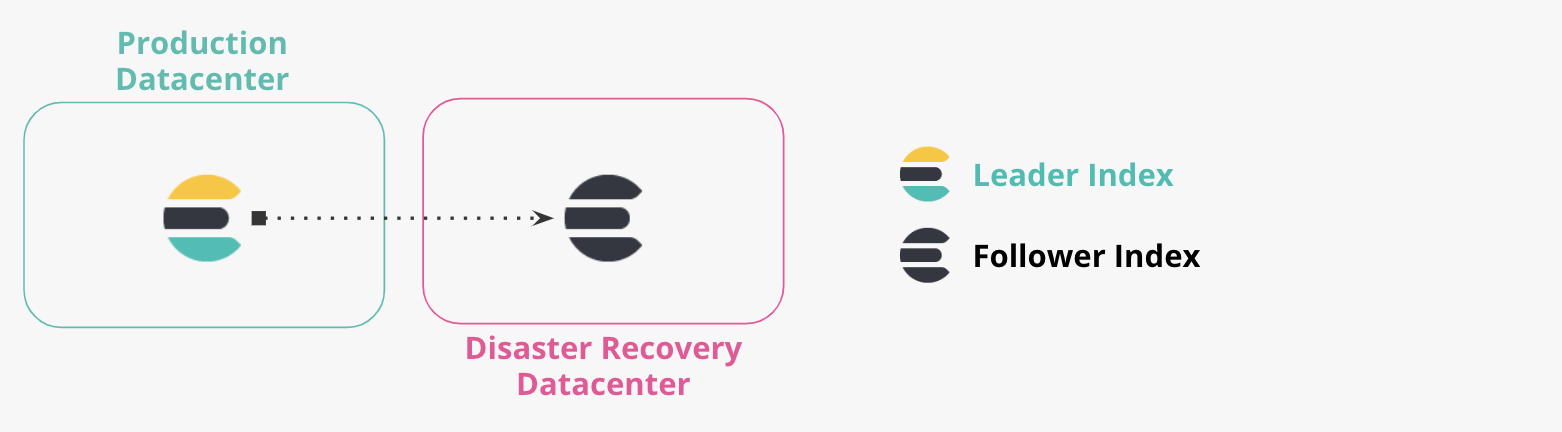
Data centers de production et de reprise d'activité après sinistre
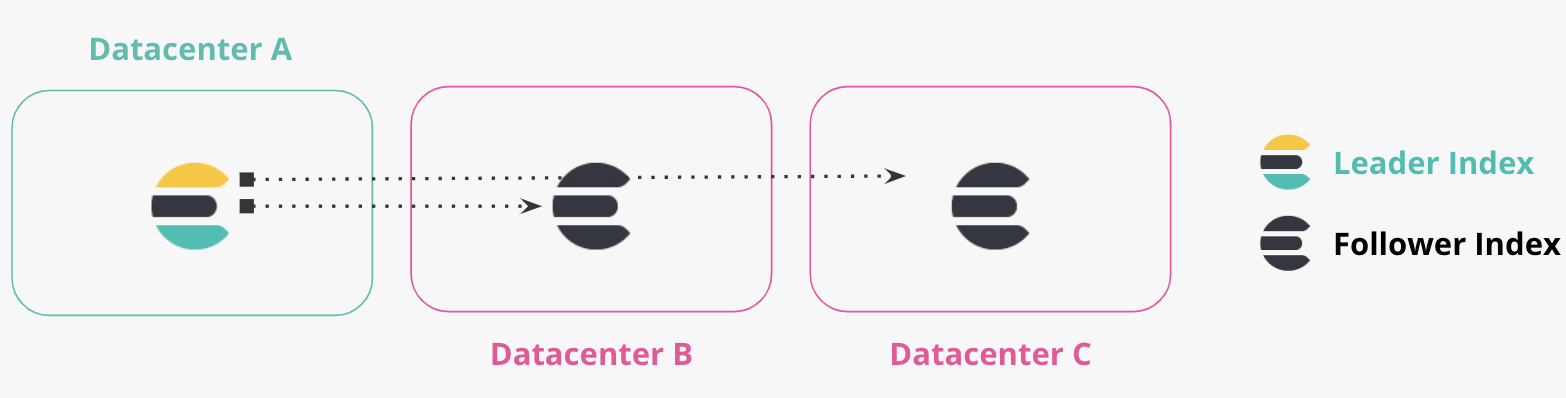
Plus de deux data centers
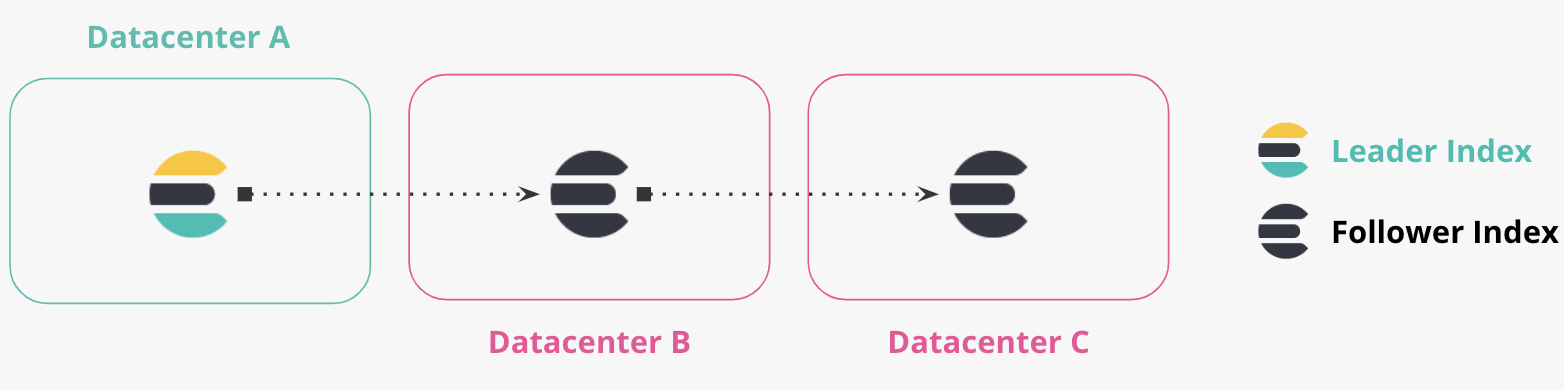
Réplication enchaînée
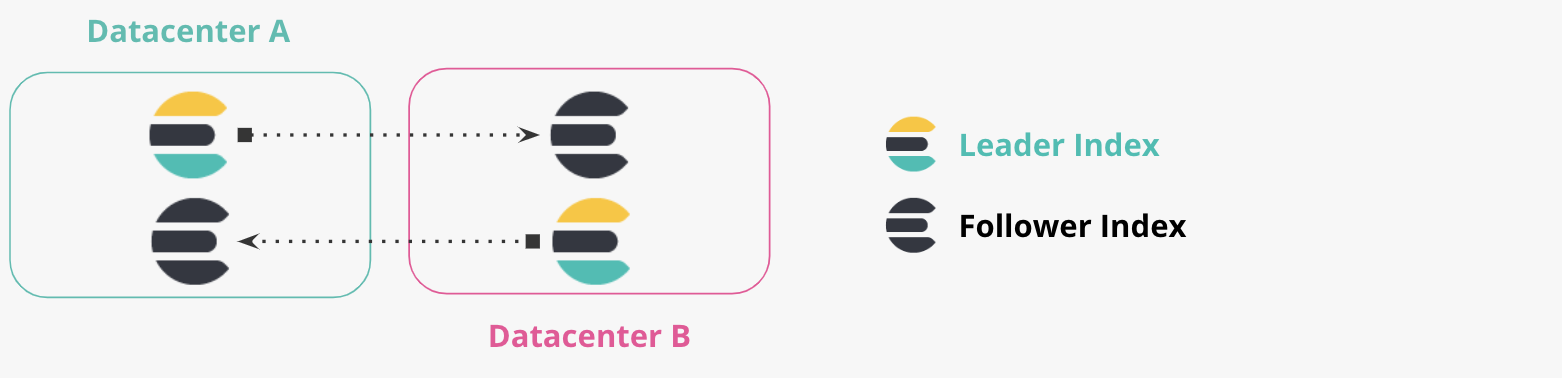
Réplication bidirectionnelle
Tutoriel sur le déploiement inter-data center
1. Configuration
Dans ce tutoriel, nous utiliserons deux clusters qui seront sur notre ordinateur local. N'hésitez pas à placer les clusters où vous le souhaitez.
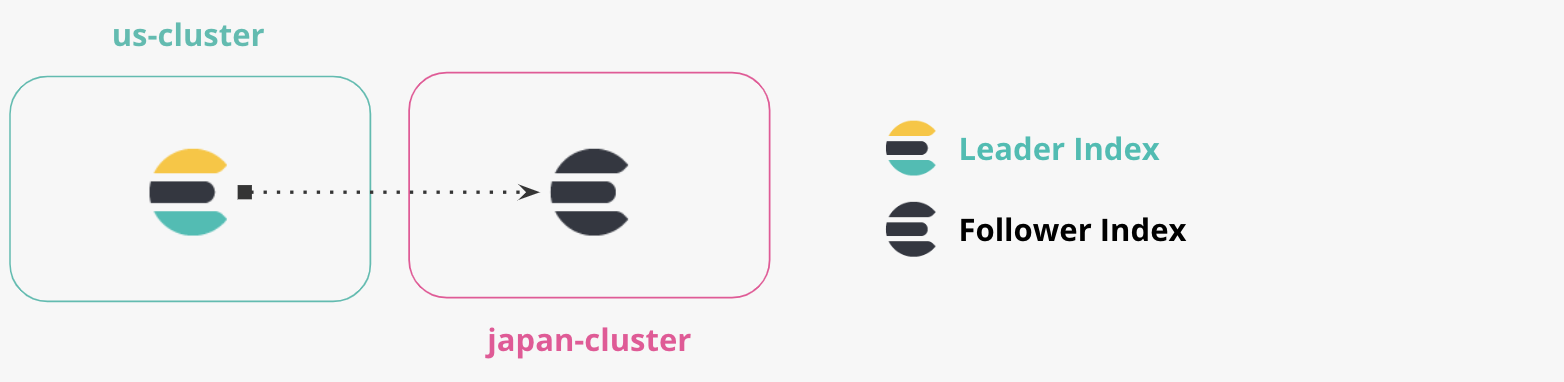
- "us-cluster" : il s'agit de notre "cluster US" et nous l'exécuterons localement sur le port 9200. Nous répliquerons les documents à partir du cluster US vers le cluster Japon.
- "japan-cluster" : il s'agit de notre "cluster Japon". Nous l'exécuterons localement sur le port 8200. Le cluster Japon assurera la maintenance d'un index répliqué à partir du cluster US.
2. Définition des clusters distants
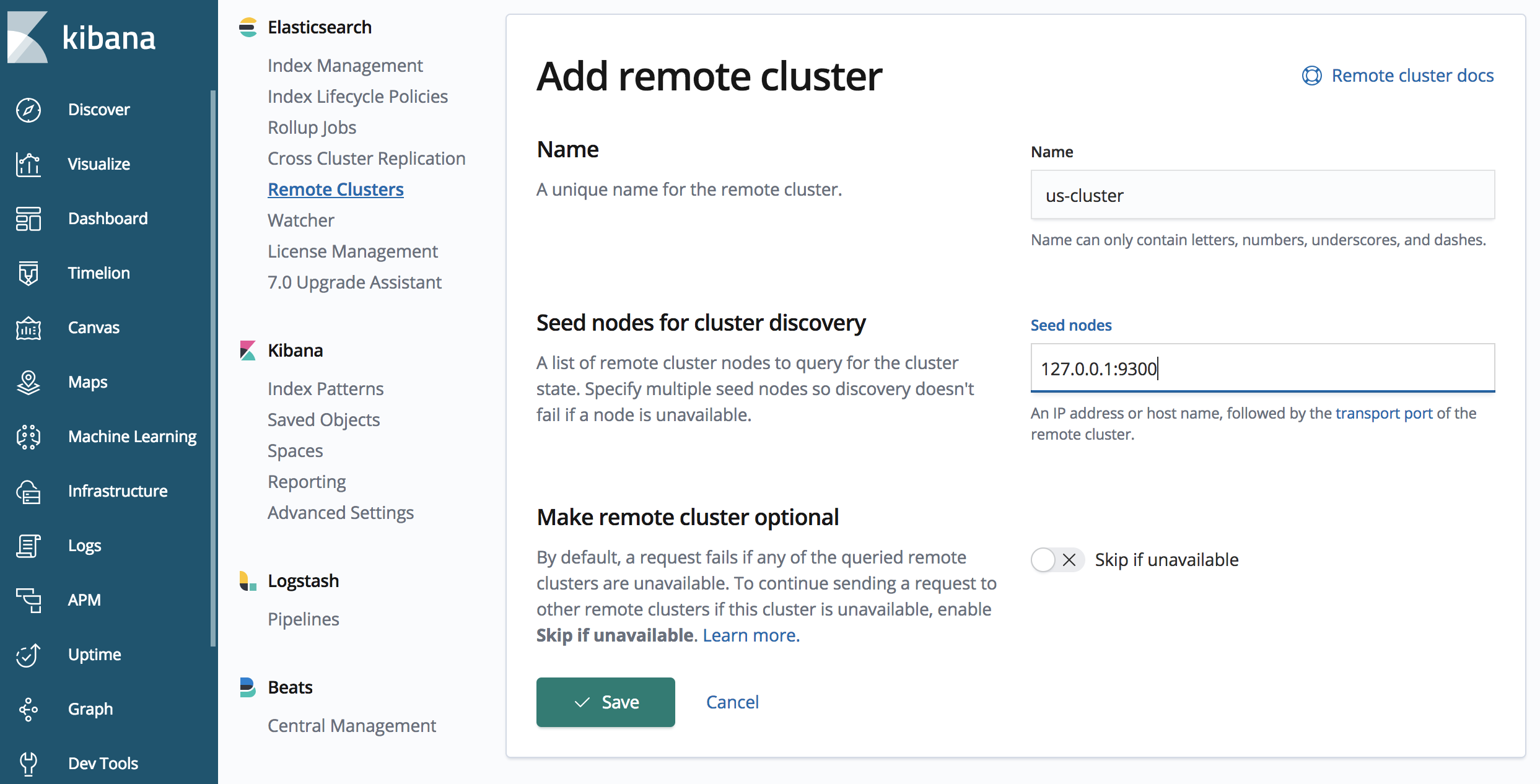
Lors du réglage de la CCR, les clusters Elasticsearch doivent connaître les autres clusters Elasticsearch. Il s'agit d'une exigence unidirectionnelle, dans laquelle le cluster cible assurera la maintenance des connexions unidirectionnelles vers le cluster source. Nous qualifions les autres clusters Elasticsearch de clusters distants et nous utilisons un alias pour les décrire.
Nous voulons nous assurer que notre "japan-cluster" connaît le "us-cluster". La réplication dans la CCR est basée sur l'extraction et nous n'avons pas besoin de préciser une connexion provenant de "us-cluster" vers "japan-cluster".
Définissons "us-cluster" via un appel de l'API dans "japan-cluster"
# À partir de "japan-cluster", nous définirons comment accéder à "us-cluster"
PUT /_cluster/settings
{
"persistent" : {
"cluster" : {
"remote" : {
"us-cluster" : {
"seeds" : [
"127.0.0.1:9300"
]
}
}
}
}
}
(Pour les commandes basées sur l'API, nous recommandons l'utilisation de la console d'outils de développement dans Kibana, disponible via Kibana -> Dev tools [Outils de développement] -> Console)
L'appel de l'API définit un cluster distant avec l'alias "us-cluster", accessible à l'adresse "127.0.0.1:9300". Une ou plusieurs valeurs initiales peuvent être spécifiées, et il est généralement recommandé d'en spécifier plus d'une, au cas où une valeur initiale ne serait pas disponible pendant la phase d'établissement de liaison.
Plus de détails sur la configuration de clusters distants sont disponibles dans notre documentation de référence sur la définition d'un cluster distant.
Il est également important de noter le port 9300 pour la connexion au "us-cluster", le "us-cluster" écoute le protocole HTTP sur le port 9200 (par défaut et spécifié dans le fichier elasticsearch.yml pour notre "us-cluster"). Cependant, la réplication se produit en utilisant le protocole de transport Elasticsearch (pour la communication nœud à nœud) ; le port par défaut est le port 9300.
Il existe une interface utilisateur de gestion pour les clusters distants dans Kibana. Dans ce tutoriel, nous aborderons l'interface utilisateur et l'API pour la CCR. Pour accéder à l'interface utilisateur du cluster distant dans Kibana, cliquez sur "Management" (Gestion) (icône en forme de roue dentée) dans le panneau de navigation de gauche, puis naviguez vers "Remote Clusters" (Clusters distants) dans la section Elasticsearch.
3. Création d'un index pour réplication
Créons un index appelé "products" dans notre "us-cluster". Nous répliquerons cet index à partir de notre source "us-cluster" vers notre cible "japan-cluster" :
Dans le "us-cluster" :
# Créer un index "product"
PUT /products
{
"settings" : {
"index" : {
"number_of_shards" : 1,
"number_of_replicas" : 0,
"soft_deletes" : {
"enabled" : true
}
}
},
"mappings" : {
"_doc" : {
"properties" : {
"name" : {
"type" : "keyword"
}
}
}
}
}
Vous avez peut-être remarqué le paramètre "soft_deletes". Les suppressions partielles sont requises pour qu'un index serve d'index meneur pour la CCR (consultez Historique des opérations pour en savoir plus) :
suppressions partielles : une suppression partielle a lieu lorsqu'un document existant est supprimé ou mis à jour. En conservant ces suppressions partielles à des limites configurables, l'historique des opérations peut être conservé dans les partitions de l'index meneur et être mis à disposition des tâches de partition de l'index suiveur, car il réexécute l'historique des opérations.
Dans la mesure où une partition d'index suiveur réplique les opérations de l'index leader, il laissera des marqueurs sur les partitions de l'index leader pour que ce dernier sache où sont ses suiveurs dans l'historique. Les opérations de suppression partielles en dessous de ces marqueurs sont éligibles à une fusion. Au-dessus de ces marqueurs, les partitions de l'index leader conserveront ces opérations pendant la période de location de conservation d'historique de partition, qui est de douze heures par défaut. Cette période détermine la durée pendant laquelle un index suiveur peut être hors ligne avant qu'il ne risque de prendre beaucoup de retard et qu'il ne doive être amorcé à partir de l'index meneur.
4. Lancement de la réplication
Maintenant que nous avons créé un alias pour notre cluster distant et que nous avons créé un index que nous souhaitons répliquer, laçons la réplication.
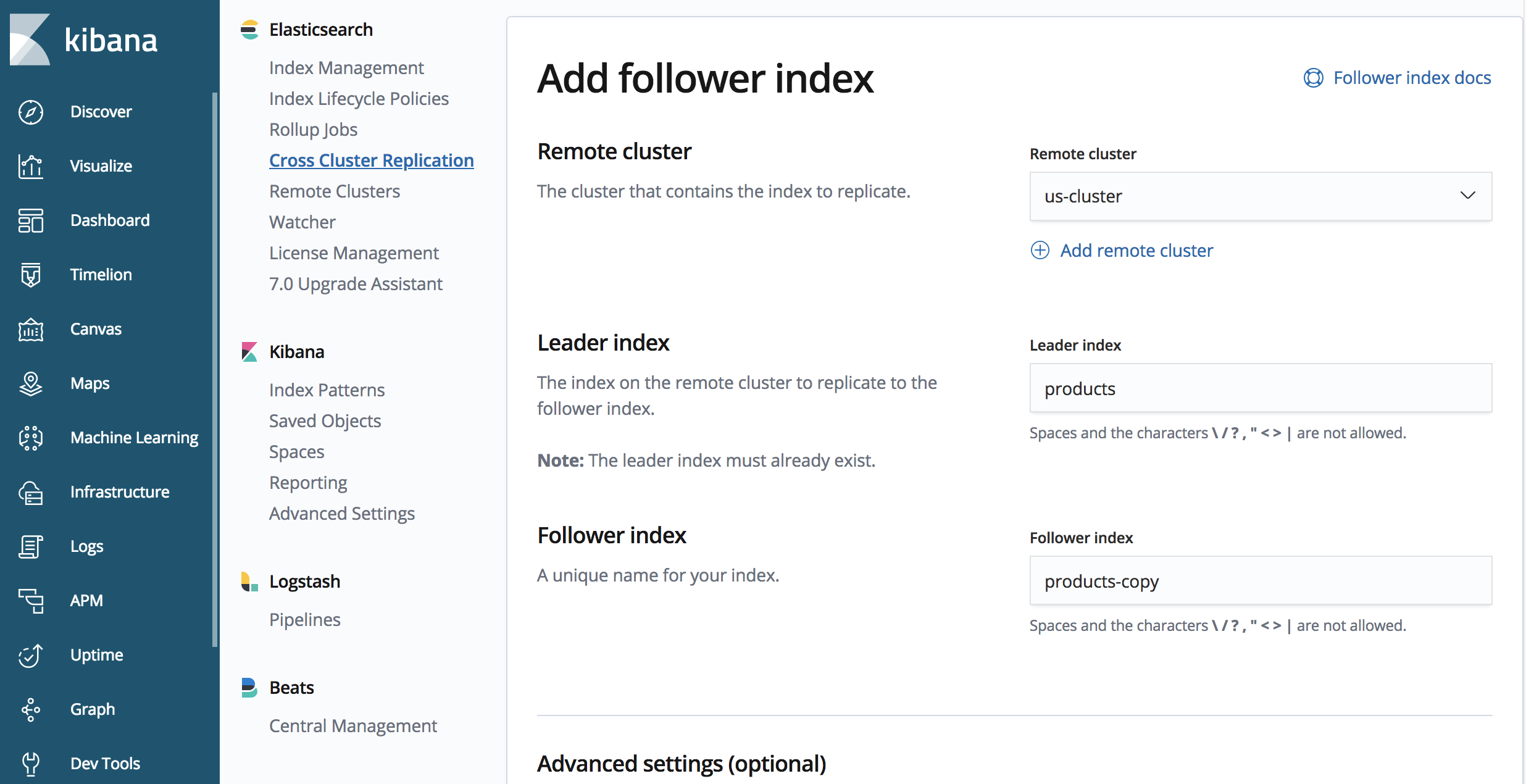
Dans notre "japan-cluster" :
PUT /products-copy/_ccr/follow
{
"remote_cluster" : "us-cluster",
"leader_index" : "products"
}
Le point de terminaison contient "products-copy", il s'agit du nom de l'index répliqué au sein du cluster "japan-cluster". Nous répliquons à partir du cluster "us-cluster" que nous avons préalablement défini, et le nom de l'index que nous répliquons se nomme "produits" dans le cluster "us-cluster".
Il convient de noter que notre index répliqué est en lecture seule et qu'il n'accepte pas les opérations d'écriture.
Et voilà ! Nous avons configuré un index à répliquer à partir d'un cluster Elasticsearch vers un autre !
Lancement de la réplication pour des modèles d'indexation
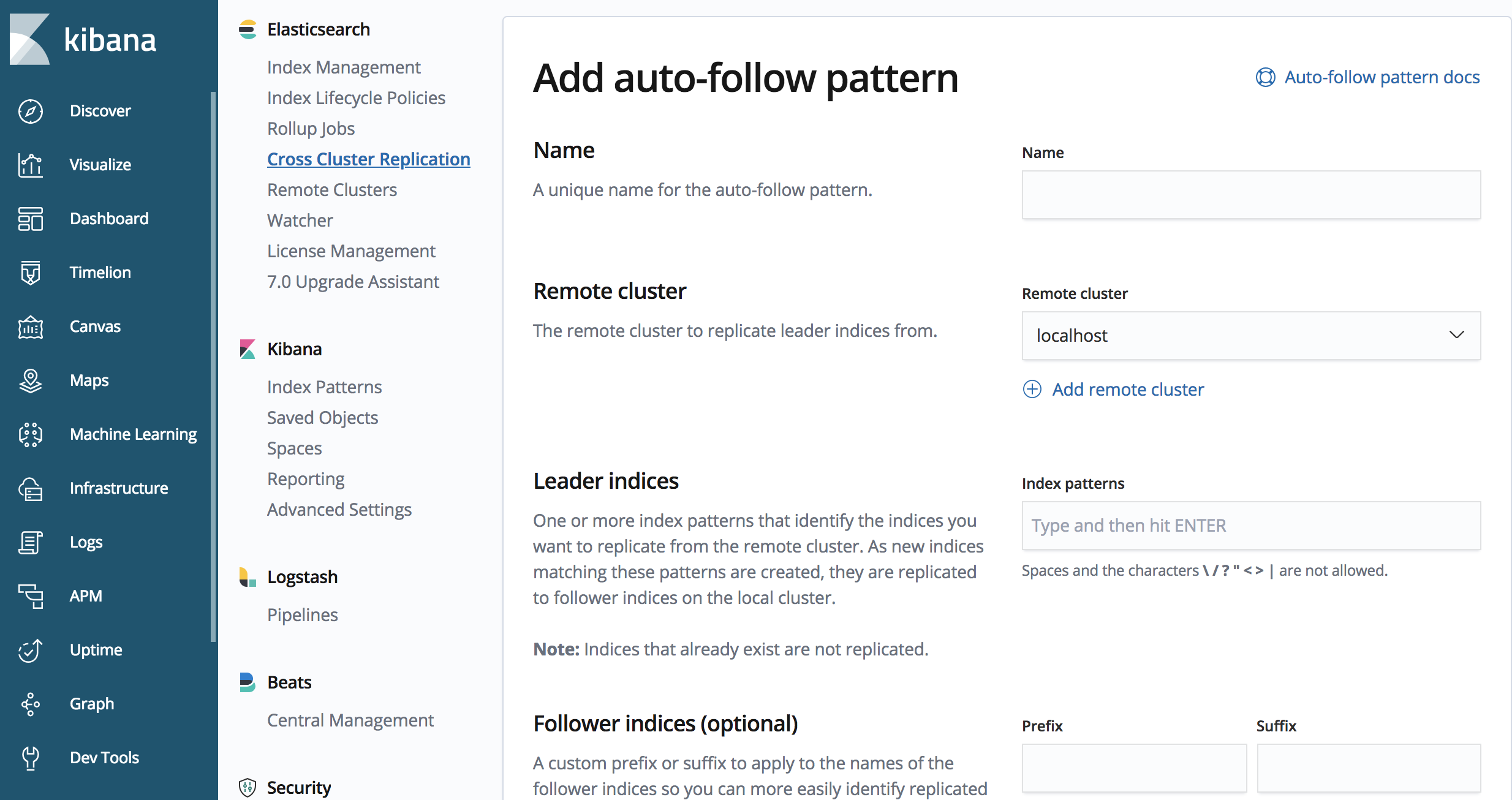
Vous avez peut-être remarqué que l'exemple ci-dessus ne fonctionnera pas très bien pour les cas d'utilisation temporels, dans lesquels il y a un index par jour, ou pour une quantité de données. L'API de la CCR contient également des méthodes de définition de modèles de suivi automatique, c'est-à-dire des modèles d'indexation devant être répliqués.
Nous pouvons utiliser l'API de la CCR pour définir un modèle de suivi automatique
PUT /_ccr/auto_follow/beats
{
"remote_cluster" : "us-cluster",
"leader_index_patterns" :
[
"metricbeat-*",
"packetbeat-*"
],
"follow_index_pattern" : "{{leader_index}}-copy"
}
L'exemple d'appel de l'API ci-dessus répliquera un index qui commence par "metricbeat" ou "packetbeat".
Nous pouvons également utiliser l'interface utilisateur de la CCR dans Kibana pour définir un modèle de suivi automatique.
5. Test des paramètres de réplication
Maintenant que nos index de produits ont été répliqués de "us-cluster" à "japan-cluster", insérons un document de test et vérifions s'il a été répliqué.
Dans le cluster "us-cluster" :
POST /products/_doc
{
"name" : "My cool new product"
}
Recherchons maintenant "japan-cluster" pour nous assurer que le document a été répliqué :
GET /products-copy/_search
Nous devrions avoir un seul document présent, qui a été écrit dans "us-cluster" et répliqué dans "japan-cluster".
{
"took" : 1,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : 1,
"max_score" : 1.0,
"hits" : [
{
"_index" : "products-copy",
"_type" : "_doc",
"_id" : "qfkl6WkBbYfxqoLJq-ss",
"_score" : 1.0,
"_source" : {
"name" : "My cool new product"
}
}
]
}
}
Remarques concernant l'administration inter-data center
Étudions certaines des API d'administration pour la CCR, les paramètres réglables, ainsi que la méthode pour convertir un index répliqué en un index normal dans Elasticsearch.
API d'administration pour la réplication
Un certain nombre d'API d'administration utiles existent pour la CCR dans Elasticsearch. Elles peuvent être utiles pour déboguer la réplication, modifier les paramètres de la réplication ou rassembler des diagnostics détaillés.
# Retourner toutes les statistiques associées à la CCR
GET /_ccr/stats
# Mettre en pause la réplication d'un index donné
POST //_ccr/pause_follow
# Reprendre la réplication, dans la plupart des cas après sa mise en pause
POST //_ccr/resume_follow
{
}
# Ne plus suivre un index (arrêter la réplication pour l'index de destination), ce qui nécessite d'abord de mettre en pause la réplication
POST //_ccr/unfollow
# Statistiques pour un index suiveur
GET //_ccr/stats
# Supprimer un modèle de suivi automatique
DELETE /_ccr/auto_follow/
# Afficher tous les modèles de suivi automatique, ou obtenir un modèle de suivi automatique par nom
GET /_ccr/auto_follow/
GET /_ccr/auto_follow/
Consultez la documentation de référence Elasticsearch pour en savoir plus sur les API d'administration de la CCR.
Conversion d'un index suiveur en index normal
Nous pouvons utiliser un sous-ensemble d'API d'administration ci-dessus pour étudier la conversion d'un index suiveur en index normal pouvant accepter l'écriture dans Elasticsearch.
Dans notre exemple ci-dessus, nous avions une configuration plutôt simple. Gardez à l'esprit que l'index "products-copy" répliqué dans notre "japan-cluster" est en lecture seule uniquement, il ne peut pas accepter les écritures. Si nous voulons convertir l'index "products-copy" en index normal dans Elasticsearch (capable d'accepter les écritures), nous pouvons alors effectuer les commandes suivantes. N'oubliez pas que les écritures dans notre index original ("products") peuvent continuer, et que nous pouvons vouloir restreindre les écritures dans notre index "products" d'abord, avant de convertir notre index "products-copy" en index Elasticsearch normal.
# Mettre en pause la réplication
POST //_ccr/pause_follow
# Fermer l'index
POST /my_index/_close
# Ne plus suivre
POST //_ccr/unfollow
# Ouvrir l'index
POST /my_index/_open
Poursuite de l'exploration de la réplication inter-clusters (CCR) dans Elasticsearch
Nous avons rédigé ce guide pour vous aider quant à la CCR dans Elasticsearch. Nous espérons qu'il est assez complet pour vous familiariser avec la CCR, pour apprendre les diverses API de CCR (y compris les interfaces utilisateur disponibles dans Kibana) et pour expérimenter la fonctionnalité. Les ressources supplémentaires incluent le guide Se lancer dans la réplication inter-clusters et le guide de référence API de réplication inter-clusters.
Comme toujours, laissez-nous un commentaire dans nos forums de discussion et posez-y toutes vos questions, nous veillerons à vous répondre dès que possible.