La Business Intelligence appliquée aux textes
Aujourd’hui les organisations (entreprises, associations, personnes, …) produisent et consomment des quantités de documents et de textes numériques (rapport, étude, synthèse, contrat, réponse aux enquêtes, sous format PDF, Office, web, …).
L’avènement des technologies du BIG DATA ont permis de mieux gérer ces énormes volumes de données, avec notamment la Business Intelligence qui a pour vocation d’exploiter cette multitude de données afin de faciliter le travail et les usages en contexte d’entreprise.
Seulement, voilà, ces outils se concentrent sur les données structurées ; or le texte n’est pas une donnée structurée.
De fait, la Business Intelligence se coupe de tout un pan de données (intéressantes voire prioritaires) en excluant les textes, données non structurées par définition.
Alors comment intégrer les données non structurées aux solutions de Business Intelligence ?
…c’est la mission que s’est donnée QWAM – et on a plutôt réussi !
Les ingénieurs QWAM ont utilisé deux outils : leur annotateur sémantique QWAM Text Analytics et la Suite Elastic – et c’est suffisant !
Explications
Que fait QWAM ?

QWAM est un éditeur de trois solutions logicielles dédiées respectivement à la gestion de contenus presse, media et métier, l’analyse automatique de textes en masse (big data textuelles), la surveillance et l’extraction d’informations-clés du web. Ces solutions sont décrites ci-après:

Ask’n’Read, solution de veille web développée par QWAM, permet de suivre l’apparition de nouvelles publications web (sites institutionnels, blogs, sites corporate, forums, tweet, …) ciblées par thématique ou secteur d’activité. Ainsi, Ask’n’Read récupère quotidiennement plusieurs millions de nouvelles informations web.

QWAM Text Analytics (QTA) est un annotateur sémantique qui permet d’enrichir les contenus textuels. Nous verrons plus loin le rôle central d’un annotateur dans la BI sur les textes.

QWAM E-Content Server (QES) est un CMS (Content Management System) pour gérer des masses de texte. Il propose des fonctions de GED, de collaboration, de workflow, d’alerte, de panier pour gérer ces volumes de texte et avoir la haute main dessus ; le tout sur Elasticsearch.
Vous l’aurez compris, QWAM est un fervent utilisateur de la Suite Elastic. Nous en utilisons tous les composants ; et notamment le X-Pack pour la gestion des droits sur les dashboards que nous produisons à destination de nos clients et le plugin « Graph » présent dans le X-Pack.Le problème intrinsèque du texte
Ce qui a donné le mauvais rôle au texte, est son aspect monolithique. Généralement, en bout de chaîne, on a … un champ texte. Et pour savoir ce qu’il y a dedans, il faut le lire. Si c’est un seul texte et qu’il est court ça peut aller, mais que faire quand on en a des milliers ou des millions ?
Il est toujours possible de les indexer dans Elasticsearch et de faire des visualisations dans Kibana.
Deux visualisations sont facilement disponibles : une timeline et un count global. Une troisième sur la base de nuage de mots est également envisageable mais c’est à peu près tout… frustration !
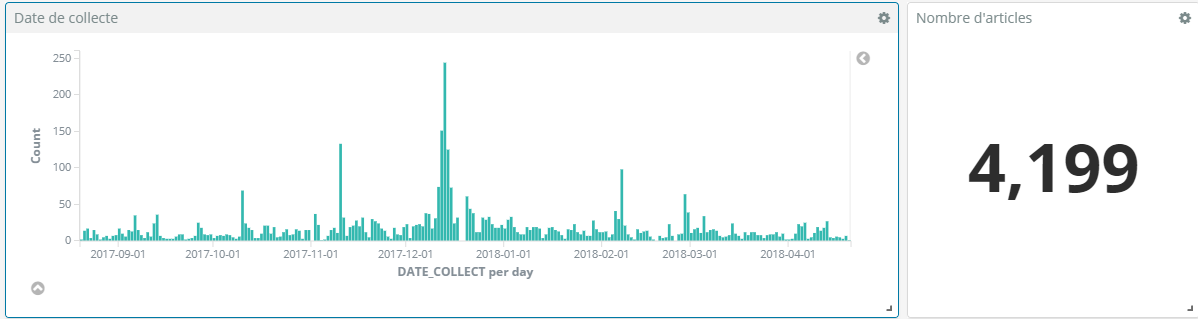
Nous sommes donc en possession d’une multitude de données et d’une Suite super performante ; mais la qualité des résultats reste décevante.
Cependant … avec un peu de méthode et des outils pour marier tout ça il est possible de faire ressortir des informations à haute valeur ajoutée !!
Explications : générer des métadonnées
Pourquoi générer des métadonnées ? Parce que … :
- les métadonnées permettent en les listant de savoir ce que contient un texte, sans avoir à le lire entièrement
- tous les outils que nous connaissons, Elasticsearch le premier, aiment bien les colonnes, les champs, les dimensions pour les exploiter. La puissance des agrégats d’Elasticsearch n’est plus à démontrer. Les champs servent de facette, sum(), count() , group-by, etc. … Mais il leur faut des champs
Il y a bien des métadonnées dans les formats PDF et Office, mais qui s’amuse à les remplir ?
Pour y parvenir, il faut juste ajouter un annotateur sémantique dans votre chaîne d’alimentation de la Suite Elastic.
Le schéma avec les solutions QWAM, Ask’N’Read (pour le crawl web en masse) et QWAM Text Analytics (pour l’annotation sémantique) est le suivant :
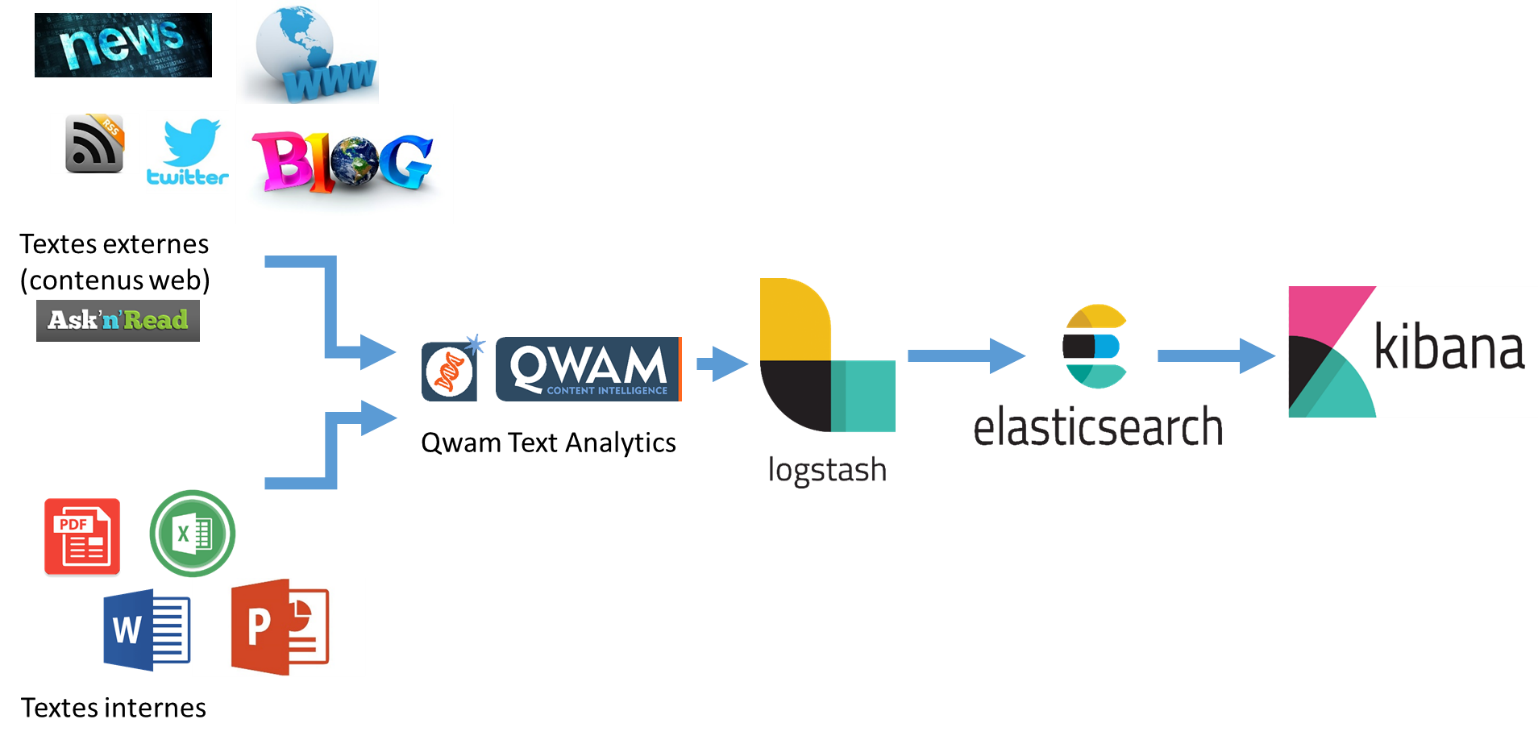
Pourquoi la suite Elastic ?
Spécialisés dans le traitement du texte en masse, nous sommes confrontés en permanence aux besoins suivants :
- Un grand nombre de documents : 15 millions minimum par an sur un sujet soit plus de 40 millions sur une durée de 3 ans
- Un grand nombre de facettes générées par notre annotateur avec chacune une grande cardinalité. Environ 50 facettes de plusieurs milliers de décompte par valeur.
- Une Dataviz d’analyse permettant la détection de patterns à partir de ces facettes et d’obtenir un dashboard rafraîchi en quelques secondes (et pas minutes ou heures)
Venant historiquement de SOLR, les faibles performances des bases SQL et l’absence de Dataviz sur SOLR nous a naturellement poussés vers Elasticsearch.
Les performances sont au rendez-vous avec une grande flexibilité dans l’ajout de nouveaux nœuds, le monitoring et la maintenance au quotidien très simples grâce à une API facile à appréhender.
Kibana couplé aux facettes, qui sont devenues des « agrégats » considérablement plus puissants, a répondu à nos attentes au-delà de nos espérances.
Il reste qu’aujourd’hui Kibana est un formidable outil de découverte de pattern mais reste peu orienté vers un client final. Il lui manque une couche de « story telling », permettant d’expliquer une démarche analytique complexe de manière plus accessible et progressive. Le projet « Canvas » devrait combler ce manque sous peu. C’est le seul point qui nous fait défaut.
Illustrations
Je vous propose donc un sujet relativement neutre, pour illustrer l’intérêt d’un annotateur couplé à la Suite Elastic, que nous autres « geeks » et les autres aimons bien : Star wars !
Voici donc mon use case :
J’ai simplement tapé la requête « star wars » et demandé la langue française dans un Kibana basé sur 40 millions de news économiques crawlées et annotées durant les 8 derniers mois.
Vous n’aurez je pense pas de mal à faire une transposition dans votre entreprise en imaginant qu’Han Solo, c’est votre PDG, le sabre laser, le produit phare que vous vendez, la galaxie, c’est la zone EMEA de votre marketing, et la requête c’est un secteur de votre entreprise par exemple !
De qui parle-t-on ? Les entités nommées
Le premier stade est la détection des entités nommées : les personnes, les sociétés, les organisations, les lieux, les médias, les produits, les objets et les événements.
Notre use case « Star wars » nous montre que « Luke Skywalker » et « Han Solo » sont les deux vedettes de notre recherche. « Star wars » était de tous les événements : les Oscars, les Golden Globes et d’autres.
Nous savons désormais de qui/quoi parlent nos documents.
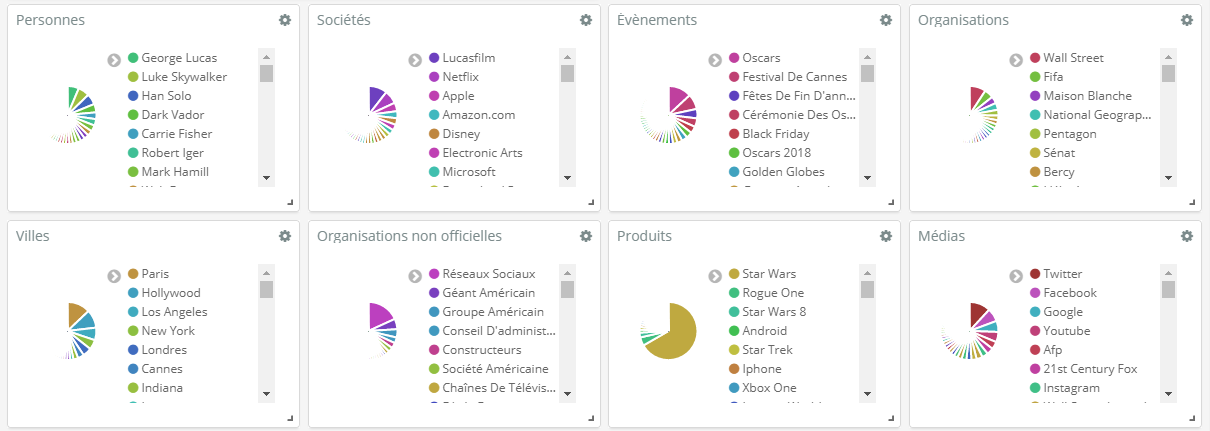
De quoi parle-t-on ? Les concepts
L’annotateur sémantique QWAM Text Analytics (QTA) grâce au TAL (Traitement automatique du langage, ou NLP Natural Language Processing en anglais) possède une connaissance grammaticale de la phrase, il est capable de détecter des locutions intéressantes du fait de leur nature grammaticale.
Nous savons désormais de quoi parlent nos documents :

Comment aider à faire des recherches performantes et interactives ?
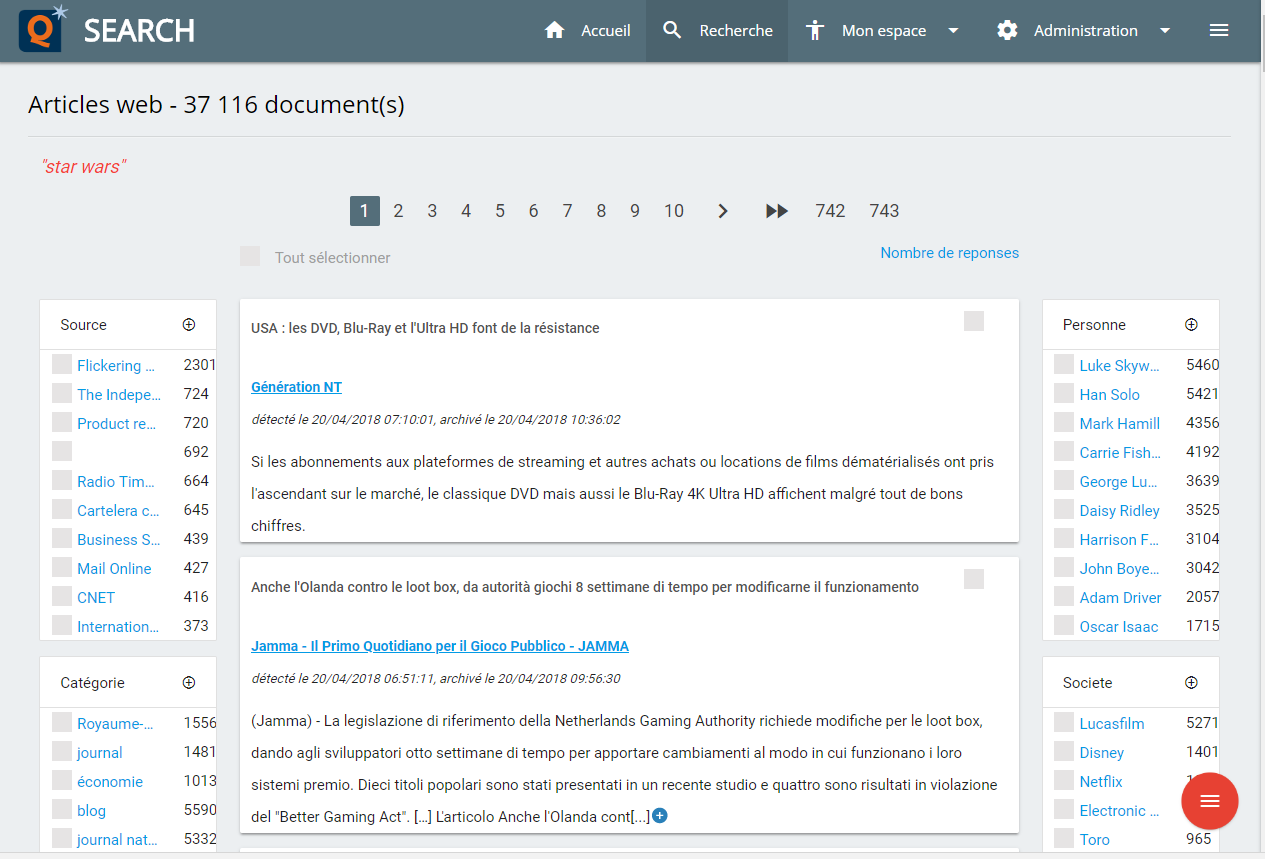
Dès ce stade, il est possible d’utiliser les métadonnées produites par l’annotateur comme facettes pour une recherche dans Elasticsearch. Les agrégations font leur miel des entités nommées et cela permet de proposer de nombreuses facettes pertinentes qui rendent la recherche interactive par « Drill down » et permet, non seulement d’avoir une bonne idée de ce que contient le corpus, mais également de produire en quelques clics successifs une recherche pointue.
Avouez que ça améliore l’expérience de « search » !
Voici un screenshot de notre CMS QWAM E-Content Server (QES)
Comment ces informations sont-elles reliées entre elles ?
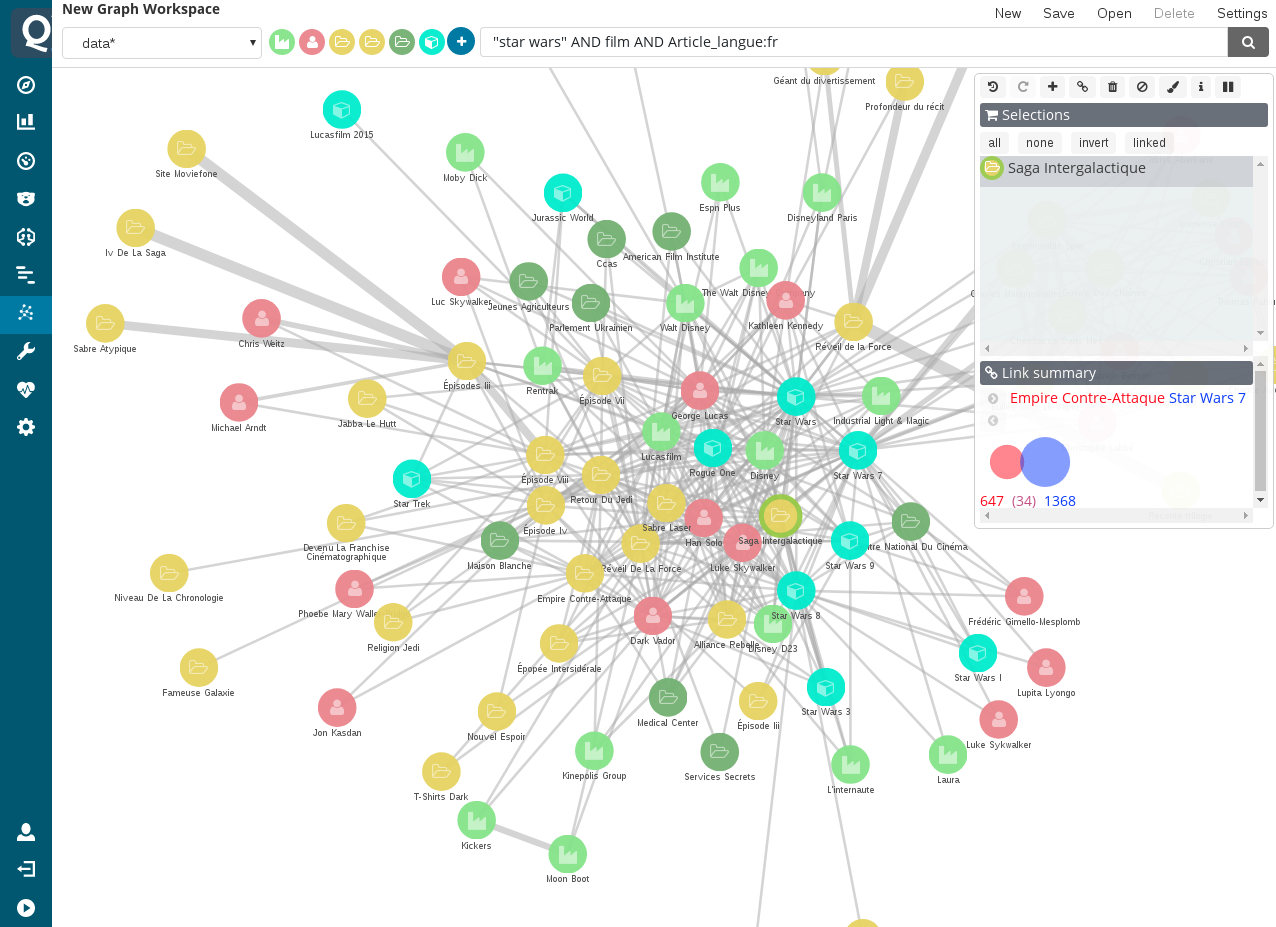
Kibana possède un plug-in «Graph», présent dans X-pack, permettant de représenter des relations.
Cela donne un graph duquel on apprend que « Mark Hamill » et « Luke Skywalker » sont une seule et même personne !
Des relations plus élaborées
Nous avons vu que la relation « Dans le même document » peut être facilement représentée par le plugin « Graph » de Kibana.
Les annotateurs les plus élaborés, dont QWAM Text Analytics, savent détecter et fournir en métadonnée des relations plus complexes entre les entités. Voici un florilège :
- Société -> Fusion, acquisition, vente, partenariat -> Société
- Personne -> Compétence, nomination, en poste -> Société
- Personne, Société -> participe -> Evénement (Salon, Foire, Exposition …)
Si « Graph » ne sait que représenter la relation « Dans le même document », comment faire pour représenter une telle relation dans Kibana ?
En isolant chaque relation dans un document propre, qui ne contient que l’expression de la relation, le tour est joué !
Vous bénéficiez alors avec « Graph » des capacités de représentation de relations « Multi layers », sans avoir à vous battre avec une base de graphes, tout cela dans votre Suite Elastic, où il suffit d’indexer des documents pour les exploiter. Vous avez dit pratique ?!
Malheureusement, pour des raisons de confidentialité sur les données de nos clients, je dois m’arrêter là concernant notre use case ”Star Wars”.
Comment en parle-t-on ?
Les sentiments exprimés avec une force sur des thèmes
Les annotateurs les plus puissants, sont capables de détecter les sentiments exprimés dans une phrase, pour les transformer en 3 niveaux de métadonnées :
- La nature du sentiment : Joie/Satisfaction, Colère/Frustration, Peur/Inquiétude/Incertitude, Suggestion, Intention
- La force du sentiment : graduée de -3 (très négatif) à +3 (très positif)
- Le thème sur lequel il s’exprime
Une représentation possible de cette répartition des sentiments selon leur force se fait sous Kibana sous la forme d’une « Heatmap » par exemple.
La voix du client, la voix du collaborateur
Il y a deux domaines majeurs pour l’analyse du sentiment :
- La voix du client : Savoir ce que vos clients pensent de vos produits sur les forums, les tweets, les verbatims dans les enquêtes
- La voix du collaborateur : Savoir ce que vos collaborateurs pensent de votre entreprise. Sont-ils heureux chez vous ? Ont-ils envie de partir (C’est l’attrition) ? Comment l’expriment-ils dans les verbatims dans les enquêtes, les réseaux sociaux d’entreprise ?
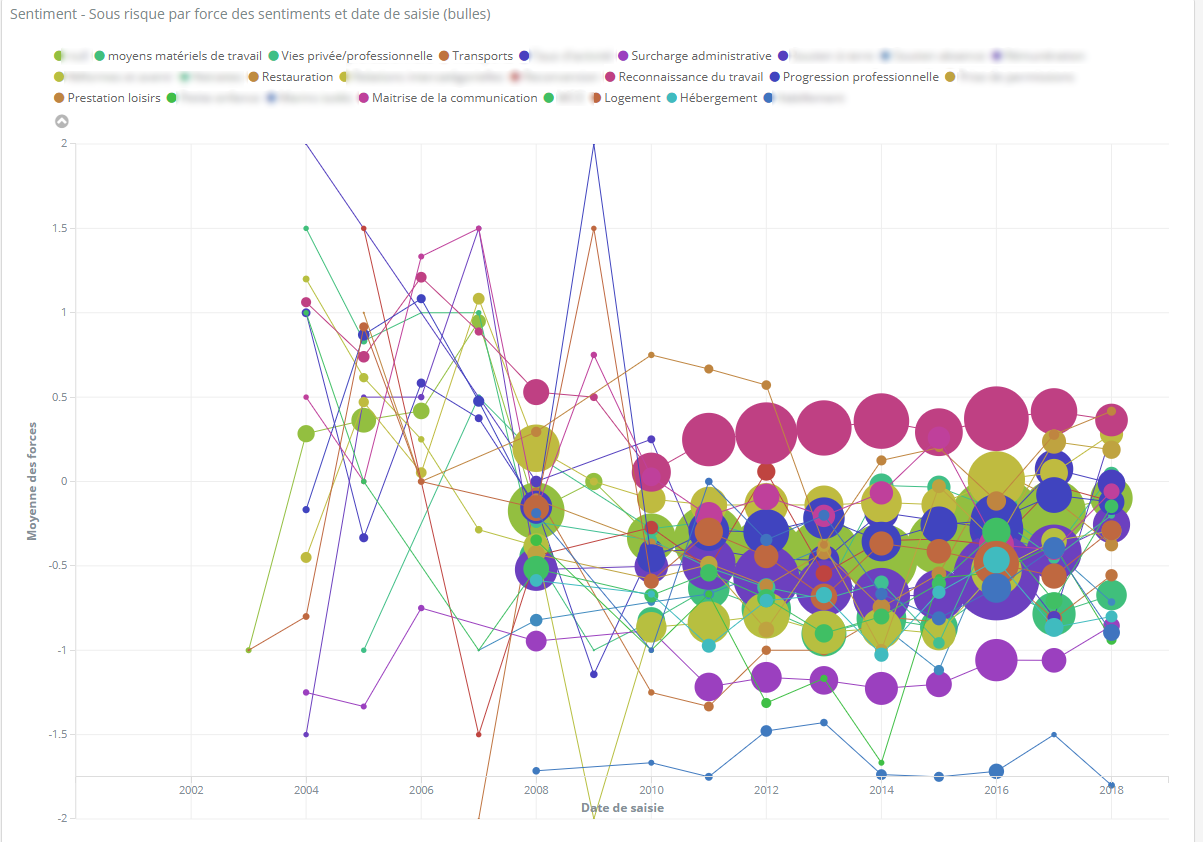
Voici par exemple une représentation dans Kibana des satisfactions et insatisfactions, exprimées par des collaborateurs, selon leur force avec une taille de bulle plus ou moins importante selon leur fréquence.
C’est le graph ultime qui résume le moral de l’entreprise en une visualisation. Le rêve de tout DRH!
Conclusion
Nous avons vu qu’un annotateur sémantique permet d’ajouter de nombreuses métadonnées/dimensions/champs à un texte brut permettant de le rendre bien plus manipulable et propre à de la Dataviz permettant de faire de la Business intelligence dessus :
- Entités nommées : Sociétés, Personnes, Organisations, Événements, Lieux, Pays, Régions, Villes, Géolocalisation
- Concepts : Fréquents sur le web, classés par thèmes, simplement dans le texte
- Relations : nominations, fusion/acquisitions, partenariats, participation à des événements
- Sentiments : Nature, Force et sujet d’expression du sentiment dans la phrase
L'auteur

Ivan Monnier est CTO de QWAM. Il est très assidu aux Meetups Elastic animés activement par David Pilato sur Paris, où il boit des bières et mange des pizzas. Comme il est très grand, il en mange beaucoup !