Introduction pratique à Logstash
La Suite Elastic a pour objectif de faciliter l'ingestion de données dans Elasticsearch. Filebeat est un outil pratique qui permet de suivre les fichiers. Il s'accompagne d'un ensemble de modules permettant d'ingérer une multitude de formats de logs courants, sans configuration complexe. Si les données que vous souhaitez ingérer ne sont pas traitées dans ces modules, les nœuds d'ingestion Logstash et Elasticsearch permettent d'analyser et de traiter la plupart des types de données texte, de manière flexible et efficace.
Cet article présente brièvement Logstash et vous explique comment l'utiliser lorsque vous développez une configuration pour analyser des exemples de logs d'accès du cache Squid et faire en sorte qu'ils soient ingérés dans Elasticsearch.
Brève présentation de Logstash
Logstash est un moteur de collecte et de traitement des données via plug-in. Il est doté de nombreux plug-ins qui permettent de configurer facilement l'outil pour collecter, traiter et transférer les données dans un grand nombre d'architectures variées.
Le traitement est organisé en un ou plusieurs pipelines. Dans chaque pipeline, un ou plusieurs plug-ins reçoivent ou collectent des données qui sont alors placées dans une file d'attente interne. Par défaut, celle-ci est petite et enregistrée dans la mémoire, mais vous pouvez la configurer pour l'agrandir et l'enregistrer sur le disque de manière permanente afin d'améliorer la fiabilité et la résilience.
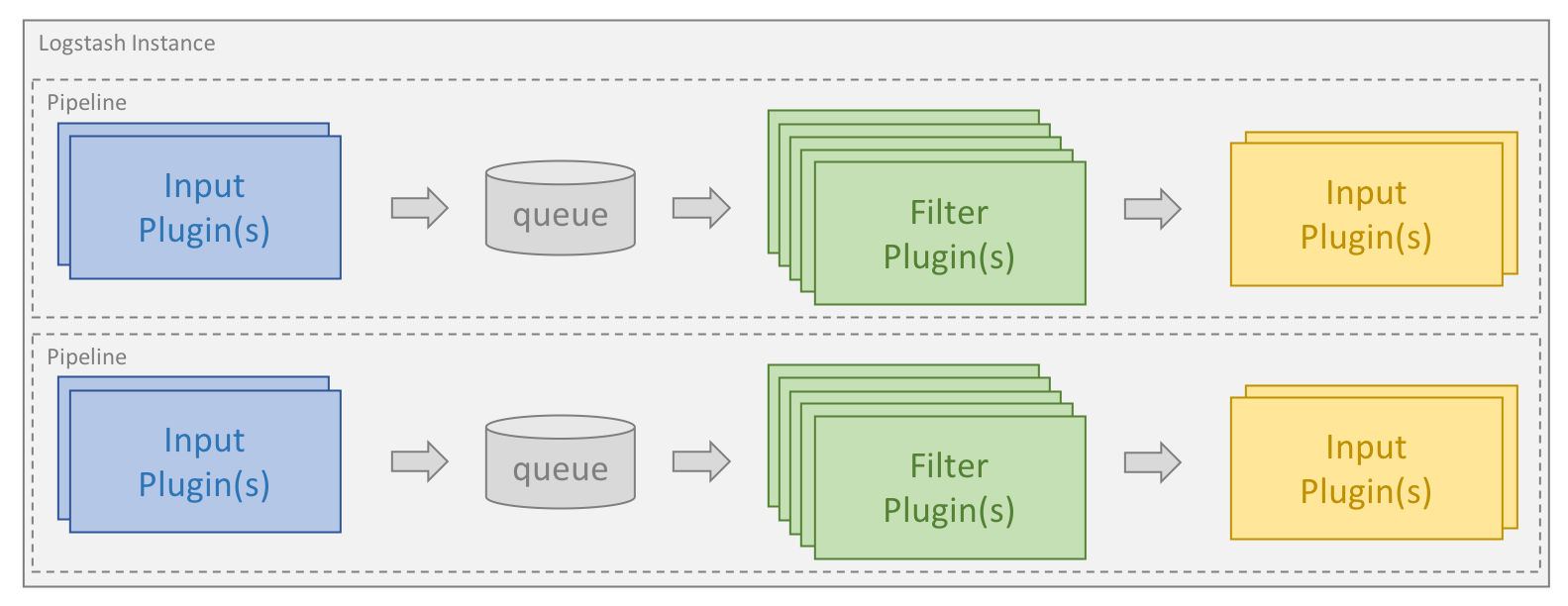
Les thread de traitement lisent les données dans la file d'attente, par micro-lots et les traitent à l'aide de l'un des plug-ins filtre configurés, en séquence. Logstash est prêt à l'emploi et est doté de nombreux plug-ins qui ciblent des types de traitements spécifiques. C'est ainsi que les données sont analysées, traitées et enrichies.
Dès lors que les données ont été traitées, les threads de traitement envoient les données aux plug-ins de sortie appropriés, chargés de formater et de transférer les données (par exemple, à Elasticsearch).
En outre, un plug-in codec peut être configuré pour les plug-ins d'entrée et de sortie. Il permet d'analyser et/ou de formater les données avant qu'elles intègrent la file d'attente interne ou qu'elles soient envoyées à un plug-in de sortie.
Installation de Logstash et Elasticsearch
Pour exécuter les exemples présentés dans cet article, vous devez d'abord installer Logstash et Elasticsearch. Cliquez sur les liens pour obtenir de l'aide concernant cette procédure, pour votre système d'exploitation. Nous utilisons la version 6.2.4 de la Suite Elastic.
Spécification des pipelines
Les pipelines Logstash sont créés à partir d'un ou plusieurs fichiers de configuration. Avant toute chose, nous commencerons par décrire les différentes options disponibles. Les répertoires décrits dans cette section peuvent varier en fonction du mode d'installation et du système d'exploitation, et sont spécifiés dans la documentation.
Un seul pipeline utilisant un seul fichier de configuration
La méthode la plus simple pour démarrer Logstash consiste à demander au système de créer un pipeline, à partir d'un fichier de configuration, défini grâce au paramètre de ligne de commande -f. C'est la méthode que nous utilisons tout au long de cet article.
Un seul pipeline utilisant plusieurs fichiers de configuration
Logstash peut aussi être configuré de manière à utiliser tous les fichiers d'un répertoire spécifique comme fichiers de configuration. Cette option peut être paramétrée grâce au fichier logstash.yml ou en intégrant le chemin d'un répertoire dans la ligne de commande, à l'aide du paramètre de ligne de commande -f. Il s'agit de l'option par défaut si vous installez Logstash en tant que service.
Lorsqu'un répertoire est spécifié, tous les fichiers de ce répertoire sont concaténés par ordre lexicographique, puis analysés sous la forme d'un seul fichier de configuration. Les données provenant de toutes les entrées sont alors traitées par l'ensemble des filtres et envoyées à toutes les sorties, sauf si vous utilisez des conditions pour contrôler le flux.
Utilisation de plusieurs pipelines
Pour utiliser plusieurs pipelines dans Logstash, vous devez modifier les fichiers pipelines.yml fournis avec Logstash. Pour ce faire, vous devez accéder au répertoire des paramètres. Il contient des fichiers de configuration et des paramètres de configuration pour tous les pipelines pris en charge par cette instance Logstash.
L'utilisation de plusieurs pipelines permet de séparer des flux logiques différents. Cela permet de réduire considérablement la complexité et la quantité de conditions utilisées. Ainsi, il est plus facile de régler et de préserver la configuration. Les données qui passent dans le pipeline deviennent alors de plus en plus homogènes. Cela permet d'améliorer les gains de performance, car les plug-ins de sortie peuvent être utilisés plus efficacement.
Création d'une première configuration
Chaque configuration Logstash doit contenir au moins un plug-in d'entrée et un plug-in de sortie. Les filtres sont facultatifs. Pour vous donner un premier exemple de ce qu'est un fichier de configuration simple, nous commencerons par un fichier qui lit un ensemble de données de test à partir d'un fichier et qui l'envoie à la console, dans un format structuré. Cette configuration peut s'avérer très utile lorsque vous développez une configuration, car elle permet d'itérer et de construire rapidement la configuration. Dans l'exemple utilisé dans cet article, notre fichier de configuration est nommé test.conf et est stocké dans le répertoire “/home/logstash” avec le fichier contenant les données du test :
input {
file {
path => ["/home/logstash/testdata.log"]
sincedb_path => "/dev/null"
start_position => "beginning"
}
}
filter {
}
output {
stdout {
codec => rubydebug
}
}
Ici nous pouvons voir les trois regroupements de premier niveau que l'on retrouve dans toutes les configurations Logstash : input, filter et output. Dans la section "input", nous avons défini un plug-in d'entrée de fichier et nous avons fourni le chemin du fichier de données de test, grâce à l'instruction path. Nous avons défini l'instruction start_position sur “beginning” afin d'ordonner au plug-in de lire le fichier depuis le début chaque fois qu'un nouveau fichier est découvert.
Afin d'effectuer un suivi des données traitées dans chaque fichier d'entrée, le plug-in d'entrée de fichier Logstash utilise un fichier nommé sincedb pour enregistrer la position actuelle. Notre configuration est utilisée pour le développement. Nous voulons donc que le fichier soit relu de manière répétée. C'est pourquoi nous tenons à désactiver l'utilisation du fichier sincedb. Pour cela, il faut paramétrer l'instruction sincedb_path sur “/dev/null” dans les systèmes Linux. Sous Windows, l'instruction doit être définie sur “nul”.
Bien que le plug-in d'entrée de fichier Logstash constitue une excellente solution pour se lancer dans le développement de configurations, Filebeat est l'outil recommandé pour collecter les logs et les envoyer en dehors des serveurs. Filebeat peut transférer les logs à Logstash et Logstash peut recevoir et traiter ces logs avec l'entrée Beats. La logique d'analyse définie dans cet article reste applicable dans les deux scénarios. Cependant, Filebeat est davantage optimisé pour la performance et utilise moins de ressources. Ainsi, il peut être exécuté en tant qu'agent.
Le plug-in de sortie stdout écrit les données sur la console et le codec rubydebug aide à afficher la structure, ce qui simplifie le débogage pendant le développement de la configuration.
Démarrage de Logstash
Pour vérifier le bon fonctionnement de Logstash et de notre fichier de configuration, nous créons un fichier nommé “testdata.log” dans le répertoire “/home/logstash”. Il contient la chaîne "Hello Logstash!", suivie d'une nouvelle ligne.
En supposant que nous disposons du fichier binaire logstash dans le répertoire, nous pouvons démarrer Logstash à l'aide de la commande suivante :
logstash -r -f "/home/logstash/test.conf"
En plus du paramètre de ligne de commande -f mentionné auparavant, nous avons également utilisé l'indicateur -r. Il ordonne à Logstash de recharger automatiquement la configuration chaque fois qu'il détecte une modification de la configuration. Cette fonction est particulièrement pratique pendant le développement. Nous avons désactivé le fichier sincedb, par conséquent le fichier d'entrée sera relu chaque fois que la configuration est rechargée. Cela nous permet de tester rapidement la configuration, au fur et à mesure de son développement.
L'élément envoyé à la console par Logstash présente des logs à son démarrage. Après quoi, le fichier est traité et le résultat est similaire à ce qui suit :
{
"message" => "Hello Logstash!",
"@version" => "1",
"path" => "/home/logstash/testdata.log",
"@timestamp" => 2018-04-24T12:40:09.105Z,
"host" => "localhost"
}
Il s'agit de l'événement traité par Logstash. Vous pouvez voir que les données sont stockées dans le champ "message" et que Logstash a ajouté des métadonnées pour l'événement, sous la forme de l'horodatage, indiquant la date à laquelle il a été traité, ainsi que son origine.
La structure est correcte et prouve que la mécanique fonctionne. À présent, nous allons ajouter des données de test plus réalistes et expliquer comment les analyser.
Comment analyser mes logs ?
Parfois, si vous avez de la chance, il existe un filtre parfaitement adapté à l'analyse de vos données (par exemple, le filtre json si vos logs sont au format JSON). Mais la plupart du temps, les logs à analyser sont de types et de formats de texte différents. L'exemple ci-après illustre des lignes de logs d'accès au cache Squid, semblables à ce qui suit :
1524206424.034 19395 207.96.0.0 TCP_MISS/304 15363 GET http://elastic.co/android-chrome-192x192.gif - DIRECT/10.0.5.120 - 1524206424.145 106 207.96.0.0 TCP_HIT/200 68247 GET http://elastic.co/guide/en/logstash/current/images/logstash.gif - NONE/- image/gif
Chaque ligne contient des informations concernant une requête au cache Squid et peut être détaillée en un certain nombre de champs distincts que nous devons analyser.

Lors de l'analyse des logs de texte, deux filtres spécifiques sont souvent utilisés : le filtre "dissect" analyse les logs en fonction des séparateurs alors que le filtre grok se base sur la correspondance d'expressions régulières.
Le filtre "dissect" est particulièrement efficace lorsque la structure des données est bien définie et il peut être très rapide. De plus il est souvent plus simple à prendre en main, en particulier pour les utilisateurs qui ne maîtrisent pas bien les expressions régulières.
Le filtre "grok" est généralement plus puissant et peut traiter une plus grande variété de données. Cependant, le système de correspondance des expressions régulières utilise plus de ressources et peut être plus lent, en particulier s'il n'est pas correctement utilisé.
Avant de procéder à l'analyse, nous remplaçons le contenu du fichier testdata.log par ces deux lignes de log, en vérifiant que chaque ligne est suivie d'une nouvelle ligne.
Analyse des logs avec le filtre "dissect"
Lorsque vous utilisez le filtre "dissect", vous devez définir une séquence de champs à extraire, ainsi que les séparateurs entre ces champs. Le filtre effectue une analyse des données et s'aligne avec les séparateurs de la structure. Parallèlement, les séparateurs sont attribués aux champs spécifiés. Le filtre ne valide pas le format des données en cours d'extraction.
Les séparateurs utilisés lors de l'analyse des données avec le filtre "dissect" sont indiqués en rose, ci-dessous.

Le premier champ contient l'horodatage et est suivi d'un ou plusieurs espaces, en fonction de la longueur du champ "duration". Nous pouvons indiquer "%{timestamp}" dans le champ "timestamp". Cependant, pour qu'il accepte un nombre variable d'espaces en tant que séparateurs, nous devons ajouter un suffixe -> dans le champ. Tous les autres séparateurs dans l'entrée du log sont composés d'un seul caractère. Ainsi, nous pouvons commencer à construire un schéma. La section du filtre est alors similaire à ce qui suit :
{
"@version" => "1",
"message" => "1524206424.034 19395 207.96.0.0 TCP_MISS/304 15363 GET http://elastic.co/android-chrome-192x192.gif - DIRECT/10.0.5.120 -",
"@timestamp" => 2018-04-24T12:42:23.003Z,
"path" => "/home/logstash/testdata.log",
"host" => "localhost",
"duration" => "19395",
"timestamp" => "1524206424.034",
"rest" => "TCP_MISS/304 15363 GET http://elastic.co/android-chrome-192x192.gif - DIRECT/10.0.5.120 -",
"client_ip" => "207.96.0.0"
}
À présent, nous pouvons continuer à créer le schéma étape par étape. Après avoir correctement analysé tous les champs, nous pouvons supprimer le champ "message" de manière à ne pas traiter les mêmes données en double. Pour cela, nous utilisons l'instruction "remove_field" qui ne s'exécute que si l'analyse est réussie. Le bloc de filtre suivant est alors généré :
filter {
dissect {
mapping => {
"message" => "%{timestamp->} %{duration} %{client_address} %{cache_result}/%{status_code} %{bytes} %{request_method} %{url} %{user} %{hierarchy_code}/%{server} %{content_type}"
}
remove_field => ["message"]
}
}
Lorsqu'on l'utilise sur les données prises dans l'exemple, on obtient le résultat suivant :
{
"user" => "-",
"content_type" => "-",
"host" => "localhost",
"cache_result" => "TCP_MISS",
"@timestamp" => 2018-04-24T12:43:07.406Z,
"duration" => "19395",
"request_method" => "GET",
"url" => "http://elastic.co/android-chrome-192x192.gif",
"timestamp" => "1524206424.034",
"status_code" => "304",
"server" => "10.0.5.120",
"@version" => "1",
"client_address" => "207.96.0.0",
"bytes" => "15363",
"path" => "/home/logstash/testdata.log",
"hierarchy_code" => "DIRECT"
}
La documentation contient des exemples utiles et le présent article traite en détail du design et de l'objectif du filtre. Un jeu d'enfant, pas vrai ?
Nous pouvons aller plus loin. Mais avant cela, voyons comment procéder de la même manière avec "grok".
Comment utiliser "grok" de manière optimale ?
"Grok" utilise des schémas d'expressions régulières pour faire correspondre les champs et les séparateurs. Dans l'exemple ci-dessous, contenant des chiffres, les champs à capturer sont en bleu et les séparateurs sont en rouge.

"Grok" associe les schémas configurés dès le début et poursuit jusqu'à mapper l'intégralité de l'événement ou jusqu'à ce qu'il décide qu'il est impossible de trouver une correspondance. En fonction des types de schémas utilisés, il se peut que "grok" soit obligé de traiter plusieurs fois certaines parties des données.
"Grok" est doté d'une vaste sélection de schémas prêts à l'emploi. Certains des schémas les plus génériques sont disponibles ici. Ce répertoire contient également un grand nombre de schémas relativement spécialisés pour les types de données courants. Il en existe même un pour l'analyse des logs d'accès Squid. Dans ce tutoriel, au lieu de l'utiliser directement, nous verrons comment le construire depuis le début. Cependant, nous verrons aussi qu'il peut être très utile de consulter ce répertoire pour vérifier si un schéma adapté existe déjà, avant de se lancer dans la création d'un schéma personnalisé.
Plusieurs schémas standard sont couramment utilisés lors de la création d'une configuration "grok" :
- WORD – schéma avec correspondance d'un seul mot
- NUMBER – schéma avec correspondance d'un chiffre entier négatif ou positif ou d'un nombre à virgule flottante
- POSINT – schéma avec correspondance d'un chiffre entier positif
- IP – schéma avec correspondance d'une adresse IPv4 ou IPv6
- NOTSPACE – schéma avec correspondance de n'importe quel élément qui n'est pas un espace
- SPACE – schéma avec correspondance de plusieurs espaces consécutifs
- DATA – schéma avec correspondance d'un nombre limité de données de tous types
- GREEDYDATE – schéma avec correspondance de toutes les données restantes
Il s'agit là des schémas que nous utiliserons pour créer notre configuration de filtre "grok". De manière générale, pour créer des configurations "grok", il convient de commencer par la gauche et de le créer graduellement, en capturant le reste des données avec le schéma GREEDYDATA. Pour commencer, nous pouvons utiliser le schéma et le bloc de filtre ci-après :
filter {
grok {
match => {
"message" => "%{NUMBER:timestamp}%{SPACE}%{GREEDYDATA:rest}"
}
}
}
Le schéma invite "grok" à chercher un chiffre au début de la chaîne et le stocke dans un champ nommé timestamp. Après quoi, il détecte un certain nombre d'espaces avant de stocker le reste des données dans un champ nommé rest. Lorsque l'on remplace le bloc de filtre "dissect" par celui-là, on obtient le résultat suivant :
{
"timestamp" => "1524206424.034",
"rest" => "19395 207.96.0.0 TCP_MISS/304 15363 GET http://elastic.co/android-chrome-192x192.gif - DIRECT/10.0.5.120 -",
"path" => "/home/logstash/testdata.log",
"message" => "1524206424.034 19395 207.96.0.0 TCP_MISS/304 15363 GET http://elastic.co/android-chrome-192x192.gif - DIRECT/10.0.5.120 -",
"@timestamp" => 2018-04-24T12:45:11.026Z,
"@version" => "1",
"host" => "localhost"
}
Utilisation du débogueur "grok"
Bien qu'il soit possible de développer le schéma entier de cette manière, il existe un outil dans Kibana permettant de simplifier la création de schéma "grok" : Grok Debugger. La vidéo ci-après explique comment utiliser cet outil pour créer des schémas pour les exemples de logs utilisés dans cet article.
Une fois la configuration créée, nous pouvons supprimer le champ "message" dès lors que l'analyse est terminée et réussie. Ainsi, nous obtenons le bloc de filtre suivant :
filter {
grok {
match => {
"message" => "%{NUMBER:timestamp}%{SPACE}%{NUMBER:duration}\s%{IP:client_address}\s%{WORD:cache_result}/%{POSINT:status_code}\s%{NUMBER:bytes}\s%{WORD:request_method}\s%{NOTSPACE:url}\s%{NOTSPACE:user}\s%{WORD:hierarchy_code}/%{NOTSPACE:server}\s%{NOTSPACE:content_type}"
}
remove_field => ["message"]
}
}
Il est semblable au schéma prêt à l'emploi, mais pas identique. Avec les données de l'exemple, on constate que le premier enregistrement est analysé de la même manière que lorsque nous avons utilisé le filtre "dissect" :
{
"request_method" => "GET",
"cache_result" => "TCP_MISS",
"@timestamp" => 2018-04-24T12:48:15.123Z,
"timestamp" => "1524206424.034",
"user" => "-",
"bytes" => "15363",
"path" => "/home/logstash/testdata.log",
"hierarchy_code" => "DIRECT",
"duration" => "19395",
"client_address" => "207.96.0.0",
"@version" => "1",
"status_code" => "304",
"url" => "http://elastic.co/android-chrome-192x192.gif",
"content_type" => "-",
"host" => "localhost",
"server" => "10.0.5.120"
}
Réglage de "grok" pour optimiser les performances
"Grok" est un outil très puissant et flexible pour l'analyse des données. Cependant, une mauvaise utilisation des schémas peut entraîner des performances plus faibles que prévu. C'est pourquoi nous vous invitons à lire cet article concernant le réglage des performances de "grok" avant de commencer à l'utiliser.
Vérification du type de champs
Comme vous avez pu le voir dans les exemples ci-dessus, tous les champs ont été analysés sous forme de champs de chaîne. Avant d'envoyer le résultat à Elasticsearch sous forme de documents JSON, nous voulons modifier les champs bytes, duration et status_code en nombres entiers et le champ timestamp en élément flottant.
Pour cela, nous pouvons utiliser un filtre mutate et son option convert.
mutate {
convert => {
"bytes" => "integer"
"duration" => "integer"
"status_code" => "integer"
"timestamp" => "float"
}
}
Alternativement, nous pouvons également passer directement par les filtres "dissect" et "grok". Dans le filtre "dissect", il faut alors utiliser l'instruction convert_datatype.
filter {
dissect {
mapping => {
"message" => "%{timestamp->} %{duration} %{client_address} %{cache_result}/%{status_code} %{bytes} %{request_method} %{url} %{user} %{hierarchy_code}/%{server} %{content_type}"
}
remove_field => ["message"]
convert_datatype => {
"bytes" => "int"
"duration" => "int"
"status_code" => "int"
"timestamp" => "float"
}
}
}
Avec le filtre "grok", vous pouvez spécifier le type directement après le nom du champ dans le schéma.
filter {
grok {
match => {
"message" => "%{NUMBER:timestamp:float}%{SPACE}%{NUMBER:duration:int}\s%{IP:client_address}\s%{WORD:cache_result}/%{POSINT:status_code:int}\s%{NUMBER:bytes:int}\s%{WORD:request_method}\s%{NOTSPACE:url}\s%{NOTSPACE:user}\s%{WORD:hierarchy_code}/%{NOTSPACE:server}\s%{NOTSPACE:content_type}"
}
remove_field => ["message"]
}
}
Utilisation du filtre "date"
L'horodatage extrait du log est exprimé en secondes et millisecondes, depuis epoch. Nous voulons prendre cet élément et le convertir au format d'horodatage standard, qui peut être stocké dans le champ @timestamp. Pour cela, nous utilisons le plug-in de filtre date avec le schéma UNIX, qui correspond à nos données.
date {
match => [ "timestamp", "UNIX" ]
}
Tous les horodatages standard stockés dans Elasticsearch correspondent au fuseau horaire UTC. C'est également le cas de l'horodatage extrait. Il n'est donc pas nécessaire de définir un fuseau horaire. Si votre horodatage est exprimé dans un autre format, vous pouvez indiquer ledit format au lieu du schéma UNIX prédéfini.
Après avoir ajouté ceci, ainsi que le type de conversion, à notre configuration, le premier événement est semblable à ce qui suit :
{
"duration" => 19395,
"host" => "localhost",
"@timestamp" => 2018-04-20T06:40:24.034Z,
"bytes" => 15363,
"user" => "-",
"path" => "/home/logstash/testdata.log",
"content_type" => "-",
"@version" => "1",
"url" => "http://elastic.co/android-chrome-192x192.gif",
"server" => "10.0.5.120",
"client_address" => "207.96.0.0",
"timestamp" => 1524206424.034,
"status_code" => 304,
"cache_result" => "TCP_MISS",
"request_method" => "GET",
"hierarchy_code" => "DIRECT"
}
Nous obtenons alors le format souhaité et nous pouvons commencer à envoyer les données à Elasticsearch.
Comment envoyer des données à Elasticsearch ?
Avant de commencer à envoyer des données à Elasticsearch à l'aide du plug-in de sortie Elasticsearch, nous devons d'abord étudier le rôle des mappages et ce qui les distingue des types dans lesquels vous pouvez convertir les éléments dans Logstash.
Elasticsearch peut détecter automatiquement les champs numériques et de chaînes. Le mappage sélectionné est basé sur le premier document détecté comportant un nouveau champ. En fonction des données, le mappage obtenu peut alors être correct ou incorrect. Par exemple, si un champ correspond habituellement à un élément flottant, mais qu'il correspond à "0" à certains endroits. Il se peut que l'élément soit mappé en tant que nombre entier au lieu d'élément flottant, en fonction du document qui a été traité en premier.
Elasticsearch peut aussi détecter automatiquement les champs de date, tant qu'elles sont dans le format standard produit par le filtre "date".
D'autres types de champs (par exemple, geo_point et ip) ne peuvent pas être détectés automatiquement et doivent être explicitement définis à l'aide d'un modèle d'index. Les modèles d'index peuvent être gérés directement dans Elasticsearch, via une API. Il est aussi possible de faire en sorte que Logstash vérifie que le modèle adapté est chargé dans le plug-in de sortie Elasticsearch.
Pour nos données, nous sommes généralement satisfaits des mappages par défaut. Le champ server peut contenir un tiret ou une adresse IP valide. Par conséquent, nous ne le mapperons pas en tant que champ IP. Le champ client_addresse, cependant, nécessite un mappage manuel, car il doit être de type IP. De plus, plusieurs champs de chaînes doivent pouvoir être agrégées, sans pour autant qu'il soit possible d'effectuer une recherche de texte libre. Nous les mapperons donc explicitement en tant que champs keyword. Les champs concernés sont les suivants : user, path, content_type, cache_result, request_method, server et hierarchy_code.
Nous souhaitons stocker nos données dans des index basés sur le temps dotés du préfixe squid-. Pour cet exemple, l'on suppose qu'Elasticsearch est exécuté avec la configuration par défaut sur le même hôte que Logstash.
Nous pouvons alors créer le modèle suivant, stocké dans un fichier nommé squid_mapping.json :
{
"index_patterns": ["squid-*"],
"mappings": {
"doc": {
"properties": {
"client_address": { "type": "ip" },
"user": { "type": "keyword" },
"path": { "type": "keyword" },
"content_type": { "type": "keyword" },
"cache_result": { "type": "keyword" },
"request_method": { "type": "keyword" },
"server": { "type": "keyword" },
"hierarchy_code": { "type": "keyword" }
}
}
}
}
Ce modèle est configuré de manière à s'appliquer à tous les index correspondant au schéma d'index squid-*. Pour le type de document doc (par défaut dans Elasticsearch 6.x), celui-ci définit le mappage pour le champ client_address sur la valeur IP et les autres champs sur keyword.
Nous pouvons importer cela directement dans Elasticsearch, mais au lieu de cela, nous allons vous montrer comment configurer le plug-in de sortie Elasticsearch de manière à ce qu'il gère cette opération. Dans la section sortie de notre configuration Logstash, nous ajoutons un bloc similaire à ce qui suit :
elasticsearch {
hosts => ["localhost:9200"]
index => "squid-%{+YYYY.MM.dd}"
manage_template => true
template => "/home/logstash/squid_mapping.json"
template_name => "squid_template"
}
À présent, si nous exécutons cette configuration et indexons les exemples de documents dans Elasticsearch, nous obtenons le résultat suivant lors de la récupération des mappages générés pour l'index, via l'API get mapping :
{
"squid-2018.04.20" : {
"mappings" : {
"doc" : {
"properties" : {
"@timestamp" : {
"type" : "date"
},
"@version" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
},
"bytes" : {
"type" : "long"
},
"cache_result" : {
"type" : "keyword"
},
"client_address" : {
"type" : "ip"
},
"content_type" : {
"type" : "keyword"
},
"duration" : {
"type" : "long"
},
"hierarchy_code" : {
"type" : "keyword"
},
"host" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
},
"path" : {
"type" : "keyword"
},
"request_method" : {
"type" : "keyword"
},
"server" : {
"type" : "keyword"
},
"status_code" : {
"type" : "long"
},
"timestamp" : {
"type" : "float"
},
"url" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
},
"user" : {
"type" : "keyword"
}
}
}
}
}
}
On peut voir que notre modèle a été appliqué et que les champs spécifiés sont mappés correctement. Cet article traite principalement de Logstash et nous n'avons donc pas approfondi la question du mappage et de son fonctionnement. Pour en savoir plus sur ce sujet important, consultez la documentation.
Conclusions
Dans cet article, nous vous avons expliqué comment utiliser Logstash de manière optimale pour le développement d'un exemple de configuration personnalisée et comment garantir l'écriture correcte dans Elasticsearch. Cependant, Logstash reste un vaste sujet qui vaut la peine de s'y attarder plus en profondeur. Nous vous invitons à consulter les documents et articles mentionnés tout au long de cet article. De même, vous pouvez consulter le guide officiel de prise en main et examiner les plug-ins d'entrée, de sortie et de filtre disponibles. Dès lors que vous maîtriserez toutes les options à votre disposition, Logstash deviendra pour vous un véritable couteau suisse du traitement de données.
En cas de problème ou si vous avez des questions, consultez la section Logstash de notre forum de discussion. Pour consulter d'autres exemples de données et de configurations Logstash, rendez-vous sur https://github.com/elastic/examples/.
À vous de jouer !