Recette magique pour la mise en place d’un plug-in dans l’agent Java Elastic APM
Dans l’idéal, un agent APM instrumente et trace automatiquement les frameworks et les bibliothèques existants. Dans la réalité, ce qu’un agent APM prend en charge dépend de sa capacité et des priorités établies. Notre liste de technologies et de frameworks pris en charge ne cesse de s’allonger, et pour cause : nous établissons des priorités à partir des commentaires précieux de nos utilisateurs. Ceci étant dit, si vous utilisez l’agent Java Elastic APM et que vous avez besoin d’un élément qui n’est pas directement pris en charge, il existe plusieurs méthodes pour en effectuer le traçage.
Par exemple, vous pouvez utiliser notre API publique pour tracer votre propre code, et notre super configuration custom-method-tracing pour monitorer des méthodes spécifiques dans des bibliothèques tierces de façon basique. Si vous souhaitez en revanche obtenir une plus grande visibilité sur des données spécifiques à partir de code tiers, il faudra aller un peu plus loin. Heureusement, notre agent est open source. De ce fait, vous pouvez faire tout ce que nous pouvons faire. Et tant que vous y êtes, faites-en profiter la communauté ! L’avantage ? Vous obtiendrez plus de commentaires et votre code sera exécuté sur d’autres environnements.
Nous accueillerons avec grand plaisir toute contribution permettant de décupler nos capacités, tant que celle-ci respecte les normes auxquelles nous sommes tenus, conformément aux attentes de nos utilisateurs. Par exemple, consultez cette requête d’extraction pour prendre en charge les appels client OkHttp ou cette extension à notre support JAX-RS. Avant que vous ne vous jetiez sur votre clavier pour écrire du code, voici quelques points à garder en tête lorsque vous apportez votre contribution à notre base de code. Un scénario de test vous sera présenté en parallèle pour vous aider avec ce guide de mise en œuvre de plug-in.
Scénario de test : Instrumentation du client Java REST Elasticsearch
Avant de lancer notre agent, nous souhaitions prendre en charge notre propre client datastore. Nous voulions que nos utilisateurs du client Java REST Elasticsearch sachent :
- Qu’une recherche a eu lieu dans Elasticsearch
- La durée de cette recherche
- Le nœud Elasticsearch ayant répondu à cette requête de recherche
- Quelques informations concernant le résultat de la recherche, tel que le code d’état
- Si une erreur s’est produite
- La recherche en tant que telle pour les opérations
_search
Dans un premier temps, nous avons décidé de prendre uniquement en charge les recherches synchrones, et de nous attaquer aux recherches asynchrones une fois que nous aurions une infrastructure adaptée.
J’ai extrait le code approprié, je l’ai chargé sur gist et j’y ai fait référence tout au long de cet article. Notez que, même s’il ne s’agit pas du code que vous trouverez sur notre référentiel GitHub, ce code est tout à fait fonctionnel et pertinent.
Aspects propres aux agents Java
Lorsque vous écrivez du code pour un agent Java, vous devez prendre en compte certaines considérations. Survolons-les brièvement avant de nous pencher sur notre scénario de test.
Instrumentation du bytecode
Pas d’affolement ! Vous n’aurez pas besoin d’écrire quoi que ce soit en bytecode. Pour cela, nous utilisons la bibliothèque magique Byte Buddy (qui, elle, s’appuie sur ASM). Nous nous servons, par exemple, des annotations pour indiquer ce qu’il faut injecter au début et à la fin de la méthode instrumentée. Rappelez-vous simplement que certaines parties de code que vous écrivez ne vont pas réellement s’exécuter là où vous les avez écrites, mais plutôt injectées sous forme de bytecode compilé dans le code d’une autre personne (ce qui représente un énorme avantage de l’open source : vous voyez précisément les parties du code qui sont injectées).

Visibilité sur les classes
Il s’agit peut-être du facteur le plus insaisissable, ainsi que celui qui présente le plus de pièges. Chacun doit avoir pleinement conscience de l’endroit à partir duquel chaque partie de code va être chargée et de celles qui peuvent être disponibles au moment de l’exécution. Lorsqu’un plug-in est ajouté, votre code sera chargé dans au moins deux endroits distincts : dans le contexte de la bibliothèque/application instrumentée et dans le contexte du code de l’agent principal. Par exemple, nous avons une dépendance avec HttpEntity, une classe du client HTTP Apache qui accompagne le client Elasticsearch. Étant donné que ce code est injecté dans l’une des classes du client, nous savons que cette dépendance est valide. En parallèle, lorsque vous utilisez IOUtils (une classe d’agent principal), les seules dépendances dont nous pouvons supposer l’existence sont celles du Java principal et de l’agent principal. Si vous n’avez pas l’habitude des concepts de chargement de classe Java, il peut être utile de vous faire une idée générale pour savoir de quoi il retourne (par exemple, en consultant cet aperçu très pratique).
Surcharge
Sujet suivant, et pas des moindres : les performances. Évidemment, personne ne veut écrire un code qui soit inefficace. Aussi, lorsque nous écrivons le code d’un agent, nous ne devons pas appliquer les compromis que nous avons l’habitude de faire lorsque nous écrivons du code. Nous devons être irréprochables dans tous les aspects. Pour illustrer ce propos, c’est comme si nous étions invités à une fête. On attend de nous que notre travail soit sans accrocs.
Pour en savoir davantage sur la surcharge des performances d’un agent et sur la façon d’y remédier, lisez cet article de blog très intéressant.
Simultanéité
En général, la première opération de traçage de chaque événement sera exécutée sur le thread de traitement des requêtes, qui fait partie des nombreux threads d’un pool. Nous devons intervenir dans une moindre mesure sur ce thread, et nous devons intervenir vite, pour laisser la place à des activités plus importantes. Les sous-produits de ces actions sont gérés dans des collections partagées, où ils sont exposés à des problèmes de simultanéité. Par exemple, l’objet Span (Intervalle) que nous créons au tout début est mis à jour plusieurs fois dans ce code sur le thread de traitement des requêtes, mais est utilisé plus tard aux fins de sérialisation et envoyé au serveur APM par un thread différent. De plus, nous devons savoir si nous traçons des opérations synchrones ou potentiellement asynchrones. Si notre trace est susceptible de démarrer dans un thread et de se poursuivre dans d’autres, nous devons tenir compte de ce point.
Mais revenons à nos moutons...
Vous trouverez ci-dessous une procédure de mise en œuvre du plug-in client REST Elasticsearch. Nous l’avons divisée en trois étapes dans un souci de praticité uniquement.
Attention : Côté technique, nous allons passer à la vitesse supérieure...
1ère étape : Sélection de ce qu’il faut instrumenter
Il s’agit de l’étape la plus importante de cette procédure. Si nous effectuons correctement quelques recherches, nous trouverons très certainement la ou les bonnes méthodes, que nous pourrons appliquer avec facilité. Aspects à prendre en compte :
- La pertinence : nous devons instrumenter des méthodes...
- ... qui capturent ce que nous voulons capturer avec exactitude. Par exemple, nous devons vérifier que, lorsque nous soustrayons l’heure de fin à l’heure de début de la méthode, nous obtenons la durée de l’intervalle que nous voulons créer.
- ... sans faux positifs. Si une méthode est appelée, c’est un aspect sur lequel nous nous pencherons systématiquement.
- ... sans faux négatifs. Méthode systématiquement appelée lorsque l’action relative à l’intervalle est exécutée.
- ...qui disposent toujours des informations pertinentes à l’entrée ou à la sortie.
- Compatibilité à venir nous souhaiterions obtenir une API centrale peu sujette aux changements. Nous n’avons pas envie de devoir mettre à jour notre code à chaque version mineure de la bibliothèque tracée.
- Rétro-compatibilité : jusqu’à quelle version la prise en charge de cette instrumentation remonte-t-elle ?
Je ne savais rien du code client (même s’il s’agissait de celui d’Elastic). J’ai néanmoins téléchargé la dernière version, qui était à l’époque la 6.4.1, et j’ai commencé à effectuer mes recherches. Le client Java REST Elasticsearch propose une API de haut niveau et une API de bas niveau. L’API de haut niveau dépend de celle de bas niveau. Et au final, toutes les recherches passent par l’API de bas niveau. Aussi, pour prendre en charge ces deux API, c’est tout naturellement que nous nous tournons vers le client de bas niveau.
En plongeant dans le code, j’ai identifié une méthode avec la signature Response performRequest(Request request) (ici dans GitHub). Il y a quatre autres alternatives pour la même méthode, qui l’appellent toutes et qui sont toutes marquées comme étant rejetées. De plus, cette méthode appelle performRequestAsyncNoCatch. La seule autre méthode qui appelle cet élément, c’est une méthode avec la signature void performRequestAsync(Request request, ResponseListener responseListener). Poussons encore davantage nos recherches et nous nous constatons que le chemin asynchrone est identique au chemin synchrone : quatre autres alternatives rejetées appellent une méthode valide qui appelle performRequestAsyncNoCatch pour formuler la requête réelle. Aussi, du point de vue de la pertinence, la méthode performRequest obtient un score de 100 %, car elle capture toutes les requêtes et uniquement les requêtes synchrones. De plus, elle dispose des informations de requête et de réponse à l’entrée et à la sortie. En bref, c’est la méthode parfaite ! Pour dire à Byte Buddy que nous voulons instrumenter cette méthode, nous remplaçons les méthodes correspondantes appropriées.

Si nous regardons vers l’avenir, cette nouvelle API centrale est un bon pari en termes de stabilité. Si nous regardons en arrière, par contre, ce choix n’était pas si bon que ça... La version 6.4.0 et les versions antérieures n’avaient pas cette API.
Étant donné qu’il s’agissait d’une candidate idéale pour l’instrumentation, j’ai décidé de l’utiliser et de bénéficier d’un support technique durable pour le client REST Elasticsearch, et d’ajouter une instrumentation additionnelle aux anciennes versions. J’ai procédé de façon similaire pour y identifier un candidat. Résultat : je me suis retrouvé avec deux solutions, l’une pour les versions 5.0.2 jusqu’à 6.4.0, et une autre pour les versions supérieures à 6.4.0.
2e étape : Conception du code
Nous utilisons Maven, et chaque nouvelle instrumentation que nous mettons en place pour prendre en charge une nouvelle technologie sera un module que nous désignerons par plug-in. Dans mon cas, je souhaitais tester aussi bien l’ancien client REST Elasticsearch que le nouveau (impliquant de fait des dépendances client conflictuelles). Et comme l’instrumentation était légèrement différente de l’un à l’autre, il faisait sens que chacun dispose de son propre module/plug-in. Étant donné que ces deux clients servent à prendre en charge la même technologie, je les ai imbriqués dans un module parent commun, avec la structure suivante :
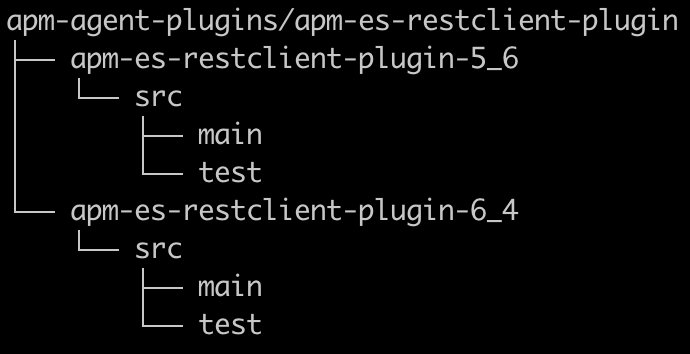
Il est important que seul le code de plug-in réel soit packagé dans l’agent. Veillez donc à ce que les dépendances de bibliothèque soient appliquées en tant queprovided et que les dépendances test soient appliquées en tant que test dans votre fichier pom.xml. Si vous ajoutez du code tiers, celui-ci doit être repackagé pour utiliser le nom de package de l’agent Java Elastic APM root.
En ce qui concerne le code actuel, voici les exigences minimales à prendre en compte pour l’ajout d’un plug-in :
La classe Instrumentation
Une mise en œuvre de la classe ElasticApmInstrumentation abstraite. Elle a pour rôle d’aider à identifier la classe et la méthode appropriées pour l’instrumentation. Étant donné que la correspondance type-méthode peut considérablement allonger les temps de démarrage de l’application, la classe Instrumentation fournit des filtres qui améliorent le processus de mise en correspondance. Vous pouvez par exemple passer outre les classes qui ne contiennent pas une certaine chaîne dans leur nom ou les classes chargées par un système qui n’a aucune visibilité sur le type que nous recherchons. Par ailleurs, cette classe fournit des méta-informations qui permettent d’activer/de désactiver l’instrumentation sur la configuration.
Remarque : ElasticApmInstrumentation est utilisé en tant que service, ce qui signifie que chaque mise en œuvre doit être répertoriée dans un fichier de configuration fournisseur.
Le fichier de configuration fournisseur de service
Votre mise en œuvre ElasticApmInstrumentation est un fournisseur de service, identifié dans l’exécution par un fichier de configuration fournisseur situé dans le référentiel de ressources META-INF/services. Le nom du fichier de configuration fournisseur est le nom qualifié complet du service et il contient une liste de noms qualifiés complets de fournisseurs de service (un par ligne).
La classe Advice
Il s’agit de la classe qui fournit le code réel qui sera injecté dans la méthode tracée. Elle ne met pas en œuvre une interface commune, mais utilise normalement les annotations @Advice.OnMethodEnter et/ou @Advice.OnMethodExit de Byte Buddy. C’est en procédant ainsi que nous indiquons à Byte Buddy le code que nous souhaitons ajouter au début d’une méthode, et juste avant de la quitter (silencieusement ou à l’aide d’un Throwable). L’API Byte Buddy enrichie nous permet de réaliser des actions sophistiquées, comme :
- Créer une variable locale à l’entrée de la méthode qui sera disponible à la sortie de la méthode.
- Observer et remplacer si besoin un argument de méthode, la valeur renvoyée ou le
Throwable. - Observer
cetobjet.
Pour finir, la structure de mon module client REST Elasticsearch se présente comme suit :
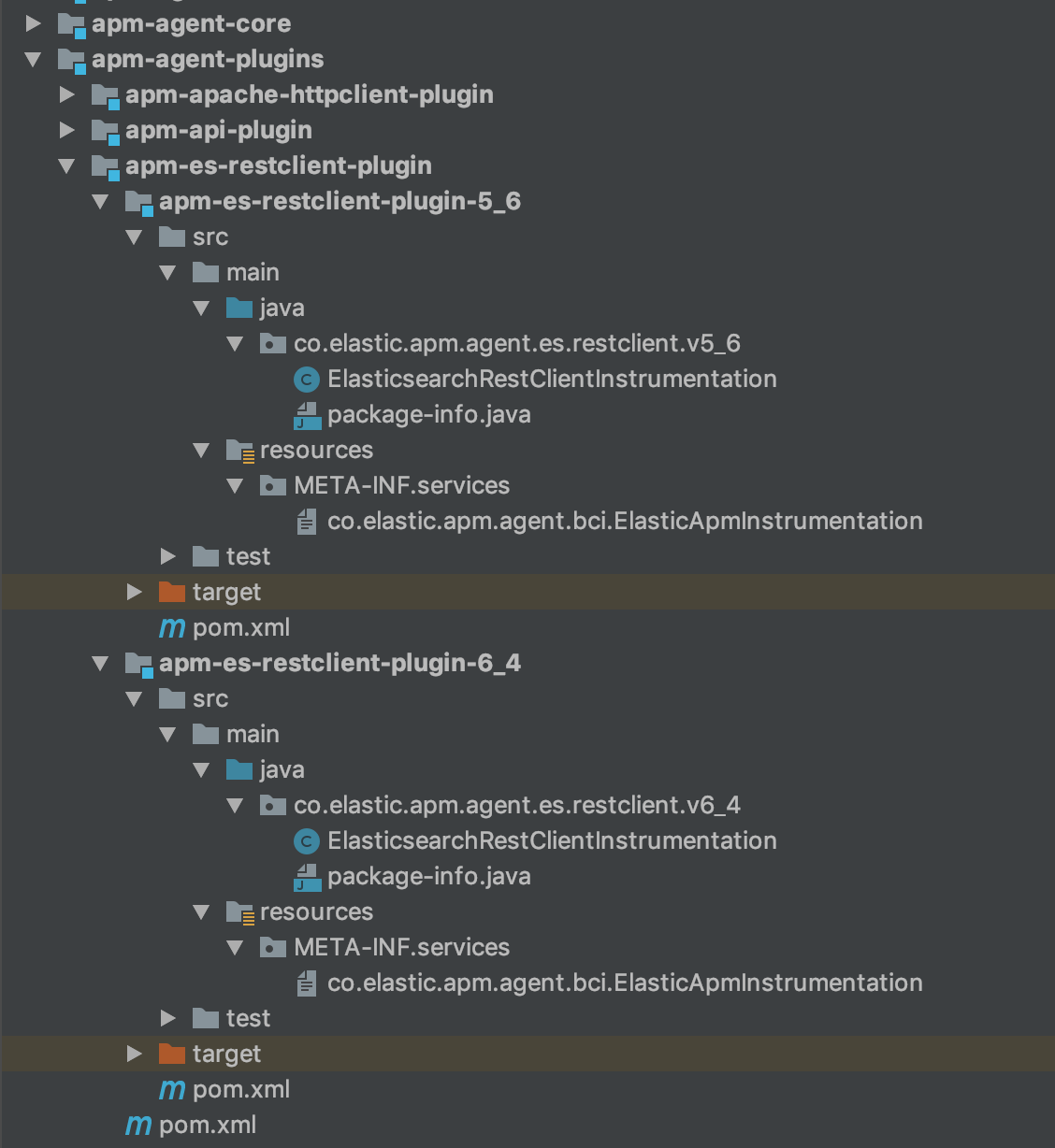
3e étape : Mise en œuvre
Comme indiqué précédemment, l’écriture d’un code d’agent comporte des spécificités. Voyons comment ces concepts se manifestent dans ce plug-in :
Création de l’intervalle et maintien
Elastic APM utilise des intervalles pour refléter chaque événement digne d’intérêt, comme la gestion d’une requête HTTP, la recherche dans une base de données, un appel à distance, etc. L’intervalle root à la base d’une arborescence enregistrée par un agent s’appelle une Transaction (consultez notre documentation sur les modèles de données pour en savoir plus). Dans le cas présent, nous utilisons un objet Span (Intervalle) pour décrire la recherche Elasticsearch, étant donné qu’il ne s’agit pas de l’événement root enregistré dans le service. Comme ici, un plug-in va créer un intervalle, l’activer, y ajouter des données, et pour finir, le désactiver et y mettre fin. L’activation et la désactivation sont les actions qui consistent à assurer le maintien d’un état contextuel au thread pour pouvoir obtenir l’intervalle actif n’importe où dans le code (comme nous le faisons lorsque nous créons l’intervalle). Un intervalle doit prendre fin, et un intervalle activé doit être désactivé. De ce fait, une bonne pratique consiste à utiliser try/finally. Autre point : si une erreur se produit, nous devons la signaler.
Ne jamais casser le code utilisateur (et éviter les effets secondaires)
En plus d’écrire un code très “défensif”, nous partons toujours du principe que notre code peut générer des exceptions. C’est pourquoi nous utilisons suppress = Throwable.class dans notre code advice. Cela indique à Byte Buddy d’ajouter un gestionnaire d’exceptions pour tous les types Throwable lancés lors de l’exécution du code advice. Ainsi, le code utilisateur continuera à s’exécuter même si le code injecté échoue.
Nous devons également nous assurer de ne pas générer d’effets secondaires avec notre code advice qui pourraient modifier l’état du code instrumenté, et de là, en affecter le comportement. Dans mon cas, c’était ce qu’il fallait faire pour lire le corps de la requête des recherches Elasticsearch. Pour y parvenir, il faut obtenir le flux de contenu de la requête par l’intermédiaire d’une API getContent. Certaines mises en œuvre de cette API renverront une nouvelle instanceInputStream pour chaque invocation, alors que d’autres renverront la même instance pour plusieurs invocations par requête. Étant donné que nous savons uniquement quelle est la mise en œuvre utilisée au moment de l’exécution, nous devons vérifier que la lecture du corps n’empêchera pas la lecture par le client. Heureusement, il y a également une API isRepeatable qui nous l’indique. Notez toutefois que si vous ne respectez pas cette procédure, vous risquez de nuire à la fonctionnalité du client.
Visibilité sur les classes
Par défaut, la classe Instrumentation est aussi la classe Advice. Il existe néanmoins une énorme différence entre ces classes par rapport au rôle qu’elles jouent. Les méthodes Instrumentation sont toujours invoquées, et ça, peu importe que la bibliothèque correspondante soit disponible ou non, voire même utilisée. En parallèle, le code Advice est utilisé uniquement lorsque la classe appropriée d’une bibliothèque spécifique a été détectée. Mon code Advice a des dépendances avec le code client REST Elasticsearch pour obtenir des informations telles que l’URL utilisée pour la requête, le corps de la requête, le code de réponse, etc. De ce fait, il serait plus prudent de compiler le code Advice dans une classe distincte et d’y faire référence uniquement par la classe Instrumentation au besoin. Notez que, bien souvent, le code Advice aura des dépendances avec la bibliothèque instrumentée. Il peut donc s’agir d’une bonne pratique à appliquer, de façon générale.
Considérations relatives à la surcharge des performances
L’une des choses que nous souhaitions faire, c’était d’obtenir des recherches _search, ce qui impliquait de lire le corps de la requête HTTP auquel nous avions accès sous la forme d’InputStream. Mais nous devons stocker le contenu du corps quelque part, et ça, nous ne pouvons pas y faire grand chose. Aussi, la surcharge de mémoire serait d’au moins la longueur du corps que nous autorisons à lire pour chaque requête tracée. Par contre, il y a beaucoup à faire au niveau des attributions de mémoire, converties en processeur ou en pauses en raison du fait de la récupération de mémoire. C’est pourquoi nous réutilisons ByteBuffer pour copier les octets lus à partir du flux, CharBuffer pour stocker le contenu de la recherche jusqu’à ce qu’elle soit sérialisée et envoyée au serveur APM, et même CharsetDecoder. En procédant ainsi, nous n’attribuons pas la mémoire, ni ne supprimons les attributions en fonction des requêtes. Cela permet de réduire la surcharge au profit d’un code un peu plus complexe (code dans la classe IOUtils).
Résultat final
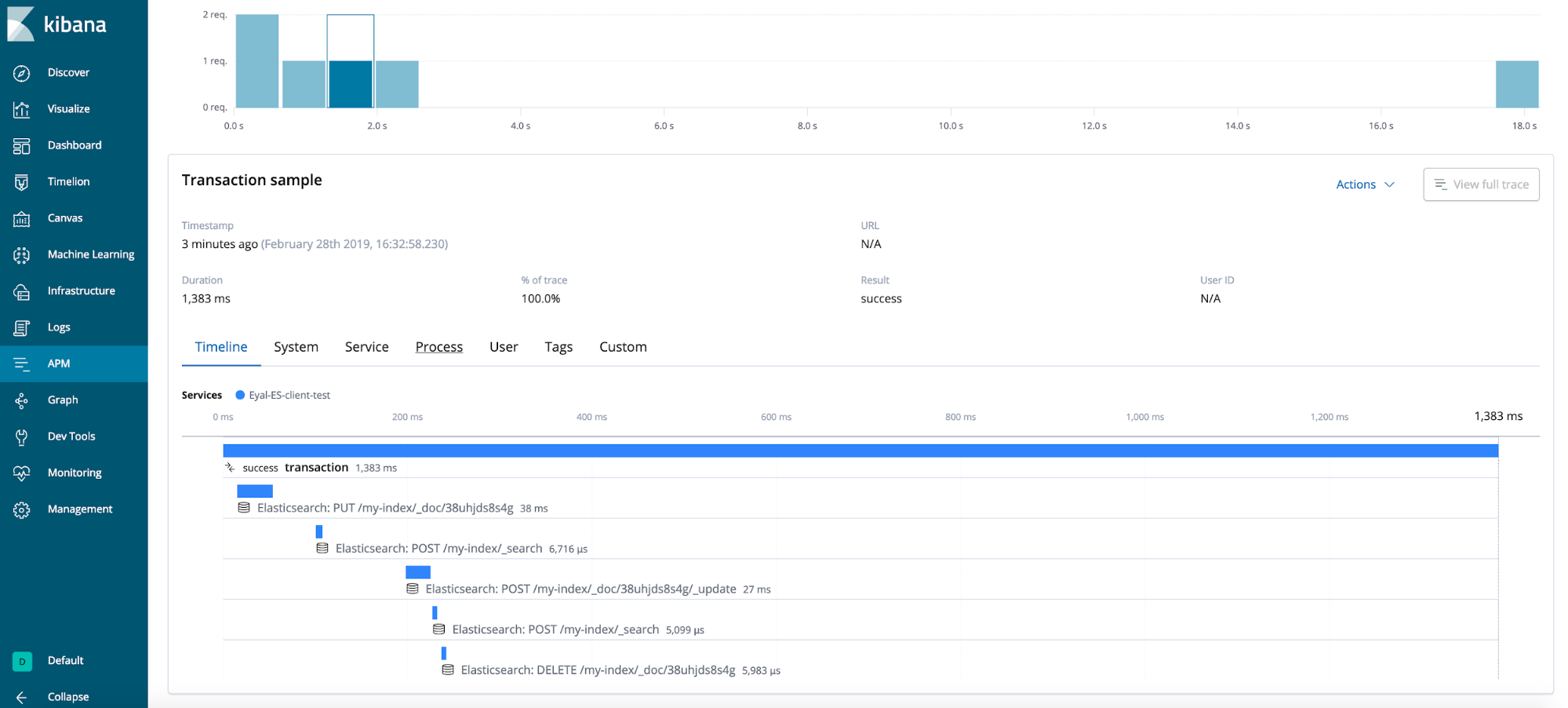
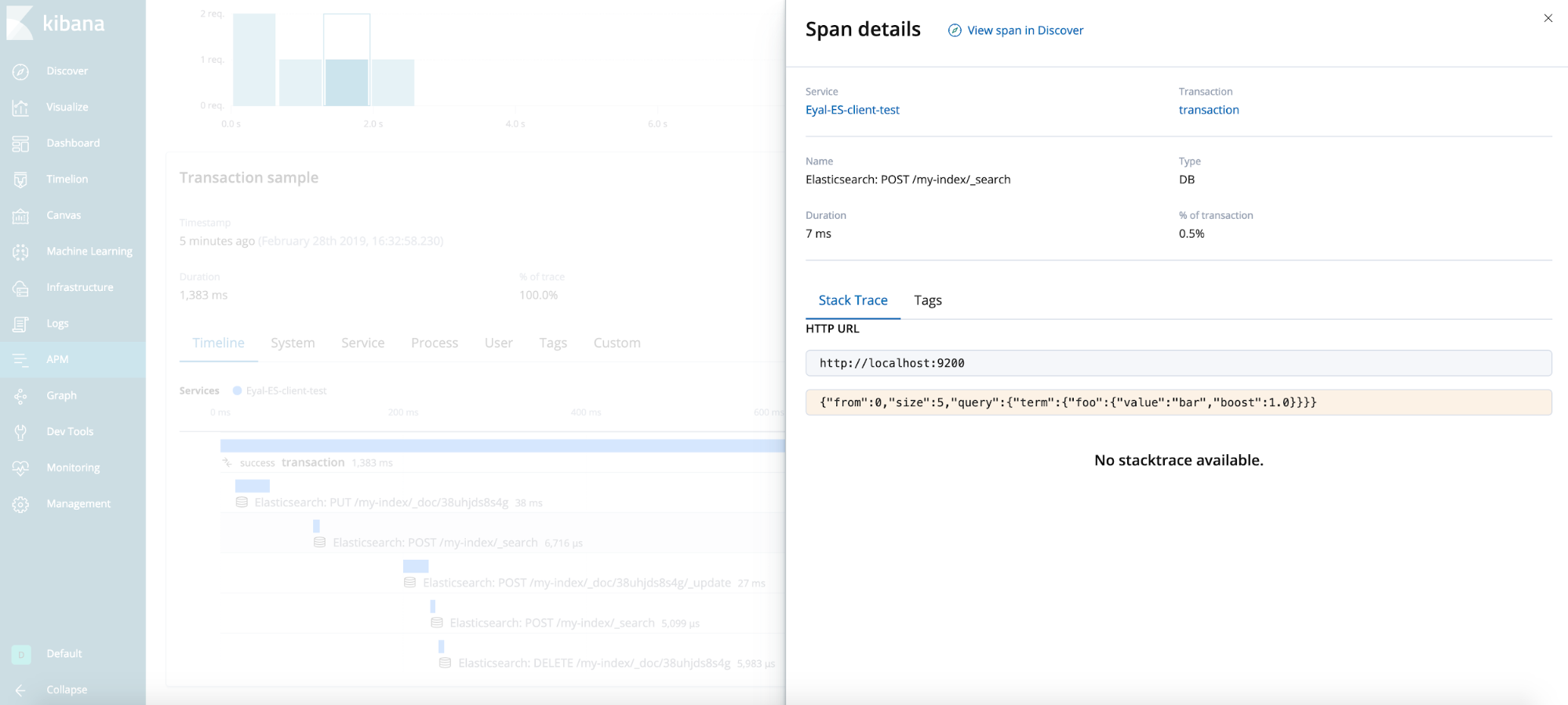
Conseils généraux (non illustrés dans le scénario de test)
Attention aux appels imbriqués
Dans certains cas, lorsque vous instrumentez des méthodes API, vous pouvez tomber sur un scénario dans lequel une méthode instrumentée appelle une autre méthode instrumentée. Par exemple, une méthode alternative qui appelle sa super-méthode, ou une mise en œuvre d’API qui en englobe une autre. Il est essentiel d’avoir conscience que de tels cas peuvent se produire, afin qu’il n’y ait pas plusieurs intervalles signalés pour la même action. À la question de savoir quand une situation comme celle-ci peut se produire, il n’y a pas de règles. Selon le scénario ou les paramètres, le comportement peut être différent. Nous vous recommandons de ce fait de coder en ayant conscience de cette éventualité.
Attention à l’auto-monitoring
Veillez à ce que votre code de traçage ne provoque pas l’invocation d’autres actions qui seront aussi tracées. Dans le meilleur cas, ce sont les opérations tracées qui seront signalées, plutôt que le résultat du processus de traçage en tant que tel. Dans le pire des cas, c’est la suite tout entière qui peut se retrouver surchargée. Prenons l’exemple du traçage JDBC : lorsque nous essayons d’obtenir des informations de la base de données, nous utilisons l’API java.sql.Connection#getMetaData, ce qui peut lancer une recherche tracée sur la base de données, entraînant une autre invocation de java.sql.Connection#getMetaData, etc.
Attention aux opérations asynchrones
Une exécution asynchrone implique qu’un intervalle ou une transaction soit créé(e) dans un thread, puis qu’il/elle soit activé(e) dans un autre thread. Chaque intervalle ou transaction peut prendre fin très exactement une fois, et peut être désactivé(e) uniquement dans chaque fil où il/elle a été activé(e). Il faut donc garder systématiquement ce point à l’esprit.