3 bonnes pratiques de l'utilisation et du dépannage de l'API de réindexation


 Share on Twitter
Share on TwitterPartager sur Twitter

 Share on LinkedIn
Share on LinkedInPartager sur LinkedIn

 Share on Facebook
Share on FacebookPartager sur Facebook

 Share by Email
Share by EmailPartage par e-mail

 Print this page
Print this pageImprimer
Lorsque vous utilisez Elasticsearch, votre intention peut être de déplacer des données d'un index à un autre, voire d'un cluster Elasticsearch à un autre. Dans cette optique, vous pouvez utiliser plusieurs variations et fonctionnalités, notamment l'API de réindexation.
Dans cet article, je vous présente l'API de réindexation, mais aussi je vous explique comment savoir si elle fonctionne correctement, ce qui génère les éventuelles défaillances et les techniques de dépannage.
Après avoir lu cet article, vous comprendrez les possibilités offertes par l'API de réindexation et saurez l'exécuter l'esprit tranquille.
L'API de réindexation est l'une des API les plus utiles pour de nombreux cas d'utilisation :
- transfert de données entre clusters (réindexation à partir d'un cluster distant) ;
- redéfinition, modification ou actualisation de mappings ;
- traitement et indexation à l'aide de pipelines d'ingestion ;
- élimination des documents supprimés pour récupérer de l'espace de stockage ;
- division des grands index en plus petits groupes à l'aide de filtres de requête.
Lorsque vous exécutez l'API de réindexation dans des index moyens ou grands, il est possible que la réindexation complète dure plus de 120 secondes. Par conséquent, vous n'obtenez pas la réponse finale de l'API, vous ne savez pas quand l'opération sera terminée, si elle a fonctionné ou si des défaillances sont survenues.
Regardons tout cela en détail.
Symptôme : dans les outils de développement Kibana, "connexion fermée dans le back-end"
Lorsque vous exécutez l'API de réindexation avec des index moyens ou grands, la connexion entre le client et Elasticsearch va expirer, ce qui ne signifie pas que la réindexation ne s'exécutera pas.
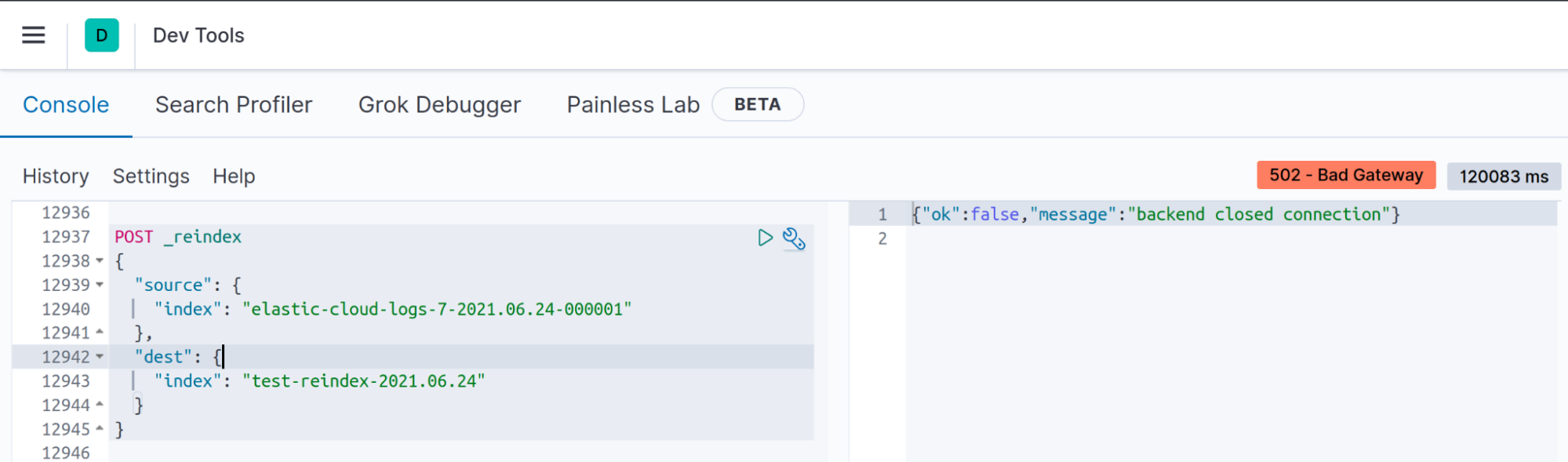
Problème
Votre client ferme les sockets inactifs au bout de N secondes. Dans Kibana, par exemple, si l'opération de réindexation ne peut pas se terminer en moins de 120 secondes (soit la valeur par défaut de server.socketTimeout dans la version 7.13), le message " connexion fermée dans le back-end" s'affiche.
Solution no 1 : obtenir la liste des tâches exécutées dans le cluster
Il ne s'agit pas d'un vrai problème : même si ce message s'affiche dans Kibana, Elasticsearch exécute l'API de réindexation en arrière-plan.
Vous pouvez suivre l'exécution de l'API de réindexation et consulter l'ensemble des indicateurs grâce à l'API _task.
GET _tasks?actions=*reindex&wait_for_completion=false&detailedCette API vous montre toutes les exécutions réalisées actuellement par l'API de réindexation dans le cluster Elasticsearch. Si votre API de réindexation n'apparaît pas dans cette liste, cela signifie que les opérations sont déjà terminées.

Comme vous pouvez le voir dans l'image ci-dessus, vous obtenez des informations sur les documents créés et actualisés, voire les conflits.
Solution no 2 : stocker les résultats de la réindexation dans l'API _tasks
Si vous savez que l'opération de réindexation va durer plus de 120 secondes (soit le délai d'expiration des outils de développement Kibana), vous pouvez stocker les résultats de l'API de réindexation à l'aide du paramètre de requête wait_for_completion= false. Ainsi, vous en obtenez l'état une fois que l'API de réindexation a terminé sa tâche grâce à l'API _task. (Vous pouvez également obtenir le document depuis l'index ".tasks", comme cela est expliqué dans la documentation du paramètre wait_for_completion=false.)
POST _reindex?wait_for_completion=false
{
"conflicts": "proceed",
"source": {
"index": "<source-index-name>"
},
"dest": {
"index": "<dest-index-name>"
}
}
Lorsque vous exécutez la réindexation avec le paramètre "wait_for_completion=false", vous obtenez une réponse similaire à ce qui suit.
{
"task" : "a9Aa_I_ZSl-4bjR5vZLnSA:247906"
}
Vous devez conserver la tâche fournie ici afin d'obtenir les résultats de la réindexation. (Vous verrez s'afficher le nombre de documents créés, les conflits, voire les erreurs. Une fois l'opération terminée, s'affichent sa durée, le nombre de lots et d'autres informations.)
GET _tasks/a9Aa_I_ZSl-4bjR5vZLnSA:247906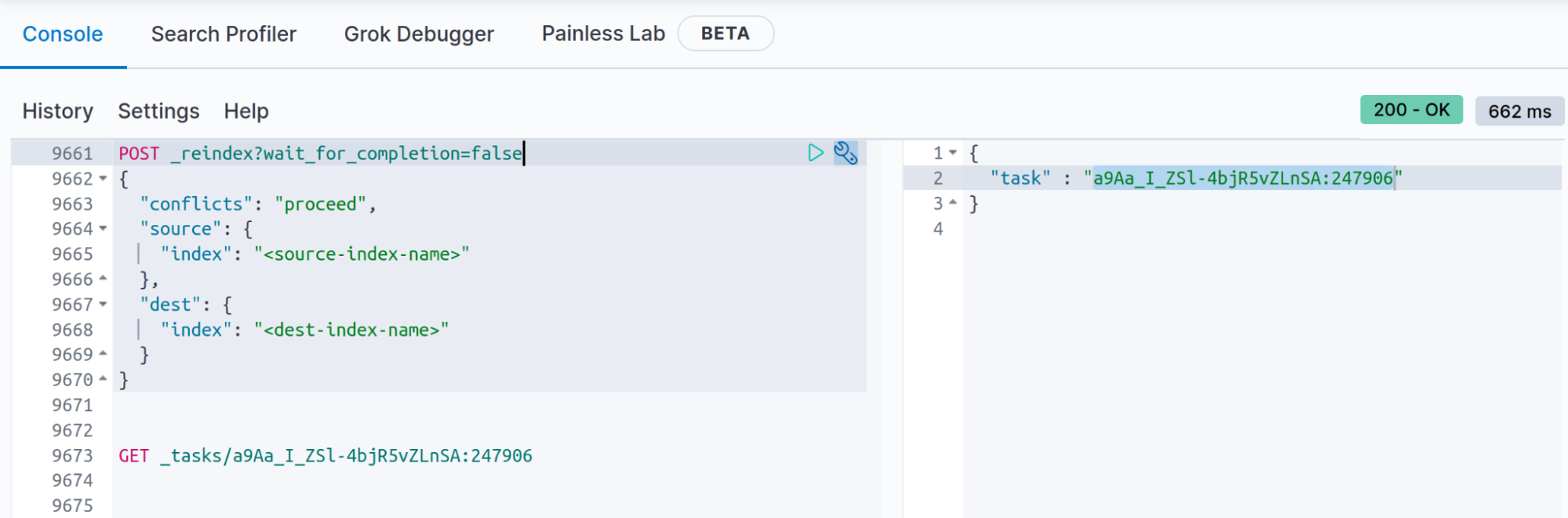
Symptôme : votre API de réindexation n'apparaît pas dans la liste de l'API _task
Si vous utilisez l'API susmentionnée et ne trouvez pas l'opération de votre API de réindexation, cela pourrait être le signe de plusieurs problèmes. Passons-les en revue un par un.
Problème
Si l'API de réindexation ne s'affiche pas, cela signifie que son exécution est terminée, car plus aucun document n'a besoin d'être réindexé ou une erreur est survenue.
Nous utiliserons l'API de comptabilisation _cat pour connaître le nombre de documents stockés dans les deux index. Si ce nombre est différent du résultat escompté, cela signifie que l'exécution de votre API de réindexation a échoué.
GET _cat/count/<source-index-name>?h=count
GET _cat/count/<dest-index-name>?h=count
Vous devrez remplacer
Solution no 1 : il s'agit d'un problème de conflit
Une des erreurs les plus courantes est la présence de conflits. Par défaut, l'API de réindexation s'interrompt si un conflit survient.
Dans ce cas, deux possibilités s'offrent à vous :
- Configurez le paramètre "conflicts" (conflits) sur "proceed" (continuer), ce qui autorise l'API à ignorer les documents ne pouvant être indexés et à indexer les autres.
- Vous pouvez également résoudre les conflits afin de réindexer l'ensemble des documents.
La première possibilité fondée sur le paramètre "conflicts" ressemble à ce qui suit.
POST _reindex
{
"conflicts": "proceed",
"source": {
"index": "<source-index-name>"
},
"dest": {
"index": "<dest-index-name>"
}
}
Avec la seconde possibilité, il faut rechercher et corriger les erreurs générant le conflit :
- La bonne pratique qui vous permet d'éviter ce problème définit un mapping ou un modèle dans l'index de destination. Dans 99 % des cas, ces erreurs proviennent de types de champs qui ne sont pas identiques entre l'index d'origine et la destination.
- Si le problème persiste après avoir défini le mapping ou un modèle, cela signifie que certains documents ne pourraient pas être indexés et que l'erreur ne sera pas enregistrée par défaut. Nous devons activer le logger pour que les erreurs s'affichent dans les logs Elasticsearch.
PUT /_cluster/settings
{
"transient": {
"logger.org.elasticsearch.action.bulk.TransportShardBulkAction":"DEBUG"
}
}
- Une fois le logger activé, nous devons exécuter l'API de réindexation une nouvelle fois, si possible en configurant le paramètre "conflicts" sur "proceed", car des conflits émergent souvent dans plusieurs champs entre l'index source et l'index de destination.
- À présent que l'API de réindexation s'exécute, nous exécuterons la commande grep/mènerons une recherche dans les logs "failed to execute bulk item" (Impossible d'exécuter l'élément de manière groupée) ou "MapperParsingException".
failed to execute bulk item (index) index {[my-dest-index-00001][_doc][11], source[{
"test-field": "ABC"
}
Ou
"org.elasticsearch.index.mapper.MapperParsingException: failed to parse field [test-field] of type [long] in document with id '11'. Preview of field's value: 'ABC'",
"at org.elasticsearch.index.mapper.FieldMapper.parse(FieldMapper.java:216) ~[elasticsearch-7.13.4.jar:7.13.4]",
Grâce à cette trace de stack, nous disposons de suffisamment d'informations pour comprendre la nature du conflit. Dans mon API de réindexation, l'index de destination est doté d'un champ intitulé [test-field] de type [long], et l'API essaie de configurer ce champ selon une chaîne "ABC". (Ces lettres seront remplacées par votre champ de contenu.)
Dans Elasticsearch, vous pouvez définir des types de données de champ, puis le configurer lors de la création d'index ou de l'utilisation de modèles. Vous ne pouvez pas modifier les types une fois l'index créé. Dans ce cas, vous devrez tout d'abord supprimer l'index de destination, puis configurer le nouveau mapping fixé à l'aide des options fournies auparavant.
- Une fois que vous avez éliminé les erreurs, n'oubliez pas de configurer le logger sur un mode moins détaillé.
PUT /_cluster/settings
{
"transient": {
"logger.org.elasticsearch.action.bulk.TransportShardBulkAction":NULL
}
}
Solution no 2 : vous ne rencontrez aucune erreur due à un conflit, mais la réindexation échoue toujours
Si, lors de l'exécution de la réindexation, la trace ci-dessous apparaît dans vos logs Elasticsearch :
'search_phase_execution_exception', 'No search context found for id [....]')
La situation peut s'expliquer de différentes manières :
- Le cluster rencontre des problèmes d'instabilité et certains nœuds de données ont été redémarrés ou indisponibles lors de l'exécution de la réindexation.
S'il s'agit bien du problème, avant d'exécuter la réindexation, veillez à ce que votre cluster soit stable et que tous les nœuds de données fonctionnent correctement. - Si vous exécutez une opération de réindexation à distance et si vous savez que le réseau entre les nœuds n'est pas fiable :
- L'API de snapshot est une très bonne solution (comme expliqué dans la conclusion de cet article).
- Nous pouvons essayer d'analyser manuellement l'API de réindexation. Cette opération vous permettra de décomposer le processus de requête en plus petits éléments. (Nous avons recours à cette option quand nous utilisons l'API de réindexation dans le même cluster.)
Si votre cluster Elasticsearch rencontre des problèmes liés au nombre excessif de partitions, à une consommation élevée de ressources ou à la récupération de mémoire, nous pouvons nous confronter à des expirations lors de la requête de recherche de défilement. La valeur par défaut pour l'expiration du défilement est 5 minutes. Par conséquent, vous pouvez essayer le paramètre de défilement dans l'API de réindexation avec une valeur supérieure.
POST _reindex?scroll=2h
{
"source": {
"index": "<source-index-name>"
},
"dest": {
"index": "<dest-index-name>"
}
}
Symptôme : le message "Nœud non connecté" s'affiche dans vos logs Elasticsearch
Nous conseillons toujours d'exécuter l'API de réindexation avec un cluster stable dont le voyant est vert. Le cluster aura besoin d'une capacité suffisante pour exécuter des recherches et des index.
Problème
NodeNotConnectedException[[node-name][inet[ip:9300]] Node not connected]; ]
Si vous rencontrez cette erreur dans vos logs, cela signifie que votre cluster a des problèmes de stabilité et de connectivité. En outre, l'échec ne concerne pas seulement l'API de réindexation.
Toutefois, imaginons que vous connaissez ces problèmes de connectivité, mais avez besoin d'exécuter l'API de réindexation.
Solution
Résolvez les problèmes de connectivité.
Imaginons que nous connaissons ces problèmes de connectivité, mais que vous avez besoin d'exécuter l'API de réindexation. Nous pouvons réduire les risques d'échec. Cependant, il ne s'agit pas d'une résolution. Cette option ne fonctionnera donc pas dans tous les cas.
- Déplacez les partitions dans l'index source ou de destination (qu'il s'agisse d'une réplique ou d'un index principal). Ainsi, elles sont extraites des nœuds rencontrant des problèmes de connectivité. Utilisez l'API de filtrage d'allocation pour déplacer les partitions.
- Vous pouvez également supprimer les répliques dans l'index de destination (uniquement dans cet index). Ainsi, l'API de réindexation gagne en vitesse. Si la réindexation s'exécute plus rapidement, les risques de défaillance diminuent.
PUT /<dest-index-name>/_settings
{
"index" : {
"number_of_replicas" : 0
}
}
Si ces deux actions ne vous ont pas permis d'exécuter correctement l'API de réindexation, vous devez commencer par régler le problème de stabilité.
Symptôme : pas d'erreurs dans les logs, mais un mauvais nombre de documents pour chaque index
Parfois, l'API de réindexation s'est exécutée, mais le nombre de documents dans l'index d'origine ne correspond pas à celui de destination.
Problème
Si nous essayons de réindexer à partir de plusieurs sources dans une seule destination (c'est-à-dire fusionner plusieurs index en un), le problème pourrait provenir de l'_id que vous avez attribué à ces documents.
Imaginons que nous disposons de 2 index sources :
- l'index A, avec l'_id 1 et le message "Hello A" (Bonjour A) ;
- l'index B, avec l'_id 1 et le message "Hello B" (Bonjour B).
Si ces deux index sont fusionnés dans l'index C, nous aurons alors :
- l'index C, avec l'_id 1 et le message "Hello B" (Bonjour B).
Les deux documents auront le même _id. Ainsi, le dernier document indexé remplacera le précédent.
Solution
Vous disposez de plusieurs possibilités avec les pipelines d'ingestion ou pouvez utiliser Painless dans votre API de réindexation. Dans le cadre de cet article, nous utiliserons l'option de script avec "Painless" dans le corps de la requête.
C'est très facile : il nous suffit d'utiliser l'_id originel et d'ajouter le nom de l'index source.
POST _reindex
{
"source": {
"index": "<source-index-name>"
},
"dest": {
"index": "<dest-index-name>"
},
"script": {
"source": "ctx._id = ctx._id + '-' + ctx._index;"
}
}
Et si nous prenons notre exemple précédent :
- l'index A, avec l'_id 1 et le message "Hello A" (Bonjour A) ;
- l'index B, avec l'_id 1 et le message "Hello B" (Bonjour B).
Si ces deux index sont fusionnés dans l'index C, nous aurons alors :
- l'index C, avec l'_id 1-A et le message "Hello A" (Bonjour A) ;
- l'index C, avec l'_id 1-B et le message "Hello B" (Bonjour B).
Conclusion
L'API de réindexation est une très bonne solution lorsque vous devez modifier le format de certains champs. Voici les principaux aspects qui permettent à l'API de réindexation de fonctionner le plus facilement possible :
- Créez et définissez un mapping (ou un modèle) pour votre index de destination.
- Réglez l'index de destination pour que l'API de réindexation puisse indexer les documents aussi rapidement que possible. Nous avons conçu une page de documentation sur laquelle nous répertorions toutes les possibilités qui vous permettent de régler et d'accélérer l'indexation.
https://www.elastic.co/guide/en/elasticsearch/reference/current/tune-for-indexing-speed.html - Si l'index source est moyen ou grand, configurez le paramètre "wait_for_completion=false" afin que les résultats de l'API de réindexation soient stockés dans l'API _tasks.
- Divisez votre index en groupes plus petits. Vous pouvez définir plusieurs groupes à l'aide d'une requête (plage, mots, etc.) ou décomposez la requête en plus petits éléments grâce à la fonctionnalité dédiée.
- La stabilité est essentielle lors de l'exécution de l'API de réindexation. Les voyants des index qui ne sont pas impliqués dans l'API doivent être verts (ou jaunes dans le pire des cas). Ensuite, veillez à ne pas avoir de longues récupérations de mémoire dans les nœuds de données, mais aussi que l'utilisation du processeur et du disque présente des valeurs normales.
Depuis la version 7.11, nous avons lancé une nouvelle fonctionnalité qui vous permet d'éviter de réindexer vos données. Elle s'appelle "champs d'exécution". Grâce à cette API, vous pouvez résoudre les erreurs sans réindexer vos données, comme vous pouvez définir les champs d'exécution dans le mapping d'index ou dans la requête de recherche. Ces deux options vous confèrent la flexibilité nécessaire pour modifier le schéma d'un document après avoir ingéré et généré des champs existant seulement partiellement dans la requête de recherche.
Un bon exemple des fonctionnalités des champs d'exécution est la capacité à créer un champ d'exécution doté du même nom qu'un champ existant déjà dans le mapping. Le champ d'exécution masque le champ mappé. Pour le tester, vous devez simplement suivre les étapes expliquées sur cette page.
Vous pouvez obtenir de plus amples informations sur les champs d'exécution en consultant notre documentation ou en lisant cet article dédié aux premiers pas avec ces éléments.
Quand vous essayez de déplacer les données d'un cluster à un autre, vous pouvez utiliser l'API de snapshot et de restauration. En utilisant les snapshots, vous pouvez déplacer les données plus rapidement, car le cluster n'a pas besoin de les rechercher. Ensuite, vous pouvez réindexer les données. Vous devez vous assurer que les deux clusters ont accès au même référentiel de snapshots. Pour en savoir plus sur l'API de snapshot, cliquez ici.
Nous avons passé en revue les questions fréquentes sur la réindexation et les solutions courantes aux erreurs. Si vous ne parvenez pas à résoudre un problème, n'hésitez pas à nous écrire. Nous serons très heureux de vous aider ! Vous pouvez nous contacter sur les forums de discussion Elastic, sur le canal Slack de la communauté Elastic, ou encore par le biais des équipes de consulting, de formation et de support technique.
Partager
- Share on Twitter
Partager sur Twitter
- Share on LinkedIn
Partager sur LinkedIn
- Share on Facebook
Partager sur Facebook
- Share by Email
Partage par e-mail
- Print this page
Imprimer