Novedades en Elastic Observability 7.11: Página de visión general de estado del servicio de APM y biblioteca de logging de ECS a disposición del público en general
Nos complace anunciar la versión 7.11 de Elastic Observability, que incluye varias características que aceleran los flujos de trabajo de investigación y reducen el tiempo promedio hasta la información (MTTI) y el tiempo promedio de resolución (MTTR) en todos los casos de uso de observabilidad. La nueva página de visión general del servicio en Elastic APM agrega aspectos clave del estado del servicio en una vista única, lo cual permite a los desarrolladores e ingenieros de confiabilidad resolver rápidamente problemas del servicio e identificar la causa raíz con un cambio de contexto mínimo. De manera similar, la app Metrics agrega una vista mejorada que presenta el estado del host en un único panel al alcance de tu mano, lo que optimiza los flujos de trabajo de solución de problemas y monitoreo de infraestructura. Por último, ya están a disposición del público en general las bibliotecas de logging de Elastic Common Schema (ECS), que introducen de forma automática el contexto de rastreo en los logs de aplicaciones para permitir la correlación log ↔ rastreo.
Experimenta la versión más reciente de Elastic Observability en nuestro Elasticsearch Service en Elastic Cloud (hay disponible una prueba gratuita de 14 días) o instala la versión más reciente del Elastic Stack para una experiencia autogestionada.
Y ahora, sin más preámbulos, estos son algunos de los aspectos destacados de esta versión.
Nueva visión general del estado del servicio en Elastic APM acelera el análisis de la causa raíz y la solución de problemas
Las aplicaciones nativas del cloud modernas suelen estar compuestas de decenas o cientos de microservicios. La capacidad de identificar rápidamente el estado de un servicio individual es fundamental para un flujo de trabajo de investigación de incidentes y puede ayudar a disminuir el MTTI/MTTR. Por ejemplo, un mapa de servicios puede ayudarte a relacionar un problema de una aplicación con un servicio específico, pero necesitas descubrir por qué el servicio no se comporta correctamente. En la versión 7.11, presentamos una nueva página de visión general del servicio en la que se resume toda la información sobre el estado de un servicio en un solo lugar; esto facilita a los desarrolladores e ingenieros de confiabilidad de sitios (SRE) la tarea de responder estos "por qué" en una página:
- ¿Cómo afectó un despliegue nuevo el rendimiento?
- ¿Cuáles son las transacciones más afectadas?
- ¿Los servicios posteriores o backends introducen la regresión?
- ¿Cómo se correlaciona el rendimiento con la infraestructura subyacente? ¿En qué instancias (contenedores, VM) ocurren los problemas de rendimiento?
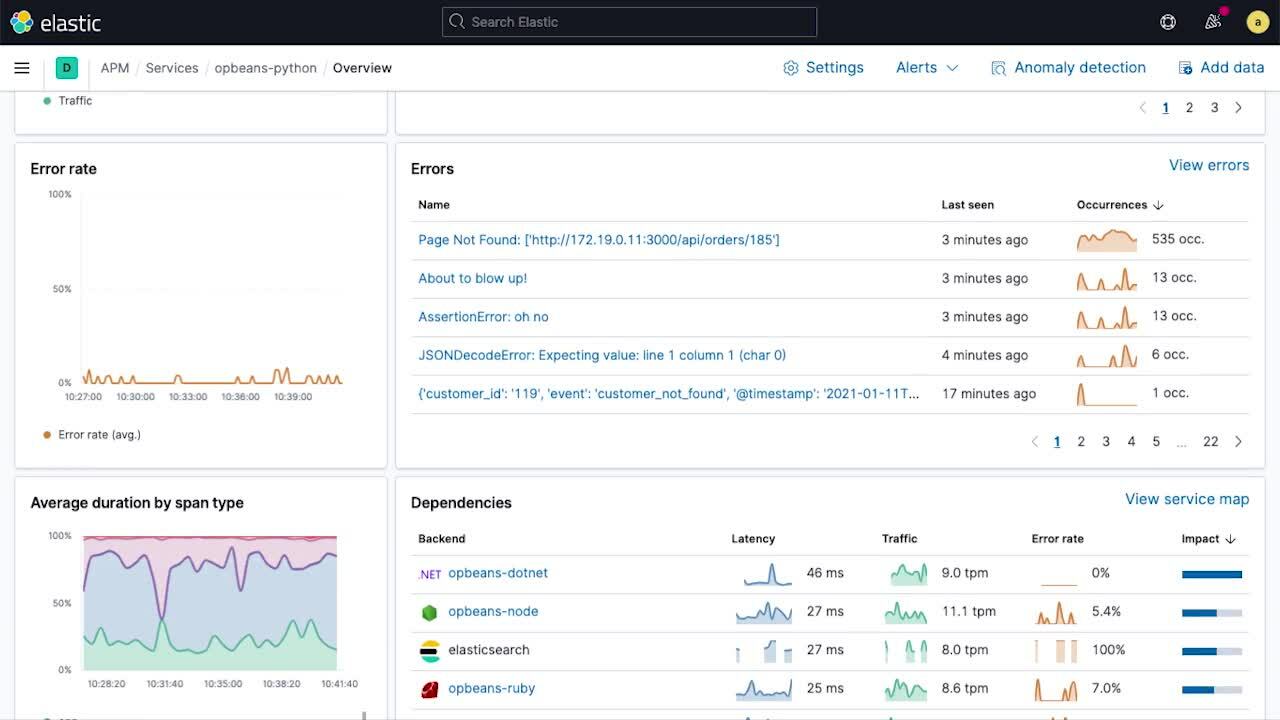
Los gráficos de series temporales que muestran la latencia del servicio, el tráfico y la tasa de errores proporcionan una vista de alto nivel de los indicadores clave de rendimiento (KPI) del servicio en el tiempo. Las anotaciones superpuestas (marcadores de despliegue, alertas de anomalía, etc.) en los gráficos de series temporales proporcionan un contexto completo de eventos clave que pueden haber contribuido a cambios en el comportamiento. Estas anotaciones ayudan de inmediato a acotar el alcance de las investigaciones que pueden proporcionar una ruta de corrección (por ejemplo, revertir).
Los minigráficos en la página de visión general del servicio brindan una vista compacta de las tendencias temporales de los subcomponentes, lo que facilita detectar cambios inusuales en el comportamiento (por ejemplo, un aumento repentino en la tasa de errores de una transacción en particular) y descubrir buenos "pasos siguientes" durante una investigación. En esta página, también se muestra el estado del servicio desglosado por instancias de la infraestructura (por ejemplo, contenedores) en las que está desplegado el servicio, esto facilita asociar los inconvenientes a los problemas con la infraestructura subyacente.
En la versión 7.11, se presenta la primera fase de esta nueva vista del estado del servicio, y en las próximas versiones se incluirán vistas y contexto adicionales para optimizar y acelerar más los flujos de trabajo de solución de problemas y análisis de la causa raíz.
Soluciona problemas de infraestructura más rápido gracias a la nueva y mejorada vista de detalles del host
El mapa de calor de recursos en la app Metrics proporciona una vista panorámica del estado de tu infraestructura, lo que facilita detectar rápidamente recursos con problemas (por ejemplo, hosts con aumento repentino en el uso de CPU) y acotar los pasos siguientes de una investigación a través de la identificación de hosts que requieren una inspección más minuciosa. Presentamos una vista nueva de la app Metrics que facilita pasar de esta vista de alto nivel a una más general en la que se puede observar una tendencia histórica de métricas clave de los hosts individuales.
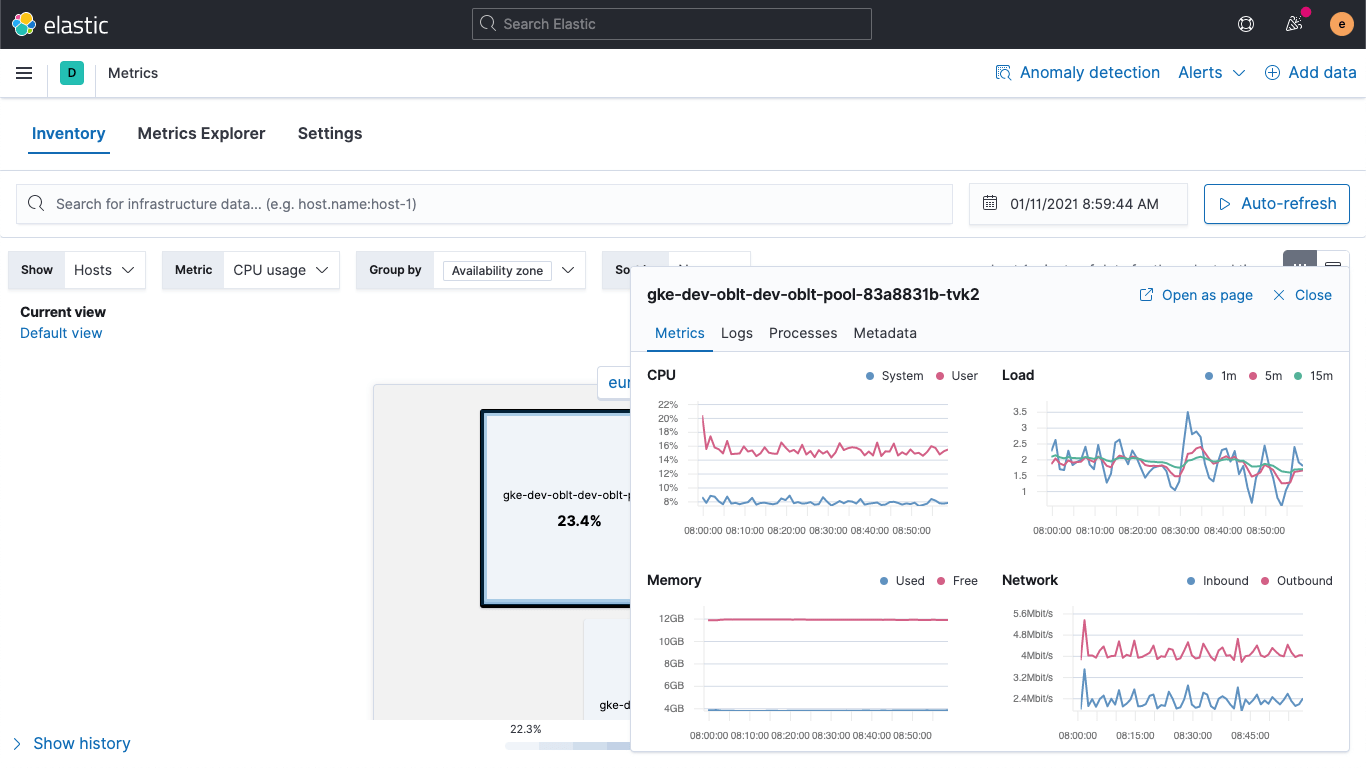
De modo similar a como la nueva página de destino del servicio muestra un vistazo de las tendencias, la vista mejorada de detalles del host ayuda a acelerar el análisis de la causa raíz a través de la consolidación de toda la información (logs, métricas, procesos, etc.) que necesitas sobre un host en una vista única, lo que facilita el monitoreo y la solución de problemas de infraestructura para los equipos de operaciones de infraestructura.
Si haces clic en un mosaico del mapa de calor, se abre una ventana emergente con información clave sobre el host, incluido lo siguiente:
- Gráficos de tiempo de métricas de hosts clave (CPU, memoria, red, etc.)
- Logs generados por el host o servicios que se ejecutan en ese host
- Procesos principales que se ejecutan en el host (por CPU o memoria)
- Metadatos del host (sistema operativo, detalles del Proveedor Cloud)
- Enlaces para obtener información más detallada de datos de tiempo de actividad o rastreo
En la versión 7.11, se presenta por primera vez esta vista mejorada de hosts o VM, y en las próximas versiones se ampliará esta funcionalidad a otros tipos de recursos (pods, contenedores, etc.) en la app Metrics.
Conoce más sobre la página de visión general del servicio y otras características nuevas de APM en los documentos sobre novedades en la versión 7.11.
Las bibliotecas de logging de ECS profundizan la observabilidad de las aplicaciones a través del enlace automático entre los rastreos y los logs de las aplicaciones
Poder correlacionar logs y rastreos de aplicaciones, y navegar entre ellos sin perder el contexto es fundamental para los flujos de trabajo de solución de problemas de las aplicaciones. ¿Qué logs pertenecen a un rastreo en particular o qué rastreo los generó? ¿Qué solicitud de aplicación desencadenó estos logs? Las bibliotecas de logging de Elastic Common Schema (ECS), ahora a disposición del público en general en la versión 7.11, facilitan a los desarrolladores de aplicaciones inyectar automáticamente en sus logs de aplicaciones el contexto de rastreo capturado por el agente de APM, lo que permite la correlación de logs a rastreos requerida para un análisis optimizado.
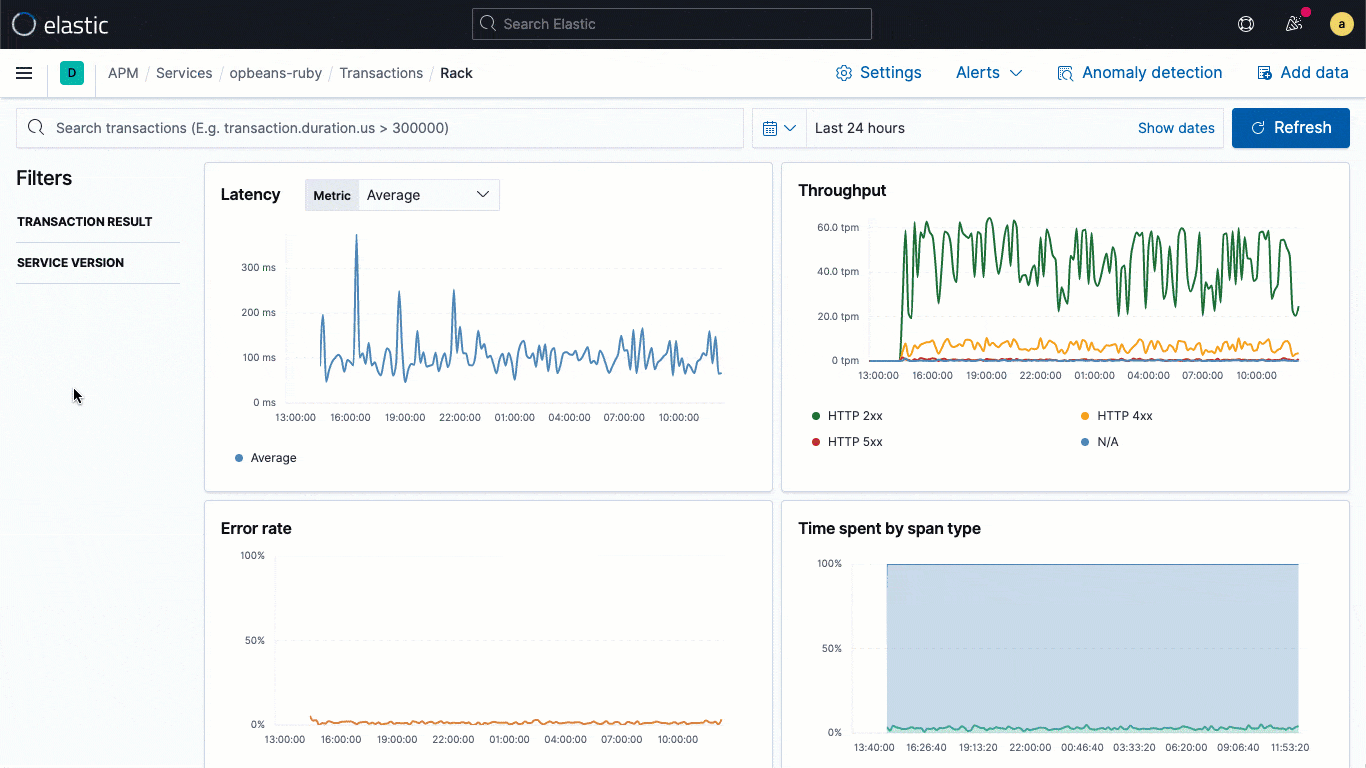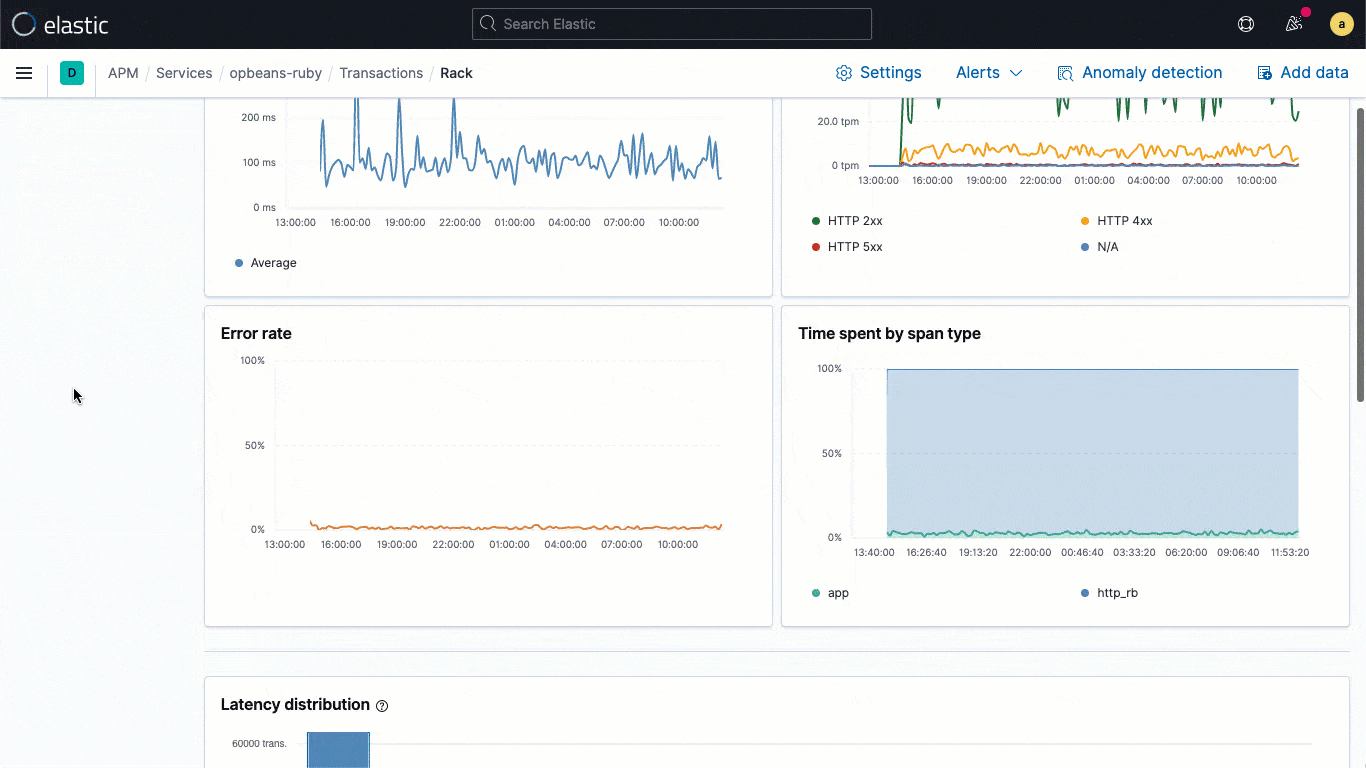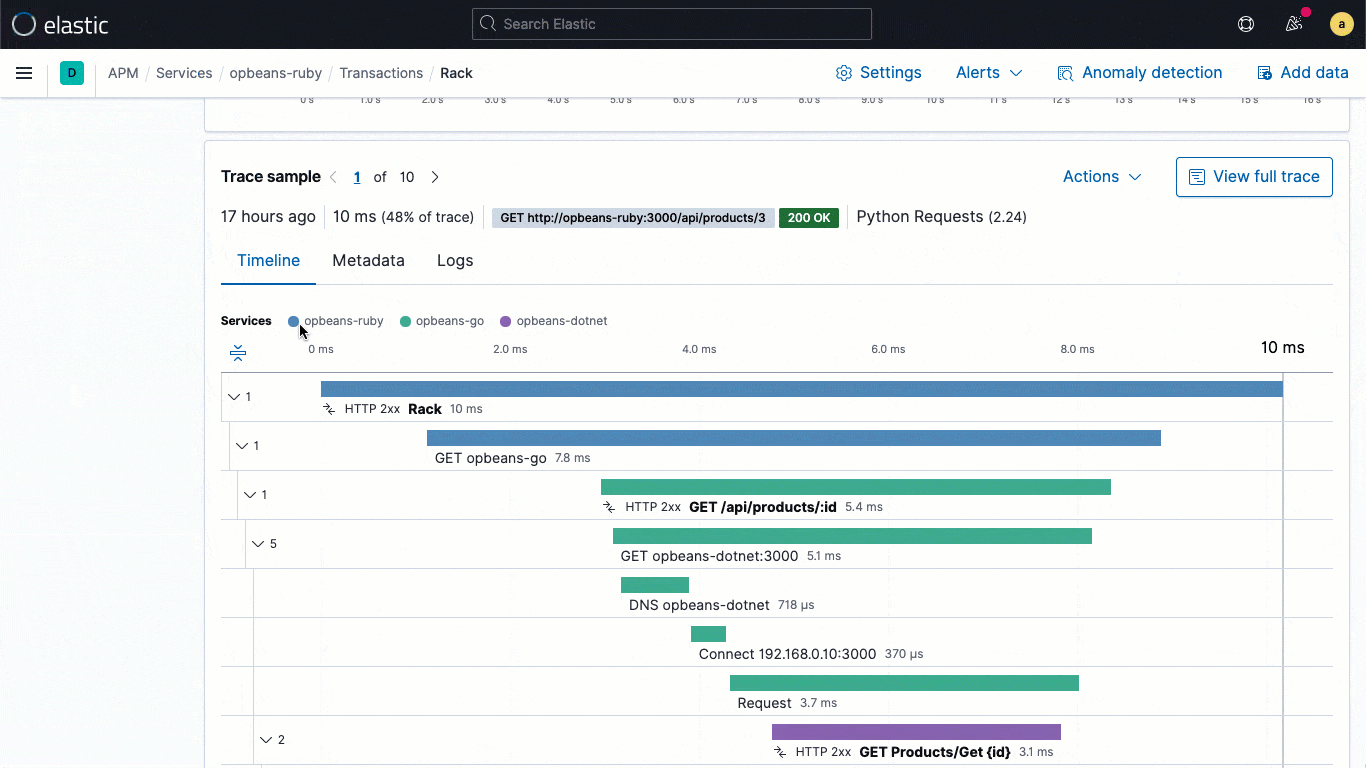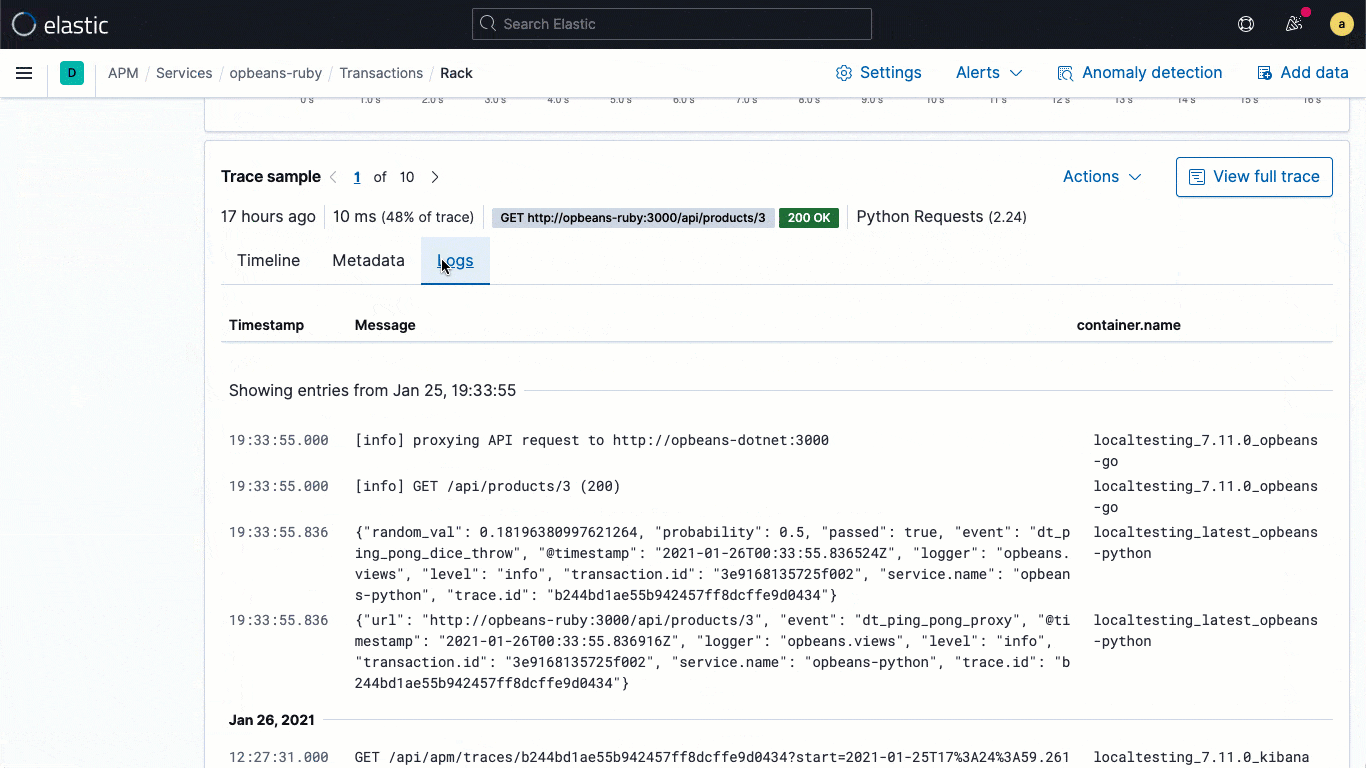
Las bibliotecas de logging de ECS son plugins para tus marcos de trabajo de logging favoritos (por ejemplo, log4j) y permiten a los desarrolladores escribir con facilidad logs de aplicaciones en un formato JSON compatible con ECS, sin cambiar sus flujos de trabajo nativos. Los loggers de ECS incluyen automáticamente en el log el contexto de rastreo relevante capturado por el agente de APM, lo que ayuda a los desarrolladores a crear aplicaciones observables sin trabajo adicional. El contexto de rastreo capturado suele incluir trace.id transaction.id y span.id, según sea necesario.
A partir de estos enlaces fundamentales a nivel de los datos, la versión 7.11 aporta un flujo de logs incorporado directamente a la vista de rastreo, lo que significa que los usuarios pueden ver de forma directa los logs asociados con un rastreo específico sin cambiar el contexto visual durante una investigación.
Además de esta correlación log ↔ rastreo, capturar logs en formato de ECS agrega otros beneficios, entre ellos, parseo automático, logs legibles para las personas y un modelo de datos normalizado en toda la pila de aplicaciones.
Conoce más sobre esta y otras mejoras para el monitoreo de infraestructuras en las novedades en la versión 7.11.
Otros aspectos destacados importantes
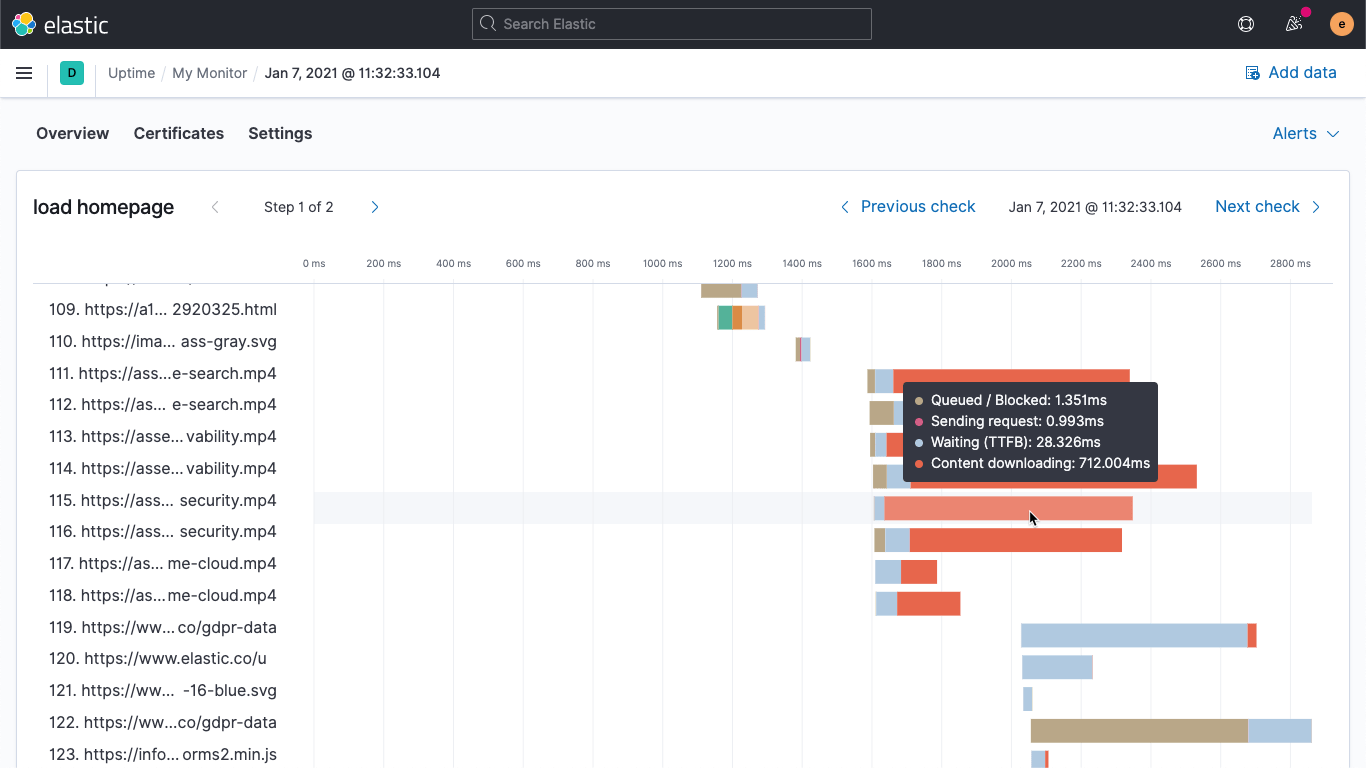
Gráfico en cascada de carga de página
En la versión 7.10, presentamos por primera vez el monitoreo sintético de recorridos de varios pasos de usuarios. En la 7.11, lanzamos la primera iteración de nuestra cascada de carga de página que muestra las estadísticas de conexión de cada objeto en la página. La vista en cascada del tiempo de carga permite a un usuario encontrar rápidamente el cuello de botella de rendimiento en la experiencia del usuario final durante pruebas sintéticas.
Los campos de tiempo de ejecución sientan las bases del esquema durante la lectura
Tal como lo sugiere el nombre, los campos de tiempo de ejecución, una de las características más solicitadas por la comunidad de Elastic Observability, te permiten crear campos nuevos sobre la marcha durante el tiempo de ejecución a través de la transformación, el enriquecimiento o la extracción de campos a partir de datos indexados. Es una característica fundamental que permite nuevos flujos de trabajo de observabilidad, incluida una de las características más solicitadas de todos los tiempos: esquema durante la lectura.
Con el lanzamiento de esta característica, los usuarios ahora tienen lo mejor de ambos mundos. Usa el esquema durante la escritura y disfruta de una velocidad de búsqueda y analíticas increíblemente rápida gracias al parseo y la estructuración de datos al momento de la indexación. O prueba el esquema durante la lectura, para ello, define campos sobre la marcha durante el tiempo de ejecución para tener más flexibilidad en los flujos de trabajo analíticos.
Elasticsearch soporta los campos de tiempo de ejecución en la versión 7.11, con soporte de UI limitado en Kibana. Lee todo sobre nuestra visión en el post dedicado.
Los snapshots buscables y el nivel frío ahora están a disposición del público en general
Los snapshots buscables, que se presentaron como característica beta en la versión 7.10, ahora están a disposición del público en general. Estos snapshots permiten a los usuarios buscar y analizar datos directamente en almacenes de objetos, como S3, lo que facilita en gran medida la implementación de la estrategia de división de datos en niveles para equilibrar la compensación entre el rendimiento y el costo. El nuevo nivel frío, impulsado por snapshots buscables, puede reducir los costos de almacenamiento hasta en un 50 % con un efecto mínimo sobre el rendimiento.
Los snapshots buscables y los niveles de datos son características innovadoras para los casos de uso de observabilidad: permiten a los usuarios hacer más con menos (sin aumentar la complejidad operativa, cambiar los flujos de trabajo de investigación o entorpecer el acceso a los datos).
Prueba hoy mismo la versión nueva
Conoce más detalles y aprende sobre todas estas capacidades nuevas y más en los aspectos destacados de la versión.
O mejor aún, comienza a usar estas grandiosas características nuevas: actualiza tu despliegue a la versión 7.11, obtén una prueba gratuita de 14 días de Elasticsearch Service o instala la versión más reciente del Elastic Stack.