Próximamente en la versión 7.7: Disminuye de forma significativa tu uso de memoria heap de Elasticsearch
Como los usuarios de Elasticsearch desafían los límites de la cantidad de datos que pueden almacenar en un nodo de Elasticsearch, a veces agotan la memoria heap antes de agotar el espacio en disco. Este problema es frustrante para los usuarios porque acomodar la mayor cantidad de datos posible por nodo suele ser importante para reducir costos.
¿Por qué Elasticsearch necesita memoria heap para almacenar datos? ¿Por qué no necesita solo espacio en disco? Hay varias razones, pero la principal es que Lucene necesita almacenar cierta información en la memoria para saber adónde buscar en el disco. Por ejemplo, el índice invertido de Lucene incluye un diccionario de términos en el cual estos se agrupan en bloques en el disco siguiendo un orden de clasificación y un índice de términos para la búsqueda rápida en el diccionario de términos. Este índice de términos mapea los prefijos de los términos con la compensación en el disco donde se inicia el bloque que contiene términos con este prefijo. El diccionario de términos está en el disco, pero el índice de términos estaba en la heap hasta hace poco.
¿Cuánta memoria necesitan los índices? Por lo general, necesitan unos pocos MB por GB de índice. No es mucho, pero vemos a los usuarios agregar cada vez más terabytes de disco en sus nodos, y los índices comienzan rápidamente a necesitar 10-20 GB de memoria heap para almacenar esos terabytes de índices. Dada la recomendación de Elastic de no superar los 30 GB de heap, esto no deja mucho margen para otros consumidores de dicha memoria, como las agregaciones, y abre las puertas a problemas de estabilidad si a la JVM no le queda espacio suficiente para las operaciones de gestión de clusters.
Veamos algunas cifras concretas. Elastic ejecuta evaluaciones comparativas cada noche en varios sets de datos y rastrea diversas métricas en el tiempo, especialmente el uso de memoria de los segmentos. El set de datos Geonames es interesante porque muestra con claridad el impacto de varios cambios en Elasticsearch 7.x:
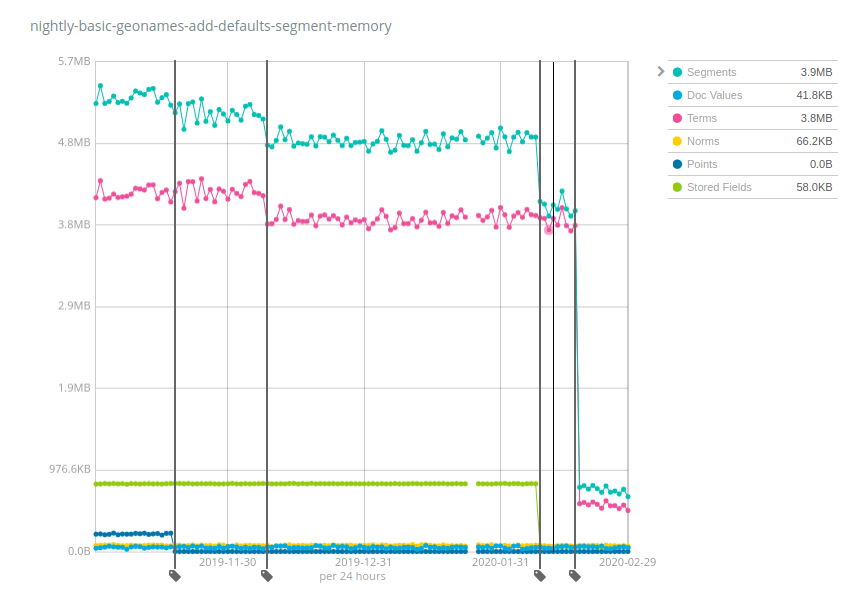
Este índice ocupa alrededor de 3 GB en el disco y solía necesitar ~5.2 MB de memoria hace 6 meses, esta es una proporción de heap:almacenamiento de ~1:600. Entonces, si tenías un total de 10 TB adjuntados en cada nodo, necesitabas 10 TB/600 = 17 GB de heap, solo para poder mantener abiertos los índices con datos del tipo nombre geográfico. Pero como puedes ver, mejoramos las cosas con el tiempo: los puntos (azul oscuro) comenzaron a necesitar menos memoria, después los términos (rosa), los campos almacenados (verde) y, por último, nuevamente los términos en una proporción mayor. La proporción de heap:almacenamiento ahora es de ~1:4000, casi 7 veces mejor en comparación con las primeras versiones 7.x y las 6.x. Ahora solo necesitarías 2.5 GB de memoria heap para mantener abiertos 10 TB de índices.
Los números varían MUCHO entre sets de datos, y la buena noticia es que Geonames es uno de los sets de datos que mostró la menor reducción en el uso de heap: mientras que el uso de heap disminuyó ~7 veces en Geonames, disminuyó más de 100 veces en los sets de datos NYC taxis y HTTP logs. Nuevamente, este cambio ayudará a reducir costos almacenando muchos más datos por nodo de los que podían soportar las versiones anteriores de Elasticsearch.
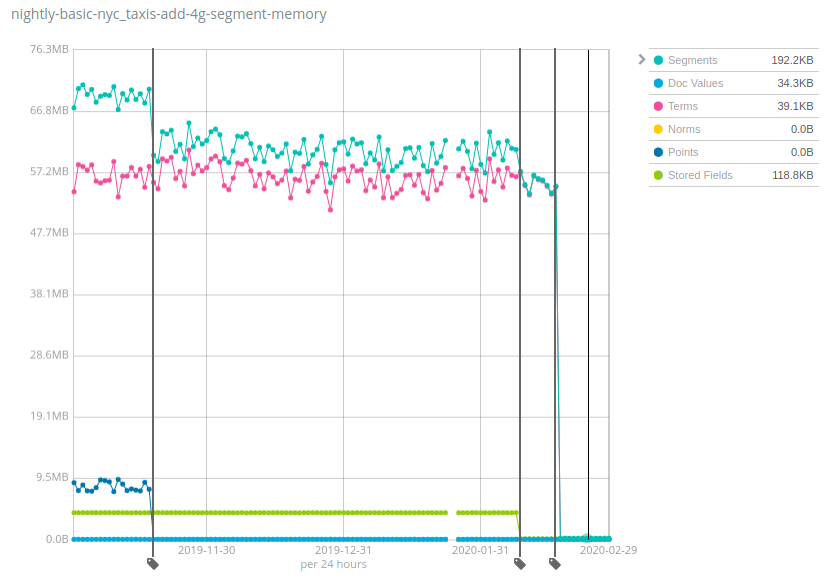
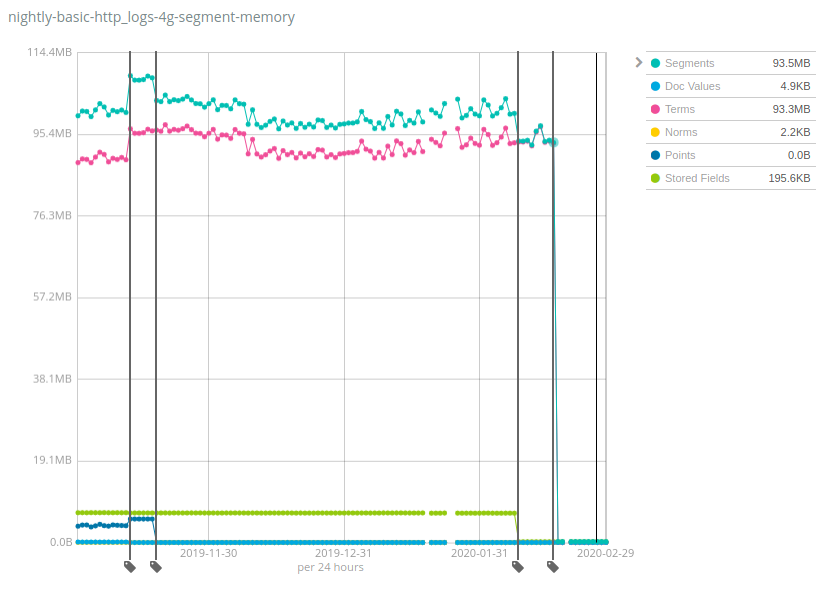
¿Cómo funciona esto y cuáles son los inconvenientes? Se ha aplicado la misma fórmula en varios componentes de los índices de Lucene con el tiempo: cambiar estructuras de datos de la heap de JVM a disco y confiar en la caché del sistema de archivos (con frecuencia llamada caché de la página o caché del SO) para mantener los bits calientes en la memoria. Esto puede interpretarse como que esta memoria aún se usa y está asignada en otra parte, pero la realidad es que una gran parte de dicha memoria simplemente nunca se usó según tu caso de uso. Por ejemplo, el último lanzamiento de Terms se debió al cambio de lugar del índice de términos del campo _id en el disco, que solo es útil cuando se usa la API GET o cuando se indexan documentos con ID específicas. La gran mayoría de los usuarios que indexan logs y métricas en Elasticsearch nunca realizan ninguna de estas operaciones, por lo que será una ganancia neta de recursos para ellos.
Reduce tu heap de Elasticsearch con la versión 7.7
Estamos muy entusiasmados por estas mejoras que estarán disponibles en Elasticsearch 7.7, y esperamos que tú también. Mantente atento al próximo anuncio de lanzamiento y pruébalo tú mismo. Pruébalo en tu despliegue existente o activa una prueba gratuita de Elasticsearch Service en Elastic Cloud (que siempre tiene la versión más reciente de Elasticsearch). Esperamos tus comentarios, cuéntanos tu opinión en Discuss.