Monitoreo de Kafka con Elasticsearch, Kibana y Beats
Publicamos por primera vez sobre el monitoreo de Kafka con Filebeat en 2016. Desde el lanzamiento de la versión 6.5, el equipo de Beats ha estado admitiendo un módulo de Kafka. Este módulo automatiza gran parte del trabajo involucrado en el monitoreo de un cluster de Kafka.
En este blog, nos enfocaremos en la recopilación de datos de logs y métricas con los módulos de Kafka en Filebeat y Metricbeat. Ingestaremos esos datos en un cluster hospedado en Elasticsearch Service y exploraremos los dashboards de Kibana proporcionados por los módulos de Beats.
Este blog usa el Elastic Stack 7.1. Se proporciona un entorno de ejemplo en GitHub.
¿Por qué módulos?
Cualquiera que haya trabajado con filtros de grok complejos de Logstash apreciará la simplicidad de configurar la recopilación de logs a través de un Filebeat module. Existen otros beneficios al usar módulos dentro de tu configuración de monitoreo:
- Configuración simplificada de recopilación de logs y métricas
- Documentos estandarizados a través de Elastic Common Schema
- Plantillas de índice razonables que proporcionan tipos de datos de campo óptimos
- Dimensionamiento apropiado del índice. Beats usa la API de rollover para garantizar tamaños de shard saludables para los índices de Beats.
Consulta la documentación para obtener una lista completa de los módulos compatibles con Filebeat y Metricbeat.
Introducción del entorno
Nuestra configuración de ejemplo consta del cluster de Kafka de tres nodos (kafka0, kafka1 y kafka2). Cada nodo ejecuta Kafka 2.1.1 junto con Filebeat y Metricbeat para monitorear el nodo. Los Beats se configuran a través de la Cloud ID para enviar datos a nuestro cluster de Elasticsearch Service. Los módulos de Kafka que se envían con Filebeat y Metricbeat configurarán dashboards dentro de Kibana para su visualización. Como nota, si deseas probar esto en tu propio cluster, puedes activar una prueba gratuita de 14 días de Elasticsearch Service, que viene con todos los accesorios.
Configuración de los Beats
A continuación, configurarás y después iniciarás los Beats.
Instala y habilita los servicios de los Beats
Seguiremos la guía de Primeros pasos para instalar Filebeat y Metricbeat. Debido a que estamos realizando la ejecución en Ubuntu, instalaremos los Beats a través del repositorio APT.
wget -qO - https://artifacts.elastic.co/GPG-KEY-elasticsearch | sudo apt-key add - echo "deb https://artifacts.elastic.co/packages/7.x/apt stable main" | sudo tee -a /etc/apt/sources.list.d/elastic-7.x.list sudo apt-get update sudo apt-get install filebeat metricbeat systemctl enable filebeat.service systemctl enable metricbeat.service
Configura la Cloud ID de nuestro despliegue de Elasticsearch Service
Copia la Cloud ID de la consola de Elastic Cloud y úsala para configurar la salida para Filebeat y Metricbeat.
CLOUD_ID=Kafka_Monitoring:ZXVyb3BlLXdlc...
CLOUD_AUTH=elastic:password
filebeat export config -E cloud.id=${CLOUD_ID} -E cloud.auth=${CLOUD_AUTH} > /etc/filebeat/filebeat.yml
metricbeat export config -E cloud.id=${CLOUD_ID} -E cloud.auth=${CLOUD_AUTH} > /etc/metricbeat/metricbeat.yml
Habilita los módulos de Kafka y de sistema en Filebeat y Metricbeat
A continuación, deberemos habilitar los módulos de Kafka y de sistema para ambos Beats.
filebeat modules enable kafka system metricbeat modules enable kafka system
Una vez habilitados, podemos ejecutar la configuración de Beats. Esto configura plantillas de índice y dashboards de Kibana usados por los módulos.
filebeat setup -e --modules kafka,system metricbeat setup -e --modules kafka,system
Inicia tus Beats
Bien, ahora que todo está configurado, iniciemos Filebeat y Metricbeat.
systemctl start metricbeat.service systemctl start filebeat.service
Exploración de los datos de monitoreo
El dashboard de logging predeterminado muestra lo siguiente:
- Excepciones recientes encontradas por el cluster de Kafka. Las excepciones se agrupan por la clase de excepción y el detalle completo de la excepción
- Una visión general del rendimiento del log por nivel, junto con el detalle completo del log.
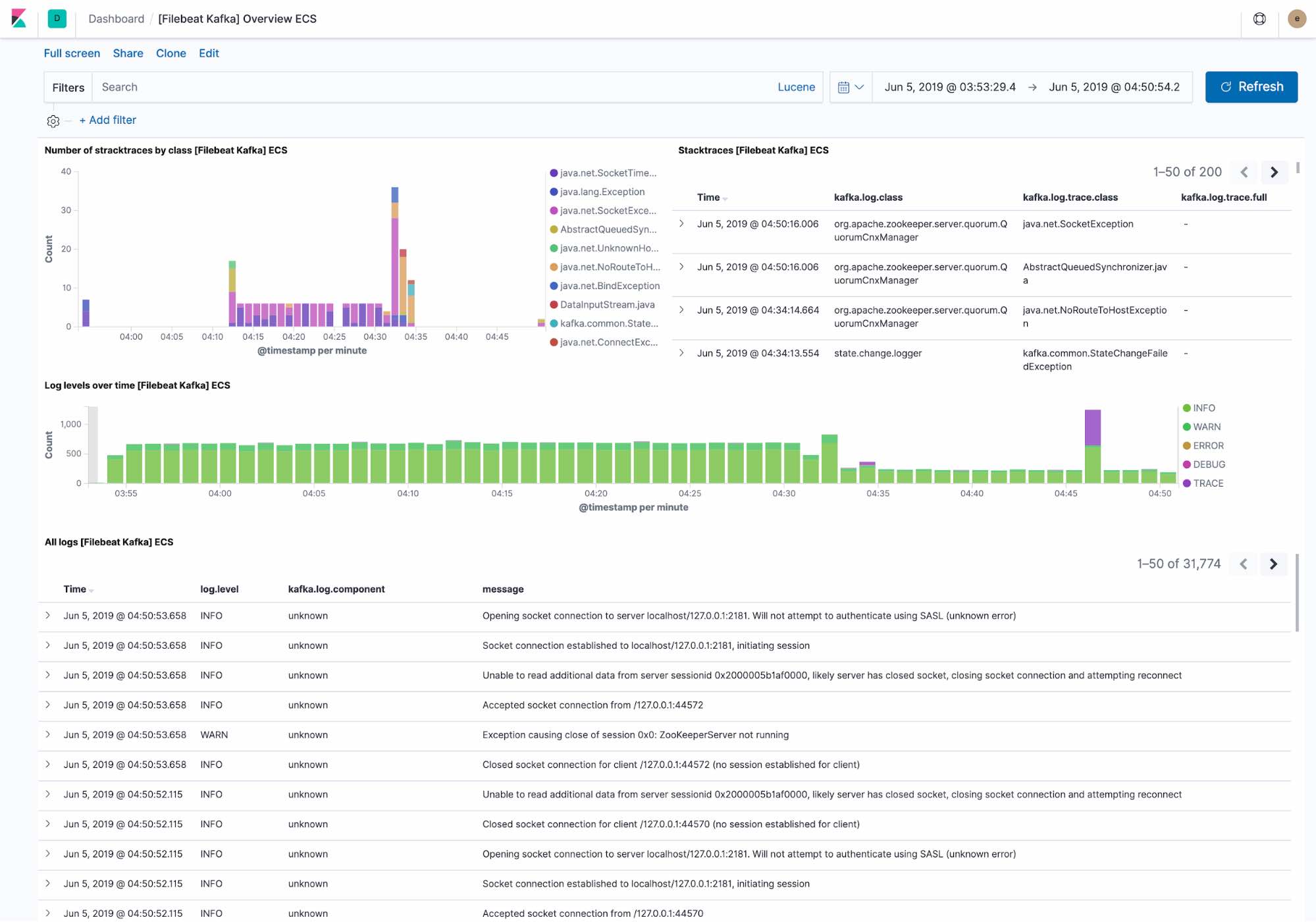
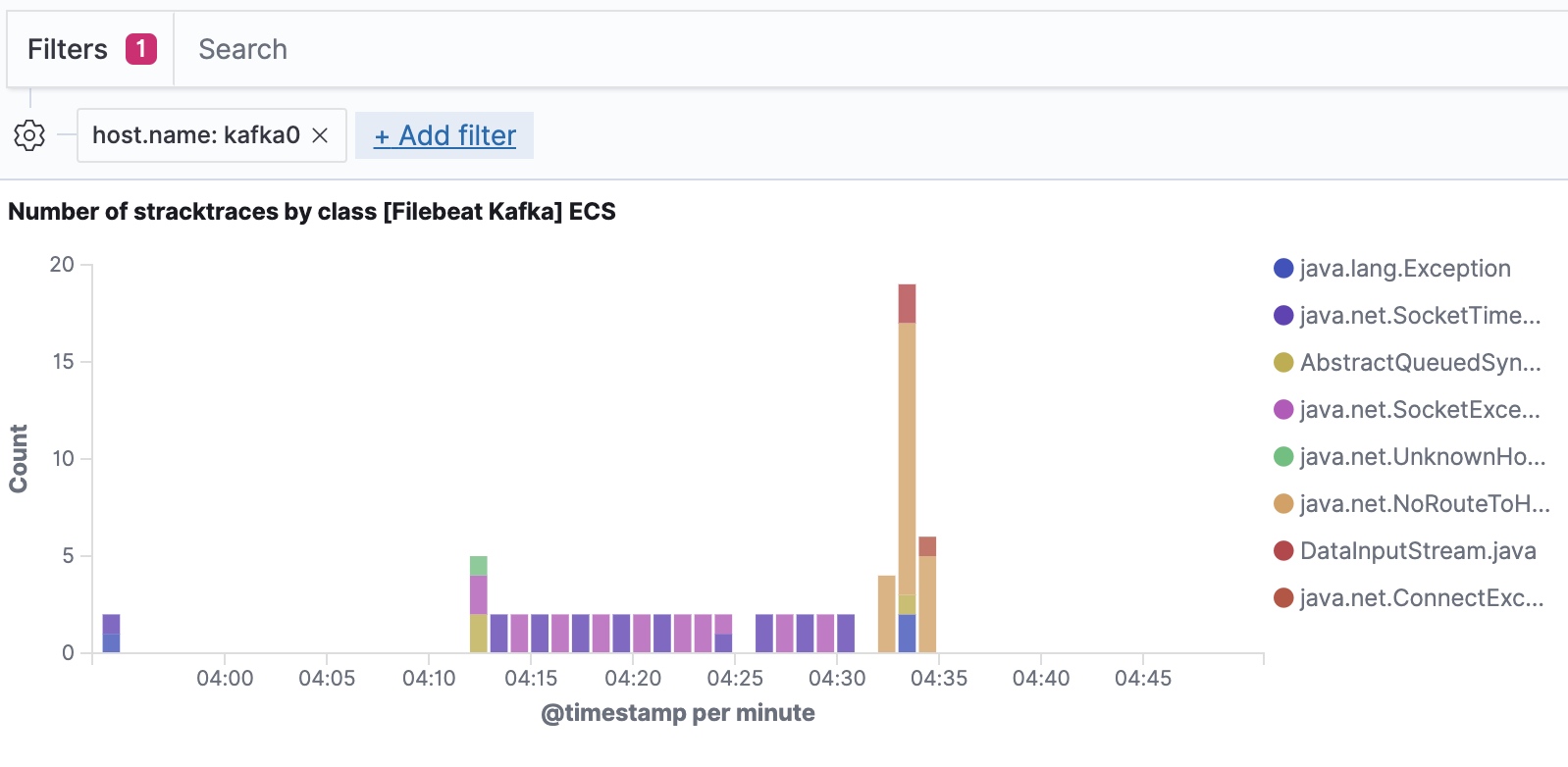
Filebeat ingesta datos siguiendo e Elastic Common Schema, lo que nos permite filtrar hasta el nivel de host.
El dashboard que proporciona Metricbeat muestra el estado actual de cualquier tema dentro del cluster de Kafka. También tenemos un menú desplegable para filtrar el dashboard a un solo tema.
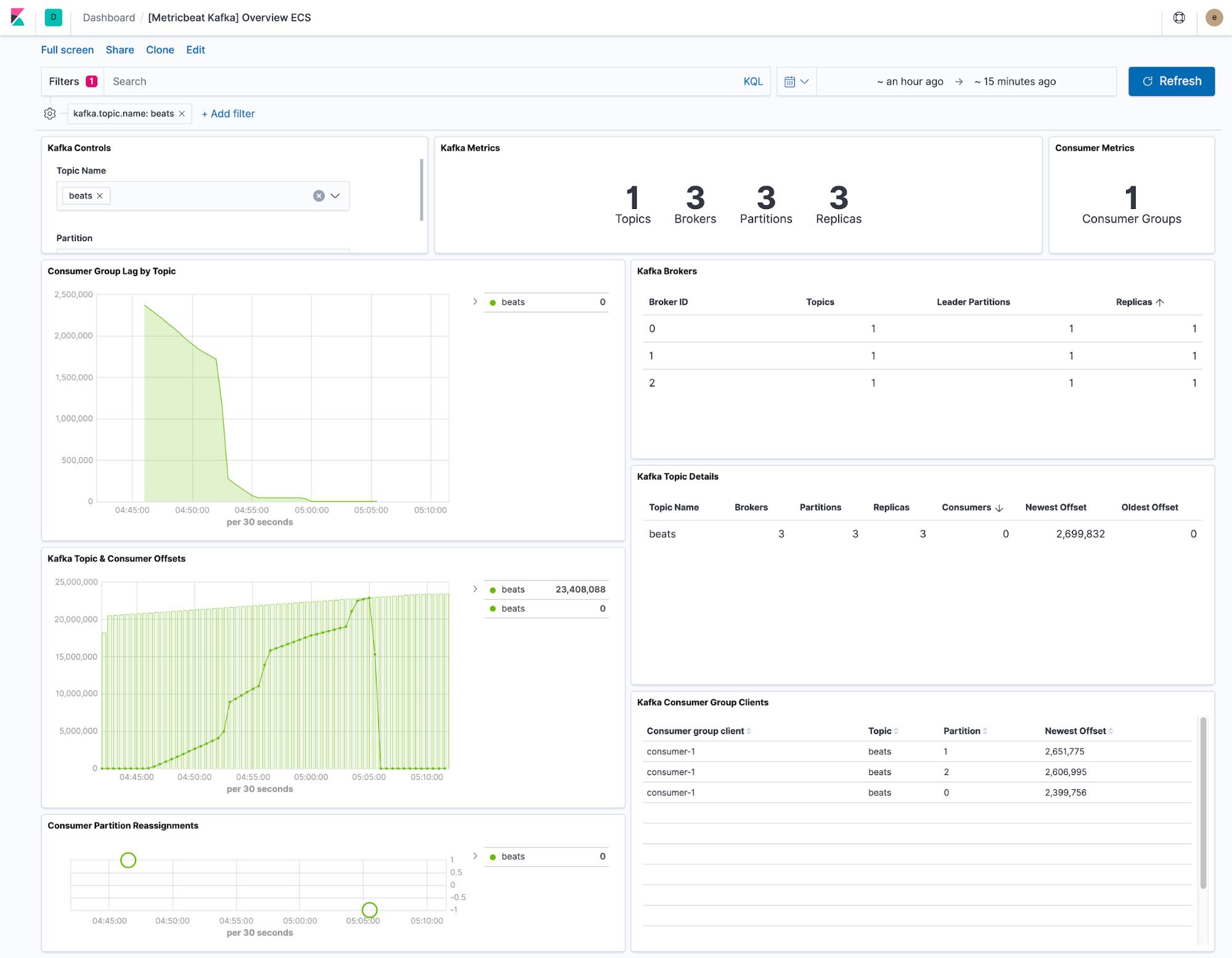
Las visualizaciones de retraso y compensación del consumidor muestran si los consumidores se están quedando atrás con respecto a temas específicos. Las compensaciones por partición también muestran si una única partición se está quedando atrás.
La configuración predeterminada de Metricbeat recopila dos sets de datos: kafka.partition y kafka.consumergroup. Estos sets de datos proporcionan información sobre el estado de un cluster de Kafka y sus consumidores.
El set de datos kafka.partition incluye detalles completos sobre el estado de las particiones dentro de un cluster. Estos datos se pueden usar para lo siguiente:
- Crear dashboards que muestren cómo las particiones se mapean a los nodos del cluster
- Alertar sobre particiones sin réplicas sincronizadas
- Realizar un seguimiento de la asignación de particiones a lo largo del tiempo
- Visualizar los límites de compensación de particiones a lo largo del tiempo
A continuación se muestra un documento completo de kafka.partition.

El set de datos kafka.consumergroup captura el estado de un solo consumidor. Estos datos podrían usarse para mostrar de qué particiones está leyendo un único consumidor y las compensaciones actuales de ese consumidor.
