Primeros pasos con las visualizaciones de Vega en Kibana
La gramática declarativa de Vega es una poderosa manera de visualizar tus datos. Con esta nueva característica en Kibana 6.2, ahora puedes crear visualizaciones enriquecidas de Vega y Vega-Lite con tus datos de Elasticsearch. Comencemos a conocer el lenguaje de Vega con algunos ejemplos simples.
Para comenzar, abre el editor de Vega: una herramienta conveniente para experimentar con Vega original (sin personalizaciones para Elasticsearch). Copia el código a continuación y verás el texto “Hello Vega!” (¡Hola, Vega!) en el panel derecho.

{
"$schema": "https://vega.github.io/schema/vega/v3.json",
"width": 100, "height": 30,
"background": "#eef2e8",
"padding": 5,
"marks": [
{
"type": "text",
"encode": {
"update": {
"text": { "value": "Hello Vega!" },
"align": { "value": "center"},
"baseline": { "value": "middle"},
"stroke": { "value": "#A32299" },
"angle": { "value": 15 },
"x": { "signal": "width/2" },
"y": { "signal": "height/2" }
}
}
}
]
}
El bloque de marcas es una matriz de primitivos de dibujo, como texto, líneas y rectángulos. Cada marca tiene una gran cantidad de parámetros especificados en el conjunto de codificado. Cada parámetro se configura como una constante (valor) o un resultado de un cálculo (señal) en la etapa de “actualización”. En el caso de la marca de texto, especificamos el texto, nos aseguramos de que esté correctamente posicionado (con respecto a las coordenadas dadas) y girado, y configuramos el color. Las coordenadas x e y se calculan según el ancho y el alto del grafo, posicionando el texto en el centro. Existen muchos otros parámetros de marcas de texto. También hay disponible un grafo interactivo de demostración de marcas de texto para probar diferentes valores de los parámetros.
$schema es simplemente un ID de la versión de motor de Vega requerida. Background hace que el grafo no sea transparente. width y height configuran el tamaño inicial del lienzo de dibujo. En ciertos casos, el tamaño final del grafo puede variar según el contenido y las opciones de dimensionamiento automático. Ten en cuenta que el valor predeterminado de autosize en Kibana es fit, en lugar de pad, por lo que height y width son opcionales. El parámetro padding agrega espacio, no incluido en el ancho y alto, alrededor del grafo.
Grafo basado en datos
El siguiente paso es dibujar un grafo basado en datos mediante la marca de rectángulo. La sección de datos permite varias fuentes de datos, codificadas de forma rígida o como URL. En Kibana, también puedes usar búsquedas directas de Elasticsearch. Nuestra tabla de datos vals tiene cuatro filas y dos columnas: category y count. Usamos category para posicionar la barra en el eje x y count para la altura de la barra. Observa que en la coordenada y 0 se encuentra en la parte superior y aumenta hacia abajo.
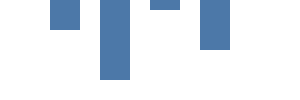
{
"$schema":"https://vega.github.io/schema/vega/v3.json",
"width": 300, "height": 100,
"data": [ {
"name": "vals",
"values": [
{"category": 50, "count": 30},
{"category": 100, "count": 80},
{"category": 150, "count": 10},
{"category": 200, "count": 50}
]
} ],
"marks": [ {
"type": "rect",
"from": { "data": "vals" },
"encode": {
"update": {
"x": {"field": "category"},
"width": {"value": 30},
"y": {"field": "count"},
"y2": {"value": 0}
}
}
} ]
}
La marca rect especifica la tabla vals como la fuente de datos. La marca se dibuja una vez por valor de datos fuente (también se conoce como fila de tabla o referencia). A diferencia del grafo anterior, los parámetros x e y no están codificados de forma rígida, sino que provienen de los campos de la referencia.
Escalado
El concepto de escalado es uno de los más importantes, pero un poco complejos, en Vega. En los ejemplos anteriores, las coordenadas de píxeles de pantalla estaban codificadas de forma rígida en los datos. Si bien simplificaba las cosas, los datos verdaderos casi nunca tienen ese formato. En cambio, los datos fuente tienen sus propias unidades (p. ej., cantidad de eventos), y depende del grafo escalar los valores fuente al tamaño de grafo deseado en píxeles.
En este ejemplo, usamos la escala lineal: básicamente, una función matemática para convertir un valor del dominio de los datos fuente (en este grafo, los valores count de 1000 a 8000; y se incluye count=0) al rango deseado (en nuestro caso, la altura del grafo es de 0 a 99). Al agregar "scale": "yscale" tanto al parámetro y como al y2, se usa la función de ajuste de escala yscale para convertir count a coordenadas de pantalla (0 se transforma en 99, y 8000 —el valor más alto de los datos fuente— se transforma en 0). Ten en cuenta que el parámetro del rango height es un caso especial, invirtiendo el valor para que 0 aparezca en la parte inferior del grafo.
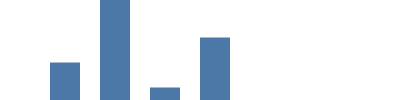
{
"$schema":"https://vega.github.io/schema/vega/v3.json",
"width": 400, "height": 100,
"data": [ {
"name": "vals",
"values": [
{"category": 50, "count": 3000},
{"category": 100, "count": 8000},
{"category": 150, "count": 1000},
{"category": 200, "count": 5000}
]
} ],
"scales": [
{
"name": "yscale",
"type": "linear",
"zero": true,
"domain": {"data": "vals", "field": "count"},
"range": "height"
}
],
"marks": [ {
"type": "rect",
"from": { "data": "vals" },
"encode": {
"update": {
"x": {"field": "category"},
"width": {"value": 30},
"y": {"scale": "yscale", "field": "count"},
"y2": {"scale": "yscale", "value": 0}
}
}
} ]
}
Ajuste de escala de barras
Para el tutorial, necesitaremos otro de los más de 15 tipos de escala de Vega: una escala de barras. Esta escala se usa cuando tenemos un conjunto de valores (como categorías) que deben representarse como barras y cada una de ellas debe ocupar el mismo ancho proporcional del ancho total del grafo. Aquí, la escala de barras le asigna a cada una de las cuatro categorías únicas el mismo ancho proporcional (alrededor de 400/4, menos el 5 % de espaciado entre las barras y en ambos extremos). {"scale": "xscale", "band": 1} obtiene el 100 % del ancho de las barras del parámetro width de la marca.
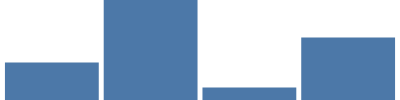
{
"$schema":"https://vega.github.io/schema/vega/v3.json",
"width": 400, "height": 100,
"data": [ {
"name": "vals",
"values": [
{"category": "Oranges", "count": 3000},
{"category": "Pears", "count": 8000},
{"category": "Apples", "count": 1000},
{"category": "Peaches", "count": 5000}
]
} ],
"scales": [
{
"name": "yscale",
"type": "linear",
"zero": true,
"domain": {"data": "vals", "field": "count"},
"range": "height"
},
{
"name": "xscale",
"type": "band",
"domain": {"data": "vals", "field": "category"},
"range": "width",
"padding": 0.05
}
],
"marks": [ {
"type": "rect",
"from": { "data": "vals" },
"encode": {
"update": {
"x": {"scale": "xscale", "field": "category"},
"width": {"scale": "xscale", "band": 1},
"y": {"scale": "yscale", "field": "count"},
"y2": {"scale": "yscale", "value": 0}
}
}
} ]
}
Ejes
Un grafo típico no estaría completo sin las etiquetas de los ejes. La definición de eje usa las mismas escalas que definimos anteriormente, por lo que agregarlas es tan sencillo como hacer referencia a la escala por su nombre y especificar de qué lado colocarla. Agrega este código como elemento de nivel superior en el último ejemplo de código.
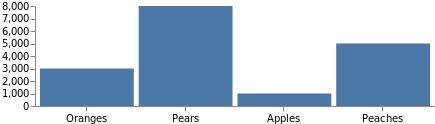
"axes": [
{"scale": "yscale", "orient": "left"},
{"scale": "xscale", "orient": "bottom"}
],
Observa que el tamaño total del grafo aumentó automáticamente para adaptarse a estos ejes. Se puede forzar al grafo a mantener el tamaño original agregando "autosize": "fit" en la parte superior de la especificación.
Transformaciones de datos y condicionales
Con frecuencia es necesario realizar alguna manipulación adicional de los datos para poder usarlos para dibujar. Vega proporciona varias transformaciones que resultan útiles para dicho fin. Usemos la transformación de fórmula más habitual para agregar dinámicamente un campo de valor count aleatorio en cada referencia fuente. En este grafo también manipularemos el color de relleno de la barra, para que se muestre en rojo si el valor es inferior a 333, en amarillo si es inferior a 666 y en verde si es superior a 666. Ten en cuenta que esto podría haberse hecho con una escala, mapeando el dominio de los datos fuentes con el conjunto de colores o con un esquema de colores.
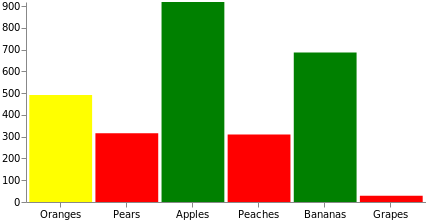
{
"$schema":"https://vega.github.io/schema/vega/v3.json",
"width": 400, "height": 200,
"data": [ {
"name": "vals",
"values": [
{"category": "Oranges"},
{"category": "Pears"},
{"category": "Apples"},
{"category": "Peaches"},
{"category": "Bananas"},
{"category": "Grapes"}
],
"transform": [
{"type": "formula", "as": "count", "expr": "random()*1000"}
]
} ],
"scales": [
{
"name": "yscale",
"type": "linear",
"zero": true,
"domain": {"data": "vals", "field": "count"},
"range": "height"
},
{
"name": "xscale",
"type": "band",
"domain": {"data": "vals", "field": "category"},
"range": "width",
"padding": 0.05
}
],
"axes": [
{"scale": "yscale", "orient": "left"},
{"scale": "xscale", "orient": "bottom"}
],
"marks": [ {
"type": "rect",
"from": { "data": "vals" },
"encode": {
"update": {
"x": {"scale": "xscale", "field": "category"},
"width": {"scale": "xscale", "band": 1},
"y": {"scale": "yscale", "field": "count"},
"y2": {"scale": "yscale", "value": 0},
"fill": [
{"test": "datum.count < 333", "value": "red"},
{"test": "datum.count < 666", "value": "yellow"},
{"value": "green"}
]
}
}
} ]
}
Datos dinámicos con Elasticsearch y Kibana
Ahora que conoces los conceptos básicos, intentemos crear un gráfico de líneas basado en la hora usando algunos datos de Elasticsearch generados aleatoriamente. Esto es similar a lo que ves inicialmente cuando creas un grafo de Vega nuevo en Kibana, excepto que usaremos el lenguaje de Vega en lugar de la opción predeterminada de Kibana, Vega-Lite (la versión simplificada de nivel superior de Vega).
En este ejemplo, codificaremos de forma rígida los datos usando values, en lugar de realizar la búsqueda real con url. De este modo, podemos continuar realizando pruebas en el editor de Vega, que no ofrece soporte para búsquedas de Elasticsearch en Kibana. El grafo será totalmente dinámico dentro de Kibana si reemplazas values con la sección url, como se muestra a continuación.
Nuestra búsqueda hace un recuento de la cantidad de documentos por intervalo de tiempo, usando los filtros de contexto y rango de tiempo según lo que seleccionó el usuario del dashboard. Consulta cómo buscar en Elasticsearch desde Kibana para obtener más información.
"url": {
"%context%": true,
"%timefield%": "@timestamp",
"index": "_all",
"body": {
"aggs": {
"time_buckets": {
"date_histogram": {
"field": "@timestamp",
"interval": {"%autointerval%": true},
"extended_bounds": {
"min": {"%timefilter%": "min"},
"max": {"%timefilter%": "max"}
},
"min_doc_count": 0
}
}
},
"size": 0
}
Cuando la ejecutemos, los resultados se verán similares a lo siguiente (se eliminaron algunos campos no relacionados por cuestiones de brevedad):
"aggregations": {
"time_buckets": {
"buckets": [
{"key": 1528061400000, "doc_count": 1},
{"key": 1528063200000, "doc_count": 45},
{"key": 1528065000000, "doc_count": 49},
{"key": 1528066800000, "doc_count": 17},
...
Como puedes ver, los datos verdaderos que necesitamos se encuentran en la matriz aggregations.time_buckets.buckets. Podemos indicarle a Vega que solo tenga en cuenta esa matriz con "format": {"property": "aggregations.time_buckets.buckets"} dentro de la definición de datos.
Nuestro eje x ya no se basa en categorías, sino en la hora (el campo key es una hora UNIX que Vega puede usar directamente). Por lo tanto, cambiamos el tipo xscale a hora y ajustamos todos los campos para que usen key y doc_count. También debemos cambiar el tipo de marca a line e incluir solo los canales de los parámetros x e y. Y listo, ahora tienes un grafo de líneas. Quizás también te interese personalizar las etiquetas del eje x con los parámetrosformat, labelAngle y tickCount.
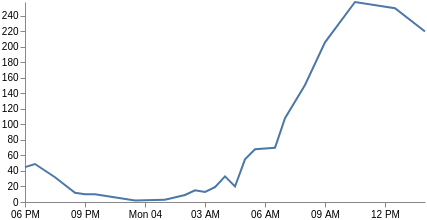
{
"$schema": "https://vega.github.io/schema/vega/v3.json",
"width": 400, "height": 200,
"data": [
{
"name": "vals",
"values": {
"aggregations": {
"time_buckets": {
"buckets": [
{"key": 1528063200000, "doc_count": 45},
{"key": 1528065000000, "doc_count": 49},
{"key": 1528068600000, "doc_count": 32},
{"key": 1528072200000, "doc_count": 12},
{"key": 1528074000000, "doc_count": 10},
{"key": 1528075800000, "doc_count": 10},
{"key": 1528083000000, "doc_count": 2},
{"key": 1528088400000, "doc_count": 3},
{"key": 1528092000000, "doc_count": 9},
{"key": 1528093800000, "doc_count": 15},
{"key": 1528095600000, "doc_count": 13},
{"key": 1528097400000, "doc_count": 19},
{"key": 1528099200000, "doc_count": 33},
{"key": 1528101000000, "doc_count": 20},
{"key": 1528102800000, "doc_count": 55},
{"key": 1528104600000, "doc_count": 68},
{"key": 1528108200000, "doc_count": 70},
{"key": 1528110000000, "doc_count": 108},
{"key": 1528113600000, "doc_count": 151},
{"key": 1528117200000, "doc_count": 206},
{"key": 1528122600000, "doc_count": 258},
{"key": 1528129800000, "doc_count": 250},
{"key": 1528135200000, "doc_count": 220}
]
}
}
},
"format": {"property": "aggregations.time_buckets.buckets"}
}
],
"scales": [
{
"name": "yscale",
"type": "linear",
"zero": true,
"domain": {"data": "vals", "field": "doc_count"},
"range": "height"
},
{
"name": "xscale",
"type": "time",
"domain": {"data": "vals", "field": "key"},
"range": "width"
}
],
"axes": [
{"scale": "yscale", "orient": "left"},
{"scale": "xscale", "orient": "bottom"}
],
"marks": [
{
"type": "line",
"from": {"data": "vals"},
"encode": {
"update": {
"x": {"scale": "xscale", "field": "key"},
"y": {"scale": "yscale", "field": "doc_count"}
}
}
}
]
}
Mantente atento a los futuros artículos del blog sobre Vega. Planeamos hacer otro artículo sobre cómo manejar los resultados de Elasticsearch, en especial las agregaciones y los datos anidados.
Enlaces útiles
- Documentos sobre Vega en Kibana
- Documentación de Vega
- Ejemplos de Vega
- Documentación de Vega-Lite
- Ejemplos de Vega-Lite