Análisis de paquetes de red con Wireshark, Elasticsearch y Kibana
15 de febrero de 2019: A partir de Wireshark 3.0.0rc1, TShark ahora puede generar un archivo de mapeo (Mapping) de Elasticsearch usando la opción -G elastic-mapping.
Para los administradores de red y los analistas de seguridad, una de las capacidades más importantes es la captura y el análisis de paquetes de red. Poder observar cada uno de los metadatos y el contenido transferidos ofrece una visibilidad muy útil y permite supervisar sistemas, depurar errores, y detectar anomalías y ataques.
La captura de paquetes puede ser ad hoc, con la finalidad de depurar un problema específico. En ese caso, puede capturarse el tráfico de una única aplicación o un único servidor, y durante un período específico. O puede ser extensivo, por ejemplo, mediante el uso de un punto de acceso de terminal (TAP) de red externo para capturar todo el tráfico.
Si bien el tráfico de red se envía en formato binario, cada paquete contiene diversos campos que, al usar las herramientas adecuadas, pueden dividirse en números, texto, marcas de tiempo, direcciones IP, etc. Todos estos datos pueden almacenarse en Elasticsearch, y puede explorarlos, buscarlos y visualizarlos en Kibana.
Arquitectura
El procesamiento de datos para la captura y el análisis de red se compone de diversos pasos:
1. Captura de paquetes: Registro del tráfico de paquetes en una red. 2. Análisis de protocolo: Análisis de los diferentes protocolos y campos de la red. 3. Búsqueda y visualización: Exploración de los datos en detalle o en conjunto.
En este artículo del blog, mostraré cómo configurar un procesamiento con Wireshark y Elastic Stack, que puede tener esta apariencia:
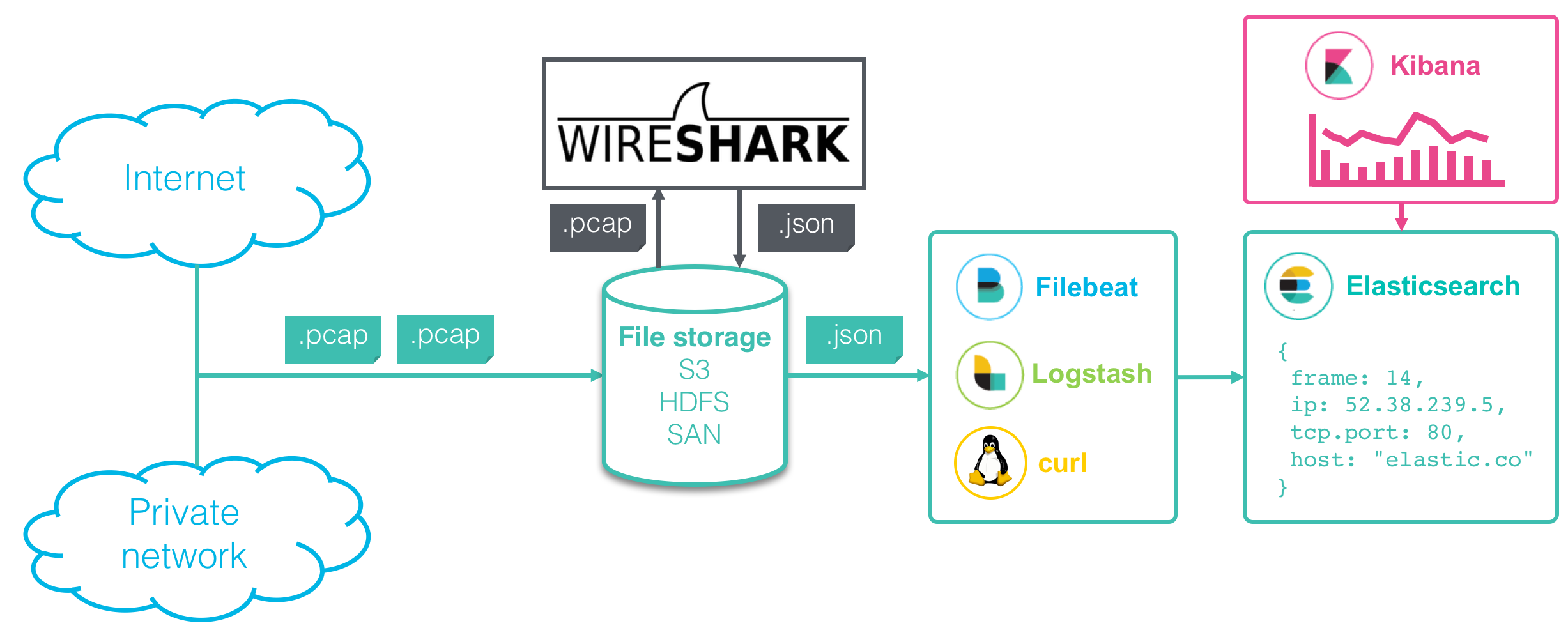
Captura de paquetes
Packetbeat
Ya existe una herramienta en Elastic Stack para indexar los datos de red en Elasticsearch: Packetbeat. Packetbeat puede configurarse para capturar paquetes de red en vivo, además de leer paquetes desde un archivo de captura con la opción -I. Puede reconocer y analizar una variedad de protocolos del nivel de aplicación, como HTTP, MySQL y DNS, además de flujo de red. Sin embargo, la herramienta no está diseñada para la captura y el análisis totales de los paquetes de los cientos de protocolos diferentes que hay en el mundo, y es más apta para monitorear aplicaciones específicas. Su capacidad de unir respuestas con las solicitudes originales e indexar los eventos en un único documento es particularmente útil si trabajará con protocolos específicos.
Wireshark/Tshark
Wireshark es el software de captura y análisis de paquetes más popular, y es de código abierto. Puede reconocer más de 2000 protocolos con más de 200 000 campos. Su interfaz gráfica de usuario (GUI) es familiar para la mayoría de los profesionales dedicados a redes y seguridad.
Además de la GUI, cuenta con la utilidad de línea de comando tshark para capturar tráfico en vivo, además de leer y analizar los archivos de captura. Con respecto a su rendimiento, tshark puede producir informes y estadísticas, y también datos de paquetes analizados en diferentes formatos de texto.
Uno de los formatos de salida que admite tshark desde la versión 2.2 (lanzada en septiembre de 2016) es el formato JSON para la API Elasticsearch Bulk:
tshark -i eth0 -T ek > packets.json
Realiza una captura de paquetes en vivo en la interfaz de red eth0, y el resultado es un archivo packets.json para la API Elasticsearch Bulk.
tshark -r capture.pcap -T ek > packets.json
Lee paquetes de archivos de captura capture.pcap, y el resultado es un JSON en el archivo packets.json para la API Elasticsearch Bulk.
Importación desde Wireshark/tshark
Mapeo en Elasticsearch
Los datos sin procesar en paquetes contienen una extraordinaria cantidad de campos. Como se mencionó anteriormente, Wireshark cuenta alrededor de 200 000 campos individuales. Es muy probable que la gran mayoría de estos campos jamás se busque ni se agregue. En consecuencia, crear un índice en todos estos campos no suele ser la mejor idea. De hecho, dado que una gran cantidad de campos puede enlentecer la indexación y las consultas, Elasticsearch 5.5 limita la cantidad de campos por índice a 1000 por defecto. Asimismo, el resultado de tshark -T ek contiene todos los valores de los campos como texto, sin importar si los datos son, en realidad, texto o números que incluyen marcas de tiempo y direcciones IP, por ejemplo. Sin los tipos correctos de datos, no podrá llevar a cabo operaciones específicas en estos campos (por ejemplo, determinar la duración promedio de los paquetes).
Para indexar números como números, marcas de tiempo como marcas de tiempo, etc., y para evitar una explosión de campos indexados, debe especificar de manera explícita un mapeo en Elasticsearch. A continuación, podrá ver un ejemplo:
PUT _template/packets
{
"template": "packets-*",
"mappings": {
"pcap_file": {
"dynamic": "false",
"properties": {
"timestamp": {
"type": "date"
},
"layers": {
"properties": {
"frame": {
"properties": {
"frame_frame_len": {
"type": "long"
},
"frame_frame_protocols": {
"type": "keyword"
}
}
},
"ip": {
"properties": {
"ip_ip_src": {
"type": "ip"
},
"ip_ip_dst": {
"type": "ip"
}
}
},
"udp": {
"properties": {
"udp_udp_srcport": {
"type": "integer"
},
"udp_udp_dstport": {
"type": "integer"
}
}
}
}
}
}
}
}
}
**"template": "packets-"especifica que esta plantilla debe aplicarse a todos los índices nuevos creados que coincidan con este patrón."dynamic": "false"***especifica que los campos que no están especificados de manera explícita en el mapeo no deben indexarse. Sin embargo, todos los campos sin indexar se almacenarán en Elasticsearch de todos modos, y los verá en los resultados de búsqueda. No obstante, no podrá buscarlos ni agregarlos.r se almacenarán en Elasticsearch de todos modos, y los verá en los resultados de búsqueda. No obstante, no podrá buscarlos ni agregarlos.
Para importar a continuación el resultado de tshark -T ek en Elasticsearch, tiene varias opciones:
1. curl
curl -s -H "Content-Type: application/x-ndjson" -XPOST "localhost:9200/_bulk" --data-binary "@packets.json"
Nota: Si el archivo JSON contiene más de algunos miles de documentos, es posible que tenga que dividirlo en partes más pequeñas y enviarlas a la API Bulk por separado, por ejemplo, con un script. En los sistemas en que esté disponible, puede recurrir a la utilidad
splitpara este fin.
2. Filebeat
Filebeat es muy ligero y puede ocuparse de un conjunto de archivos o directorio para archivos nuevos, y procesarlos de forma automática. Una posible configuración para leer archivos de tshark y enviar los datos del paquete a Elasticsearch tiene esta apariencia:
filebeat.yml
filebeat.prospectors:
- input_type: log
paths:
- "/path/to/packets.json"
document_type: "pcap_file"
json.keys_under_root: true
processors:
- drop_event:
when:
equals:
index._type: "pcap_file"
output.elasticsearch:
hosts: ["localhost:9200"]
index: "packets-webserver01-%{+yyyy-MM-dd}"
template.enabled: false
json.keysunderroot: trueAnálisis de líneas como JSONindex.type: "pcapfile"Líneas de unión de control para la API Elasticsearch Bulktemplate.enabled: falseUso de la plantilla actual que cargamos en Elasticsearch anteriormente
3. Logstash
Al igual que Filebeat, Logstash puede ocuparse de un directorio para nuevos archivos y procesarlos de forma automática. En comparación con Filebeat, puede transformar datos de forma más extensiva que el procesamiento de ingesta de Elasticsearch.
Consulte la sección que describe la transformación de datos a continuación para ver un ejemplo de una configuración de Logstash.
Transformación de datos
Si desea realizar modificaciones a los datos antes de indexarlos en Elasticsearch, hay dos formas de hacerlo:
Procesamiento de ingesta
Elasticsearch tiene el concepto de procesamiento de ingesta desde la versión 5.0. Un procesamiento consiste en una serie de procesadores que pueden aplicar diversos cambios a los datos.
Un ejemplo de procesamiento podría ser así:
PUT _ingest/pipeline/packets
{
"description": "Import Tshark Elasticsearch output",
"processors" : [
{
"date_index_name" : {
"field" : "timestamp",
"index_name_prefix" : "packets-webserver01-",
"date_formats": [ "UNIX_MS" ],
"date_rounding" : "d"
}
}
]
}
Este procesamiento simplemente cambiará el índice sobre el que se escribirán los paquetes (el valor predeterminado especificado por Tshark es packets-YYYY-MM-DD). Para usar este procesamiento al importar datos, debe especificarlo en la URL:
curl -s -H "Content-Type: application/x-ndjson" -XPOST "localhost:9200/_bulk?pipeline=packets" --data-binary "@packets.json"
Consulte la documentación del módulo de ingesta y estos dos artículos del blog para obtener más información: Una nueva forma de ingerir, parte 1, parte 2.
Filebeat y Logstash ofrecen opciones de configuración equivalentes para especificar un proceso de ingesta al enviar datos a Elasticsearch.
Logstash
Logstash es parte de Elastic Stack y sirve para el procesamiento de datos. Puede usarse para leer datos en el formato de la API Elasticsearch Bulk y realizar transformaciones y enriquecimientos más complejos sobre los datos antes de enviarlos a Elasticsearch.
Una posible configuración podría ser la siguiente:
logstash.conf
input {
file {
path => "/path/to/packets.json"
start_position => "beginning"
}
}
filter {
# Drop Elasticsearch Bulk API control lines
if ([message] =~ "{\"index") {
drop {}
}
json {
source => "message"
remove_field => "message"
}
# Extract innermost network protocol
grok {
match => {
"[layers][frame][frame_frame_protocols]" => "%{WORD:protocol}$"
}
}
date {
match => [ "timestamp", "UNIX_MS" ]
}
}
output {
elasticsearch {
hosts => "localhost:9200"
index => "packets-webserver01-%{+YYYY-MM-dd}"
document_type => "pcap_file"
manage_template => false
}
}
El filtro grok extrae el nombre interno del protocolo de red del campo frame_frame_protocols (que tiene el formato «protocolo:protocolo:protocolo», por ejemplo, «eth:ethertype:ip:tcp:http») en un campo de «protocolo» de nivel superior.
Visualización y exploración de paquetes de red en Kibana
En Kibana, ahora puede explorar los paquetes y crear visualizaciones.
Por ejemplo:
![Gráfico de torta que muestra la distribución de los protocolos de red][13] *Gráfico de torta que muestra la distribución de los protocolos de red
Configuraciones útiles de Kibana
Dado que los datos de red de Wireshark tienen un formato diferente a, por ejemplo, syslog, puede que sea recomendable cambiar algunas configuraciones en Kibana (pestaña Management [Administración] -> Kibana Advanced Settings [Configuración avanzada de Kibana]).
shortDots:enable = true
format:number:defaultPattern = 0.[000] (2)
timepicker:timeDefaults = {
"from": "now-30d",
"to": "now",
"mode": "quick"
}
shortDots:enable = trueacorta los nombres largos de campos anidados, por ejemplo, layer.frame.frame_frame_number a l.f.frame_frame_numberformat:number:defaultPattern = 0.[000]cambia el formato de visualización para no mostrar el separador de milestimepicker:timeDefaultscambia el período predeterminado sobre el cual Kibana muestra datos por los últimos 30 días, suponiendo que las capturas de paquetes, por lo general, serán históricas y en tiempo real
Conclusión
Elasticsearch es un almacenamiento de datos escalable y de baja latencia, apto para guardar datos en paquete y proporcionar acceso a estos casi en tiempo real. Los administradores de redes y de IT, además de los analistas de seguridad y profesionales de otras áreas, obtienen grandes beneficios por poder explorar paquetes de red de forma interactiva y al instante en un navegador web, y por poder compartir las búsquedas y las visualizaciones con otros.
[13]: https://api.contentstack.io/v2/uploads/598385ba24760200499120ed/download?uid=blt06ed83ed65dba82center code here