1.000 % Leistungssteigerung mit Elasticsearch
Voxpopme ist eine der weltweit führenden Plattformen für Videoanalysen. Das Unternehmen wurde 2013 unter der einfachen Prämisse gegründet, dass Videos der beste Weg sind, um Hunderten oder Tausenden von Personen gleichzeitig eine Stimme zu geben. Unsere einzigartige Software analysiert von Verbrauchern aufgenommene Videos und Inhalte im Langformat (z. B. Fokusgruppen) von einer Vielzahl von Umfragepartnern und liefert wertvolle Marketingdaten in Form von Diagrammen, durchsuchbaren Themen und konfigurierbaren Präsentationen.
Seit unserem Launch haben wir vier Jahre damit verbracht, die Einblicke, die Kunden aus Videos gewinnen können, zu optimieren und zu automatisieren, um die Barrieren zwischen Marken und ihren Kunden einzureißen. Für ein optimales Kundenerlebnis verwenden wir die neuesten NLP-Tools von IBM Watson, um die Gefühlslage der Umfrageteilnehmer zu identifizieren und zu aggregieren. Außerdem arbeiten wir exklusiv mit Affectiva zusammen, um Gesichtsausdrücke zu analysieren. 2017 haben wir Elasticsearch in unsere Werkzeugpalette aufgenommen, um unseren Kunden das bestmögliche Erlebnis zu bieten.
Der Legacy-Infrastruktur entwachsen
Der Technologie-Stack von Voxpopme hat in den vergangenen zwölf Monaten eine tiefgreifende Änderung durchlaufen. Im Jahr 2017 hat unsere Plattform eine halbe Million Videoumfragen verarbeitet – so viel wie in den vorherigen vier Jahren zusammen – und für 2018 erwarten wir, dass sich dieser Wert verdoppelt. Dabei traten Skalierungsprobleme auf, die zwar zu den angenehmeren Problemen zählen, aber dennoch gelöst werden müssen.
Die Ursache lag in unserem Legacy-System, das aus einer monolithischen PHP-Anwendung bestand, die für ihre Kernfunktionen mit einer Vielzahl verschiedener Datenbanken kommunizierte. Die Logik für diese Trennung der Daten war zu Anfang noch sinnvoll:
- Ein Großteil unserer Daten befand sich in einer MySQL-Datenbank. Dazu gehörten unter anderem Benutzer und ursprüngliche Videoantworten, also strukturierte relationale Daten, die über Fremdschlüssel miteinander verknüpft sind und mit einer RESTful API erstellt, ausgelesen, aktualisiert und gelöscht werden.
- Kundendaten wurden in einem MongoDB-Cluster gespeichert und konnten in jedem beliebigen Format bereitgestellt werden. Auf diese Weise konnten die Kunden die Videos mit ihrer eigenen Terminologie markieren, filtern und mit Anmerkungen versehen.
- Wir haben die Abschriften der Videos unserer Teilnehmer in einem kleinen Elasticsearch-Cluster gespeichert, das wir für Volltextsuchen verwendet haben.
Dieser Ansatz hat über lange Zeit hervorragend funktioniert, hatte jedoch ein offensichtliches Problem.
Rechenleistung ist weder kostenlos noch unbegrenzt.
Eine Suche in unserer Plattform kann sehr einfach oder auch extrem komplex sein. Im einfacheren Fall können unsere Benutzer nach dem Primärschlüssel einer Videoantwort suchen. Dafür reicht eine einfache Abfrage an die indexierte MySQL-Datenbank aus.
Was geschieht jedoch, wenn ein Benutzer nach einer indexierten Ganzzahl oder nach eigenen Freiformdaten filtern und die Ergebnisse auf alle Teilnehmer eingrenzen möchte, die ein bestimmtes Thema erwähnen? Ein Beispiel:
Suche alle Datensätze mit Antwortdatum zwischen dem ersten und dem letzten Tag im Juni und einem Haushaltseinkommen der Teilnehmer von 100.000-125.000 $, in denen die Wortkombination „zu teuer“ vorkommt.
Unser bisheriger Ansatz:
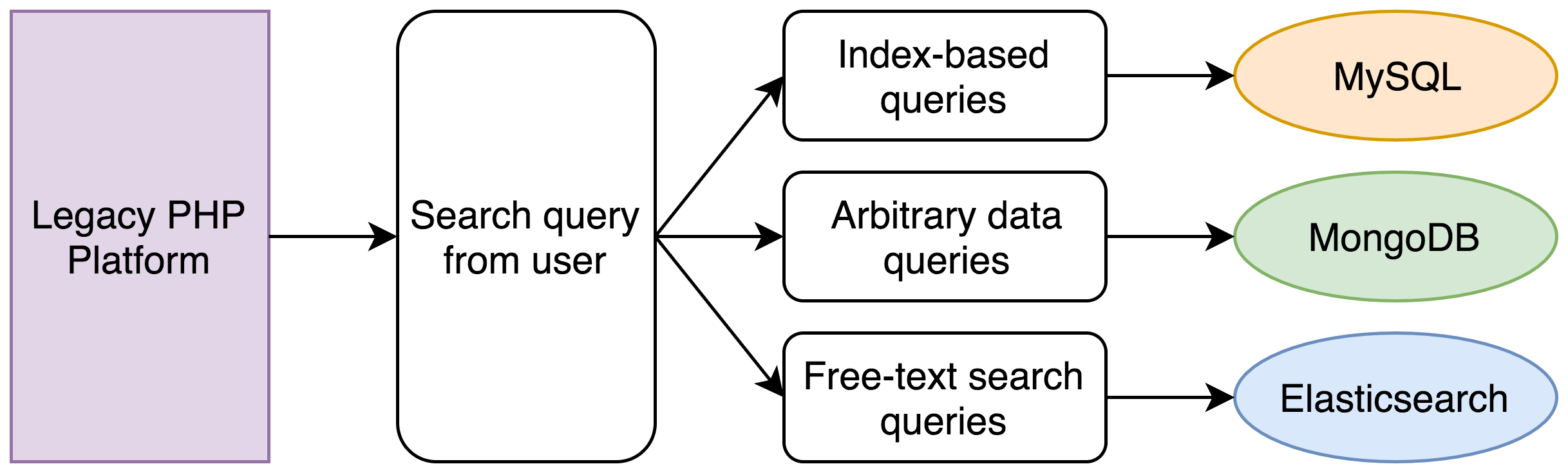
In unserem Legacy-System wurden die folgenden Schritte ausgeführt:
- Eine MySQL-Abfrage sucht sämtliche Datensätze im genannten Datumsbereich.
- Eine MongoDB-Abfrage sucht alle Datensätze im Einkommensbereich (das Einkommen ist nur ein Beispiel, unsere Kunden können beliebige Informationen bei uns speichern).
- Eine Elasticsearch-Abfrage sucht alle Datensätze mit einer passenden Wortkombination in der Abschrift.
- Eine Vereinigung der IDs aller drei Datensätze wird berechnet.
- Eine neue Reihe von MySQL- und MongoDB-Abfragen ruft die vollständigen Datensätze für die einzelnen Einträge ab.
- Die Einträge werden sortiert und in Seiten unterteilt.
Für einen einfachen Satz von Suchkriterien sind oft fünf separate Datenbankabfragen erforderlich. Zu Anfang dauerte dieser Vorgang weniger als eine Sekunde, aber angesichts der Daten aus fünf Jahren und der Tatsache, dass PHP in einem einzigen Thread ausgeführt wird, müssen die Datenbankabfragen nacheinander ausgeführt werden und dauern inzwischen oft bis zu 30 Sekunden.
Dieses Modell hat uns eine schnelle Markteinführung ermöglicht und über mehrere Jahre hervorragende Dienste geleistet, ließ sich jedoch nicht ohne Weiteres skalieren. Als uns auffiel, dass das Erlebnis unserer Benutzer beeinträchtigt wurde, haben wir beschlossen, den Suchmechanismus neu zu schreiben.
Wir hatten bereits Erfahrungen mit Elasticsearch aus unserem bisherigen Stack gesammelt und haben uns mit einem Elastic-Vertriebsmanager zusammengesetzt, um über unsere Probleme bei komplexen Suchvorgängen über Daten an verteilten Speicherorten zu sprechen. Wir mussten unbedingt eine passende Lösung finden - unser Produkt basiert darauf, Berechnungen zu unseren Daten schnell und effizient darzustellen. Engpässe beim Abrufen der Daten sind völlig inakzeptabel.
Wir haben in Erwägung gezogen, unser vorhandenes MongoDB-Cluster zu erweitern, aber nach einem kurzen Telefongespräch mit Elastic hat das Entwicklungsteam beschlossen, dass Elasticsearch die einzige Lösung ist, mit der wir unsere Daten mühelos speichern, durchsuchen und bearbeiten (z. B. Aggregationen) können.
Unser erster Eindruck
Für unsere Textsuche hatten wir bis dahin ein Elasticsearch-Cluster der Version 1.5 von Compose.io verwendet. Da wir für den Rest unserer Infrastruktur umfassend in AWS investiert haben, entschieden wir uns ursprünglich für Amazon Elasticsearch Service mit einem Cluster der Version 5.x.
In unserem neuen Modell werden alle verteilten Daten eines Datensatzes in einem einzigen Elasticsearch-Dokument aufbewahrt. Dazu verwenden wir verschachtelte Werte mit bekannten Schlüsseln für die komplexeren Freiformdaten unserer Kunden. Anschließend lässt sich jede beliebige Benutzersuche mit einer einzigen Elasticsearch-Abfrage ausführen.
Innerhalb von einer Woche hatten wir eine einfache Machbarkeitsstudie mit einigen Tausend Dokumenten eingerichtet, und unser erster Eindruck von den Abfragen in Kibana war so gut, dass wir beschlossen, unseren Backend-Suchmechanismus von Grund auf neu zu schreiben.
Unser neuer Ansatz:
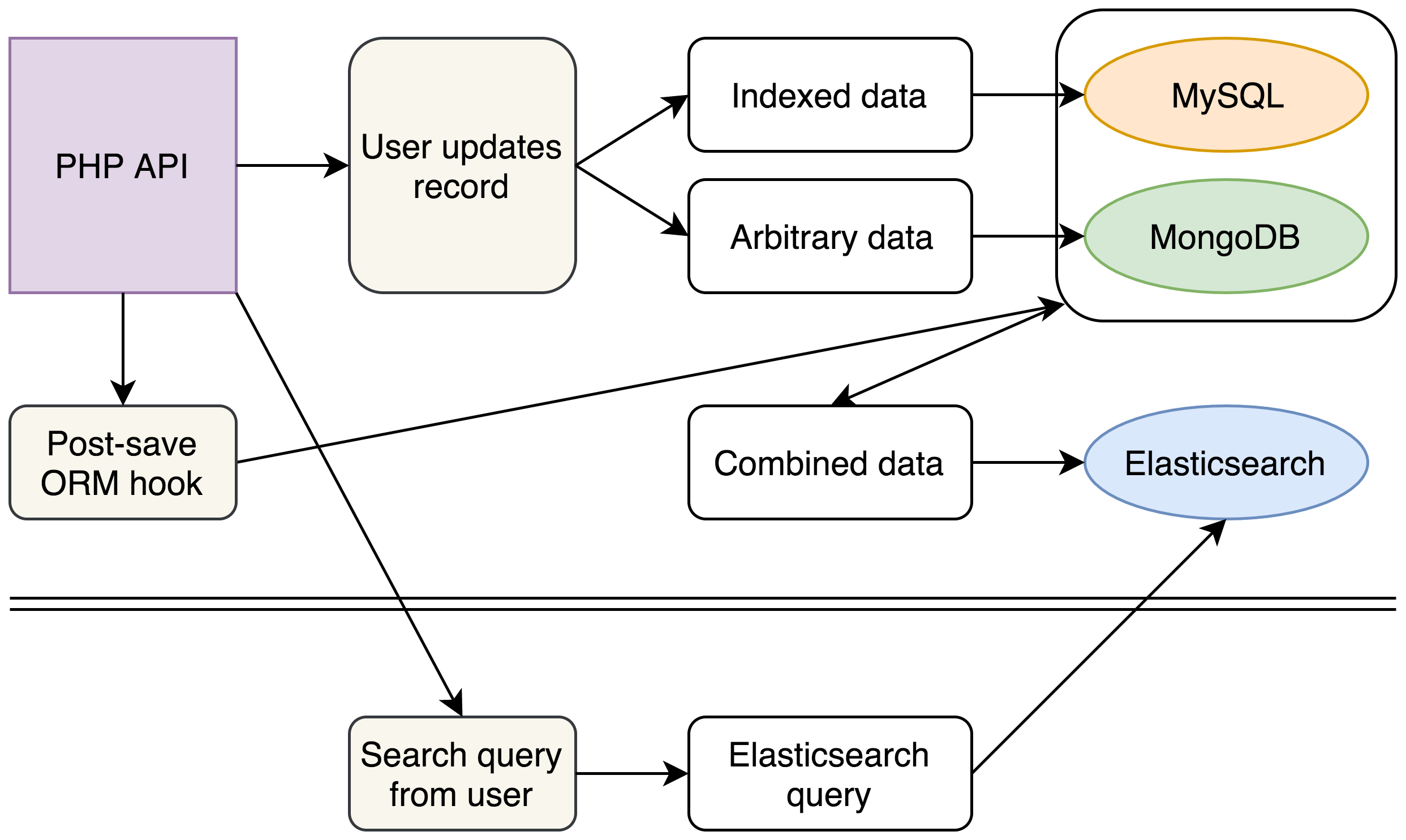
(Vorerst haben wir unsere Legacy-Datenbanken nicht verändert, aber mit der Einführung unseres neuen Elasticsearch-Clusters für komplexe Suchen können wir darauf hinarbeiten, MongoDB komplett aus unserem Stack zu entfernen)
In unserem neuen Stack schreiben wir weiterhin wie bisher nach MySQL und MongoDB. Jeder Schreibvorgang löst jedoch auch ein Ereignis aus, das sämtliche Daten aus den verschiedenen Quellen sammelt und in einem einzigen JSON-Dokument zusammenfasst, das anschließend in Elasticsearch eingefügt wird.
Im Backend haben wir einen neuen Suchmechanismus geschrieben, der komplexe Elasticsearch-Abfragen aus den vorhandenen Suchabfragen unserer Benutzer generiert und konnten den Legacy-Code für MySQL- und MongoDB-Abfragen komplett entfernen. Die Abfragen an ein einziges Elasticsearch-Cluster liefern uns dieselben Daten in einem Bruchteil der Zeit.
Mit der Struktur unserer Elasticsearch-Dokumente konnten wir die Leistung weiter verbessern. Unsere API liefert JSON-Dokumente zurück, daher konnten wir unsere Elasticsearch-Dokumente exakt an unsere API-Ausgaben anpassen, um weitere Sekunden zu sparen, die bisher darauf verwendet wurden, Daten aus MySQL und MongoDB zu kombinieren und neu zu ordnen.
Wir konnten den verschiedenen Stakeholdern in unserem Unternehmen eine vorläufige Leistungssteigerung von 1.000 % für wichtige Teile unserer Plattform melden.
Das ist nicht der Anbieter, den ihr sucht
Nachdem wir allen Beteiligten eine Leistungssteigerung von 1.000 % versprochen hatten, mussten wir sämtliche Daten indexieren und hoffen, dass wir unser Versprechen unter Last einlösen konnten.
Nachdem wir all unsere Daten indexiert hatten, bereitete uns das AWS-Cluster leider Probleme.
Wenn wir die Daten nur einmalig indexieren und oft abfragen müssen, wäre alles in Ordnung. Unser Modell basiert jedoch darauf, die Daten bei jeder Änderung in MySQL oder MongoDB neu zu kombinieren und zu indexieren. Dies kann zu Zeiten mit besonders hoher Suchlast Tausende von Malen geschehen.
Wir stellten Leistungseinbußen fest, und manche Abfragen dauerten bis zu mehrere Sekunden. Dies führte wiederum dazu, dass unsere PHP-Anwendung nicht mehr reagierte, wodurch MySQL-Verbindungen offen blieben, und ein schrecklicher Dominoeffekt hat unseren gesamten Stack lahmgelegt.
Diese Probleme traten zur gleichen Zeit auf, als Elastic{ON} nach London kam, daher nutzten wir die Gelegenheit und sprachen am AMA-Stand mit einem Elastic-Vertreter über Clustergrößen und über unsere Probleme. Wir erwähnten, dass unsere Abfragen im besten Fall etwa 40 ms dauerten, und wurden darauf hingewiesen, dass wir mit den Standardeinstellungen Antwortzeiten von etwa 1 ms erreichen könnten, wenn wir den Elastic Cloud-Dienst von Elastic anstelle von AWS verwenden.
Die Verfügbarkeit von Elastic Stack Features (ehemals X-Pack) in der Elastic Cloud war ein Riesenvorteil für uns, da wir zu diesem Zeitpunkt nur eingeschränkte Logging- und Auswertungssysteme hatten. Da X-Pack im AWS Elasticsearch-Angebot nicht verfügbar ist, haben wir beschlossen, parallel dazu einen Elastic Cloud-Cluster für Tests einzurichten. Wenn die Leistung auch nur gleich gut wäre wie im AWS-Cluster, würden wir allein aufgrund der anderen Vorteile umstellen.
Die GUI der Elastic Cloud ist sehr aufgeräumt und benutzerfreundlich. Für die Indexierung mussten wir unsere Umgebung skalieren und zusätzliche Worker für die Datenverarbeitung hinzufügen und waren von der einfachen Clusterverwaltung beeindruckt: es reicht aus, einen Schieberegler nach links oder rechts zu ziehen und auf „Aktualisieren“ zu klicken.
Nachdem wir unsere Daten im neuen Cluster erfolgreich indexiert hatten, konnten wir komplexe Abfragen in nur 2 ms und praktisch ohne Sperren ausführen (seitdem haben wir unser System weiter optimiert, und Sperren gehören der Vergangenheit an). Einige Millisekunden hier und da machen zwar für die Endbenutzer keinen Unterschied, aber die Technikbegeisterten unter wird es freuen, dass wir die Latenz auf 5 % des vorherigen Werts reduziert haben.
Optimale Nutzung unserer Daten
Wir wollten jedoch nicht Oldschool sein und Elasticsearch nur als Suchmaschine für unsere Benutzer einsetzen. Viele der Erfolgsgeschichten für diese Technologie hängen mit dem Logging zusammen, und uns wurde schnell klar, dass wir keine Ausnahme sind.
Wir haben ein separates Logging-Cluster zum Verarbeiten der Logs aus unseren Kubernetes-Pods eingerichtet, haben dadurch viel bessere Einblicke in die Integrität unserer Server als zuvor und können viel schneller auf Probleme reagieren.
Außerdem konnten wir den Benutzern unserer Plattform etwas Ähnliches anbieten. Wir haben Aggregationen verwendet, um die Daten unserer Benutzer grafisch aufzubereiten. Allein diese Funktion war eine hervorragende Ergänzung für unsere Plattform und ein reiner Nebeneffekt der Datenaufbewahrung in Elasticsearch.
Im Verlauf der letzten Monate haben wir unsere Prozesse überarbeitet und verfeinert, und die Leistung unserer Elasticsearch-Cluster verbessert sich von Woche zu Woche. Wir haben unter anderem große Mengen an Arbeitsspeicher eingespart, indem wir Felder mit fielddata aus unserem primären Cluster in ein kleineres Cluster verschoben haben, auf das weniger häufig zugegriffen wird (unsere Speicherauslastung ist von 75 % auf 25 % gefallen). Außerdem haben wir unseren Code optimiert und schreiben neue Daten als Block und nicht mehr On-Demand, um die Reaktionszeiten des Clusters unter hoher Last zu verbessern.
Für die Zukunft haben wir geplant, Elasticsearch für umfassende Analysen unserer internen Unternehmensdaten einzusetzen. Elasticsearch hat sich als Kern unseres kundenseitigen Produkts bewährt, und wir haben bereits damit begonnen, unsere eigenen Daten in Elasticsearch-Indizes zu speichern und werden den Elastic Stack einsetzen, um Erkenntnisse über unsere Betriebseffizienz als Unternehmen zu gewinnen.
 David Maidment ist Senior Software Engineer bei Voxpopme und konzentriert sich darauf, die Codebasis der Plattform angesichts des exponentiellen Wachstums des Unternehmens für die Zukunft fit zu machen.
David Maidment ist Senior Software Engineer bei Voxpopme und konzentriert sich darauf, die Codebasis der Plattform angesichts des exponentiellen Wachstums des Unternehmens für die Zukunft fit zu machen.
 Andy Barraclough ist Mitgründer und CTO von Voxpopme. Er leitet die technische Abteilung und koordiniert die langfristige Vision für das Unternehmen.
Andy Barraclough ist Mitgründer und CTO von Voxpopme. Er leitet die technische Abteilung und koordiniert die langfristige Vision für das Unternehmen.