Erste Schritte mit ES|QL (Elasticsearch Query Language)
Mit ES|QL direkt in Discover Aggregationen, Visualisierungen und Alerts erstellen und schneller Einblicke erhalten

 Share on Twitter
Share on TwitterAuf Twitter teilen

 Share on LinkedIn
Share on LinkedInAuf LinkedIn teilen

 Share on Facebook
Share on FacebookAuf Facebook teilen

 Share by Email
Share by EmailPer E-Mail teilen

 Print this page
Print this pageDrucken
Was ist ES|QL (Elasticsearch Query Language)?
ES|QL (Elasticsearch Query Language) ist die neue und innovative Pipe-basierte Abfragesprache von Elastic®. Mit ihren leistungsstarken Berechnungs- und Aggregationsmöglichkeiten sorgt sie für eine deutliche Beschleunigung Ihrer Prozesse zur Datenanalyse und Bedrohungsuntersuchung.
Nutzen Sie ES|QL, um einfacher und effizienter sich entwickelnde Cyberangriffe zu identifizieren oder Produktionsprobleme auszumachen.
Mit ES|QL wird nicht nur das Durchsuchen, Aggregieren und Visualisieren riesiger Datenbestände einfacher, sondern die Nutzer:innen können auch erweiterte Features wie Lookups und Echtzeit-Verarbeitung nutzen – alles von einem einzigen Bildschirm in Discover aus.
ES|QL erweitert den Elastic Stack um drei leistungsstarke Funktionen
-
Eine neue und schnelle verteilte und dedizierte Abfrage-Engine zur Unterstützung von _query. Die neue ES|QL-Abfrage-Engine liefert erweiterte Suchfunktionen mit paralleler Verarbeitung, was sich positiv auf die Geschwindigkeit und Effizienz von Suchen auswirkt – unabhängig von Datenquelle und ‑struktur. Die Leistung der neuen Engine wird gemessen und öffentlich gemacht. Die Performance-Benchmarks finden Sie in diesem öffentlich zugänglichen Dashboard.
-
Eine neue und leistungsstarke Pipe-basierte Abfragesprache. ES|QL ist eine neue, Pipe-basierte Abfragesprache von Elastic, die Datenuntersuchungen transformiert, vereinfacht und verbessert. Mehr zu den Funktionen von ES|QL finden Sie in der Dokumentation.
-
Ein neuer und zentralisierter Prozess zur Datenerkundung/-untersuchung, der die Problemlösung beschleunigt, denn er erlaubt es, Aggregationen und Visualisierungen im selben Bildschirm zu erstellen. So wird für einen unterbrechungsfreien Workflow gesorgt.
Warum haben wir Zeit und Mühe in ES|QL investiert?
Unsere Nutzer:innen benötigen agile Tools, die Daten nicht nur präsentieren, sondern auch effiziente Methoden für deren Nutzung sowie die Möglichkeit bieten, in Echtzeit auf Erkenntnisse zu reagieren und Daten nach dem Ingestieren zu verarbeiten.
Da wir uns dem Ziel verschrieben haben, es den Nutzer:innen immer leichter zu machen, haben wir uns entschlossen, in ES|QL zu investieren. ES|QL wurde so entwickelt, dass es Anfänger:innen einen leichten Einstieg ermöglicht und gleichzeitig Expert:innen alle Funktionen bietet, die sie benötigen. Dank der intuitiven Benutzeroberfläche von ES|QL können Nutzer:innen schnell und ohne steile Lernkurven loslegen und in ihre Daten eintauchen. Die Autovervollständigung und die In-App-Dokumentation machen das Erstellen erweiterter Abfragen so einfach wie nur irgend möglich.
Außerdem zeigt ES|QL Ihnen nicht einfach nur Zahlen an – es erweckt diese auch zum Leben. Kontextbezogene Visualisierungen, die von der Suggestion-Engine Lens unterstützt werden, passen sich automatisch an das Wesen Ihrer Suchanfragen an und bieten einen klaren Überblick über Ihre Erkenntnisse.
Darüber hinaus spiegelt die direkte Integration in die Dashboard- und Alerting-Funktionen unsere Vision einer kohärenten End-to-End-Experience wider.
Im Kern war unsere Investition in ES|QL eine direkte Reaktion auf das Feedback aus unserer Community – ein Schritt in Richtung eines besser vernetzten, aufschlussreicheren und effizienteren Workflows.
Tieferes Eintauchen in Security- und Observability-Anwendungsfälle
Unser Engagement für ES|QL entspringt auch einem tiefen Verständnis für die Herausforderungen, mit denen unsere Nutzer:innen (wie z. B. SREs, DevOps und Threat Hunter) konfrontiert sind.
Für SREs ist Observability unverzichtbar. Jede Sekunde Downtime oder Störung kann sich kaskadenartig auf die User Experience und folglich auf das Betriebsergebnis auswirken. Ein Beispiel für eine ES|QL-Funktion, von der SREs profitieren, ist die Alerting-Funktion: Bei ihr liegt der Schwerpunkt darauf, nicht isolierte Incidents hervorzuheben, sondern aussagekräftige Trends sichtbar zu machen. So können SREs proaktiv Ineffizienzen im System oder Systemausfälle aufspüren und beheben. Das reduziert das Rauschen und sorgt dafür, dass sich die SREs auf die tatsächlichen Bedrohungen der Systemstabilität konzentrieren und zeitnah und effektiv reagieren können.
DevOps-Teams befinden sich in einem nie aufhörenden Wettkampf mit der Zeit – ständig müssen verschiedene Updates, Patches und neue Features bereitgestellt werden. Die neue und leistungsstarke Datenerkundung und Datenvisualisierung von ES|QL hilft ihnen, die Auswirkungen eines jeden Deployments schneller zu beurteilen, den Systemzustand zu überwachen und Feedback in Echtzeit zu erhalten. Das verbessert nicht nur die Qualität von Deployments, sondern ermöglicht bei Bedarf auch rasche Kursänderungen.
Threat Hunter profitieren in einer sich dynamisch entwickelnden Security-Landschaft, in der die einzige Konstante die Veränderung ist, von ES|QL-Funktionen wie dem ENRICH-Feature. Damit lassen sich Daten aus unterschiedlichen Datasets abrufen und so versteckte Muster oder Anomalien aufdecken, die auf eine Sicherheitsbedrohung hindeuten könnten. Und dank der kontextbezogenen Visualisierungen sehen sie nicht nur Rohdaten, sondern erhalten auch visuell präsentierte verwertbare Erkenntnisse. Dadurch lassen sich potenzielle Bedrohungen sehr viel schneller eindeutig erkennen und entsprechende Schwachstellen schneller schließen.
Ganz gleich, ob Sie als SRE versuchen, sich einen Reim auf plötzlich ansteigende Serverlasten zu machen, ob Sie als DevOps-Expertin die Auswirkungen der neuesten Version bewerten oder ob Sie als Threat Hunter eine potenzielle Sicherheitslücke untersuchen – ES|QL unterstützt Sie bei Ihrer Arbeit, statt die Aufgabe zu verkomplizieren.
In den nächsten Abschnitten erfahren Sie, wie Sie mit ES|QL loslegen können, und wir zeigen Ihnen anhand einiger konkreter Beispiele, wie Ihnen ES|QL beim Erkunden Ihrer Daten helfen kann.
Erste Schritte mit ES|QL in Kibana
Wenn Sie ES|QL nutzen möchten, gehen Sie zu Discover und wählen Sie unter „Data views“ einfach Try ES|QL aus. Das ist intuitiv und ganz unkompliziert.
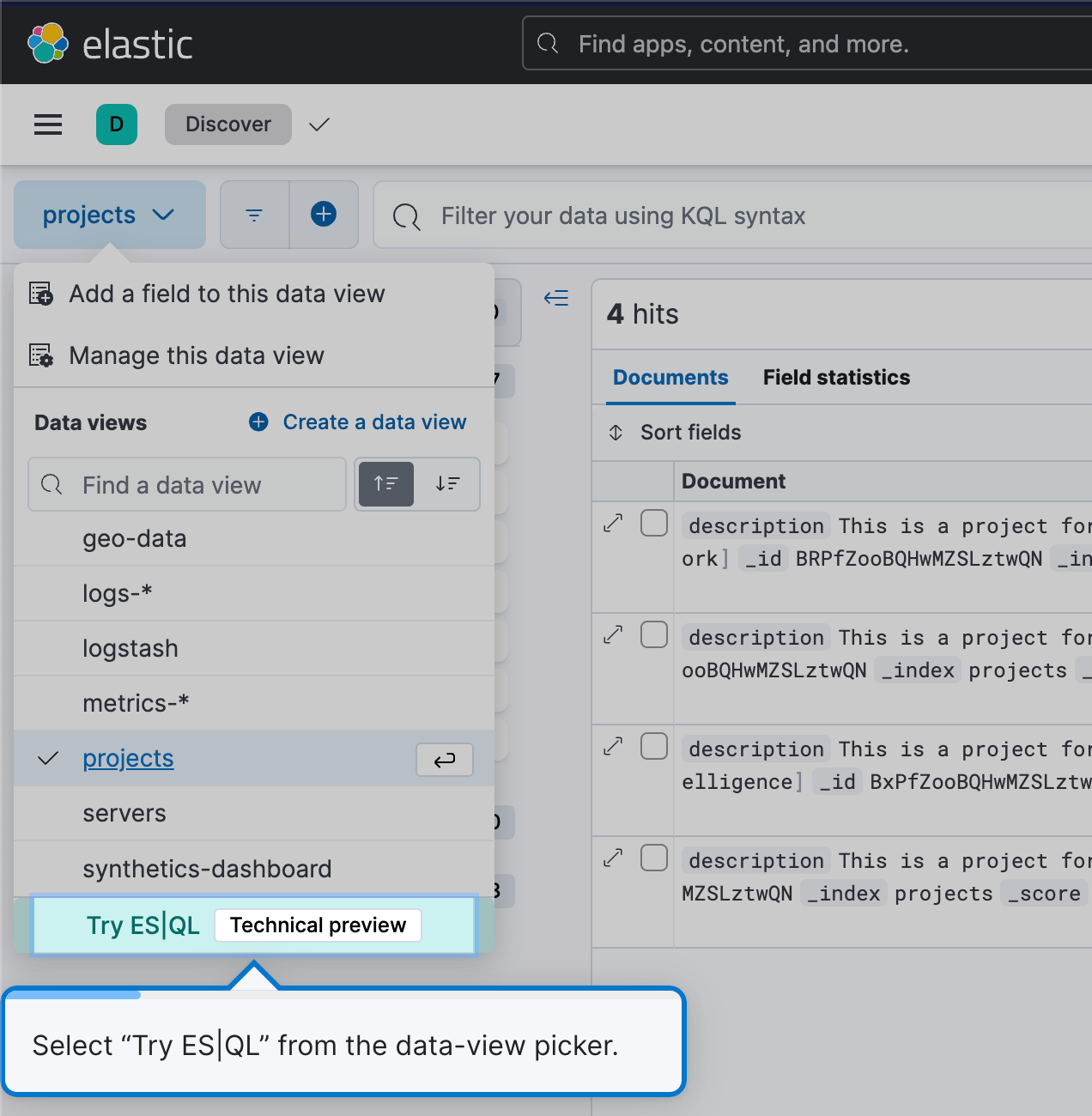
Sie gelangen in den ES|QL-Modus in Discover.
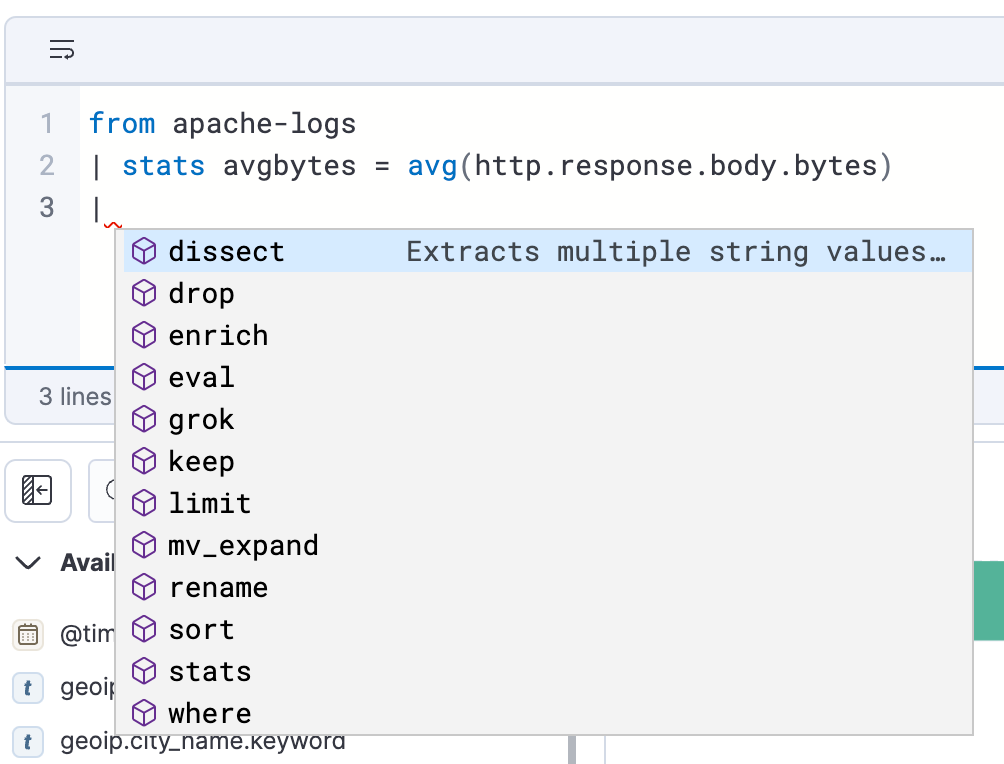
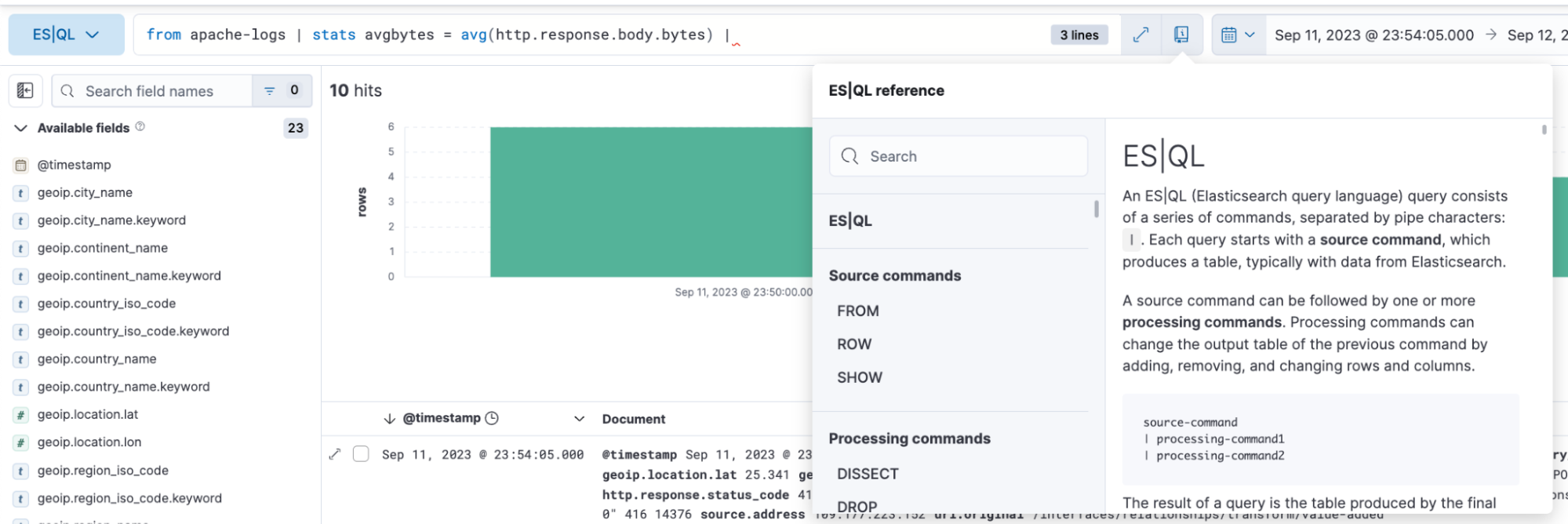
Effizientes und einfaches Erstellen von Abfragen
ES|QL in Discover bietet Autovervollständigung und In-App-Dokumentation und ermöglicht es so ganz einfach, direkt über die Suchleiste leistungsfähige Suchanfragen zu erstellen.
Analysieren und Visualisieren von Daten mit ES|QL
Mit ES|QL können Sie umfangreiche und effektive Datenerkundungen durchführen. Die Abfragesprache erlaubt die Durchführung von Ad-hoc-Datenerkundungen innerhalb von Discover, das Erstellen von Aggregationen, das Transformieren von Daten, das Anreichern von Datasets und vieles andere mehr – direkt aus der Suchleiste. Die Ergebnisse werden – abhängig von der jeweiligen Suchanfrage – in tabellarischer Form oder als Visualisierungen präsentiert.
Im Folgenden finden Sie Beispiele für ES|QL-Suchanfragen für Observability-Zwecke mit Darstellung der Ergebnisse in tabellarischer Form und als visuelle Darstellung.
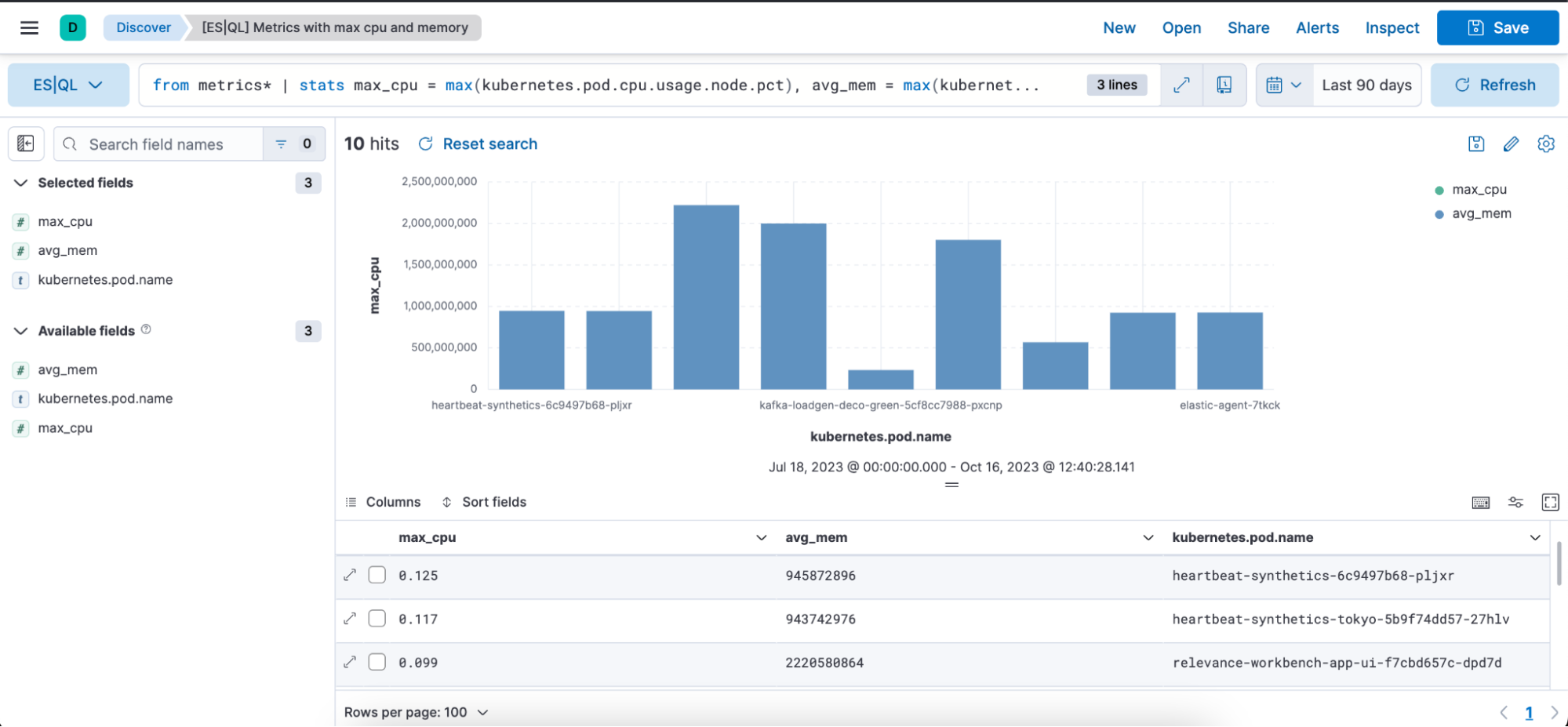
ES|QL-Abfrage zum Abrufen von Metriken:
from metrics*
| stats max_cpu = max(kubernetes.pod.cpu.usage.node.pct), max_mem = max(kubernetes.pod.memory.usage.bytes) by kubernetes.pod.name
| sort max_cpu desc
| limit 10Die Abfrage oben demonstriert die Verwendung des folgenden Quellbefehls sowie der folgenden Aggregationsfunktionen und Verarbeitungsbefehle:
Quellbefehl from (Dokumentation)
from metrics*: Dieser Befehl löst eine Abfrage aus Indexmustern aus, die mit dem Muster „metrics*“ übereinstimmen. Das Sternchen (*) fungiert als Platzhalter: Es wird in allen Indexmustern gesucht, deren Name mit „metrics“ beginnt.
stats…by-Aggregationen (Dokumentation), max (Dokumentation) und by (Dokumentation)
Dieses Segment aggregiert Daten anhand konkreter Statistikwerte. Es ist wie folgt aufgebaut:
max_cpu=max(kubernetes.pd.cpu.usage.node.pct): Für jeden eindeutigen „kubernetes.pod.name“ wird der maximale Prozentsatz der CPU-Auslastung ermittelt und der Wert wird in einer neuen Spalte namens „max_cpu“ gespeichert.
max_mem = max(kubernettes.pod.memory.usage.bytes): Für jeden eindeutigen „kubernetes.pod.name“ wird die maximale Speicherauslastung in Byte ermittelt und der Wert wird in einer neuen Spalte namens „avg_mem“ gespeichert.
Verarbeitungsbefehle (Dokumentation)
- sort (Dokumentation)
- limit (Dokumentation)
sort max_cpu desc: Dieser Befehl sortiert die Ergebnisdatenzeilen absteigend nach der Spalte „max_cpu“. Das bedeutet, dass die Zeile mit dem höchsten „max_cpu“-Wert ganz oben steht.
limit 10: Dieser Befehl beschränkt die Ausgabe nach dem Sortieren auf die 10 Zeilen mit den besten Übereinstimmungen.
Zusammengefasst macht die Abfrage Folgendes:
- Sie gruppiert mithilfe eines Indexmusters Daten aus allen Metriken-Indizes.
- Sie aggregiert die Daten, um für jeden separaten Kubernetes-Pod den maximalen Prozentsatz der CPU-Auslastung und die maximale Speicherauslastung zu ermitteln.
- Sie sortiert die aggregierten Daten absteigend nach der maximalen CPU-Auslastung.
- Sie gibt nur die 10 Zeilen mit der höchsten CPU-Auslastung aus.
Kontextbezogene Visualisierungen: Beim Schreiben von ES|QL-Abfragen in Discover erhalten Sie visuelle Darstellungen, die von der Support-Engine Lens unterstützt werden. Die Art der Visualisierung richtet sich nach dem Wesen der Abfrage, also danach, ob es sich um eine Metriken-Abfrage, eine Histogramm-Heatmap-Abfrage usw. handelt.
Unten sehen Sie eine visuelle Darstellung in Form eines Balkendiagramms und eine tabellarische Darstellung der Abfrage oben mit den Spalten „max_cpu“, „avg_mem“ und „kubernetes.pod.name“:
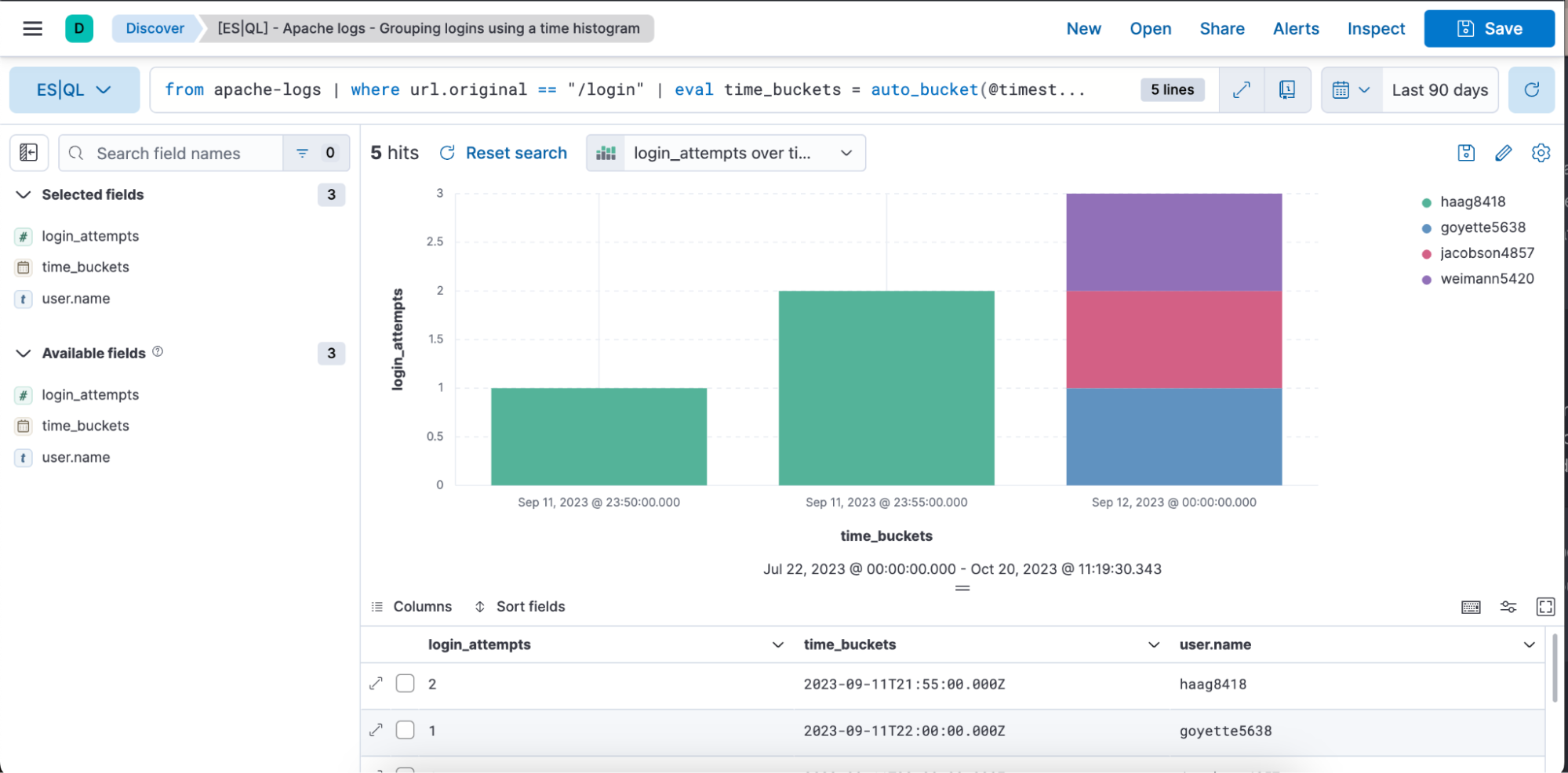
Beispiel für eine ES|QL-Abfrage für Observability-Zwecke mit Zeitreihendaten:
from apache-logs |
where url.original == "/login" |
eval time_buckets = auto_bucket(@timestamp, 50, "2023-09-11T21:54:05.000Z", "2023-09-12T00:40:35.000Z") |
stats login_attempts = count(user.name) by time_buckets, user.name |
sort login_attempts descDie Abfrage oben demonstriert die Verwendung des folgenden Quellbefehls sowie der folgenden Aggregationsfunktionen, Verarbeitungsbefehle und Funktionen:
Quellbefehl from (Dokumentation)
from apache-logs: Dieser Befehl löst eine Abfrage aus einem Index namens „apache-logs“ aus. Dieser Index enthält Log-Einträge, die sich auf den Traffic des Apache-Webservers beziehen.
where (Dokumentation)
where url.original=="/de/login": Dieser Befehl filtert die Datensätze so, dass nur diejenigen zurückgegeben werden, bei denen „url.original“ gleich „/login“ ist. Das bedeutet, dass wir nur an Log-Einträgen interessiert sind, die im Zusammenhang mit Login-Versuchen oder Zugriffen auf die Login-Seite stehen.
eval (Dokumentation) und auto_bucket (Dokumentation)
eval time_buckets =... : Dieser Befehl erstellt eine neue Spalte namens „time_buckets“.
Die Funktion auto_bucket erstellt menschenlesbare Buckets und gibt für jede Zeile, die dem resultierenden Bucket entspricht, zu dem die Zeile gehört, einen Datums- und Uhrzeitwert zurück.
@timestamp ist das Feld, dass den Zeitstempel für den jeweiligen Log-Eintrag enthält.
50 ist die Anzahl der Buckets.
2023-09-11T21:54:05.000Z: Startzeit des Bucketings
2023-09-12T00:40:35.000Z: Endzeit des Bucketings
Das bedeutet, dass die Log-Einträge von „2023-09-11T21:54:05.000Z“ bis „2023-09-12T00:40:35.000Z“ in 50 gleichmäßig verteilte Intervalle unterteilt werden und jeder Eintrag anhand seines Zeitstempels einem bestimmten Intervall zugeordnet wird.
Das Ziel dabei ist nicht, exakt die angegebene Anzahl von Buckets zu liefern, sondern es geht darum, einen Bereich zu wählen, mit dem Sie umgehen können und der maximal die angegebene Anzahl von Buckets liefert. Wenn Sie mehr Buckets wollen, kann auto_bucket einen kleineren Bereich auswählen.
stats…by-Aggregationen (Dokumentation), count (Dokumentation) und by (Dokumentation)
stats login_attempts = count(user.name) by time_buckets, user.name: Diese Aggregation aggregiert die Daten zur Berechnung der Anzahl der Login-Versuche. Dazu zählt sie die Vorkommen von user.name (die jeweils für einen Login-Versuch einer eindeutigen Nutzerin bzw. eines eindeutigen Nutzers stehen).
Die Anzahl wird sowohl nach time_buckets (d. h. nach den von uns erstellen Zeitintervallen) als auch nach user.name gruppiert. Wir sehen also für jeden Zeit-Bucket, wie oft jede Nutzerin oder jeder Nutzer versucht hat, sich einzuloggen.
sort (Dokumentation)
Sort login_attempts desc: Zum Schluss werden die aggregierten Ergebnisse absteigend nach der Spalte login_attempts sortiert. Das bedeutet, dass im Ergebnis die höchste Anzahl von Login-Versuchen ganz oben steht.
Zusammengefasst macht die Abfrage Folgendes:
- Sie wählt Daten aus dem Index „apache-logs“ aus.
- Sie filtert die Log-Einträge heraus, die sich auf die Login-Seite beziehen.
- Sie ordnet diese Einträge in bestimmte Zeitintervalle ein.
- Sie zählt die Anzahl der Login-Versuche für jede Nutzerin bzw. jeden Nutzer in jedem dieser Zeitintervalle.
- Sie gibt die Ergebnisse aus und sortiert diese so, dass die höchste Anzahl an Login-Versuchen ganz oben steht.
Unten sehen Sie eine visuelle Darstellung in Form eines Balkendiagramms und eine tabellarische Darstellung der Abfrage oben mit den Spalten „login_attempts, time_buckets“ und „user.name“:
Inline-Bearbeitung von Visualisierungen in Discover und Dashboards
ES|QL-Visualisierungen können direkt in Discover und in Dashboards bearbeitet werden. Sie müssen also nicht erst zu Lens wechseln, um schnell etwas zu ändern.
Im Folgenden finden Sie ein Video, das den kompletten Workflow zeigt. Außerdem erklären wir den Vorgang Schritt für Schritt:
Schreiben einer ES|QL-Abfrage
Abrufen kontextbezogener Visualisierungen unter Berücksichtigung des Wesens der Abfrage
Inline-Bearbeiten der Visualisierung
Speichern der Visualisierung in einem Dashboard
Bearbeiten der Visualisierung von einem Dashboard aus
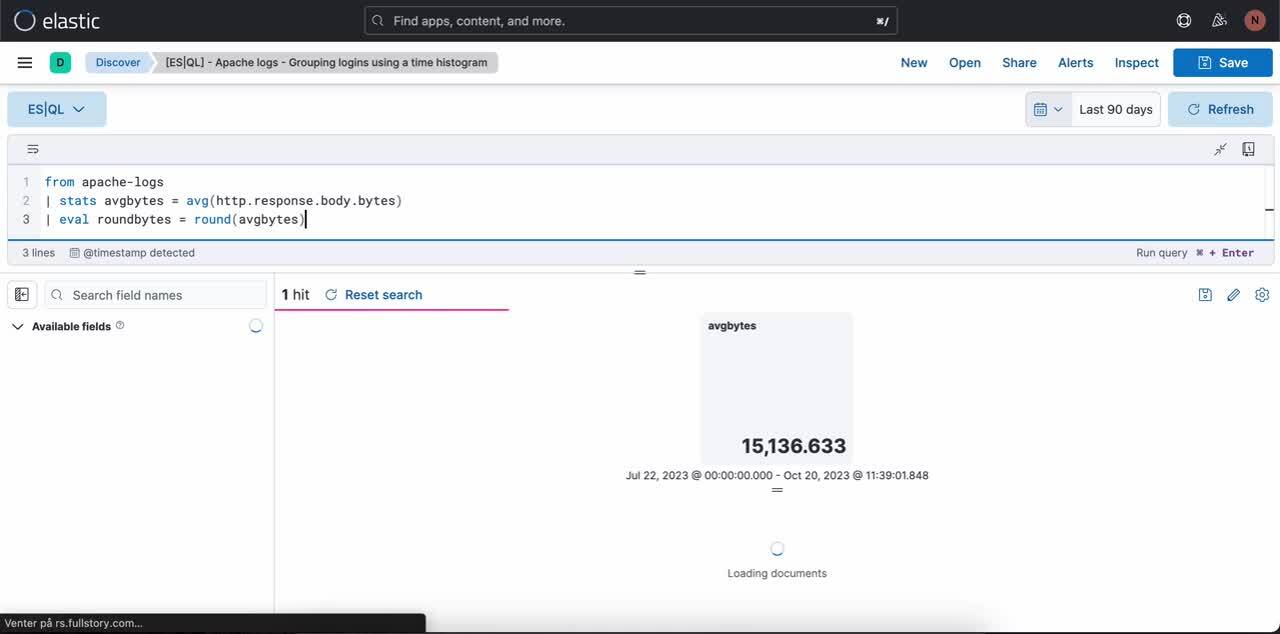
Schritt 1: Schreiben einer ES|QL-Abfrage. Abfragebeispiel zum Erzeugen einer Metriken-Visualisierung:
from apache-logs
| stats avgbytes = avg(http.response.body.bytes)
| eval roundbytes = round(avgbytes)
| drop avgbytesSchritt 2: Erstellen einer kontextbezogenen Visualisierung (in diesem Fall einer Metriken-Visualisierung) auf der Basis des Wesens der Abfrage. Anschließend können Sie das Stift-Symbol auswählen, um in den Inline-Bearbeitungsmodus zu wechseln.
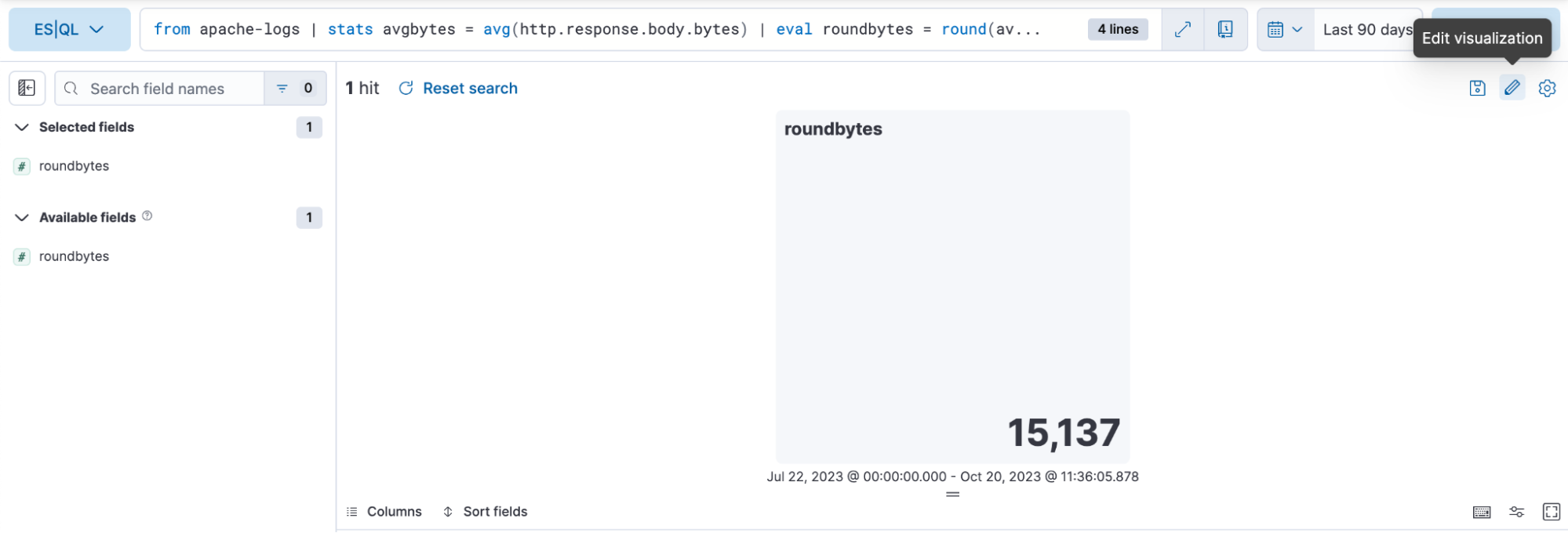
Schritt 3: Bearbeiten der Visualisierung im Inline-Bearbeitungsmodus.
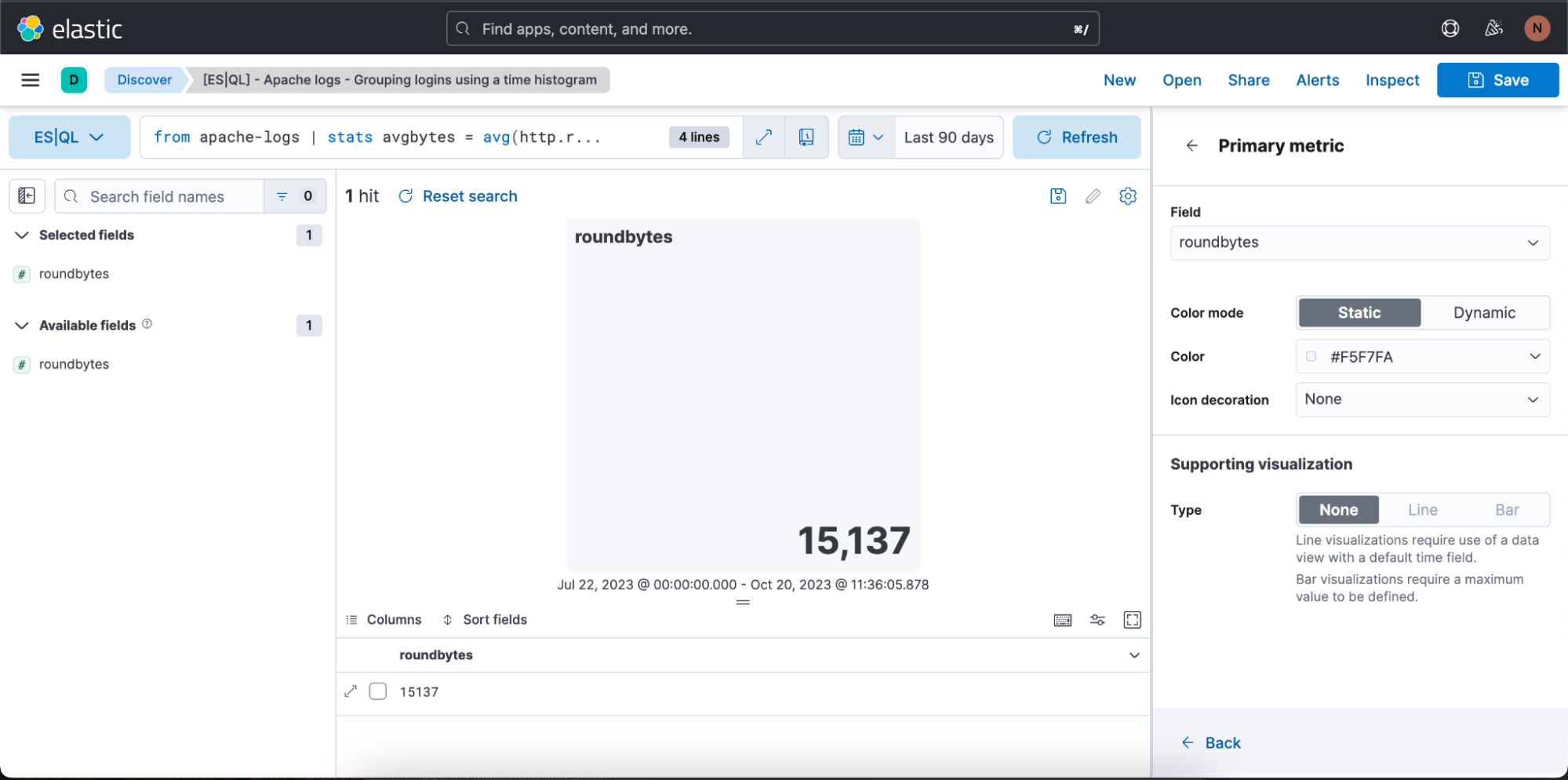
Im Beispiel oben soll die Visualisierung im Farbmodus „Dynamic“ erfolgen, daher schalten wir auf „Dynamic“ um.
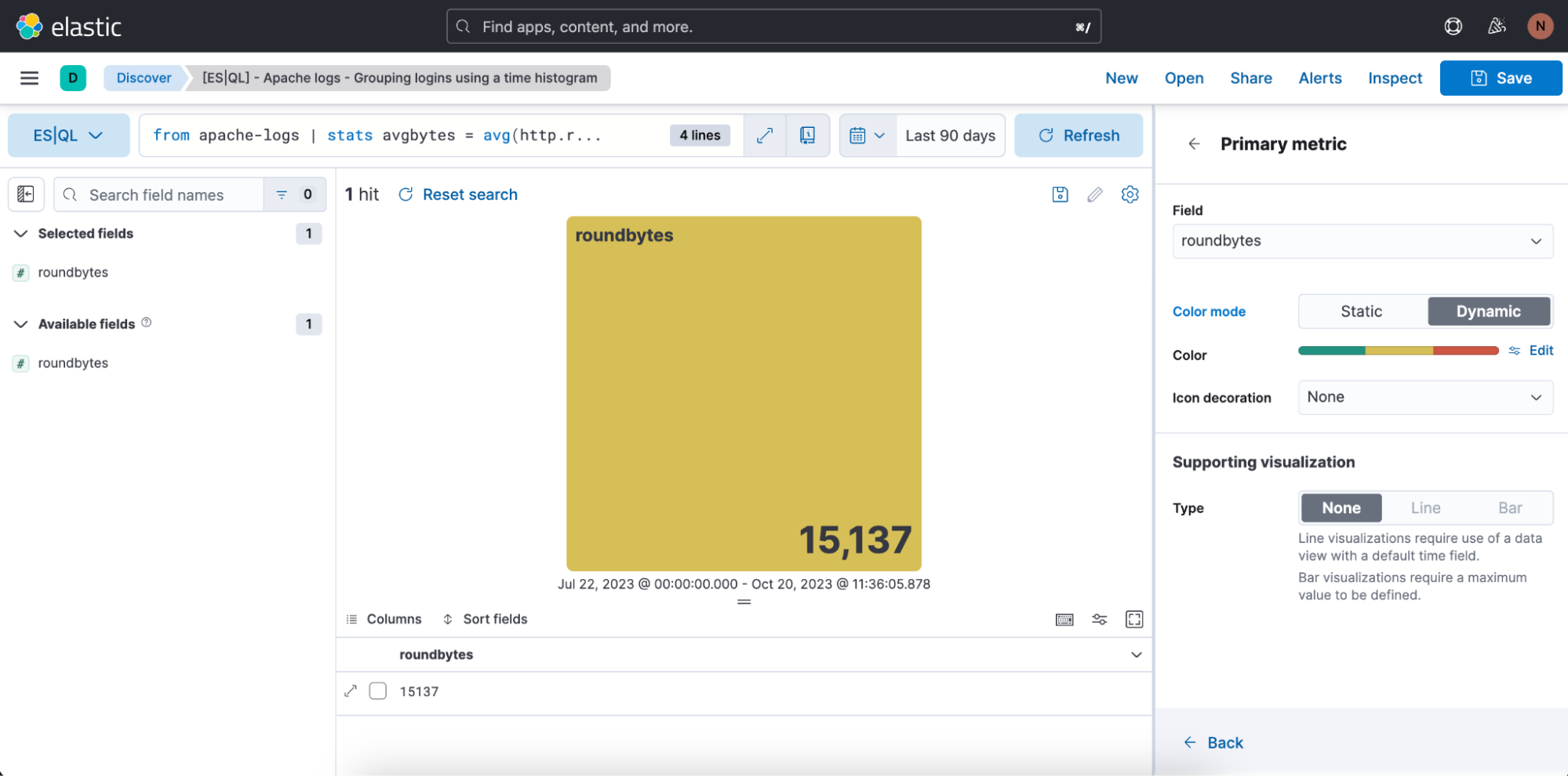
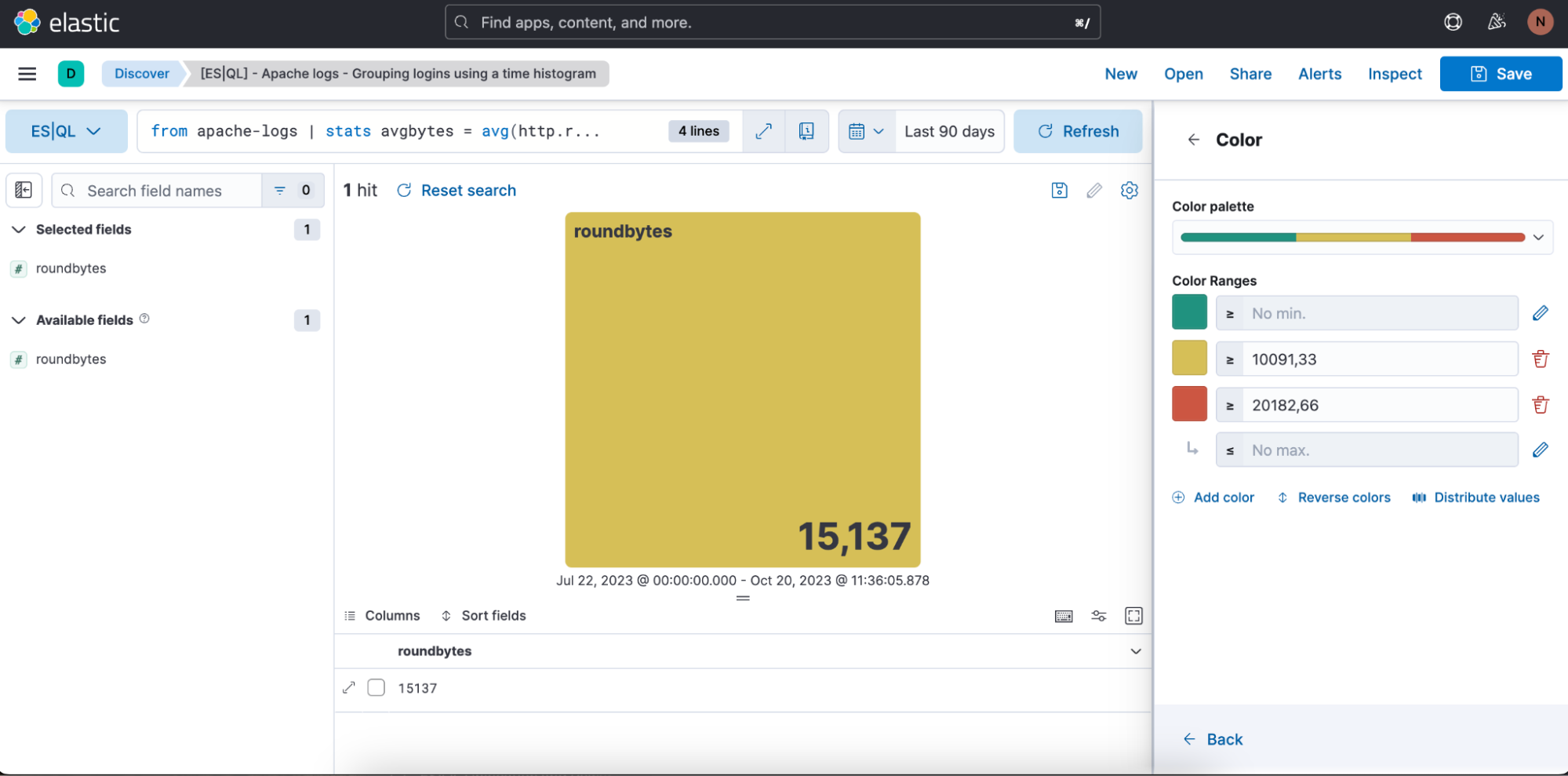
Wir können auch die Farbbereiche festlegen, die verwendet werden sollen:
Schritt 4: Speichern der Visualisierung in einem Dashboard.
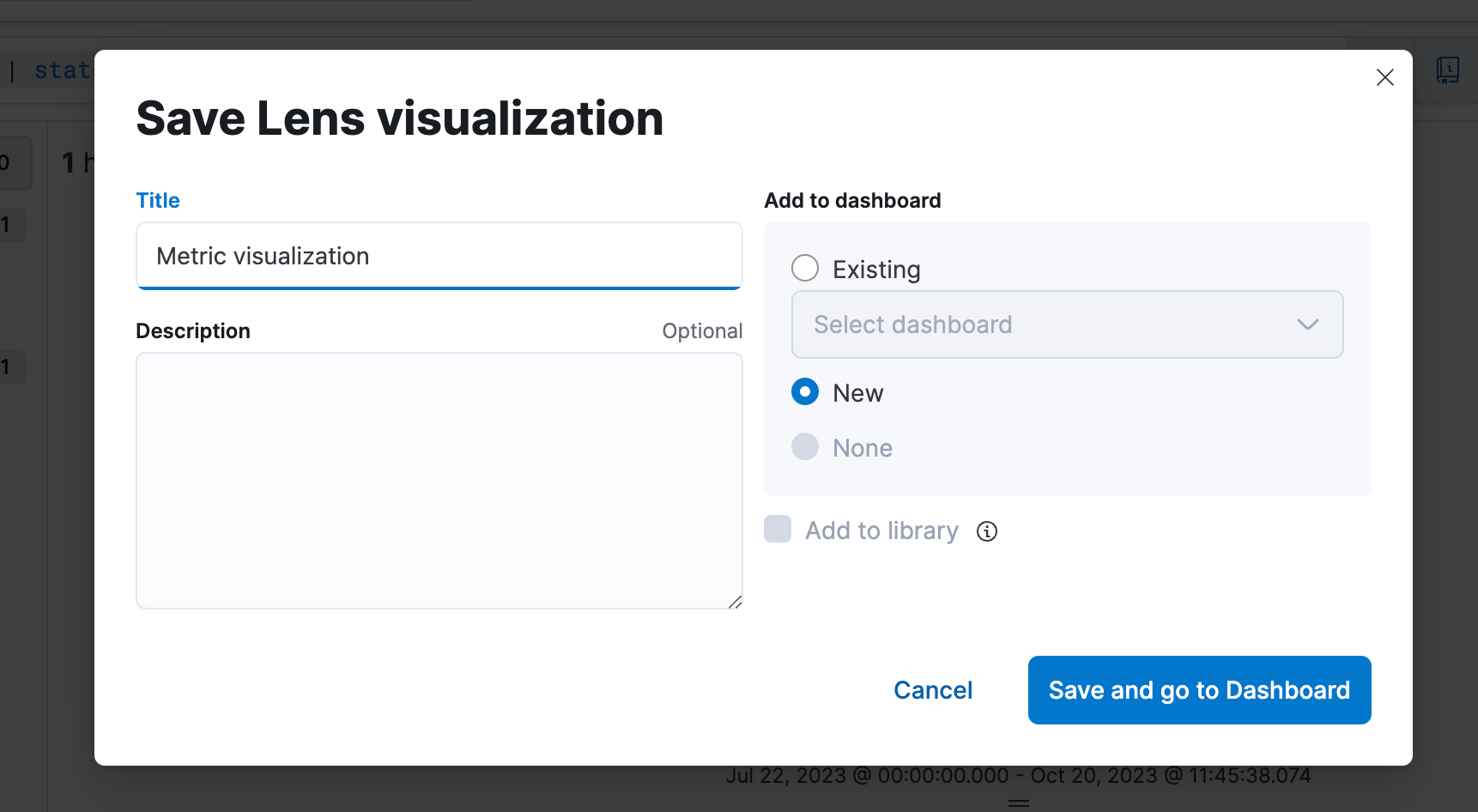
Schritt 5: Bearbeiten der Visualisierung von einem Dashboard aus.
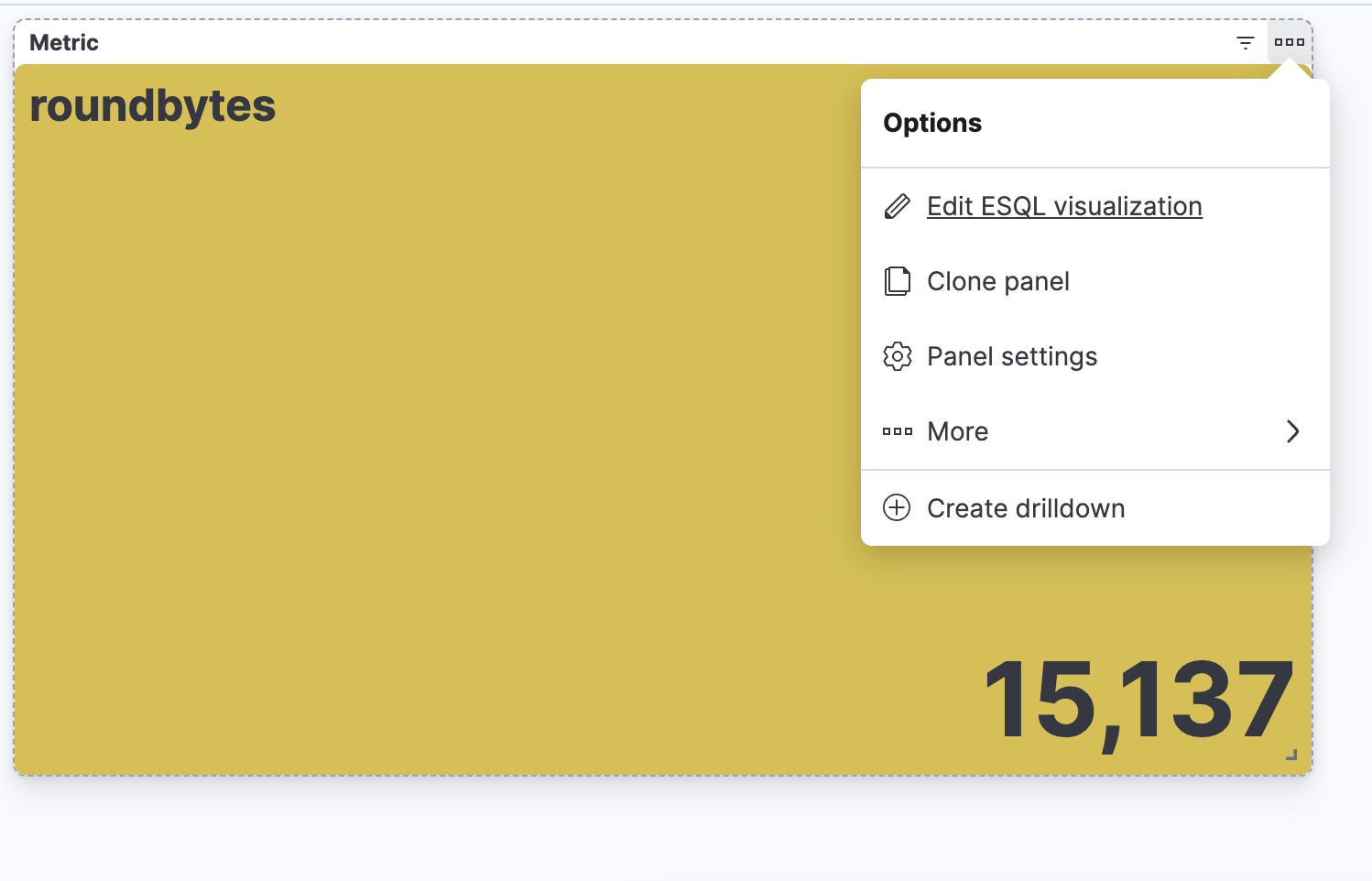
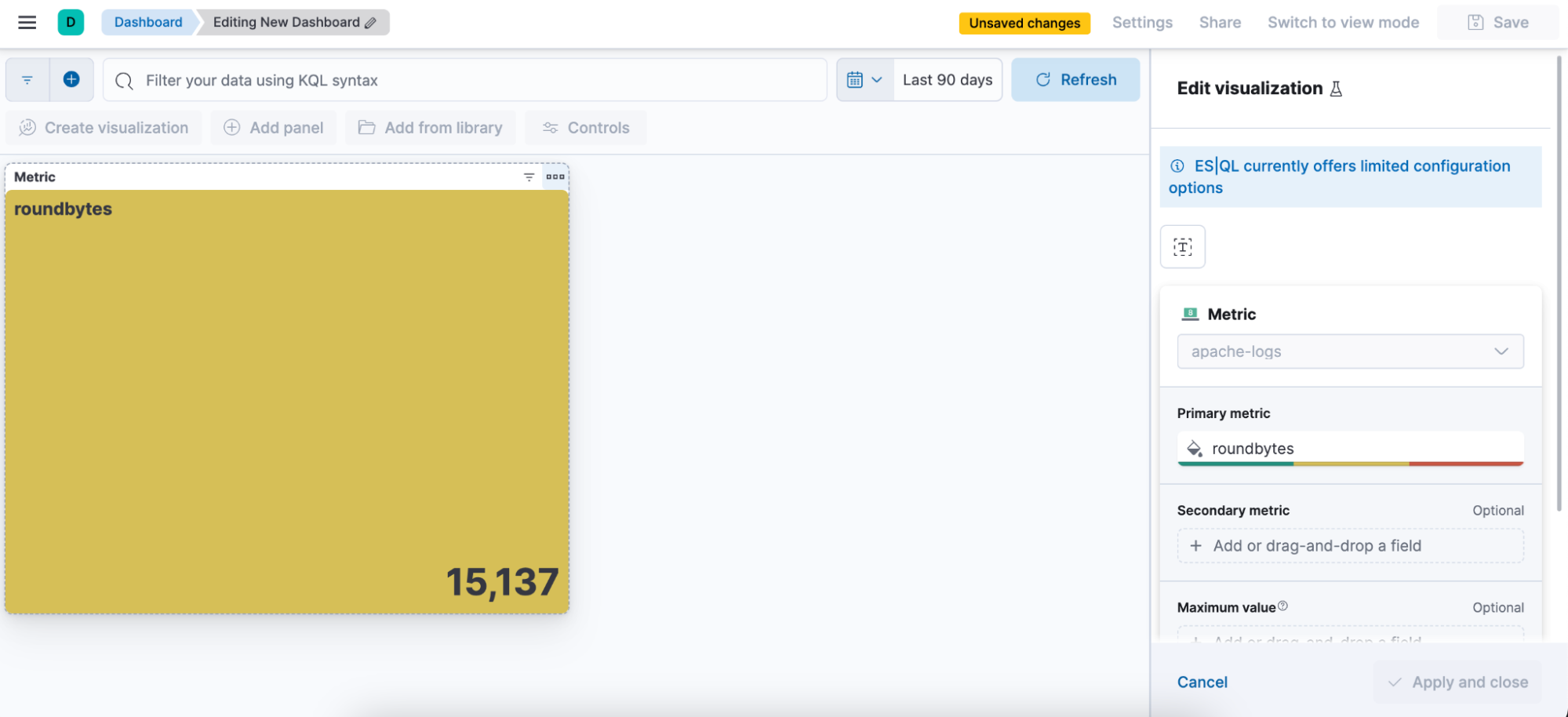
Erstellen eines ES|QL-Alerts direkt in Discover
Sie können ES|QL für Observability- und Security-Alerts verwenden, indem Sie aggregierte Werte als Schwellenwerte festlegen. Durch die Konzentration auf aussagekräftige Trends, statt auf isolierte Incidents, erhöht sich die Erkennungsgenauigkeit, was die Zahl der falsch-positiven Ergebnisse reduziert, sodass die Benachrichtigungen, die Sie bekommen, wirklich relevant sind.
Im Folgenden erfahren Sie, wie Sie direkt in Discover einen ES|QL-Alert-Regeltyp erstellen können.
Der neue Alert-Regeltyp ist unter dem vorhandenen Elasticsearch-Regeltyp verfügbar. Dieser Regeltyp bietet alle neuen Funktionalitäten, die in ES|QL verfügbar sind, und macht neue Alerting-Anwendungsfälle möglich.
Bei dem neuen Typ können Nutzer:innen auf der Grundlage einer definierten ES|QL-Abfrage einen einzelnen Alert generieren und sich eine Vorschau des Abfrageergebnisses ansehen, bevor sie die Regel speichern. Wenn die Abfrage ein leeres Ergebnis zurückgibt, werden keine Alerts generiert.
Abfragebeispiel für einen Alert:
from metrics-pods |
stats max_cpu = max(kubernetes.pod.cpu.usage.node.pct) by kubernetes.pod.name|
sort max_cpu desc | limit 10
So erstellen Sie einen Alert in Discover
Schritt 1: Klicken Sie auf „Alerts“ und dann auf „Create search threshold rule“. Sie können mit dem Erstellen Ihres ES|QL-Alert-Regeltyps sowohl vor dem Definieren der ES|QL-Abfrage in der Suchleiste als auch danach beginnen. Die Alert-Erstellung nach dem Definieren hat den Vorteil, dass die Abfrage automatisch in das Flyout „Create Alert“ eingefügt wird.
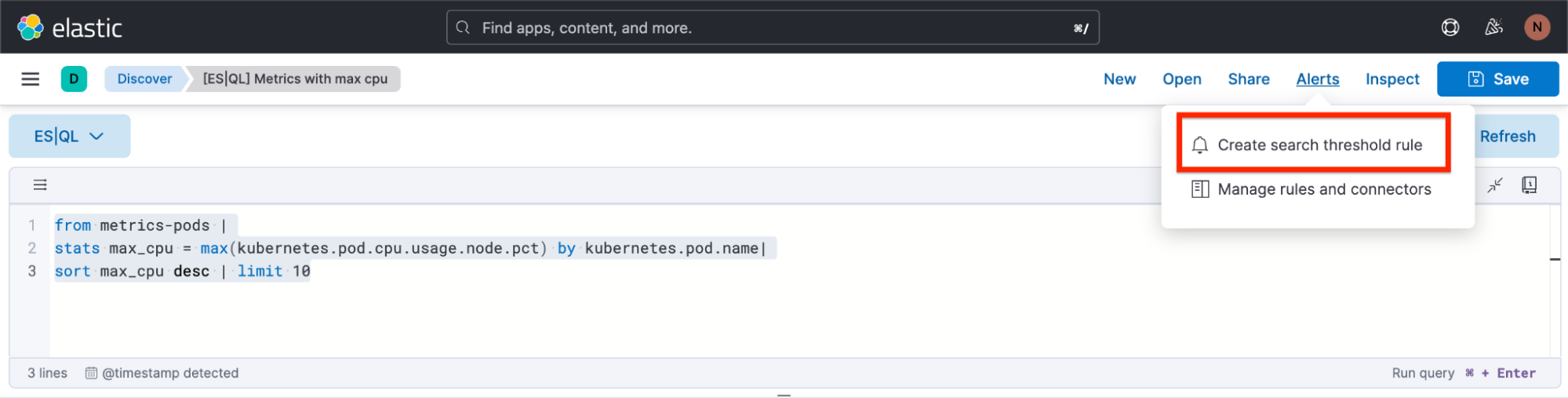
Schritt 2: Beginnen Sie, Ihren ES|QL-Alert-Regeltyp zu definieren.
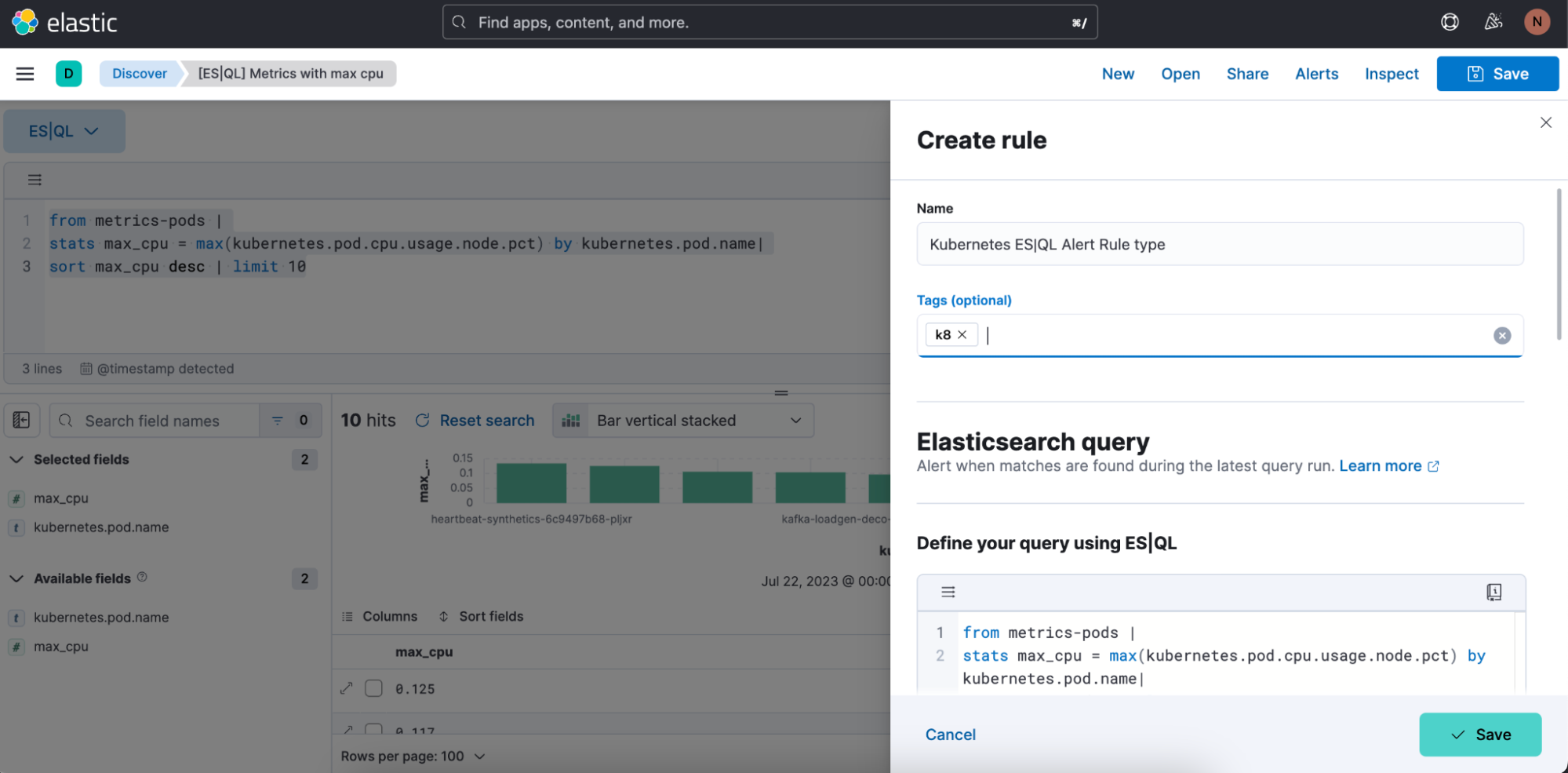
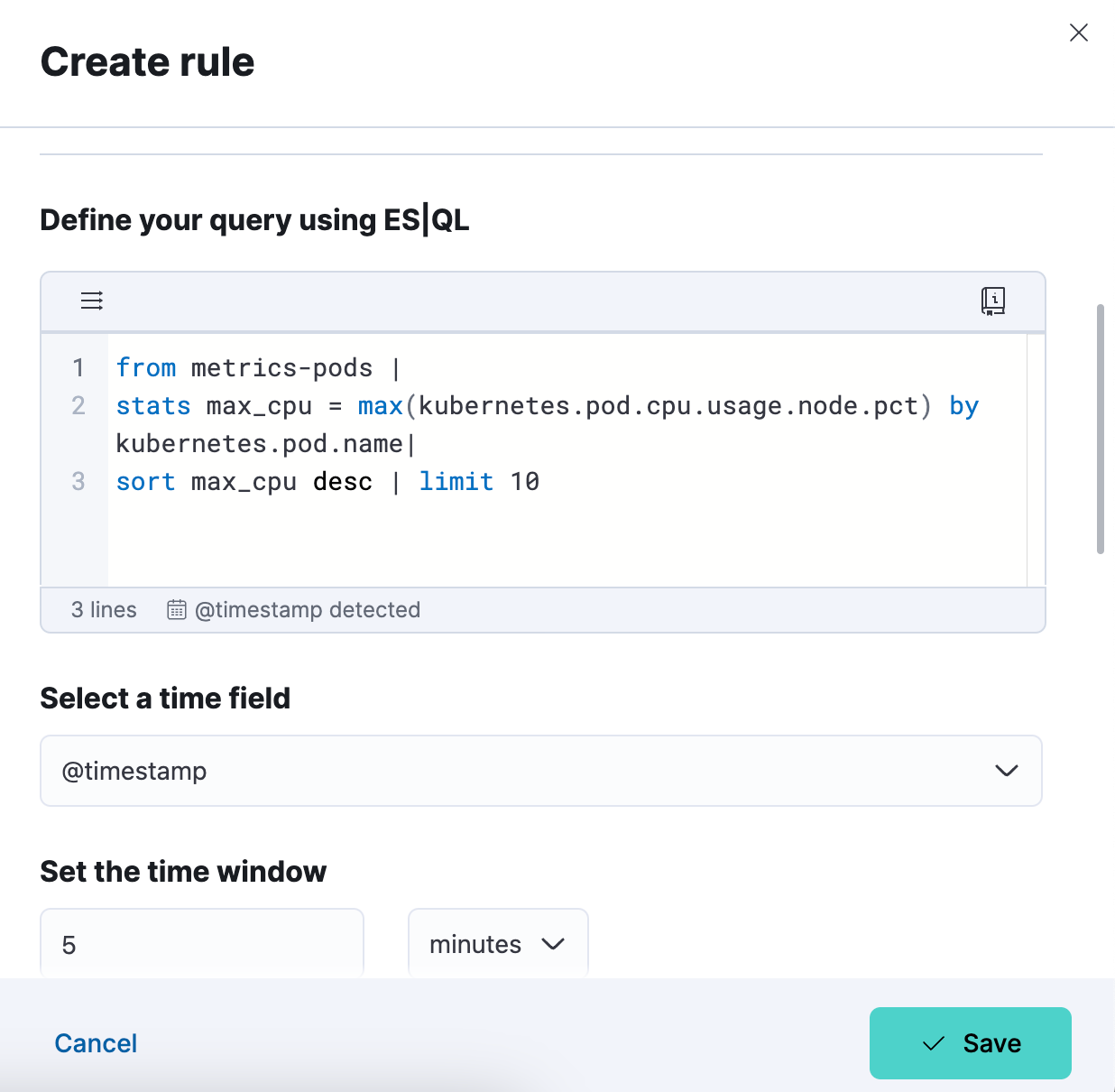
Schritt 3: Testen Sie Ihre Alert-Regeltyp-Abfrage. Sie können die ins Feld eingefügte ES|QL-Abfrage iterieren und sie durch Klicken auf „Test query“ testen. Die Vorschau der Ergebnisse wird in einer Tabelle ausgegeben.
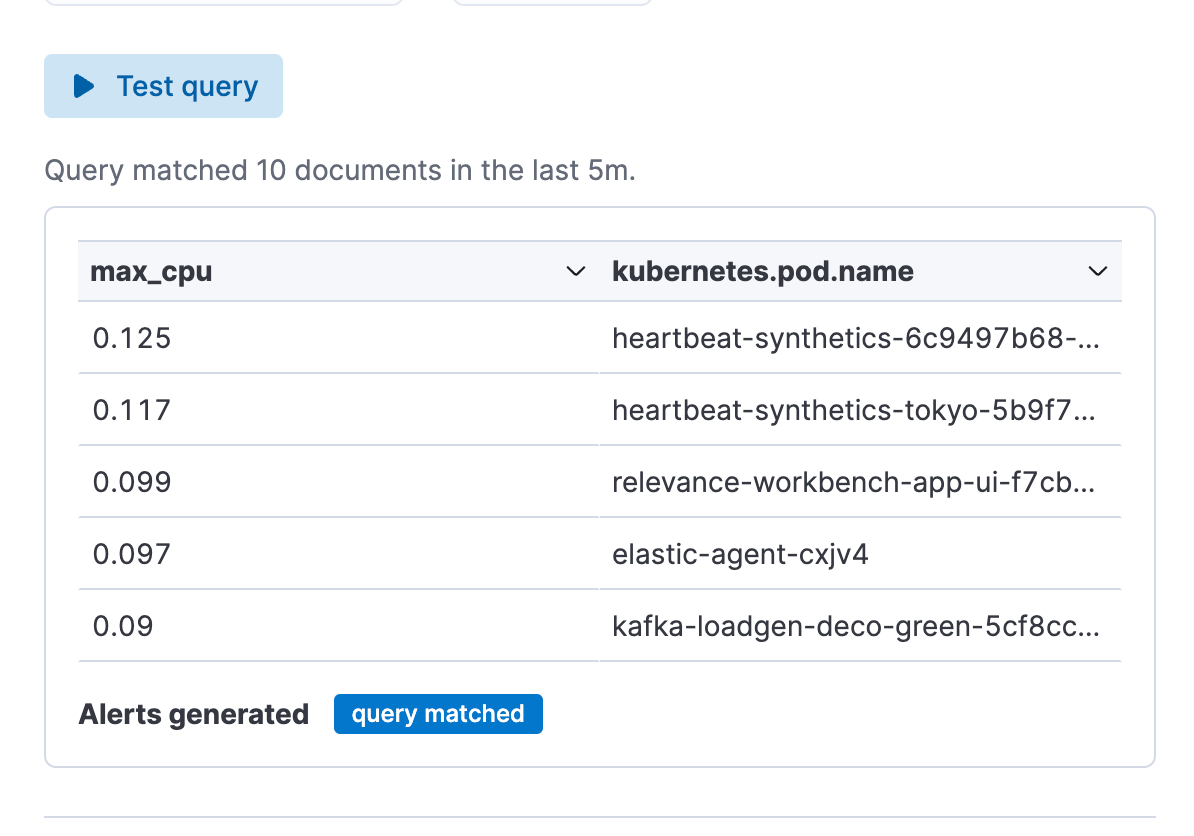
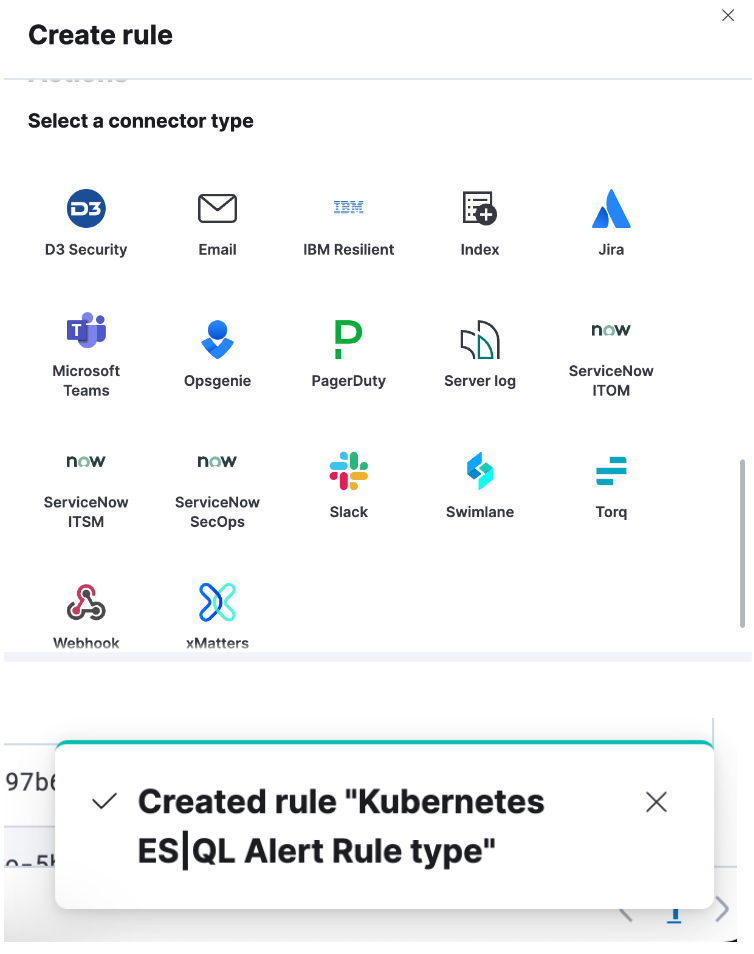
Schritt 4: Richten Sie Ihren Connector ein und speichern Sie ihn durch Klicken auf „Save“. Damit haben Sie erfolgreich einen ES|QL-Alert-Regeltyp erstellt!
Anreichern Ihres Abfrage-Datasets mit Feldern aus einem anderen Dataset
Sie können den Befehl ENRICH (Dokumentation) verwenden, um Ihr Abfrage-Dataset um Felder aus einem anderen Dataset zu erweitern – inklusive kontextspezifischer Vorschläge für die ausgewählte Richtlinie (d. h. mit Hinweisen für das passende Feld und die angereicherten Spalten).
Abfragebeispiel mit ENRICH, bei dem über die Abfrage eine Anreicherungsrichtlinie namens „servers-to-project“ verwendet wird, um das Dataset mit den Feldern name, server_hostname und cost anzureichern:
from projects* | limit 10 |
enrich servers-to-project on project_id with name, server_hostname, cost |
stats num_of_servers = count(server_hostname), total_cost = sum(cost) by project_id |
sort total_cost desc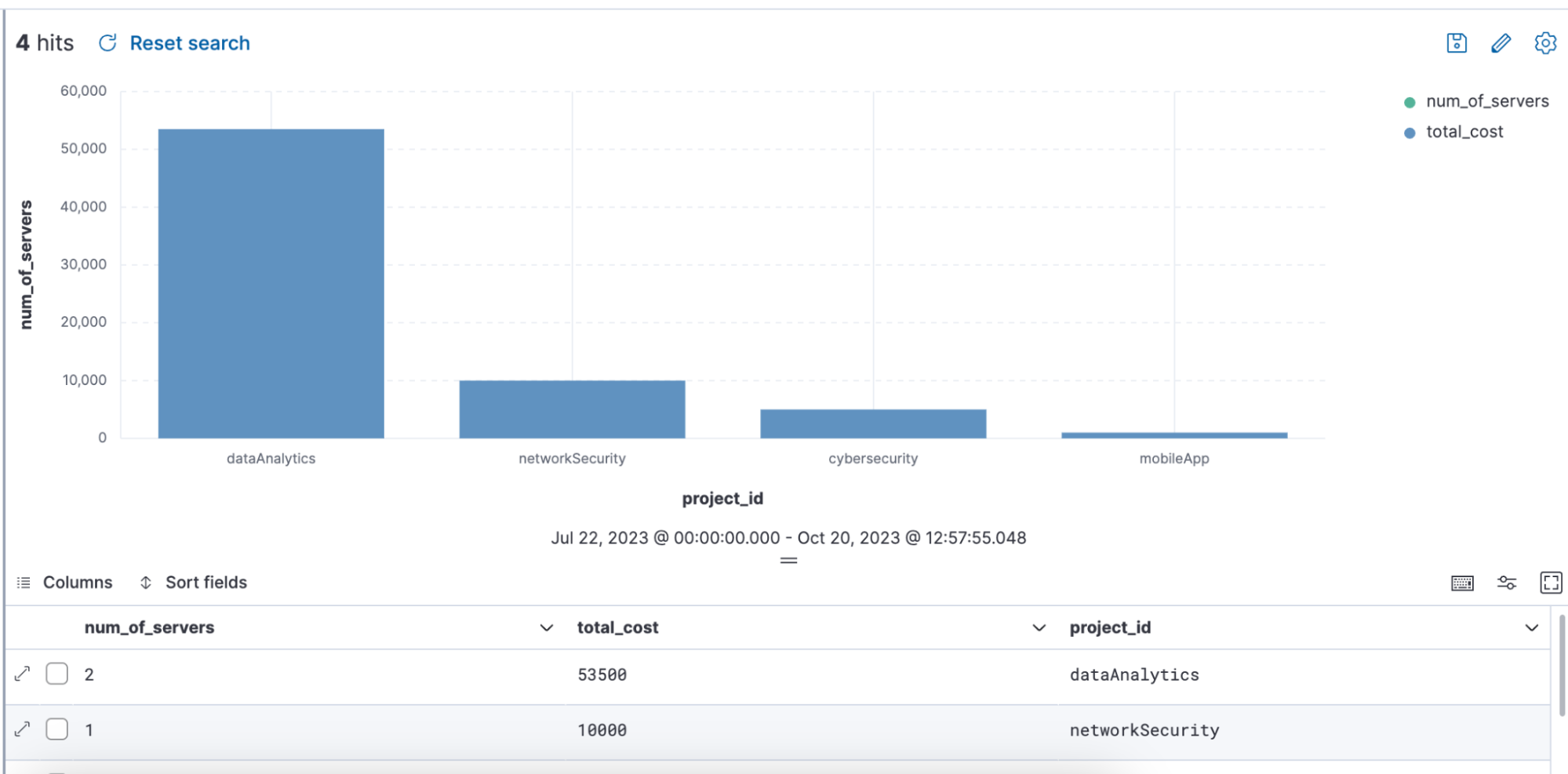
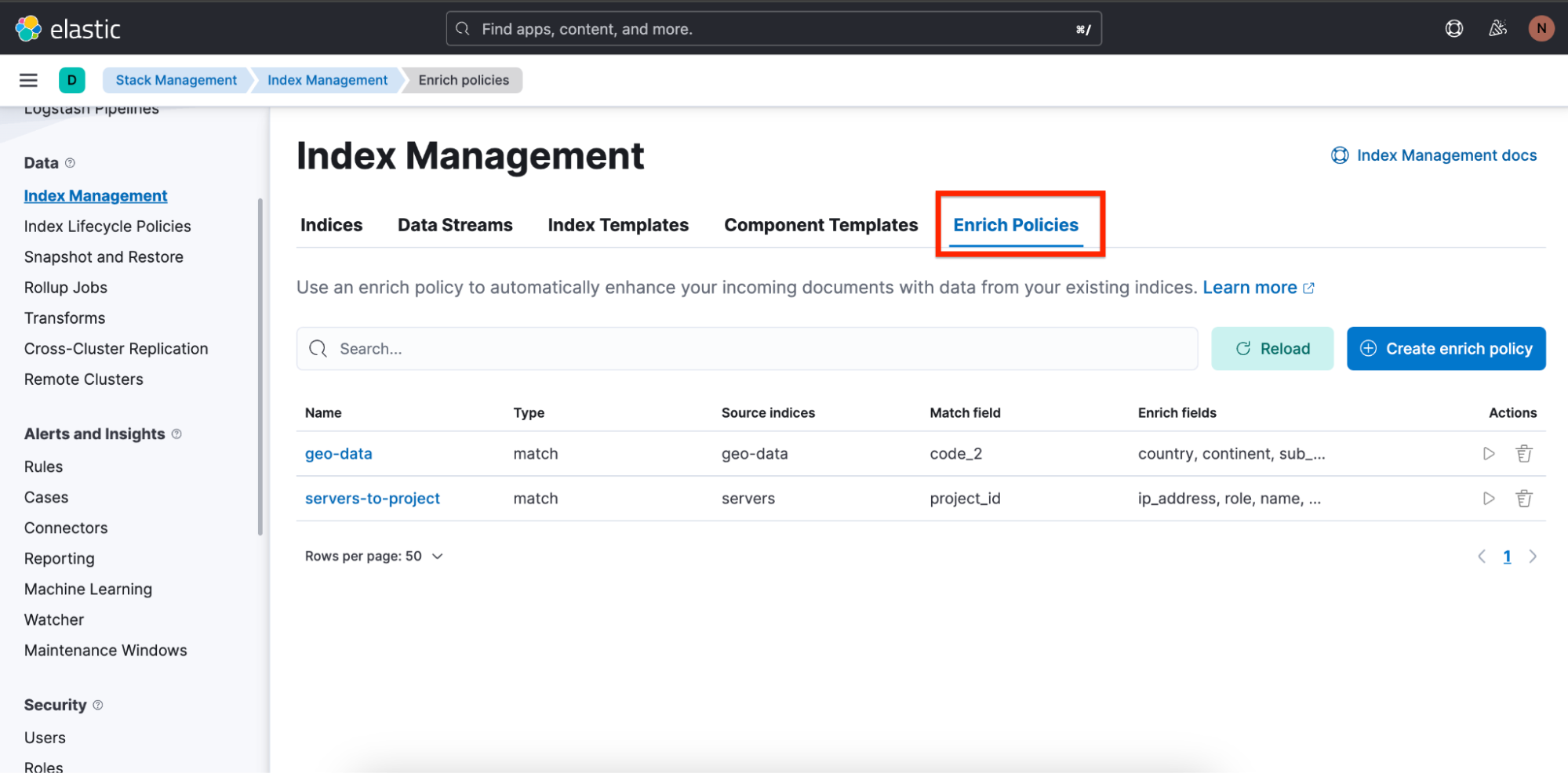
Wir haben auch eine Übersicht und einen Assistenten zum Erstellen von Anreicherungsrichtlinien hinzugefügt, um das Erstellen von Anreicherungsrichtlinien möglichst einfach zu machen.
Die Übersicht über die Anreicherungsrichtlinien finden Sie auf dem Tab Enrich Policies unter „Stack Management“ ⇒ „Index Management“:
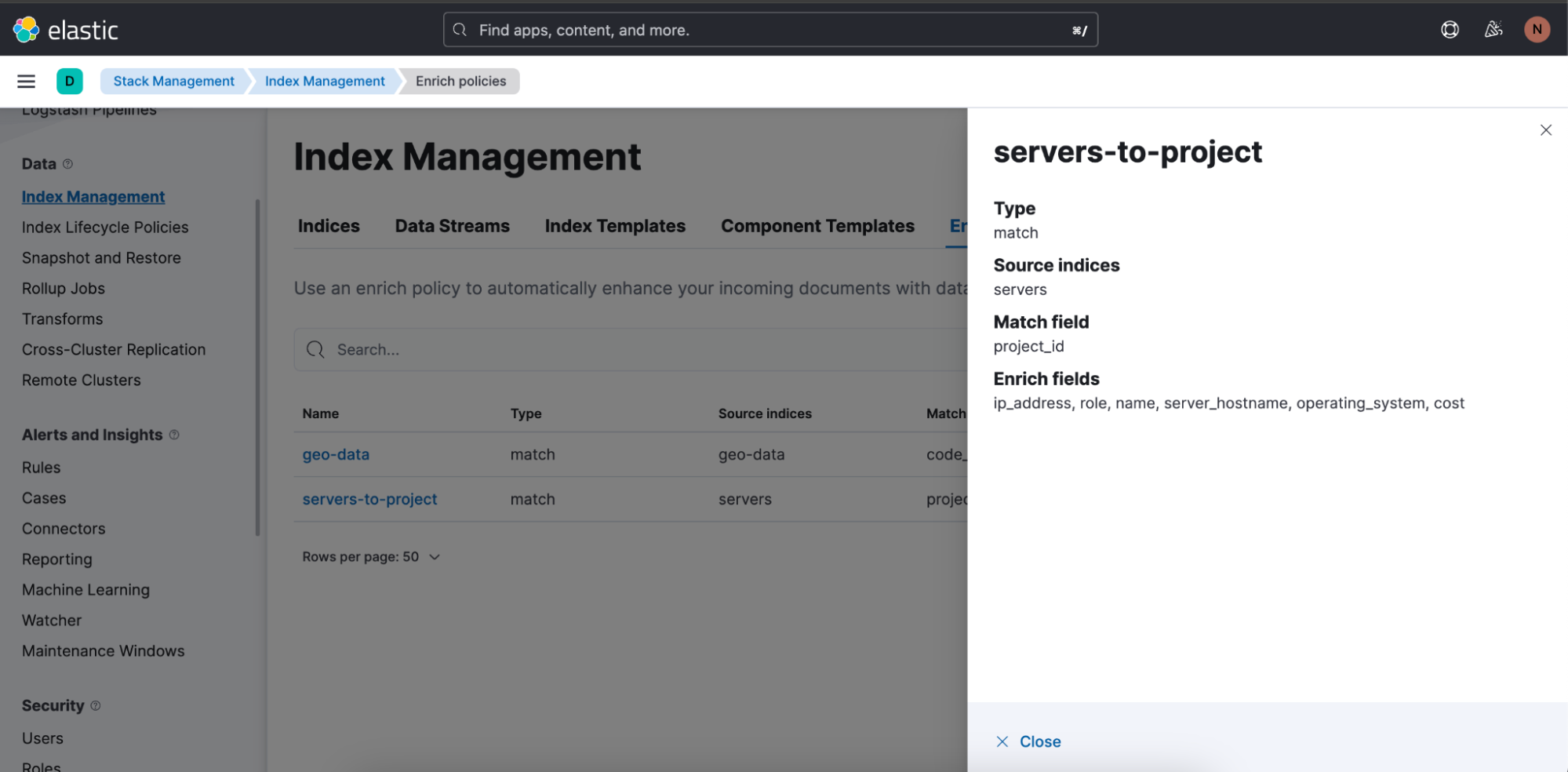
Die für die Abfrage oben verwendete Anreicherungsrichtlinie „servers-to-project“ sieht wie folgt aus:
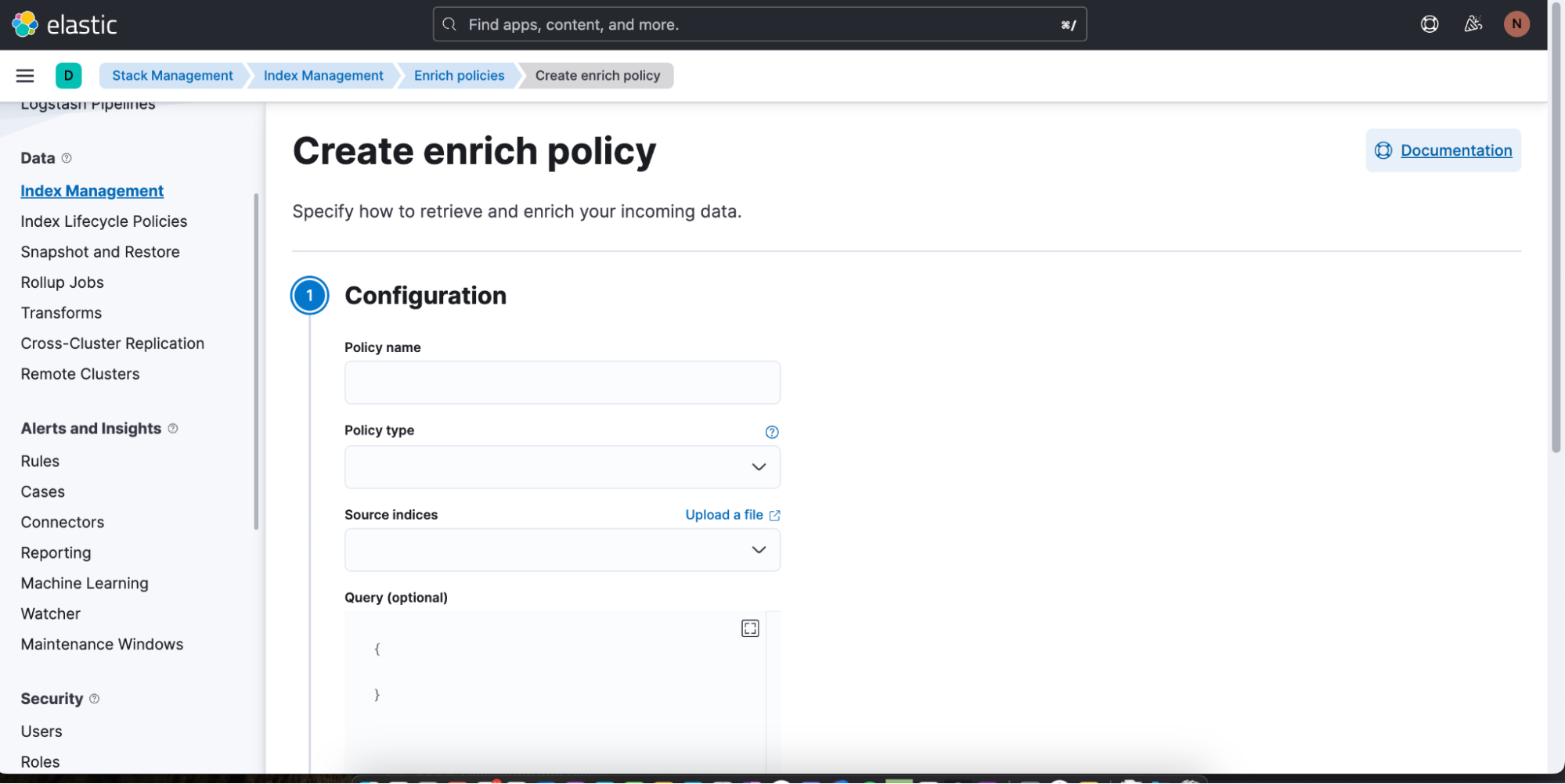
Wenn Sie eine neue Anreicherungsrichtlinie erstellen möchten, klicken Sie einfach auf Create enrich policy. Nachdem Sie die Richtlinie erstellt und einmal ausgeführt haben, kann Sie in Discover in einer ES|QL-Abfrage verwendet werden.
Weitere Informationen zu Anreicherungsrichtlinien finden Sie hier. Informationen zum ENRICH-Befehl in ES|QL können Sie hier nachlesen.
Datenerkundung auf einem neuen Niveau: Das Potenzial und das Versprechen von ES|QL
ES|QL ist die neueste Innovation von Elastic zur Verbesserung von Datenanalyse und ‑erkundung. Zentraler Punkt dabei ist nicht nur das Darstellen von Daten an sich; es geht auch darum, die Daten verständlich, verwertbar und visuell ansprechend zu präsentieren. Angetrieben von einer schnellen, verteilten und dedizierten Abfrage-Engine, konzipiert als neue, Pipe-basierte Abfragesprache und präsentiert als zentralisiertes Datenerkundungserlebnis, hilft ES|QL SREs, DevOps, Threat Huntern und anderen Analyst:innen dabei, die vor ihnen stehenden Herausforderungen zu meistern.
ES|QL versetzt SREs in die Lage, Systemineffizienzen wirksam zu bekämpfen, unterstützt DevOps bei der Sicherstellung der Deployment-Qualität und gibt Threat Huntern Tools für das schnelle Erkennen potenzieller Sicherheitsbedrohungen an die Hand. Die direkte Integration in Dashboards, die Inline-Bearbeitung von Visualisierungen, Alert-Funktionen und Optionen wie ENRICH-Befehle ermöglichen einen reibungslosen und effizienten Workflow. Die ES|QL-Benutzeroberfläche kombiniert Leistungsfähigkeit und Nutzerfreundlichkeit, damit die Nutzer:innen tief in ihre Daten eintauchen können, um genauere Analysen anzustellen und verwertbare Erkenntnisse zu gewinnen. Die Einführung von ES|QL ist einfach eine Fortsetzung der Bestrebungen von Elastic, Nutzer:innen die Erkundung ihrer Daten zu vereinfachen und die sich stets weiterentwickelnden Anforderungen unserer User Community zu erfüllen.
Sie können alle Funktionen von ES|QL sofort ausprobieren! Sie können Elastic kostenlos ausprobieren oder sich ES|QL in unserer öffentlichen Demoumgebung ansehen.
Die Entscheidung über die Veröffentlichung von Features oder Leistungsmerkmalen, die in diesem Blogpost beschrieben werden, oder über den Zeitpunkt ihrer Veröffentlichung liegt allein bei Elastic. Möglicherweise werden aktuell nicht verfügbare Features oder Funktionen nicht rechtzeitig oder gar nicht bereitgestellt.
Teilen
- Share on Twitter
Auf Twitter teilen
- Share on LinkedIn
Auf LinkedIn teilen
- Share on Facebook
Auf Facebook teilen
- Share by Email
Per E-Mail teilen
- Print this page
Drucken