Elastic Stack 7.0.0 veröffentlicht
7.0 ist da! Dieser Version liegen mehr als 10.000 Pull-Requests von 861 Beitragenden zugrunde. Daher zuerst einmal ein großes Dankeschön an unsere Mitarbeiter und die Community.
Wer sich direkt vom Entwicklerteam über die neue Version informieren lassen möchte, ist hiermit herzlich zu unserem [virtuellen Launch-Event] (https://www.elastic.co/de/webinars/7.0-virtual-event) am 25. April 2019 eingeladen, das ab 17 Uhr MESZ live übertragen wird. Dabei wird es 7.0-Demos, eine Fragenrunde mit Elastic-Engineers aus aller Welt und anderes mehr geben.
Sie können Elastic Stack 7.0 ab sofort herunterladen oder vollständig verwaltete Deployments auf dem Elasticsearch Service auf Elastic Cloud nutzen – Elastic Cloud ist die einzige gehostete Lösung, auf der neue Elastic Stack-Versionen ab dem Tag ihrer Einführung genutzt werden können.
Die schiere Fülle an Erwähnenswertem macht es schwer, einen Einstieg zu finden. Versuchen wir’s trotzdem.
Kibana 7.0: neues Design, überarbeitete Navigation … und ein Dark Mode!
Bei der Gestaltung von Kibana 7.0 haben wir uns entschieden, uns ganz auf den Inhalt zu konzentrieren. Das Ergebnis ist eine Benutzeroberfläche, die insgesamt leichter und minimalistischer daherkommt. Die spürbarste Veränderung dürfte die Einführung einer neuen globalen Navigation sein: Am oberen Rand eines jeden Kibana-Space befindet sich jetzt eine Navigationsleiste mit Breadcrumbs sowie Optionen zum Wechseln zwischen den einzelnen Spaces und zum Starten von Benutzeraktionen, wie Passwortänderungen oder das Abmelden vom System. Um dies zu erreichen und die Konsistenz zu verbessern, haben wir das Elastic UI Framework entwickelt. Im Laufe des letzten Jahres wurde Kibana so umgestellt, dass diese Komponenten fast durchweg genutzt werden. Diesen Komponenten und dem heldenhaften Einsatz unserer Design- und Engineering-Teams ist es außerdem zu verdanken, dass die Anwendung von Styles und Stylesheets drastisch vereinfacht werden konnte.
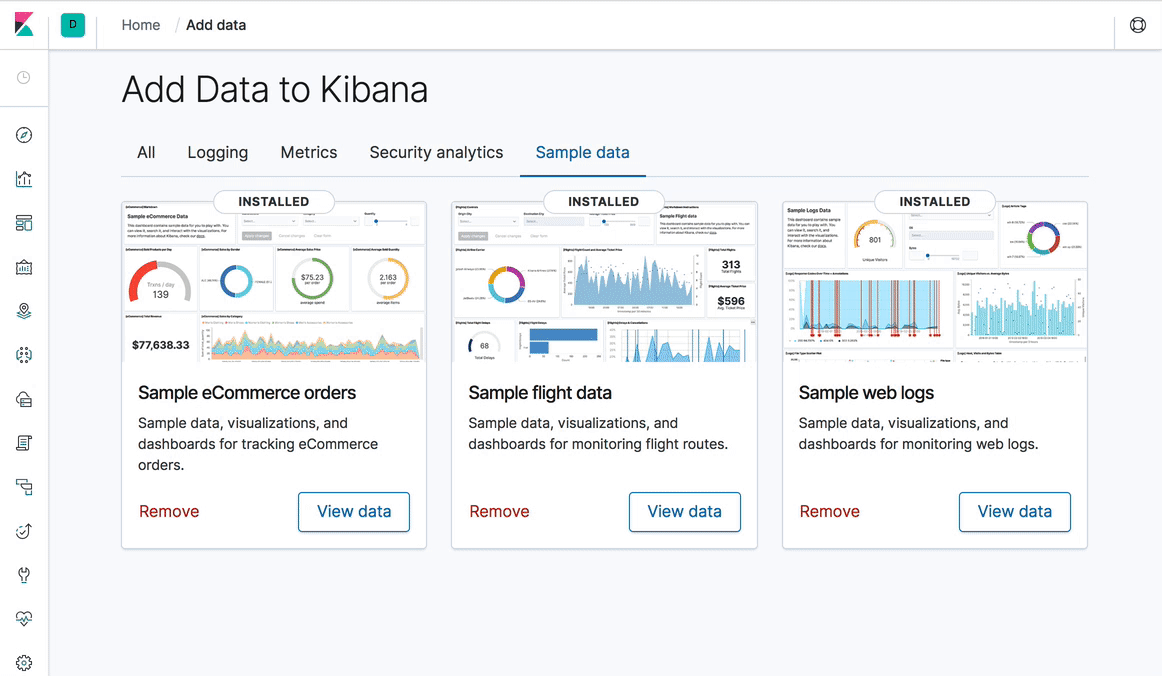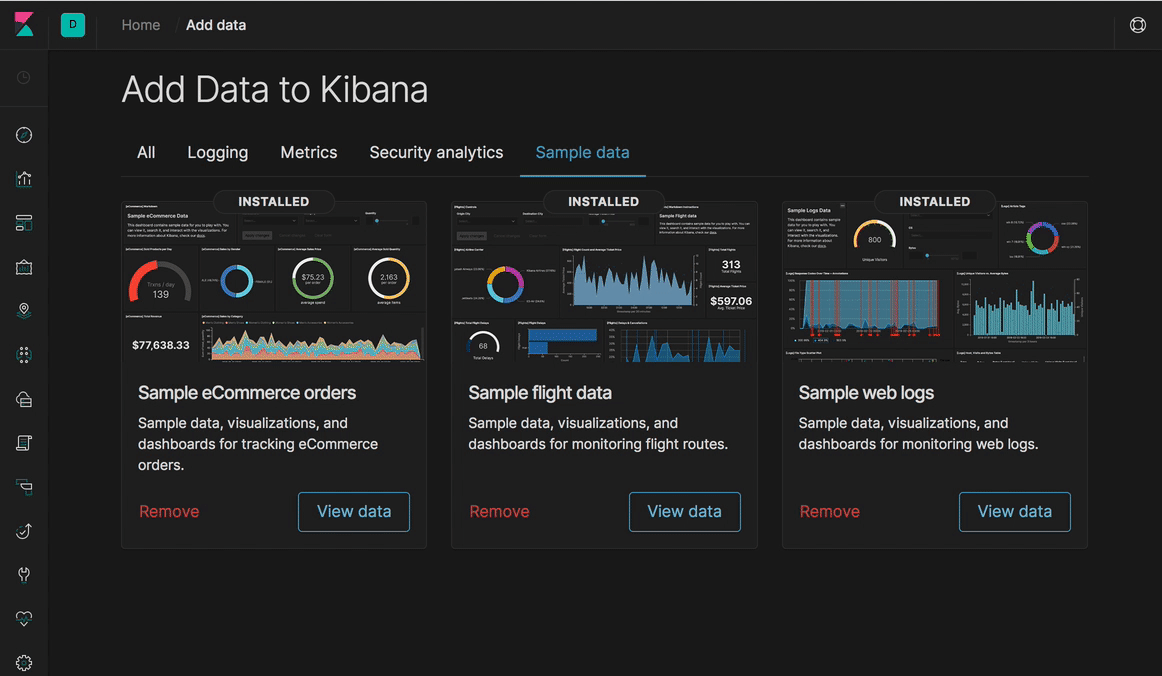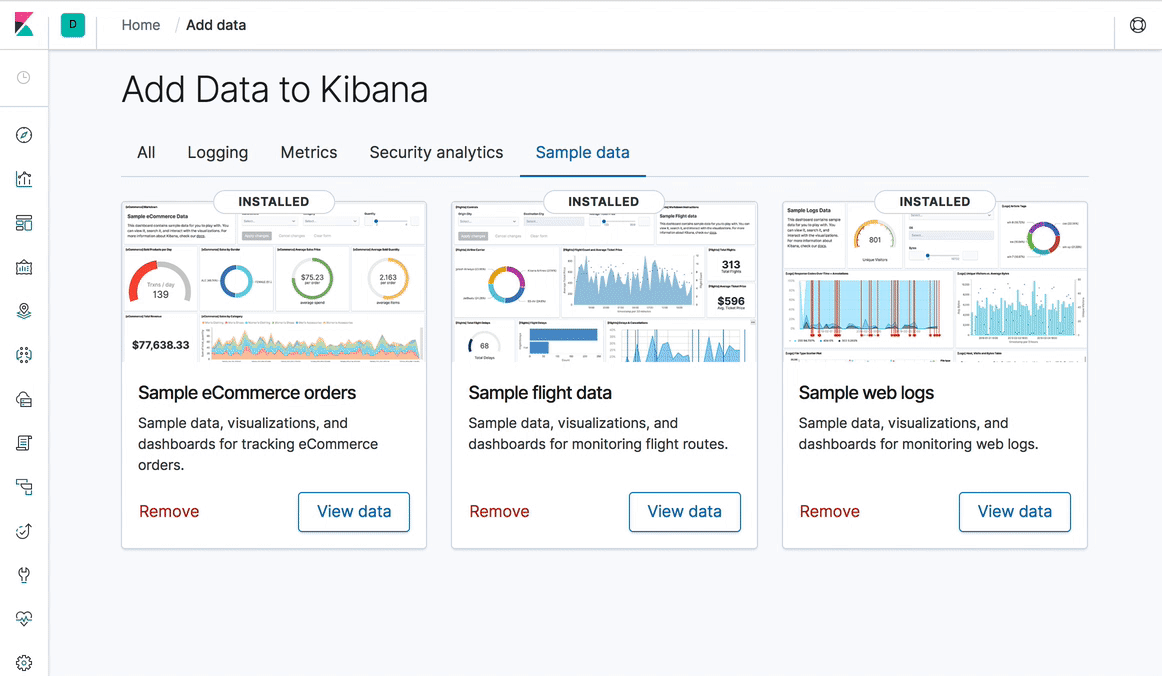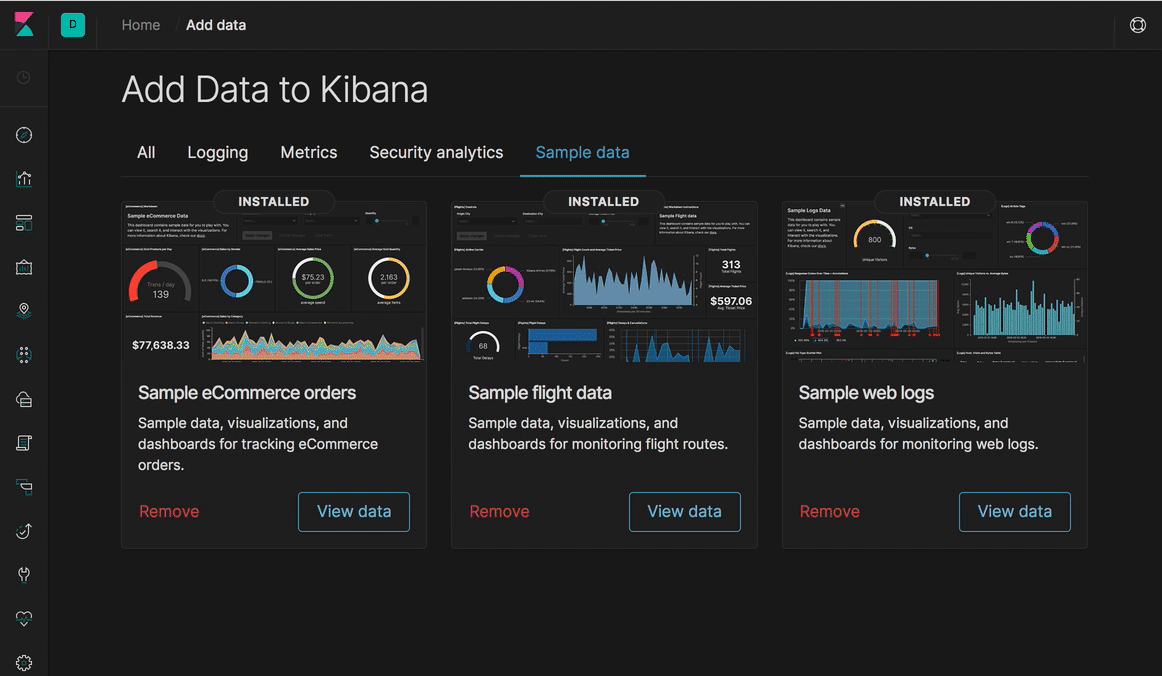
Dank der Verbesserungen bei der Konsistenz und den Stylesheets konnten wir endlich einen der größten Feature-Wünsche in der Geschichte von Kibana Wirklichkeit werden lassen – die Einführung eines Dark Mode in allen Komponenten von Kibana. Auch die Kibana-Dashboards haben von diesen Änderungen profitiert. Sie verfügen jetzt über ein responsives Design, was die Grundvoraussetzung für umfangreiche Usability-Verbesserungen für Nutzer mobiler Geräte ist.
Ein neues Zeitalter für die Cluster-Koordinierung in Elasticsearch
Wir bemühen uns seit jeher, Elasticsearch so zu gestalten, dass es einfach skalierbar und hochgradig resilient ist, um die Folgen katastrophaler Ausfälle abzufedern. Diesem Zweck dienen Maßnahmen an verschiedenen Fronten – von der Stärkung einzelner Knoten, was Skalierbarkeit und Zuverlässigkeit anbelangt, bis zur kontinuierlichen Verbesserung unserer unter dem Namen „Zen Discovery“ bekannten Cluster-Koordinierungsschicht. Version 7.0 bringt ein weiteres Mal große Verbesserungen in beiden Bereichen mit sich.
Es gibt eine vollkommen neue Cluster-Koordinierungsschicht für Elasticsearch, die schneller, sicherer und benutzerfreundlicher ist. Um dies zu erreichen, haben wir uns zunächst der theoretischen Korrektheit unseres neuen verteilten Konsensalgorithmus gewidmet und formale Modelle herangezogen, um das Design zu validieren. Es gibt zwar eine Reihe bekannter Konsensalgorithmen, wie Paxos, Raft, Zab und Viewstamped Replication (VR), aber die Anforderungen eines Elasticsearch-Clusters verlangen nach einem höheren Durchsatz für Cluster-Veränderungen, Unterstützung für das einfache Vergrößern oder Verkleinern von Clustern und eine nahtlose Strategie für rollende Upgrades, damit 6.7-Clustern rollende Upgrades auf 7.0 ermöglicht werden. Die Referenzalgorithmen konnten all dies nicht liefern. Darüber hinaus beinhaltet die neue Cluster-Koordinierungsschicht eine Vielzahl von Änderungen, die die Wahrscheinlichkeit menschlichen Versagens reduzieren und bei der Wiederherstellung nach einem katastrophalen Ausfall verständlichere Auswahloptionen bieten. Es ist nicht einfach, Zuverlässigkeit, Performance und Nutzererlebnis gleichzeitig zu verbessern, ganz besonders, wenn es sich um eine solch zentrale Komponente handelt. Umso stolzer sind wir, dass und wie es uns gelungen ist, die neue Cluster-Koordinierungsschicht auf die Beine zu stellen. Wenn Sie mehr erfahren möchten, lesen Sie unseren Blogpost zum Thema.
Eine der Hauptvorgaben für die Entwicklung einzelner Knoten in Elasticsearch lautet, dass sie widerstandsfähig und robust sein müssen. Wenn ein Knoten zu viele Anfragen erhält oder die Anfragen zu groß sind, wehrt sich der Knoten irgendwann. Die nötige Widerstandsfähigkeit (Resilienz) erzielen wir, indem wir Elasticsearch mit Schutzschaltern versehen. Diese stellen fest, ob die Anfrage für den Knoten zu groß ist. Sollte dies der Fall sein, reagieren sie sofort und bitten den Client, es erneut zu versuchen und dabei eventuell einen anderen Knoten zu verwenden. Das wird umso wichtiger, je verbreiteter Knoten mit kleineren JVM-Heaps werden, wie dies angesichts des Trends weg von massiven Clustern mit mehreren Mandanten hin zum Ein-Cluster-pro-Mandant-Modell gegenwärtig zu beobachten ist. Neu in 7.0 ist der echte Speicher-Schutzschalter, der deutlich genauer nicht bedienbare Anfragen erkennt und einzelne Knoten davor schützt, durch solche Anfragen destabilisiert zu werden. Mehr darüber, wie diese Änderung zur Verbesserung der Knoten- und Cluster-Zuverlässigkeit insgesamt beiträgt, erfahren Sie in diesem Blogpost.
Stärkung von Relevanz und Geschwindigkeit für die verschiedensten Anwendungsfälle
Relevanz und Geschwindigkeit sind die Grundpfeiler eines positiven Sucherlebnisses. Und in Elasticsearch 7.0 gibt es mehrere grundlegende Neuerungen, die diese beiden Pfeiler stärken.
– Schnellere Top-k-Abfragen: In vielen Suche-Anwendungsfällen ist es viel wichtiger, schnell die ersten k (z. B. 20) Ergebnisse zu sehen, als zu erfahren, wie viele Treffer es insgesamt gibt. Wer beispielsweise auf einer E-Commerce-Website nach einem Produkt sucht, interessiert sich viel mehr für die 10 relevantesten Ergebnisse als für die anderen 120.897 Ergebnisse, für die ebenfalls Treffer gefunden wurden. In Elasticsearch 7.0 (und Lucene 8.0) gibt es einen neuen Algorithmus (Block-Max WAND), der das Abrufen der Top-Treffer merklich beschleunigt. – Intervallabfragen: In einigen Anwendungsfällen für die Suche, z. B. im juristischen oder Patentumfeld, ist es wichtig, Datensätze finden zu können, in denen Begriffe innerhalb einer bestimmten Distanz voneinander auftreten. Mit den Intervallabfragen in Elasticsearch 7.0 steht eine ganz neue Möglichkeit zur Strukturierung solcher Abfragen zur Verfügung. Im Vergleich zur bisherigen Methode („Span“-Abfragen) lassen sich Intervallabfragen wesentlich einfacher handhaben und definieren. Intervallabfragen sind auch deutlich resilienter als „Span“-Abfragen, wenn es um Randfälle geht. – Function Score 2.0: Benutzerdefiniertes Scoring gehört zum täglichen Geschäft bei Suche-Anwendungsfällen, die über die grundlegende Suche hinausgehen und nach kleinteiligeren Einflussmöglichkeiten auf das Relevanz- und Ergebnis-Ranking verlangen. Elasticsearch bietet diese Möglichkeit schon seit Langem. Mit Version 7.0 kommen Sie in den Genuss der nächsten Generation der Function-Score-Funktion, mit der sich das Ermitteln von Ranking-Scores für einzelne Datensätze einfacher, modularer und flexibler gestaltet. Die neue modulare Struktur ermöglicht die gemischte Nutzung von arithmetischen und Distanzfunktionen für arbiträre Function-Score-Berechnungen, wodurch die Nutzer das Zustandekommen des Ergebnis-Scorings und -Rankings besser beeinflussen können.
Geokachelraster für stufenloses Zoomen in Elastic Maps
Unsere Unterstützung von Geodaten hat sich im Laufe der Jahre kontinuierlich verbessert – vom erstmaligen Unterstützen von Geodaten in Elasticsearch in den Anfangstagen über die Einführung der Bkd-Baum-Datenstruktur in Lucene und ihrer Nutzung zur Verbesserung der Geoformen-Abfragegeschwindigkeit um mehr als das 25-Fache bis zum Elastic Maps-Dienst, der die Bereitstellung der globalen Grundkarte in Kibana ermöglicht.
In 7.0 setzen wir diese Tradition fort und führen mit „geotilegrid“ eine neue Aggregation in Elasticsearch ein, die es ermöglicht, mit (Geo-)Kartenkacheln so umzugehen, dass Nutzer in die Karte hinein- und aus ihr herauszoomen können, ohne dass sich dies auf die Form der Ergebnisdaten auswirkt. Die neue Aggregation gruppiert Geodatenpunkte (geopoints) zu Klassen, die Zellen in einem Raster darstellen. Jede Zelle entspricht dabei einer Kachel in einer Karte. In früheren Versionen gab es beim Zoomen leichte Änderungen an den Rändern der Form, da sich die Ausrichtung der rechteckigen Kacheln in Abhängigkeit von der Vergrößerungsstufe geändert hat. Elastic Maps in 7.0 verwendet bereits diese neue Aggregation, sodass gewährleistet ist, dass Ihre Ansicht beim Zoomen stabil bleibt. Dieses Maß an Genauigkeit ist wichtig – gleich, ob Sie Ihr Netzwerk vor Angreifern schützen, langsame Reaktionszeiten von Anwendungen an bestimmten Orten untersuchen oder Ihrem Bruder auf seiner Wanderung entlang des Pacific Crest Trail folgen möchten.
Bessere Unterstützung für Zeitreihen-Anwendungsfälle mit nanosekundengenauer Präzision
Ob Infrastrukturmetriken, Systemaudit-Logs, Netzwerk-Traffic oder ein Mars-Fahrzeug: Zeitreihendaten sind für viele Nutzer des Elastic Stack von zentraler Bedeutung. Sie müssen in der Lage sein, Ereignisse über mehrere Systeme und Dienste hinweg präzise zu ordnen und miteinander in Beziehung zu setzen.
Bislang wurden Zeitstempel in Elasticsearch nur mit Millisekundengenauigkeit gespeichert. 7.0 hängt noch ein paar Nullen dran und führt nanosekundengenaue Präzision ein. So erhalten Nutzer, die auf die Erfassung von Daten mit hoher Frequenz angewiesen sind, den Grad an Präzision, den sie für die genaue Speicherung und Ordnung dieser Daten benötigen. Ermöglicht wurde diese Änderung durch die Migration von der historischen JODA-Bibliothek zur offiziellen Java-Zeit-API in JDK 8.