向量数据库与图数据库:了解二者差异


 Share on Twitter
Share on Twitter在 Twitter 上分享

 Share on LinkedIn
Share on LinkedIn在 LinkedIn 上分享

 Share on Facebook
Share on Facebook在 Facebook 上分享

 Share by Email
Share by Email通过邮件分享

 Print this page
Print this page打印
大数据管理不仅仅是存储尽可能多的数据,而是要能够从中识别有意义的见解,发现隐藏的模式,并做出明智决策。这种对高级分析的追求一直是推动数据建模和存储解决方案创新的核心动力,其影响远远超越了传统的关系数据库。
向量数据库和图数据库就是这些众多创新中的典型代表。这两种数据库在数据管理领域均取得了显著的进步,各自提供了独具特色的数据结构,并展现出了各自独特的优势。但是,在您能够有效选出最适合自己项目或目标的数据库之前,您需要先深入了解它们的工作原理以及二者之间的区别。
本篇博客将为您提供指南,概述它们的工作原理、相似之处以及显著差异。我们将探讨两种数据库截然不同的数据结构、各自的理想用例,并帮助您在二者之间做出选择。为了便于理解,我们将内容拆分为以下几个部分:
向量数据库定义和概念
什么是图形数据库?
比较向量数据库和图形数据库
向量数据库和图形数据库用例
选择向量数据库还是图形数据库
在读完本篇文章后,您将会获得足够的信息来做出明智决策,以便让您最大限度地利用数据资源。
向量数据库定义和概念
与按行和列组织数据不同,向量数据库将数据组织为广阔多维空间中的点。每个点都代表一个数据片段,而数据片段所在位置反映的是其相对于其他数据片段的特征。您可以将它想象成一个宇宙,在这个宇宙中,每个星球代表一个数据片段,相似度高的星球彼此靠近,而相似度低的星球相距较远。
向量数据库通过将数据存储为高维向量来实现这一点,这些高维向量就是数据特征的数值表示。这些向量会捕捉它们所代表数据的本质,这也是在多维空间中对它们进行编码和组织的方式。在多维空间中,两个点距离越近,它们的底层数据就越相似。
这正是向量数据库擅长相似性搜索的原因。由于向量是基于相似性进行结构化的,因此您可以快速识别最接近查询向量的数据点。这使其成为许多重要应用的理想选择:
图像和文档检索:根据内容而不只是关键字查找相似图像。
个性化推荐:推荐与用户此前互动过的产品或内容相似的项目。
异常检测:识别偏离常态的异常数据点,这些数据点可能表明存在欺诈或系统错误。
机器学习:高效处理和分析高维数据,用于文本分析、图像分类和自然语言处理等任务。
想要更详细的指南?请阅读“什么是向量数据库?”以获取完整讲解。
什么是图形数据库?
尽管图数据库乍看之下可能与其他数据库相似,但它们组织数据的方式完全不同。图数据库既不像关系数据库那样使用固定表,也不像向量数据库那样按相似性组织数据,而是以图结构存储数据。实体在图中表示为节点,关系则表示为边。您可以把它想象成思维导图:每个节点都是一个圆圈,代表人、地点或事物;节点之间的线条(边)则表示它们之间的连接方式。
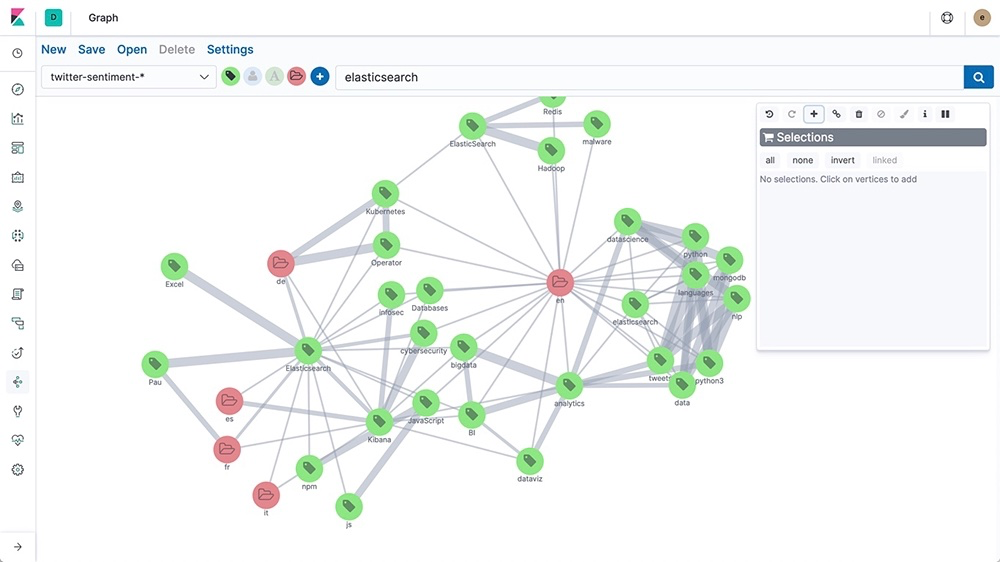
这种结构的一大优势在于,它可以更自然地表示复杂关系。与其他类型的数据库相比,这种结构更便于解读连接关系。图数据库的无模式结构还意味着,随着数据增长,您可以轻松添加新的节点和边,使其兼具灵活性与可扩展性。因此,图数据库非常适合许多应用场景:
实时分析:使用图形数据库实时分析流数据,预测未来结果,并优化动态系统。
主数据管理:创建一个一体化的实体视图,消除歧义,并在一个单个互连图形中跟踪实体的演变。
网络发现:通过分析网络中的关系,发现隐藏连接、识别异常并预测级联故障。
知识图谱构建:通过相互关联的实体和概念,构建智能知识库、回答复杂问题,并为智能应用提供支持。
比较向量数据库和图形数据库
现在,您应该已经了解每种数据库是什么,以及它们如何组织数据。但同样重要的是,您还需要理解向量数据库和图数据库之间的细微差别。最简单的方法是进行并列比较:
| 向量数据库 | 图形数据库 | |
| 数据表示 | 数据被结构化地表示为广阔多维空间中的点。这些点之间的距离越近,代表的内容越相似。这种结构非常适合捕捉数据本身固有的相似性,无需考虑数据之间的连接或关系。 | 数据被结构化为由相互连接的节点(实体)和边(关系)组成的网络。重点在于表示数据点之间的连接和层级关系,从而深入洞察实体彼此之间的关联方式。 |
| 查询和检索 | 擅长相似性搜索,能够有效找到与所查询向量相似的数据点。非常适合处理图像/文档检索等任务,在这些任务中,理解内容相似性至关重要。 | 功能强大,可用于导航关系和连接。能够高效遍历网络结构,非常适合进行社交网络分析、推荐系统和知识图谱的探索。 |
| 性能和可扩展性 | 得益于经过优化的相似性搜索算法,通常能够很好地扩展以处理大型数据集。不过,模式变更可能需要重新生成数据嵌入,从而影响性能。 | 由于无模式的特性,因此它具备高度的灵活性,可轻松添加和修改数据。然而,复杂的查询或庞大的网络可能会对性能造成压力,因此需要谨慎优化。 |
用例
为了更好地理解向量数据库和图数据库之间的差异,我们来比较一下二者如何应用于同一领域。这不仅可以展现二者之间的对比,也能说明它们如何结合使用,以取得出色效果:
欺诈检测
向量数据库:通过分析交易模式和用户信息来识别欺诈性交易。根据学习到的相似性画像,检测消费习惯、购买地点或设备指纹中的异常情况。。
- 图数据库:发现可疑的关联个人或交易网络。通过分析潜在欺诈企图中所涉及实体之间的关系,迅速识别出欺诈活动
科学研究
向量数据库:分析复杂的数据结构,如蛋白质序列、基因表达或化合物。比较不同的数据集,根据多维特征识别相似之处,从而得出新的科学发现。
- 图数据库:对生物通路或分子相互作用进行建模。探索实体之间错综复杂的关系,并可视化复杂系统,从而更深入地理解生物过程。
电子商务
向量数据库:分析图像、文本描述和技术规格等产品属性。基于内容相似性推荐相似产品,从而提供更相关、更有吸引力的建议。。
- 图数据库:获取购买记录、浏览历史和愿望清单等用户与产品之间的互动信息。根据用户与其他品味相近用户之间的相似度来推荐产品,从而打造更加个性化的购物体验。
媒体与娱乐
向量数据库:分析音乐流派、文章主题或电影主题等内容特征。根据内容本身的相似性推荐相似歌曲、电影或文章,从而满足个人偏好。
- 图数据库:探索观看历史、阅读列表或社交媒体分享等用户与内容之间的关系。根据兴趣相似用户之间的连接推荐内容,从而促进互动与发现。
选择向量数据库还是图形数据库
即便掌握了本文介绍的信息,选择合适的数据库仍可能是一项艰巨任务。为了简化这一过程,下面提供了一个可供参考的框架,帮助您做出最适合实现目标的决策。
第 1 步:了解您的数据
这一过程的第一步,是评估数据的复杂性。您的数据主要是结构化数据还是非结构化数据?它涉及复杂关系,还是由相互独立的实体组成?
您还需要考虑您的数据量以及预计的增长速度。然后,您需要决定哪些具体的特征或属性定义了您的数据点——以及这些特征或属性是数值型的还是分类型的。
第 2 步:确定主要用例
简单来说,您希望从数据分析中获得哪些见解?您是希望基于内容查找相似数据点,还是探索实体之间错综复杂的连接关系?您会频繁执行哪类查询?
第 3 步:性能和可扩展性需求
第三步是思考速度和可扩展性对实现目标有多重要。实时响应对您的应用有多关键?您的数据集有多大,预期查询有多复杂?您还需要考虑预算约束和资源限制。
第 4 步:评估每种技术的具体优势
每种数据库类型都有各自的优势和局限。向量数据库非常适合相似性搜索,能够高效处理高维数据,并且可以很好地应对大型数据集。图数据库擅长关系导航,适用于复杂网络分析,并且具有高度灵活的模式设计。
释放数据的全部潜能
驾驭庞大的大数据量需要强有力的工具,矢量数据库和图形数据库作为信息领域的创新参与者脱颖而出。然而,选择适合您需求的正确模型可能会颇具挑战性。
请仔细评估上述因素,了解每种技术的独特优势。您最终会整理出一份因素清单,为您制定决策提供参考,从而帮助您选择正确的数据库模型,以释放数据的全部潜能。
您接下来应该怎么做
无论您何时准备就绪,我们都可以通过下面四种方式帮助您为企业打造更好的搜索体验:
本文中描述的任何功能或功能性的发布和时间均由 Elastic 自行决定。当前尚未发布的任何功能或功能性可能无法按时提供或根本无法提供。
在本博文中,我们可能使用或提到了第三方生成式 AI 工具,这些工具由其各自所有者拥有和运营。Elastic 对第三方工具没有任何控制权,对其内容、操作或使用不承担任何责任或义务,对您使用此类工具可能造成的任何损失或损害也不承担任何责任或义务。请谨慎使用 AI 工具处理个人、敏感或机密信息。您提交的任何数据都可能用于 AI 训练或其他目的。Elastic 不保证您所提供信息的安全性或保密性。在使用任何生成式 AI 工具之前,您都应自行熟悉其隐私惯例和使用条款。
Elastic、Elasticsearch、ESRE、Elasticsearch Relevance Engine 及相关标志为 Elasticsearch N.V. 在美国和其他国家/地区的商标、徽标或注册商标。所有其他公司和产品名称均为其相应所有者的商标、徽标或注册商标。
分享
- Share on Twitter
在 Twitter 上分享
- Share on LinkedIn
在 LinkedIn 上分享
- Share on Facebook
在 Facebook 上分享
- Share by Email
通过邮件分享
- Print this page
打印