我们改进 Elasticsearch 可扩展性的三种方法


 Share on Twitter
Share on Twitter在 Twitter 上分享

 Share on LinkedIn
Share on LinkedIn在 LinkedIn 上分享

 Share on Facebook
Share on Facebook在 Facebook 上分享

 Share by Email
Share by Email通过邮件分享

 Print this page
Print this page打印
“一个人只有挑战极限才能发现自己的极限。”
Herbert A. Simon
Elastic 专注于让用户快速搜索出可大规模操作且高度相关的结果,从而为用户带来价值 — 速度、扩展和相关性一直是我们的初心。在 Elasticsearch 7.16 版中,我们将重点放在了扩展上,一步步突破 Elasticsearch 的极限,以实现更快的搜索速度、更低的内存要求和更稳定的集群。一路走来,我们在分片维度方面获得了一系列发现,并在这个过程中将 Elasticsearch 的查询速度提升到了新高度。
过去,由于涉及到资源开销,我们建议避免在集群中创建大量分片。然而,随着 Fleet 中涌现出新的数据流索引策略,从安全和可观测性用例中生成的小分片越来越多,因此,我们必须找到新方法来应对日益增长的分片数量。在这篇博文中,我们将介绍 Elasticsearch 中的三大扩展挑战,以及我们是如何在 7.16 及更高版本中改进体验的。

简化授权
打个比方,就像您走进一家酒吧时,有人在门口已经检查过您的身份证了,然后每次点饮品的时候,都还要再次检查您的身份证。在 7.16 版发布之前,授权就是这样运行检查的,其中每个节点(门)都需要进行授权检查,每个分片(饮品点单)也需要进行授权检查。但是,如果在门口检查一次身份证就能完成这两个事件了呢?我们不妨将同样的概念应用到 Elasticsearch 中的授权上!
在 Elasticsearch 中,用户可以设置基于角色/属性的访问控制,以授予对每个字段、每个文档或每个索引级别的细粒度权限。以前,搜索查询的许多阶段中都需要进行授权,以确保未经授权的请求无法访问未经授权的数据。然而,对授权功能的小心戒备是有代价的,而且一些逻辑不能随着集群大小的增加而横向扩展。 例如,在大型集群中,用于收集所有索引中所有字段的获取字段功能,可能需要好几秒钟甚至几分钟才能完成,因为几乎所有执行时间都花在了与授权相关的工作上。
7.16 版从以下两个方面解决了这些问题:
- 对授权算法进行了改进,加快了单个请求的授权速度,无论是在对 REST 请求授权时,还是在 Elasticsearch 集群内节点之间的传输层通信(即所有内部节点到节点通信)期间进行授权,授权速度都有了极大提升。
- 内部请求的授权要么继承自以前的检查,要么在许多情况下成本都有了显著降低。在 7.16 版之前,Elasticsearch 在授权集群内的内部传输请求时,执行的是与通过初始外部请求相同的授权逻辑。这样做是为了避免在内部节点到节点通信中引入攻击面,使得攻击者通过编写内部请求来绕过授权逻辑。现在,通过跳过子请求上的通配符扩展、跳过对节点本地请求(在同一节点内)的授权,以及减少搜索等操作所需的总请求数量,这种方法的成本已经变得非常低廉。
在 pre-filter 阶段减少分片请求
7.16 版在 pre-filter 阶段实施了一种新的搜索策略,可将请求数量减少到每个匹配节点一次。在 7.16 版之前,如果搜索的第一阶段试图从已知不包含任何相关数据的查询中筛选出所有分片,就需要从协调节点向数据节点发出请求,每个分片一次。当一次查询数千个分片时,就需要从协调节点为每个搜索请求发送数千个请求,在协调节点上处理数千个响应,还要在数据节点上处理和响应所有这些请求。虽然将集群扩展到更多的数据节点可以提高在数据节点上处理大量请求的性能,但对协调节点上此操作的性能没有帮助。
从 7.16 版开始,执行 pre-filter 阶段的策略已经调整为,在该阶段每个节点只发送一个请求,覆盖节点上的所有分片。下面的图 1 中显示了调整过程。这样一来,不管要搜索的分片数量有多少,在最初的搜索阶段,在三个数据节点上容纳数千个分片的集群看到的网络请求数量将从数千个变为三个或更少。7.16 版之前,因为发送的每个分片请求在所有分片(即搜索查询)中都包含几乎相同的数据,因此,每个节点只发送一个请求,意味着这些信息不再会在多个请求中重复出现,从而大幅减少了必须通过网络发送的字节数。
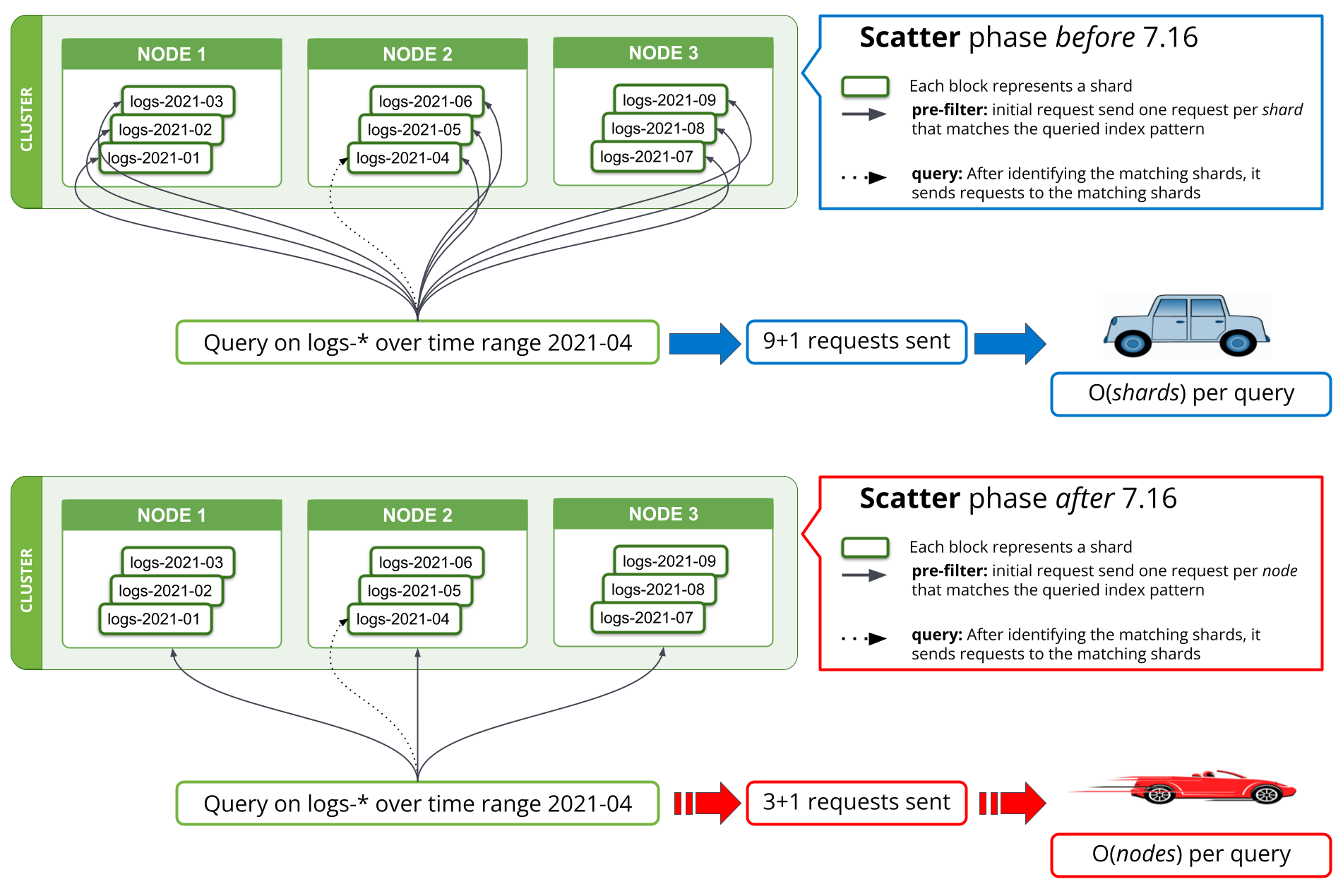
Kibana 和 *QL 查询使用的 field_caps 也实施了类似的策略。从理论上讲,网络请求中保存的搜索请求从每个查询 O(shards) 减少到了 O(nodes);实际上,我们的基准测试结果表明,在大型日志集群中查询数月数据的日志,用时从几分钟缩短到了不到 10 秒。这里所实现的时间节省,不仅有助于减少网络请求的数量,还有助于减少与这些请求相关的内存和 CPU 使用率。
减少内存占用
说起来可能会让人惊讶,但航空公司确实可以通过一些方式来实现大幅减重,比如拿掉沙拉中橄榄,用更薄的玻璃器皿,以及印刷更小版面的杂志。我们在 Elasticsearch 中也采用了类似的方法,也就是减少每个字段的内存成本。尽管我们谈论的每个字段只有几千字节,但当乘以集群中所有索引的数百万个字段时,我们就能够节省大量的堆。
Elasticsearch 数据节点上的堆使用量取决于索引数量、每个索引的字段,以及在集群状态下存储的分片。拥有大量索引,就意味着无论节点上的负载如何,堆内存都会持续被占用。在 7.16 版中,我们为文本和数字字段重建了字段构建器,从而减少了它们的内存占用,仅仅在保存这些字段结构上,就实现了 90% 以上的内存减少。
我们采集数据、搜索信息、克服挑战
自该版本推出以来,我们看到了在实际工作负载集群中所做的各项改进。下面几个图表显示了升级对这一拥有 60 个数据节点集群的影响。
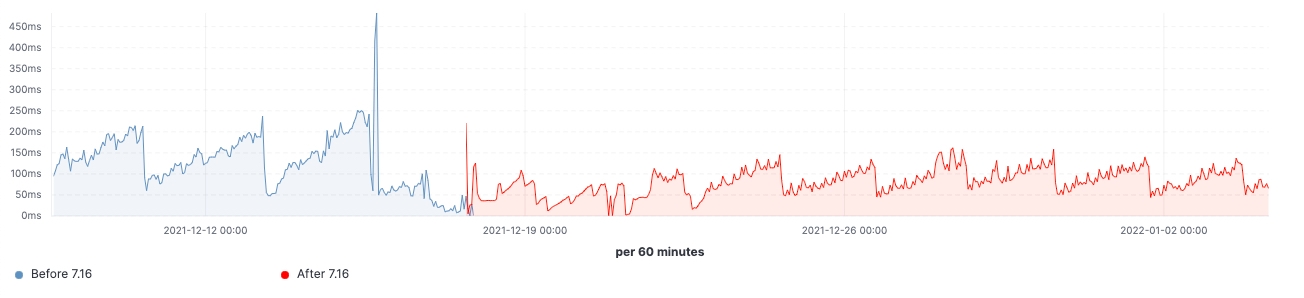
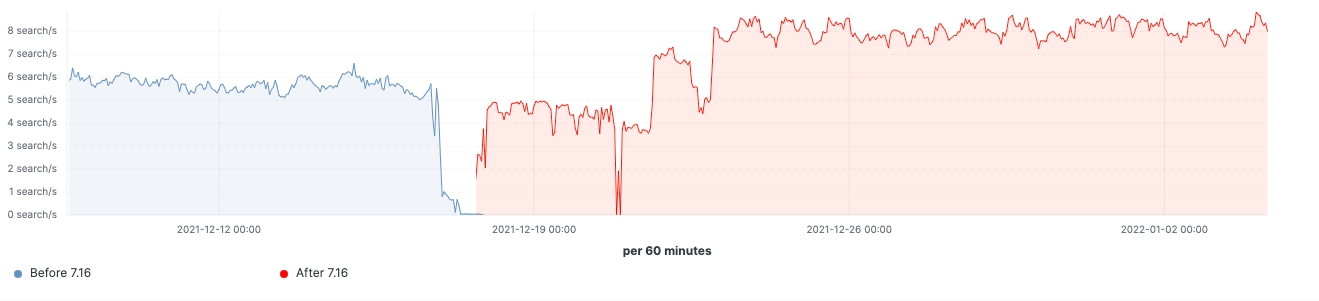
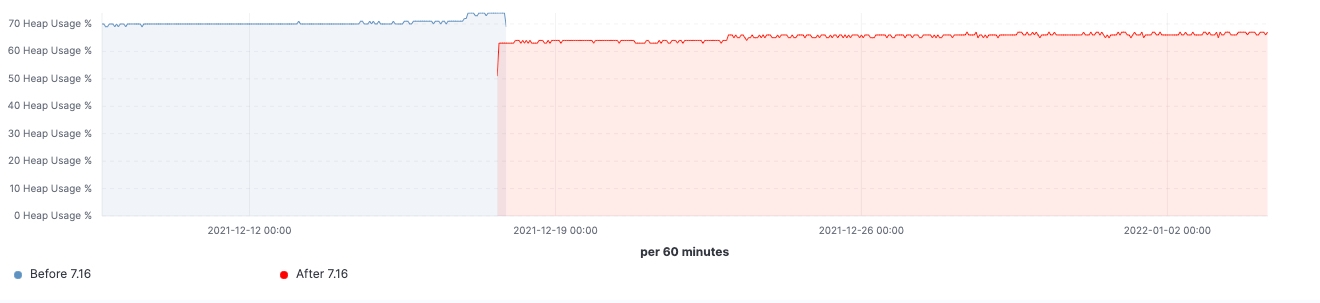
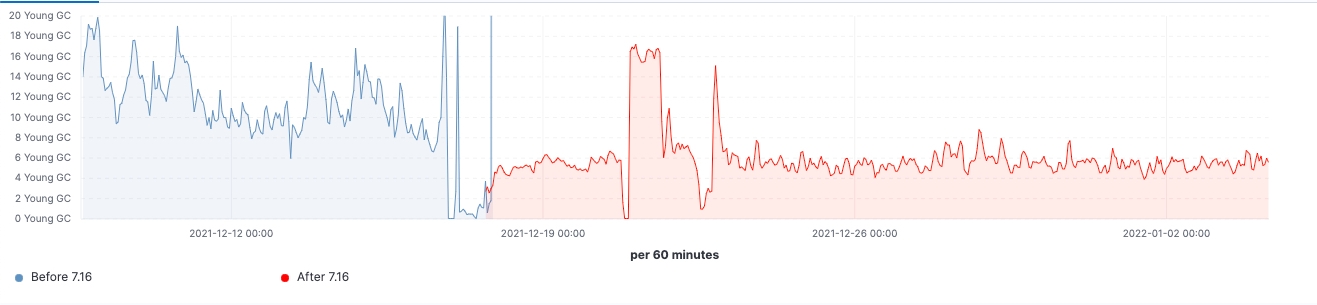
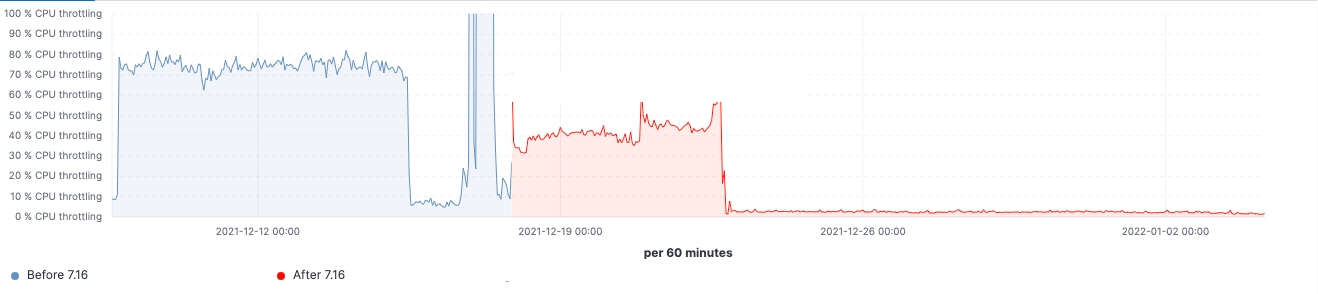
在这个集群中,我们能够看到在升级前后同样工作负载的变化,其中 99% 的搜索延迟已全面降低,搜索速率(吞吐量)已提升,并且由于存储数据结构上的内存占用减少,冻结节点上的堆使用量始终处于较低水平。预计这会对所有的数据层产生影响,但在冻结层上最为明显,因为这里堆主要用于存储数据结构,不像堆在热节点上可以用于索引、查询和其他活动。按节点角色划分,协调节点在年轻代 GC 计数方面的减少最为显著,这要归功于在 pre-filter 阶段减少了分片请求。最后,随着集群状态管理的改进,对主节点的 CPU 限制需求大大降低。
我们调查了 Elasticsearch 在扩展到数万个分片时出现性能问题的原因,以及 Elasticsearch 7.16 版中的目标可扩展性改进。 众所周知,拥有海量分片和映射爆炸是导致 Elasticsearch 崩溃的首要因素,因此仍应避免这些问题 — 但在 7.16 版中实施多项改进后,这些问题的影响预计会小得多。在这一版本中,改进主要集中在集群的整体大小上,使较小的主节点能够处理集群状态更新,并简化了大量索引之间的搜索协调。
Elasticsearch 的性能在 7.16 版中有了质的飞跃,您现在可以享受到更快的搜索引擎、更低的内存要求和更强的集群稳定性 — 只需升级即可体验!我们会继续改进可扩展性的各个方面,并将在 8.x 中和大家分享更多成果。
准备好进一步扩展了吗?
Elastic Cloud 的现有客户能够直接从 Elastic Cloud 控制台访问其中的许多功能。如果您刚刚使用 Elastic Cloud,请查看我们的快速入门指南(助您快速入门的培训短视频)或我们的免费基础知识培训课程。您随时可以免费开始使用 Elastic Cloud 的 14 天免费试用版。或者,您也可以免费下载 Elastic Stack 的自管型版本。
欢迎阅读 Elastic 7.16 版发行说明,了解以上功能及更多信息;此外 Elastic 7.16 版发布博文中还介绍了 Elastic Stack 的其他亮点。分享
- Share on Twitter
在 Twitter 上分享
- Share on LinkedIn
在 LinkedIn 上分享
- Share on Facebook
在 Facebook 上分享
- Share by Email
通过邮件分享
- Print this page
打印