在 Elastic Cloud 上的 Elasticsearch 服务中,如何针对日志和指标用例确定热温架构的规模
希望深入了解 Amazon Elasticsearch 服务和我们官方 Elasticsearch 服务之间的区别吗?请访问我们的 AWS Elasticsearch 对比页面。
最近一段时间推出了很多激动人心的变化!Elastic Cloud 上的 Elasticsearch 服务最近新增了面向广泛硬件选择的支持,并且还增加了针对部署模板的支持;这些变更使得 Elastic Cloud 上的 Elasticsearch 服务成为高效处理日志和指标相关工作负载的完美选择。由于推出了所有这些新灵活功能,用户也需要做出许多选择。如何针对您的用例选择最为适宜的架构,以及如何预估所需的集群规模,这些都是棘手的问题。但是您不用担心,我们随时为您提供帮助!
本篇博文将会向您详细解释日志和指标用例常用的不同架构,以及何时使用这些架构。本文还会提供一些指南来帮助您确定集群规模并对集群进行管理,以便您能充分利用自己的集群。
我可以针对日志集群采用哪些架构呢?
在所有 Elasticsearch 集群中,最简单的一种架构是:所有数据节点的规格相同,并且可以处理所有角色。如果采用这种架构,随着集群规模的增大,用户通常需要添加针对具体任务的节点,例如专用的主节点、采集节点,以及 Machine Learning 节点。这样会减轻数据节点的负载,并提高这些数据节点的运行效率。在此种类型的集群中,所有数据节点会平均分担索引和查询负载,而且由于这些数据节点的配置相同,我们通常将此种架构称为同质或统一集群架构。
另一种十分热门的架构便是我们所说的热温架构,当处理诸如日志和指标等时序型数据时,这一架构尤为常用。此架构基于下列原则:数据通常是不可更改的,并且能够索引到时序型索引中。由于每个索引仅包含特定时间段的数据,所以用户有可能通过删除整个索引来管理数据保留时间和数据生命周期。此架构有两种不同类型的数据节点(拥有不同的硬件配置文件):“热”和“温”数据节点。
由于所有最新索引均位于热数据节点上,所以热数据节点会处理集群中的全部索引负载。鉴于最新数据的查询频率通常也最为频繁,所以这些节点一般而言都会十分繁忙。将数据索引到 Elasticsearch 中需要占用大量 CPU 和 I/O 资源,再加上还要处理查询负载,因此这些节点需要具有十分强大的性能,并且可以十分快速地进行存储。一般而言,这意味着需要使用本地附加型 SSD(固态硬盘)。
温节点则已经过优化,能够在节省成本的同时满足集群中只读索引的长期存储需求。温节点一般拥有较大的内存和 CPU,但通常会使用本地附加型转盘式硬盘或 SAN,而不会使用 SSD。一旦热节点上的索引超过了这些节点的保留期限,并且 Elasticsearch 不再向其中索引数据,这些索引便会转移到温节点上。
有很重要的一点需要注意:将数据从热节点转移至温节点并不意味着查询速度肯定会变慢。由于温节点根本不处理任何占用大量资源的索引负载,所以温节点通常无需使用 SSD 类存储,便能高效完成早期数据的查询请求,并且延迟较低。
由于此种架构中的数据节点具有十分专一的用途,并且可能需要处理很高的负载,所以我们推荐使用专门的主节点、采集节点、Machine Learning 节点以及纯协调节点。
我应该选择哪种架构呢?
对很多用例而言,这两种架构的效果都很好,因此对于选择哪种架构,我们并不能直接给出明确的答案。然而,的确存在一些特定的条件和限制,使得某种架构在这些情形下能够更胜一筹。
集群可以使用的存储类型是一个需要考虑的重要因素。由于在热温架构中热节点需要十分快速的存储性能,所以如果集群仅限使用较慢的存储工具,则热温架构并不合适。在这种情况下,最好使用统一架构,并将索引和查询负载扩展到尽可能多的节点上。
尽管 SSD 越来越普遍,但统一集群通常仍由附加作为区块存储工具的本地转盘式硬盘或 SAN 提供支持。如果存储速度较慢,则可能不能支持特别高的索引速度,若同时还有查询负载,这种情况会尤为明显;有鉴于此,如果存储速度较慢,可能需要很长时间才能填满可用的磁盘空间。因此,只有在您有充分理由需要长期存储数据时,才可能需要在每个节点上存放大量数据。
如果用例规定的保留期限很短(例如少于 10 天),那么索引完成后,数据不会在磁盘上长期闲置。这要求具备强大的存储性能。热温架构可能适用,但是仅有热数据节点的统一集群可能效果会更好,也更加易于管理。
我需要多少存储空间呢?
确定日志和/或指标用例的集群规模时,其中一个主要问题便是存储量。原始数据量与数据在 Elasticsearch 中完成索引和复制后所占磁盘空间之间的比例,在很大程度上取决于数据类型以及索引方式。下图显示了数据在索引过程中经过的不同阶段。
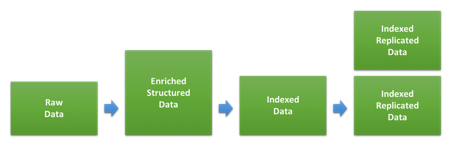
第一步需要将原始数据转换为 JSON 文档,然后我们才能将这些 JSON 文档索引到 Elasticsearch 中。数据量在这一过程中的变化不仅取决于初始格式和新增结构,同时还取决于在各种数据扩充过程中所增加的数据量。对于不同类型的数据,这一数值可能会有很大差别。如果您的数据已经是 JSON 格式并且您并未新增任何数据,则数据量完全不会变化。而如果您的数据是文本型网络访问日志,新增结构以及用户代理和地点信息的数据量可能会大得多。
我们将这些数据索引到 Elasticsearch 中后,所用的索引设置和映射将决定这些数据会占用多少磁盘空间。Elasticsearch 应用的默认动态设置通常出于灵活性的目的而设计,而非出于优化磁盘存储空间的目的,因此如要节省磁盘空间,您可以通过定制索引模板来对所用映射进行调优。有关这一主题的更多指南,请参见调整文档。
如要预估特定类型的数据会在您的集群中占用多少磁盘空间,您可以对足量数据进行索引,以便确保您达到在生产环境中很可能要使用的分片规模上限。常见错误之一是使用过小的数据量进行测试,因为这样得出的结果并不准确。
我如何在采集和查询之间实现平衡呢?
确定集群规模时,大部分用户运行的第一个基准测试通常是确定集群的最大索引吞吐量。毕竟,这项基准测试十分容易设置和运行,而且结果也可用来确定数据将会占用多少磁盘空间。
一旦我们对集群和采集过程调整完毕,并且已经确定可以维持的最大索引速度,我们便能计算,如以最大吞吐量进行索引,需要多长时间方能填满数据节点上的磁盘。这一结果便能告诉我们,假定要最大程度利用可用磁盘空间,这种节点类型的最短保留期限为多久。
您可能会倾向于直接使用这一结果来确定所需规模,但是由于所有系统资源均会用于索引,所以此方法并没有为查询留出任何余量。毕竟,大部分用户在 Elasticsearch 中存储数据的目的是为了在日后进行查询,并且希望获得卓越的查询性能。
那么,我需要为查询流出多少余量呢?很难针对此问题给出一个通用答案,因为这很大程度上取决于预计的查询数量和性质,以及用户的预期延迟。确定余量的最好方法是模拟不同数据量和索引速度时的实际查询水平进行基准测试,具体操作详见这个关于通过定量方式确定集群规模的 Elastic{ON} 演讲,以及关于集群基准测试和规模确定的网络研讨会(所用工具为 Rally)。
一旦确定了在满足用户查询(且性能在可接受范围内)的前提下可以维持最大索引吞吐量中的多大比例,我们便能调整预期保留期限以匹配这一降低后的索引速度。如果我们降低索引速度,则填满磁盘所用的时间就会变长。
通过这一调整,我们能够应对小型流量峰值,但一般而言,我们均假定索引速度长期范围内会十分稳定。如果预计流量水平有峰值并且会全天上下浮动,我们可能需要假定调整后的索引速度与峰值水平相对应,甚至进一步降低我们所假定每个节点可以处理的平均索引速度。如果上下浮动是可以预测的,并且上下浮动的持续时间较长(例如上班期间),则还有另外一种方式,即仅在此段时间内增加热区的规模。
我如何使用全部这些存储空间呢?
在热温架构中,我们预计温节点能够存储大量数据。这一点同样适用于保留期限较长的统一架构中的数据节点。
通常而言,节点能够成功存储的准确数据量取决于您能在多大程度上良好地管理堆的使用情况,堆的使用情况常常会变为密集节点的主要限制因素。由于很多因素都会影响 Elasticsearch 集群内堆的使用情况(例如索引、查询、缓存、集群状态、字段数据,以及分片开销),所以不同用例的结果会有所不同。要想精准确定您的用例的限制因素,最佳方法是基于实际数据和查询模式运行基准测试。然而,关于日志和指标用例,有很多通用的最佳实践能够帮助您最充分利用自己的数据节点。
确保已对映射进行调优
如之前所讲,数据所用的映射会影响数据在磁盘上的密集程度。映射还能影响您可使用多少字段数据,并对堆的使用情况产生影响。如果您正在使用 Filebeat 模块或 Logstash 模块来解析和采集数据,由于这些模块自带开箱即用的已调优映射,所以您无需过于担心这一点。然而,如果您解析的是自定义日志,并且大量依赖 Elasticsearch 的能力来动态映射新字段,则您应当继续读下去。
当 Elasticsearch 动态映射字符串时,默认行为是使用 multi-fields(多字段),从而将数据同时映射为文本(可用于不区分大小写的自由文本搜索)和关键字(用于在 Kibana 中对数据进行聚合)。这是一项很好的默认设置,因为它能实现最佳灵活性,但却有一个不足之处:此设置会增加磁盘上索引的规模,也会增加所用字段数据的数量。因此,我们建议,但凡有可能,都要仔细查看映射并对映射进行调优,因为随着数据量的增长,这一设置会产生十分重大的影响。
尽量加大分片规模
Elasticsearch 中的每个索引都包含一个或多个分片,每个分片都会有开销,而这些开销均会使用部分堆空间。如这篇有关分片的博文所述,相较于规模较大的分片,较小分片的每单位数据量的开销会高一些。所以,为了在用于存储大量数据的节点上最大限度降低堆使用量,很重要的一点就是尽量加大分片规模。这里有一条很好的经验法则:对于长期保留用例,将平均分片规模保持在 20GB 至 50GB 之间。
因为每个查询和聚合在每个分片上都是单线程运行的,所以最低查询延迟通常取决于分片规模。由于分片规模取决于数据和查询,所以甚至同一用例中的不同索引之间也会有所不同。然而,对于特定数据量和数据类型,我们并不能确定相较于单个规模较大的分片,使用多个规模较小的分片会实现更优性能。
为了确定最佳的查询使用量和最低开销,很重要的一点是测试分片规模的效果。
进行调整以提高存储量
能否对 JSON 文档进行高效压缩,将会显著影响数据在磁盘上占用的空间大小。Elasticsearch 压缩这些数据时使用的默认压缩算法已进行调整,能够在存储和索引速度之间实现平衡,但是 Elasticsearch 同时也提供了一种更为节省存储空间的方法: best_compression codec。
您可以针对所有新索引指定此算法,但这种算法会导致索引性能降低大约 5-10%。因为节省的磁盘空间可能十分显著,所以这可能是个值得一试的折衷办法。
如果您遵循前一节中的建议正准备强制合并索引,您还可以先应用经过改进的压缩算法,然后再进行强制合并操作。
避免无必要的负载
我们此处要讨论的会影响堆使用情况的最后一个因素是请求处理。对于发送至 Elasticsearch 的所有请求,它们都是在到达时所在的节点上进行协调的。然后会对这些请求进行分区,并将它们分发到数据所在的位置。这一点同时适用于索引和查询。
请求和响应的解析和协调过程会对堆的使用情况产生重大影响。确保用于协调或索引的节点拥有足够的堆余量,以便能够应对此种情况。
如果节点已经针对长期数据存储进行调整,通常较为合理的一种做法是将此节点作为专门的数据节点,并最大程度降低该节点需要执行的其他工作。如要帮助实现上述目标,可将所有查询均导向热节点或者专门的纯协调节点。
如何将这些内容应用到我的 Elasticsearch 服务部署中呢?
Elasticsearch 服务目前已在 AWS 和 GCP 上推出,尽管这两个平台上的实例配置和部署模板是一样的,但是规格却稍有不同。在本节中,我们将会看一下不同的实例配置,以及如何在之前讨论的架构中使用这些配置。我们还会看一下如何预估所需的集群规模以便为示范用例提供支持。
可用的实例配置
Elasticsearch 服务一直以来都拥有由快速 SSD 存储提供支持的 Elasticsearch 节点。这些称为 highio 节点,拥有杰出的 I/O 性能。这使得它们十分适合作为热温架构中的热节点,但是也可作为统一架构中的数据节点。如果您的数据保留期限较短,并且需要高性能存储,我们通常会推荐使用此类节点。
在 AWS 和 GCP 上,highio 节点的磁盘与内存的比例为 30:1,所以对于 1GB 的内存,需要有 30GB 的存储空间。AWS 上可用的节点规模分别为 1GB、2GB、4GB、8GB、15GB、29GB 和 58GB;而 GCP 上可用的节点规模分别为 1GB、2GB、4GB、8GB、16GB、32GB 和 64GB。
最近在 Elastic Cloud 上推出的另一种节点类型是已针对存储进行调优的 highstorage 节点。这些节点有大量的慢速存储空间,磁盘与内存的比例为 100:1。GCP 上 64GB 的 highstorage 节点可以提供超过 6.2TB 的存储空间;而 AWS 上 58GB 的节点则可支持 5.6TB 的存储空间。此类节点类型的内存大小与各自平台上的 highio 节点相同。
这些节点通常作为热温架构中的温节点。对 highstorage 节点进行的基准测试显示,GCP 上此种类型的节点性能要远优于 AWS,即使排除二者之间规模的差异因素后,依然如此。
使用两个或三个可用区
在大部分区域,您可以选择在两个或三个可用区上运行,而且可以在集群中为每个可用区选择不同数量的节点。如果保持在可用区的固定数量范围之内,可用集群的规模会大约增长一倍,至少对规模较小的集群而言如此。如果可以接受使用两个或三个可用区,您可以按照较小的增量调整规模,这是因为对于相同的节点规模,从两个可用区提高至三个可用区仅会将容量提高 50%。
确定规模示例:热温架构
在这个示例中,我们将会看一下如何确定下列热温集群的规模:此集群每天能够采集 100GB 的原始网络访问日志,数据的保留期为 30 天。我们会同时使用 AWS 和 GCP 上的 Elastic Cloud 进行部署,以便进行对比。
请注意:此处所用数据仅作为示例,您的用例很可能会有所不同。
第 1 步:预估总数据量
在此示例中,我们假定数据是使用 Filebeat 模块进行采集的,所以映像已完成调优。为简单起见,我们在此示例中仅使用单一类型的数据。在索引基准测试期间,我们看到原始数据量和索引后所占磁盘空间之间的比例大约为 1.1,所以 100GB 的原始数据预计会在磁盘上产生 110GB 的索引数据。添加完复制索引后,此数值会翻倍,变为 220GB。
在 30 天内,索引数据和复制数据的总量为 6600GB,这就是集群需要处理的总量。
本示例假定在所有区中使用了 1 个复制分片,因为业内认为这是兼顾性能和可用性的最佳实践。
第 2 步:确定热节点的规模
我们已经使用此数据集针对热节点运行了一些最大索引基准测试,并且看到大约需要 3.5 天将 AWS 和 GCP 中 highio 节点上的磁盘填满。
为了给查询和小型流量峰值流出一些余量,我们假定仅能将索引吞吐量维持在不超过最高水平 50% 的范围内。如想完全利用这些节点上的可用存储,我们需要在更长时间内向这些节点中索引数据,所以我们在这些节点上调整了保留期限以反映这一要求。
由于 Elasticsearch 还需要一些备用磁盘空间以实现高效运行,所以为了不超过 disk watermarks(磁盘水位线),我们假定需要 15% 的额外磁盘空间进行缓冲。该值显示在下面表格中的“所需磁盘空间”列。基于这些数据,我们便可以确定对于每个供应商所需的总内存量。
| 平台 | 磁盘与内存的比例 | 填满所需天数 | 有效保留期(天) | 需存储的数据量 (GB) | 所需磁盘空间 (GB) | 所需内存 (GB) | 可用区规格 |
| AWS | 30:1 | 3.5 | 7 | 1440 | 1656 | 56 | 29GB,两个可用区 |
| GCP | 30:1 | 3.5 | 7 | 1440 | 1656 | 56 | 32GB,两个可用区 |
第 3 步:确定温节点的规模
热节点上超出保留期的数据将会转移到温节点。通过计算这些节点需要存储的数据量,我们便可以预估所需的规模,计算时需要将高磁盘水位线的开销考虑在内。
| 平台 | 磁盘与内存的比例 | 有效保留期(天) | 需存储的数据量 (GB) | 所需磁盘空间 (GB) | 所需内存 (GB) | 可用区规格 |
| AWS | 100:1 | 23 | 5060 | 5819 | 58 | 29GB,两个可用区 |
| GCP | 100:1 | 23 | 5060 | 5819 | 58 | 32GB,两个可用区 |
第 4 步:添加其他节点类型
除了数据节点,我们通常还需要 3 个专用主节点,以便提高集群的弹性和可用性。由于这些节点不处理任何流量,所以它们的规模很小。最初为全部 3 个可用区分配 1GB 至 2GB 的节点便是一个不错的选择。随着托管集群规模的增长,然后可将这些节点的规模扩大至 16GB 左右(针对全部 3 个可用区)。
接下来呢?
如果还没使用,欢迎免费试用 14 天 Elasticsearch 服务,动手尝试一下吧!亲自体验一下设置和管理过程有多么简单。如有任何问题,或者希望了解有关确定 Elastic Cloud 上 Elasticsearch 服务规模的更多建议,请直接与我们联系,也可在公共论坛中与我们进行互动。