Kibana 中 Vega 可视化入门
Vega 声明性语法是可视化数据的一种强大方法。Kibana 6.2 中引入了一个新功能,您现在可以用 Elasticsearch 数据构建丰富的 Vega 和 Vega-Lite 可视化。所以,让我们从几个简单的例子开始学习 Vega 语言。
首先,打开 Vega 编辑器 - 一个实验原始 Vega 的方便工具(它没有 Elasticsearch 定制)。复制下面的代码,您会在右侧面板中看到“Hello Vega!”文本。

{
"$schema": "https://vega.github.io/schema/vega/v3.json",
"width":100, "height":30,
"background": "#eef2e8",
"padding":5,
"marks": [
{
"type": "text",
"encode": {
"update": {
"text": { "value":"Hello Vega!" },
"align": { "value": "center"},
"baseline": { "value": "middle"},
"stroke": { "value": "#A32299" },
"angle": { "value":15 },
"x": { "signal": "width/2" },
"y": { "signal": "height/2" }
}
}
}
]
}
标记块是一组绘图图元,如文本、线条和矩形。对于每个标记,编码集中都指定了大量参数。在“update”阶段,每个参数被设置为常数(值)或计算结果(信号)。 对于文本标记,我们指定文本字符串,确保文本相对于给定坐标正确定位,旋转,并设置文本颜色。x 和 y 坐标是根据图形的宽度和高度计算的,将文本放在中间。 还有许多其他文本标记参数。还有一个交互式文本标记演示图来尝试不同的参数值。
$schema 只是所需 Vega 引擎版本的 ID。Background 可以使图形不透明。width 和 height 设置初始绘图画布大小。根据内容和 自动调整大小选项 ,最终图形大小在某些情况下可能会发生变化。请注意,Kibana 的默认 autosize 是 fit 而不是 pad,因此 height 和 width 是可选的。 padding 参数除了宽度和高度之外,还在图形周围增加了一些空间。
数据驱动图
我们的下一步是使用 矩形标记绘制一个数据驱动的图表。 数据部分允许多个数据源,可以是硬编码的,也可以是网址。在 Kibana,您也可以使用直接 Elasticsearch 查询。我们的 vals 数据表有 4 行 2 列 - category 和 count。 我们使用 category 将操纵条定位在 x 轴上,并 count 操纵条的高度。 请注意,y 坐标的 0 位于顶部,并向下增加。
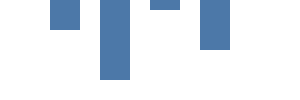
{
"$schema":"https://vega.github.io/schema/vega/v3.json",
"width":300, "height":100,
"data": [ {
"name": "vals",
"values": [
{"category":50, "count":30},
{"category":100, "count":80},
{"category":150, "count":10},
{"category":200, "count":50}
]
} ],
"marks": [ {
"type": "rect",
"from": { "data": "vals" },
"encode": {
"update": {
"x": {"field": "category"},
"width": {"value":30},
"y": {"field": "count"},
"y2": {"value":0}
}
}
} ]
}
rect 标记指定 vals 为数据源。每个源数据值(也称为表格行或数据 )绘制一次标记。与前面的图表不同,x 与 y 参数不是硬编码的,而是来自数据字段。
扩展
扩展 是 Vega 最重要的概念之一,但有些棘手。在前面的例子中,屏幕像素坐标被硬编码在数据中。虽然它让事情变得更简单,但真正的数据几乎从来没有以这种形式出现过。相反,源数据以其自己的单位(例如事件数量)来提供,并且要由图表将源值扩展到所需的以像素为单位的图表大小。
在这个例子中,我们使用 线性扩展 - 本质上是一个数学函数来转换来自 domain 源数据(在这个图中 count 值为1000..8000,包括 count=0)到期望的 范围(在我们这个例子中,图表高度是 0..99)。 在 y 和 y2 参数中添加 "scale": "yscale" 使用 yscale 定标器将 count 转换为屏幕坐标( 0 变为 99,而 8000 - 源数据中最大的值 - 变为 0 )。 请注意, height 范围参数是一种特殊情况,翻转该值使 0 出现在图表底部。
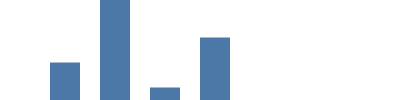
{
"$schema":"https://vega.github.io/schema/vega/v3.json",
"width":400, "height":100,
"data": [ {
"name": "vals",
"values": [
{"category":50, "count":3000},
{"category":100, "count":8000},
{"category":150, "count":1000},
{"category":200, "count":5000}
]
} ],
"scales": [
{
"name": "yscale",
"type": "linear",
"zero": true,
"domain": {"data": "vals", "field": "count"},
"range": "height"
}
],
"marks": [ {
"type": "rect",
"from": { "data": "vals" },
"encode": {
"update": {
"x": {"field": "category"},
"width": {"value":30},
"y": {"scale": "yscale", "field": "count"},
"y2": {"scale": "yscale", "value":0}
}
}
} ]
}
带扩展
在我们的教程中,我们将需要另外一种 15 + Vega 扩展类型 - 一种带扩展类型。当我们有一组值(如类别)需要用带表示时,使用这扩展,每一个都占据图形总宽度的相同比例宽度。在这里,带扩展给 4 个独特类别中的每一个提供了相同的比例宽度(大约 400/4,减去带状之间和两端的 5% 填充)。 {"scale": "xscale", "band":1} 获取标记的 width 参数的 100% 带宽。
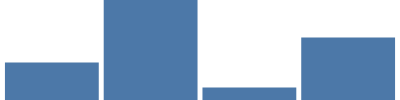
{
"$schema":"https://vega.github.io/schema/vega/v3.json",
"width":400, "height":100,
"data": [ {
"name": "vals",
"values": [
{"category":"Oranges", "count":3000},
{"category":"Pears", "count":8000},
{"category":"Apples", "count":1000},
{"category":"Peaches", "count":5000}
]
} ],
"scales": [
{
"name": "yscale",
"type": "linear",
"zero": true,
"domain": {"data": "vals", "field": "count"},
"range": "height"
},
{
"name": "xscale",
"type": "band",
"domain": {"data": "vals", "field": "category"},
"range": "width",
"padding":0.05
}
],
"marks": [ {
"type": "rect",
"from": { "data": "vals" },
"encode": {
"update": {
"x": {"scale": "xscale", "field": "category"},
"width": {"scale": "xscale", "band":1},
"y": {"scale": "yscale", "field": "count"},
"y2": {"scale": "yscale", "value":0}
}
}
} ]
}
轴
没有轴标签,典型的图表是不完整的。 轴定义 使用了我们之前定义的相同扩展,因此添加它们就像通过其名称引用扩展并指定放置边一样简单。 将此代码作为顶级元素添加到最后一个代码示例中。
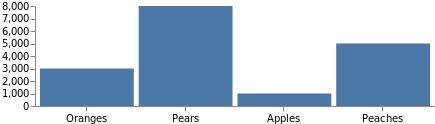
"axes": [
{"scale": "yscale", "orient": "left"},
{"scale": "xscale", "orient": "bottom"}
],
请注意,总图形大小已自动增加,以适应这些轴。 可以通过在规范顶部添加 "autosize": "fit" 来强制图表保持原始大小。
数据转换和条件句
数据在用于绘图之前通常需要额外的操作。Vega 提供了许多 变换 来帮助实现这一点。让我们使用最常见的 公式转换 来动态地向每个源基准添加随机的 count 值字段。此外,在该图中,我们将操纵条的填充颜色,如果值小于 333,则使其为红色,如果值小于 666,则为黄色,如果值大于 666,则为绿色。请注意,这可以通过扩展来实现,将源数据的域映射到颜色集或 配色方案。
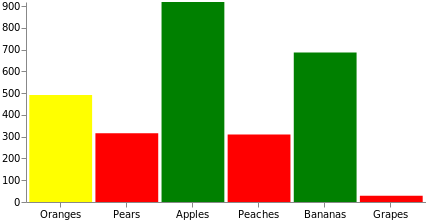
{
"$schema":"https://vega.github.io/schema/vega/v3.json",
"width":400, "height":200,
"data": [ {
"name": "vals",
"values": [
{"category":"Oranges"},
{"category":"Pears"},
{"category":"Apples"},
{"category":"Peaches"},
{"category":"Bananas"},
{"category":"Grapes"}
],
"transform": [
{"type": "formula", "as": "count", "expr": "random()*1000"}
]
} ],
"scales": [
{
"name": "yscale",
"type": "linear",
"zero": true,
"domain": {"data": "vals", "field": "count"},
"range": "height"
},
{
"name": "xscale",
"type": "band",
"domain": {"data": "vals", "field": "category"},
"range": "width",
"padding":0.05
}
],
"axes": [
{"scale": "yscale", "orient": "left"},
{"scale": "xscale", "orient": "bottom"}
],
"marks": [ {
"type": "rect",
"from": { "data": "vals" },
"encode": {
"update": {
"x": {"scale": "xscale", "field": "category"},
"width": {"scale": "xscale", "band":1},
"y": {"scale": "yscale", "field": "count"},
"y2": {"scale": "yscale", "value":0},
"fill": [
{"test": "datum.count < 333", "value": "red"},
{"test": "datum.count < 666", "value": "yellow"},
{"value": "green"}
]
}
}
} ]
}
Elasticsearch 和 Kibana 中的动态数据
既然您已经学习了基本知识,让我们试着用一些 随机生成的 Elasticsearch 数据创建一个基于时间的折线图。 这与您最初在 Kibana 创建新的 Vega 图时看到的相似,只是我们将使用 Vega 语言代替 Vega 精简版的 Kibana(Vega 的简化高级版本)默认值。
对于本例,我们将使用“values”对数据进行硬编码,而不是使用“url”进行真正的查询。这样,我们可以在不支持 KibanaElasticsearch 查询的 Vega 编辑器中继续测试。 如果您用如下所示的 url 部分替换 values,该图将在 Kibana 内部变得完全动态。
我们的查询使用仪表板用户选择的时间范围和上下文过滤器计算每个时间间隔的文档数量。 更多信息,请参见如何从 Kibana 查询 Elasticsearch。
"url": {
"%context%": true,
"%timefield%": "@timestamp",
"index": "_all",
"body": {
"aggs": {
"time_buckets": {
"date_histogram": {
"field": "@timestamp",
"interval": {"%autointerval%": true},
"extended_bounds": {
"min": {"%timefilter%": "min"},
"max": {"%timefilter%": "max"}
},
"min_doc_count":0
}
}
},
"size":0
}
当我们运行它时,结果将如下所示(为了简洁起见,删除了一些不相关的字段) :
"aggregations": {
"time_buckets": {
"buckets": [
{"key":1528061400000, "doc_count":1},
{"key":1528063200000, "doc_count":45},
{"key":1528065000000, "doc_count":49},
{"key":1528066800000, "doc_count":17},
...
如您所见,我们需要的真实数据在 aggregations.time_buckets.buckets 数组中。我们可以告诉 Vega 只查看数据定义中带有 "format": {"property": "aggregations.time_buckets.buckets"} 数组。
我们的 x 轴不再基于类别,而是基于时间(关键”字段是 Vega 可以直接使用的 UNIX 时间)。因此,我们将 xscale 类型更改为时间,并调整所有字段以使用 key 和 doc_count。我们还需要将标记类型改为 line,并且只包括 x 和 y 参数通道。 瞧,您现在有一个折线图。您可能也有兴趣定制带有 format、labelAngle、tickCount 定义 x 标签 参数。
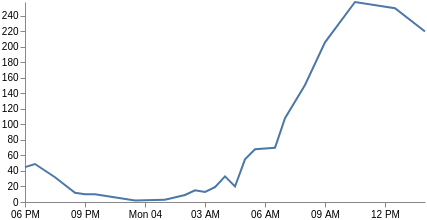
{
"$schema": "https://vega.github.io/schema/vega/v3.json",
"width":400, "height":200,
"data": [
{
"name": "vals",
"values": {
"aggregations": {
"time_buckets": {
"buckets": [
{"key":1528063200000, "doc_count":45},
{"key":1528065000000, "doc_count":49},
{"key":1528068600000, "doc_count":32},
{"key":1528072200000, "doc_count":12},
{"key":1528074000000, "doc_count":10},
{"key":1528075800000, "doc_count":10},
{"key":1528083000000, "doc_count":2},
{"key":1528088400000, "doc_count":3},
{"key":1528092000000, "doc_count":9},
{"key":1528093800000, "doc_count":15},
{"key":1528095600000, "doc_count":13},
{"key":1528097400000, "doc_count":19},
{"key":1528099200000, "doc_count":33},
{"key":1528101000000, "doc_count":20},
{"key":1528102800000, "doc_count":55},
{"key":1528104600000, "doc_count":68},
{"key":1528108200000, "doc_count":70},
{"key":1528110000000, "doc_count":108},
{"key":1528113600000, "doc_count":151},
{"key":1528117200000, "doc_count":206},
{"key":1528122600000, "doc_count":258},
{"key":1528129800000, "doc_count":250},
{"key":1528135200000, "doc_count":220}
]
}
}
},
"format": {"property": "aggregations.time_buckets.buckets"}
}
],
"scales": [
{
"name": "yscale",
"type": "linear",
"zero": true,
"domain": {"data": "vals", "field": "doc_count"},
"range": "height"
},
{
"name": "xscale",
"type": "time",
"domain": {"data": "vals", "field": "key"},
"range": "width"
}
],
"axes": [
{"scale": "yscale", "orient": "left"},
{"scale": "xscale", "orient": "bottom"}
],
"marks": [
{
"type": "line",
"from": {"data": "vals"},
"encode": {
"update": {
"x": {"scale": "xscale", "field": "key"},
"y": {"scale": "yscale", "field": "doc_count"}
}
}
}
]
}
留意我们的博客,继续阅读我们之后会发布关于 Vega 的帖子。 我计划再发表一篇关于处理 Elasticsearch 结果的文章,尤其是聚合和嵌套数据。