



Beats 6.0.0 GA released
Today is a big day for Elastic and the entire community: the Elastic Stack 6.0 is now generally available (GA). In this blog post we’ll highlight the main new features of Beats 6.0.
If you’ve been following the Alpha and Beta blog posts, you know already what’s in, so we won’t stay in your way. Go to the Beats product page to Download Beats Now.
Before upgrading from Beats 5.x, review the Breaking Changes docs and the Upgrade guide. If you are planning to upgrade the whole Elastic stack at once, we also have a guide for that.
Logs and metrics out of Kubernetes and Docker
Filebeat and Metricbeat have gained several processors and modules that make container observability with the Elastic stack a breeze.
You can use the add_docker_metadata and add_kubernetes_metadata processors to enhance application logs and metrics with Docker and Kubernetes metadata. These processors query the Docker and Kubernetes APIs and enhance the events with the container name, image, pod name, labels, and so on. Depending on the Beat, these processors can use different logic to obtain the metadata. For example Filebeat takes the path of the log file, extracts the container ID from it, and uses the ID to retrieve metadata about the container/pod from which the log message originated. See this blog post about how to use Filebeat to collect Docker logs.
Metricbeat gets a new Kubernetes module, which works by interrogating periodically the Kubernetes API. It gives you details about the running container’s pods, including the CPU usage, memory usage, bytes exchanged over the network, and info about the file system. The sample Kibana dashboard provided with the module shows you at a glance the monitoring status of your Kubernetes cluster.
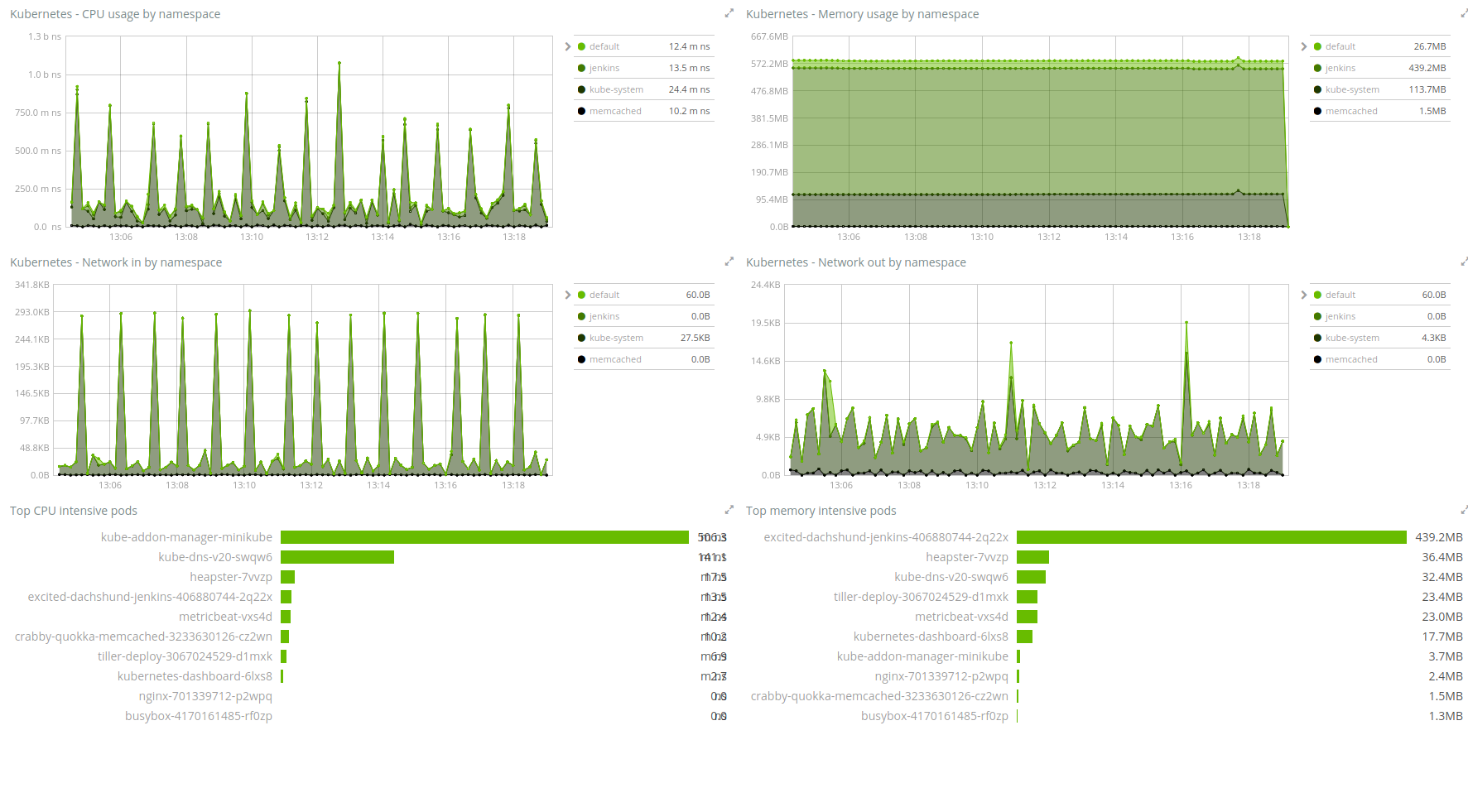
We also provide Kubernetes deployment manifests for Metricbeat and Filebeat. You can find more details about deploying Filebeat and Metricbeat on Kubernetes in the docs, but as a sneak peak, it’s as easy as:
curl -L -O https://raw.githubusercontent.com/elastic/beats/6.0/deploy/kubernetes/filebeat-kubernetes.yaml # edit the YAML file to set the Elasticsearch connection information kubectl create -f filebeat-kubernetes.yaml
The above commands install Filebeat as a DaemonSet, ensuring one agent is running on each Kubernetes node, and configure Filebeat to pick up the logs from /var/lib/docker/containers/, unwrap them from the JSON objects, and automatically enhance them with Kubernetes metadata.
Auditbeat - easy operational security
You can think of Auditbeat as a friendlier version of auditd that is perfectly integrated with the Elastic Stack. It is based on the Linux audit framework, which means it can hook into every system call and capture them on particular conditions. You can use Auditbeat to very efficiently detect things like short-lived connections and processes, unauthorised attempts to open files, privilege escalations, and so on. Auditbeat automatically correlates events together, resolves UIDs ito names, and outputs JSON objects directly to Elasticsearch or Logstash.
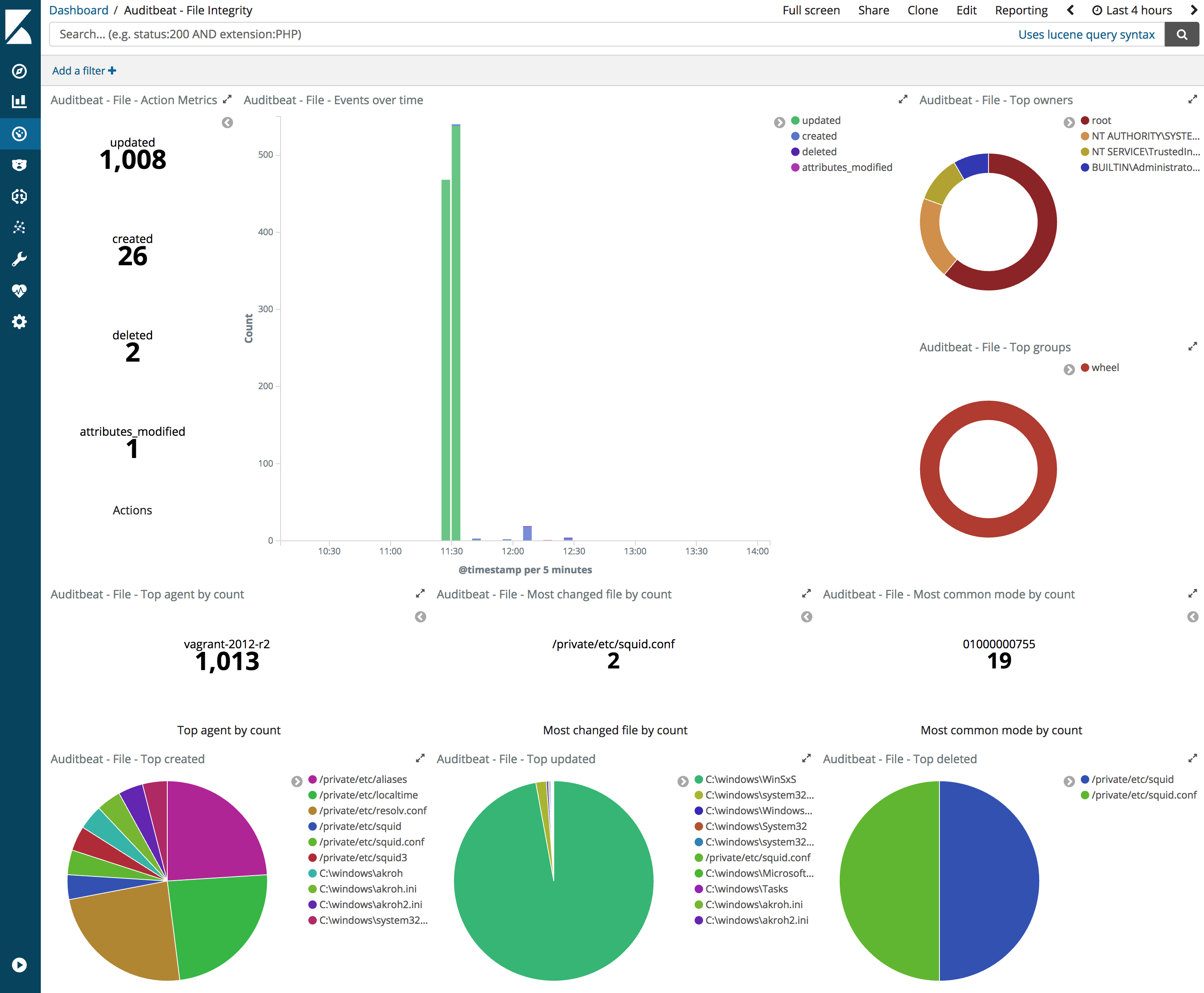
Auditbeat also has a file integrity module. It watches files and directories for changes, and when a file changes it computes the MD5, SHA1, and SHA256 hashes and publishes them to Elasticsearch. The hashes can be compared against known malicious files, as shown in this blog post about detecting WannaCry. This functionality is available on Windows, macOS, and Linux.
New commands and configuration layout
We rethought the way the Metricbeat and Filebeat modules are enabled and configured. Instead of one huge configuration file, we now have a modules.d directory with individual configuration files for each module. The Beats also get commands to list, enable, or disable modules. For example:

$ metricbeat modules list $ metricbeat modules enable redis $ metricbeat modules disable redis
And these are not the only useful new commands. There are also commands to export the configuration, export the Elasticsearch mapping template, do a test fetch for a Metricbeat module, and even test the connectivity with Logstash or Elasticsearch.
More efficient Metricbeat storage
We took a good look at the data that Metricbeat generates and how it is stored into Elasticsearch, and worked our way towards using considerably less storage while still providing the same, or almost the same, value. We have changed the number of default shards to 1 for the Metricbeat indices, because the amount of data typically doesn’t require more. We have added a new feature that captures only the first N processes by memory and CPU time, instead of all processes, which significantly reduces the number of documents created. And we have reduced the polling frequency for the more static metricsets, like the filesystem one.
These changes are complemented nicely by the storage efficiency improvements that went into Elasticsearch 6.0, especially the better support for sparse fields. Together, the improvements add up to 85% less storage used by Metricbeat 6.0 in default configuration compared to Metricbeat 5.5.
Internal pipeline refactoring and better performance
Beats 6.0 also comes with a refreshed internal pipeline architecture. While this change is mostly internal, meant to simplify and improve the Beats overall architecture, it does have some visible effects.
The new pipeline is asynchronous by default, meaning, for example, that while Filebeat is waiting for a network acknowledgement from Logstash/Elasticsearch, it continues to read and process lines from disk. This brings an increase in the maximum throughput.
The Filebeat internal spooler is removed, as its functionality is covered by the new pipeline. This means that tuning Filebeat for performance is easier (only one internal queue size to play with). Be aware that this also implies some breaking changes in the configuration file.
Another effect of the pipeline refactoring is that you can no longer enable two outputs at the same time. In previous versions of the Beats, it was possible to enable simultaneously multiple outputs of different types (e.g. one Logstash and on Elasticsearch), but not multiple outputs of the same type. In a back-pressure sensitive shipper, like Filebeat, having multiple outputs generally means that the slowest output decides the rhythm. This is not ideal and often took our users by surprise. We therefore removed the possibility, which also simplified our internal architecture, and instead we recommend using multiple Filebeat instances or using Logstash as an intermediary with multiple outputs.
Tell me more
Besides the highlights above, Beats 6.0 come with a ton of other small features, improvements, and modules. Please read the full release notes for details.
Thank you and community credits
The 6.0 release was a big undertaking, and it wouldn’t have been possible without the continuous support from our community. We’d like to thank everyone who has contributed code or documentation, but also everyone who has tried out the alpha and beta releases.
We’d like to nominate the following community members in particular:
- Vijay Samuel (@vjsamuel), from eBay, for his constant high quality contributions to Beats over the last two years, especially around the Kubernetes support. You can read more about how eBay is using Beats to monitor their Kubernetes app on their blog.
- Amanda H. L. de Andrade (@amandahla) for the RabbitMQ, Vsphere, and CEPH modules
- Martin Scholz (@martinscholz83) for the Windows module in Metricbeat and other improvements
On behalf of the whole community: Thank you and enjoy 6.0!