Want to get Elastic certified? Find out when the next Elasticsearch Engineer training is running! You can start a free cloud trial or try Elastic on your local machine now.
DocValuesSkippers add block-level skipping to Lucene DocValues, making range queries significantly faster on fields that correlate with document insert order or index sort, without duplicating your data into a block k-dimensional (BKD) tree. The skipper index takes up less than 0.1% of the base DocValues field size, adds minimal overhead at index time, and Lucene applies it automatically at query time when available. If your index has a defined sort, or if your timestamps, counters or numeric fields were written roughly in order, enabling skippers can cut the number of documents your range queries need to touch.
The problem: DocValues are great for reading, not so much for searching
Lucene can store numeric values in two ways: DocValues are column-oriented per-document storage which allow fast lookup of the values for individual documents; a BKD tree is an index structure allowing for efficient range searches. DocValues are used for sorting, faceting, and aggregating, but they’re not as useful for searching, as most queries will end up checking every document in the index. Table scans are slow! So, for fast querying and fast aggregation, you need both of these data structures, essentially storing the same data twice.
In many cases, though, there’s an inherent structure to the index, which means that numeric values in a DocValues field correlate roughly with the internal docid [2]; for example, log entries with a timestamp are likely to be added to an index approximately in order, so documents with a lower docid will also have a lower timestamp. And if an index sort is defined on an index, there will be an exact correlation between field values and docid for fields that are part of the sort. A full BKD index is overkill here; what we really want is a data structure that chunks up the column-based storage into blocks and allows queries to efficiently identify if a block can be excluded from the search. Enter the DocValuesSkipper.
What is a DocValuesSkipper?
A DocValuesSkipper is an optional, hierarchical skip index covering a DocValues field, added to Lucene 10.0 by Ignacio Vera of Elastic. At write time, you can enable a skipper by setting the DocValuesSkipIndexType on a FieldType or by using one of the indexedField sugar methods on XXDocValuesField classes.
The base DocValues field in each index segment [1] is divided into blocks of 4096 documents, with each block recording its min/max docid, the minimum and maximum value found in the block, and the number of documents that it covers (which can be different from maxDoc - minDoc, if some documents have missing values). The hierarchy is then built by merging consecutive intervals, so eight intervals in the base layer are recorded as a single larger interval in layer 1, up to four levels deep. The coarsest level covers approximately 2 million docs per block.
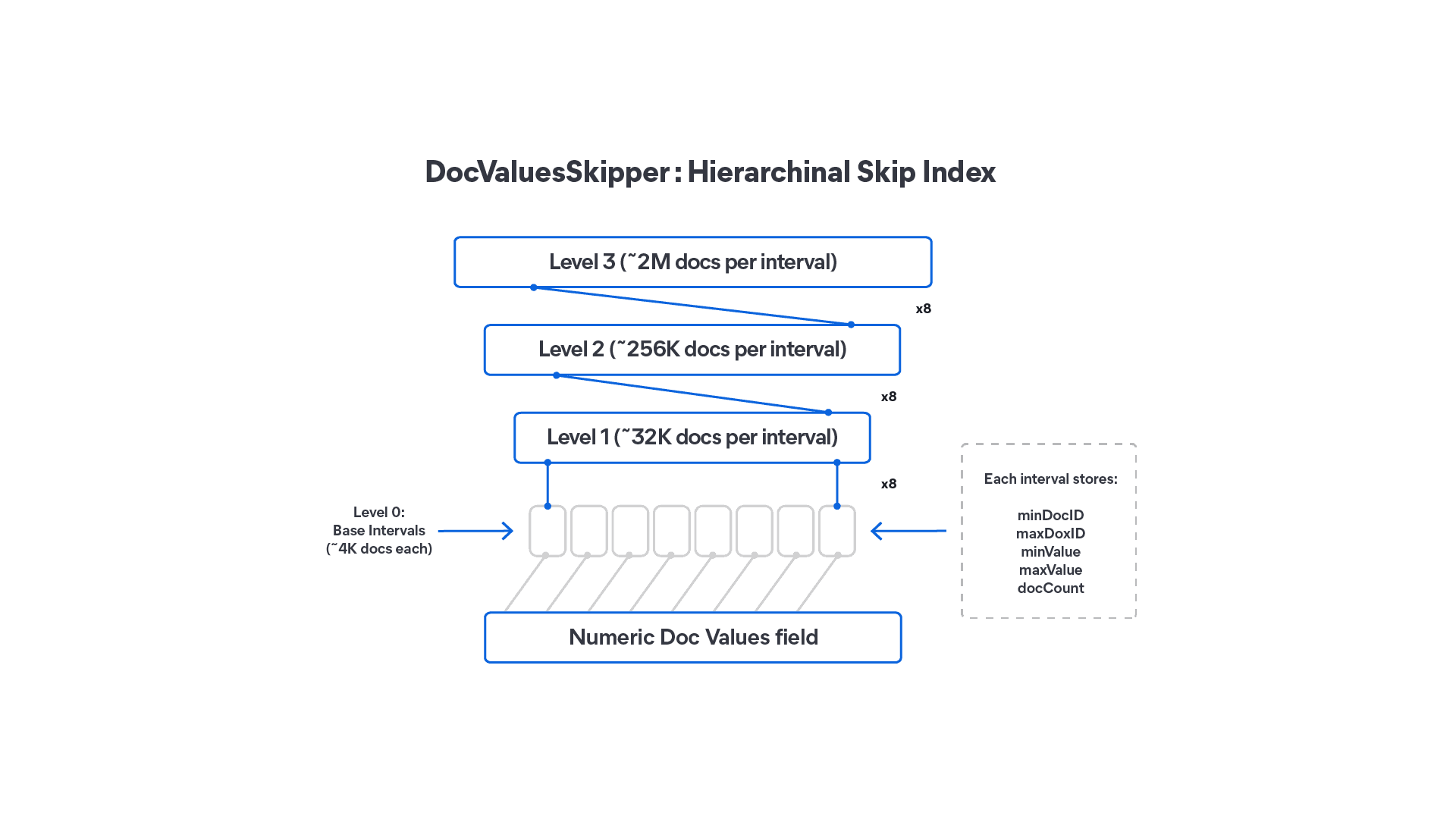
DocValuesSkippers can be enabled for numeric, sorted_numeric, sorted, and sorted_set DocValues types. For the latter two types, the values in the skip index are ordinals [3].
How do DocValuesSkippers accelerate range queries?
Lucene can use skippers under the hood to accelerate a number of query-time operations:
- Range queries can use a skipper-based block iterator to quickly skip over blocks of documents that fall entirely outside the range of interest. They can also use the skipper to build a two-phase iterator that improves performance when the range query is combined with more expensive queries, such as phrase matches.
- Sort pruning can use skippers to exclude blocks from consideration for top-k queries; once enough matching documents have been found to populate the results list, any document with a sort value lower than the bottom document in the list can be skipped.
- MultiTermQueries, such as regex or wildcard, can be rewritten as ordinal range queries, and the skipper then used in the same way as for a numeric range query.
When to use DocValuesSkippers: correlated fields vs. random data
If the skipper field is part of (or correlated with) the index sort, the values in the field will cluster by docid, meaning the skip blocks will have tight min/max bounds and large regions of the document space can be excluded from searches.
Conversely, if the values are randomly distributed across documents, every block will span nearly the full value range and nothing can be skipped, so the skipper index will be pure overhead.
| Field characteristic | Skipper effectiveness |
|---|---|
| Correlated with index sort | High: tight min/max bounds, large skip regions |
| Insert-order correlated (e.g. timestamps) | High: approximate correlation still benefits |
| Randomly distributed values | Low: blocks span full value range, nothing skipped |
| Part of a defined index sort | Highest: exact value-docID correlation |
Skipper indexes take up very little disk space (typically less than 0.1% of the size of the base DocValues field) but do add some overhead at index and merge time, so they’re best used on fields that have some correlation with the index order.
What's next for DocValuesSkippers in Lucene
There are a number of possible future improvements to DocValuesSkippers in the pipeline, both at index time (improving build time, using skipper metadata to streamline merge operations) and for querying or aggregations (better cardinality estimations, adding more metadata to allow fast sum and average calculations). Watch this space!
References
[1] docid: An integer value that Lucene uses internally to identify individual documents in the index.
[2] segment: A Lucene index is divided into a number of immutable index segments, and searches will run over each segment separately (consecutively or concurrently) before combining the results at the end of the process to produce a whole-index result view.
[3] ordinal: Term-based DocValues store information in a dual structure: A terms dictionary contains all the term values for the field, each with an associated ordinal number, and then a column-based numeric DocValues field assigns an ordinal to each document. This means that documents can be compared efficiently as the comparison can use the integer ordinal; the original term can be retrieved by looking up the ordinal in the terms dictionary.
Related Content

June 29, 2026
Bringing it together: How we rebuilt Elasticsearch as a columnar metrics engine; 6.6x less storage, 160x faster queries
Elasticsearch metrics in version 9.4 run on a fully columnar engine: 6.6x less storage, 160x faster queries, native PromQL and OTel support.
The hash() Elasticsearch won't name and the 12 bytes that prove it's Murmur3
Elasticsearch's routing formula uses MurmurHash3, but the docs never say so. This post names the function, walks through the full shard calculation, and shows you how to reproduce it externally.
June 19, 2026
Why your Elasticsearch cluster is hitting disk watermarks: 14 real-world causes explained
Learn how Elasticsearch disk watermarks work, why they trigger, and how to diagnose 14 of the most common scenarios Support encounters, from index bloat to ILM stalls.

June 2, 2026
Elasticsearch reindex now relocates across nodes automatically: zero user intervention, no lost progress
Elasticsearch reindex now survives node shutdowns, uses Point in Time for more efficient source iteration, and ships with dedicated management APIs. Reindex-from-remote is GA in Serverless.

May 20, 2026
Elasticsearch downsampling methods: last-value vs. aggregate sampling
Elasticsearch downsampling now gives you a choice: last-value sampling for maximum storage savings or aggregate sampling for precise rate calculations and counter resets, both fully queryable in ES|QL.