Na versão 7.7: diminua significativamente o uso de memória heap do Elasticsearch
Como os usuários do Elasticsearch estão ampliando os limites de quantos dados podem armazenar em um nó do Elasticsearch, eles às vezes ficam sem memória heap antes de ficar sem espaço em disco. Esse é um problema frustrante para esses usuários, pois costuma ser importante ter o máximo de dados possível em cada nó a fim de reduzir custos.
Mas por que o Elasticsearch precisa de memória heap para armazenar dados? Por que ele não precisa apenas de espaço em disco? Existem alguns motivos, mas o principal é que o Lucene precisa armazenar algumas informações na memória para saber onde procurar no disco. Por exemplo, o índice invertido do Lucene é composto por um dicionário de termos que agrupa os termos em blocos no disco em ordem classificada e um índice de termos para pesquisa rápida no dicionário. Esse índice de termos mapeia os prefixos dos termos com o deslocamento no disco onde começa o bloco contendo os termos com esse prefixo. O dicionário de termos fica no disco, mas o índice de termos ficava no heap até recentemente.
De quanta memória os índices precisam? Normalmente, em torno de alguns MB por GB de índice. Não é muito, mas como estamos vendo os usuários anexarem mais e mais terabytes de disco a seus nós, os índices começam rapidamente a exigir entre 10 e 20 GB de memória heap para armazenar esses terabytes de índices. Dada a recomendação da Elastic de não ultrapassar 30 GB de heap, não sobra muito para outros consumidores de memória heap, como as agregações. Além disso, aumentará a probabilidade de ocorrerem problemas de estabilidade se a JVM não tiver espaço suficiente para as operações de gerenciamento de cluster.
Vejamos alguns números práticos. A Elastic executa benchmarks noturnos em vários conjuntos de dados e controla várias métricas ao longo do tempo, em particular o uso de memória dos segmentos. O conjunto de dados Geonames é interessante porque mostra claramente o impacto de várias mudanças que aconteceram no Elasticsearch 7.x:
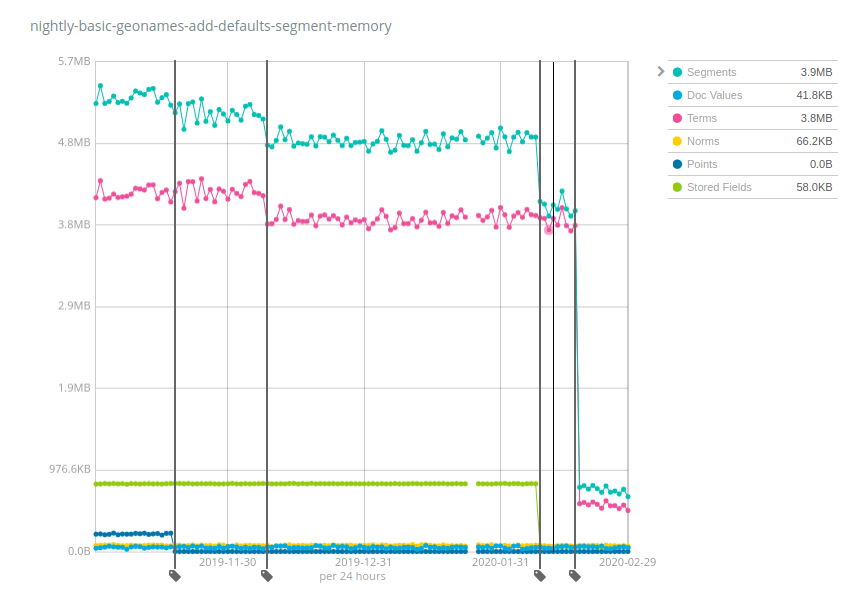
Esse índice ocupa cerca de 3 GB no disco e costumava exigir cerca de 5,2 MB de memória há 6 meses, com uma proporção de heap:armazenamento de cerca de 1:600. Então, se você tivesse um total de 10 TB anexado a cada nó, precisaria de 10 TB/600 = 17 GB de heap, apenas para ser capaz de manter abertos os índices que armazenam dados semelhantes aos nomes geográficos. Mas, como você pode ver, tornamos as coisas melhores com o tempo: os pontos (azul-escuro) começaram a exigir menos memória, depois os termos (rosa), os campos armazenados (verde) e, finalmente, os termos novamente com uma diferença significativa. A proporção de heap:armazenamento agora é de cerca de 1:4.000, uma melhoria de quase 7x em comparação com a versão 6.x e as primeiras versões 7.x. Agora você só precisaria de 2,5 GB de memória heap para manter abertos 10 TB de índices.
Os números variam MUITO entre os conjuntos de dados, e a boa notícia é que o Geonames é um dos conjuntos de dados que apresentou a menor redução do uso de heap: enquanto o uso de heap baixou cerca de 7x no Geonames, ele baixou mais de 100x nos conjuntos de dados NYC taxis (Táxis de NYC) e HTTP Logs (Logs HTTP). Novamente, essa mudança ajudará a reduzir custos, pois muito mais dados são armazenados por nó em comparação com as versões anteriores do Elasticsearch.
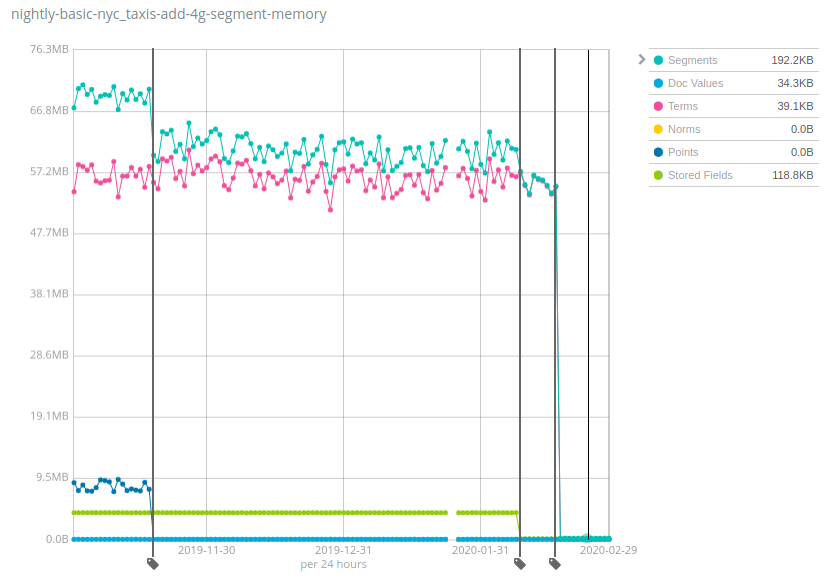
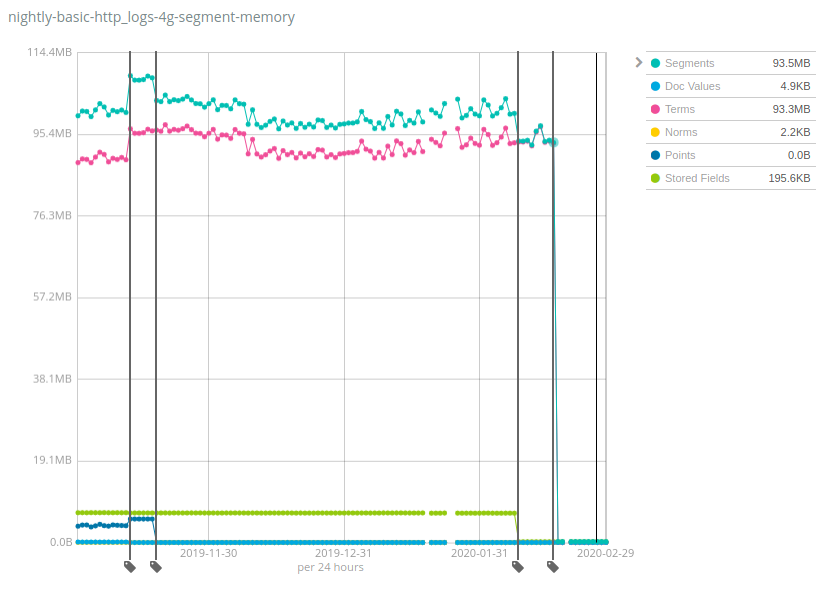
Como isso funciona e quais são as armadilhas? A mesma receita foi aplicada a vários componentes dos índices do Lucene ao longo do tempo: mover estruturas de dados do heap da JVM para o disco e contar com o cache do sistema de arquivos (frequentemente chamado de cache de página ou cache do sistema operacional) para manter os bits ativos na memória. Isso pode significar que essa memória ainda esteja sendo usada e esteja apenas alocada em outro lugar, mas a realidade é que uma parte significativa dessa memória simplesmente nunca foi usada, dependendo do seu caso de uso. Por exemplo, a última queda para Terms foi devida à movimentação do índice de termos do campo _id no disco, o que só é útil ao usar a API GET ou ao indexar documentos com IDs explícitos. A grande maioria dos usuários que indexam logs e métricas no Elasticsearch nunca faz nenhuma dessas operações; portanto, isso será um ganho líquido de recursos para eles.
Reduza o heap do seu Elasticsearch com a versão 7.7!
Estamos muito animados com essas melhorias que estarão disponíveis no Elasticsearch 7.7 e esperamos que você também fique. Fique de olho no anúncio de lançamento que está por vir e faça o teste. Experimente na sua implantação existente ou faça uma avaliação gratuita do Elasticsearch Service no Elastic Cloud (que sempre tem a versão mais recente do Elasticsearch). Estamos ansiosos para receber seu feedback, então diga-nos o que você acha no Discuss.