Machine learning na segurança cibernética: modelos supervisionados de treinamento para detectar atividade de DGA
Não é irritante receber uma ligação de telemarketing de um número de telefone aleatório? E não adianta bloqueá-lo, porque a próxima ligação será feita de um número totalmente novo. Os ciberataques empregam os mesmos truques sujos. Usando algoritmos de geração de domínio (DGA), os criadores de malware mudam a origem de sua infraestrutura de comando e controle, evitando a detecção e frustrando os analistas de segurança que tentam bloquear sua atividade.
Nesta série de duas partes, usaremos o machine learning da Elastic para construir e avaliar um modelo para detectar algoritmos de geração de domínio. Na parte 1:
- Apresentaremos o processo de extração de recursos dos domínios maliciosos e benignos brutos
- Explicaremos um pouco sobre o processo de encontrar recursos adequados
- Mostraremos como treinar e avaliar um modelo de machine learning usando o Elastic Stack
Na parte 2, discutiremos como implantar o modelo treinado em um pipeline de ingestão para enriquecer os dados do Packetbeat no momento da ingestão. Arquivos de configuração e materiais de apoio estarão disponíveis no repositório de exemplos.
Se quiser experimentar em casa, recomendo iniciar uma avaliação gratuita do nosso Elasticsearch Service, na qual você terá acesso completo a todos os nossos recursos de machine learning. OK, vamos lá.
DGA: o que acontece na prática
Depois de infectarem uma máquina-alvo, muitos programas maliciosos tentam contatar um servidor remoto — o chamado servidor de comando e controle (C&C ou C2) — para extrair dados e receber instruções ou atualizações. Isso significa que o binário malicioso precisa saber o endereço IP do servidor de C&C ou o domínio. Se esse endereço IP ou domínio está codificado no binário, as medidas defensivas podem impedir essa comunicação com relativa facilidade adicionando o domínio a uma lista de bloqueio.
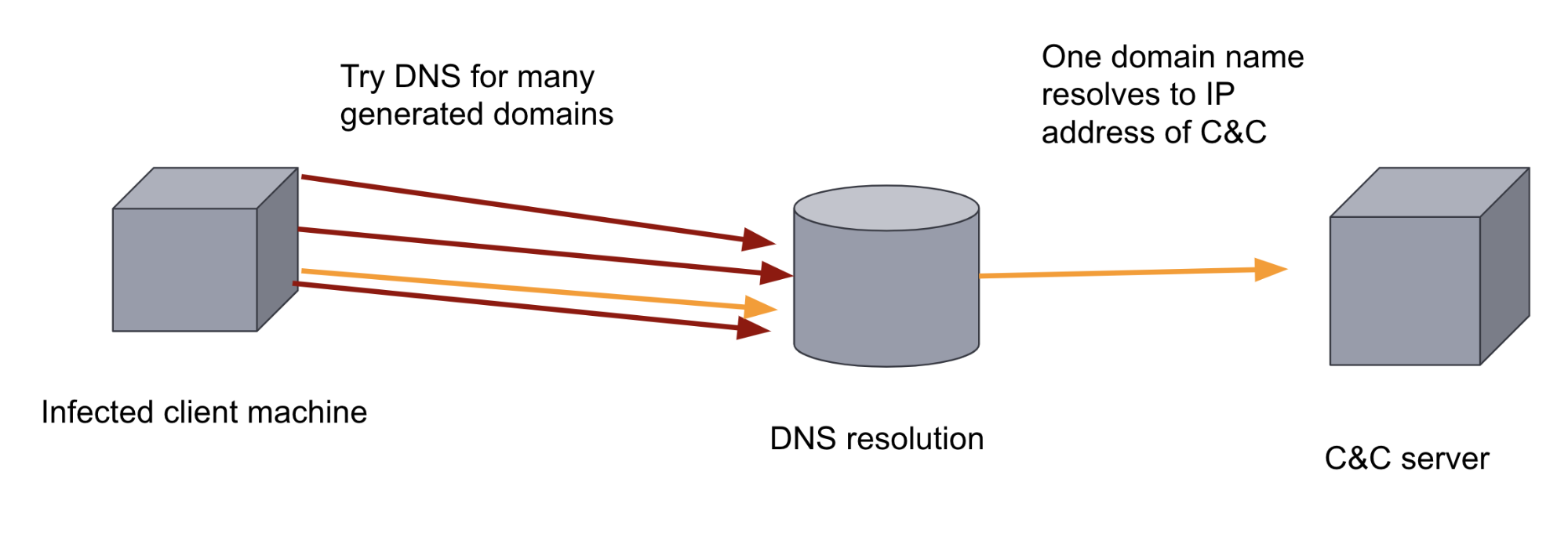
Para subverter essa medida defensiva, os autores do malware podem adicionar um DGA a ele. Os DGAs geram centenas ou milhares de domínios de aparência aleatória. Então, o binário do malware na máquina infectada passa por cada um dos domínios gerados, tentando resolver os nomes de domínio para ver qual dos domínios foi registrado como o servidor de C&C. É difícil para uma abordagem defensiva baseada em regras impedir esse canal de comunicação devido ao grande volume e à aleatoriedade dos domínios. Também é difícil para um analista humano encontrá-lo, já que o tráfego de DNS geralmente tem um volume muito alto. Ambos os fatores fazem com que essa seja uma aplicação ideal para o machine learning.
Treinamento de um modelo de machine learning para classificar domínios
No machine learning supervisionado, fornecemos um conjunto rotulado de dados de treinamento de domínios maliciosos e benignos, permitindo que um modelo aprenda com esse conjunto de dados para que possa então ser usado para classificar domínios anteriormente não vistos como maliciosos ou benignos.
Existem vários tipos diferentes de DGAs, e nem todos têm a mesma aparência. Alguns DGAs produzem domínios de aparência aleatória, outros usam listas de palavras. Para modelos em produção, diferentes recursos e modelos podem ser usados para capturar as características dos diferentes algoritmos. Neste exemplo, treinaremos um único modelo com base nas características encontradas nos algoritmos mais comuns.
Aqui, vamos usar um conjunto de dados composto por domínios de várias famílias de malware e domínios benignos para treinar nosso modelo.

cryptolocker, banjori e suppobox
Engenharia de recursos
A entrada necessária para criar um modelo de machine learning eficaz consiste nos recursos que podem capturar as características dos domínios gerados pelos DGAs. Portanto, temos de dizer ao modelo quais aspectos da string são importantes para distinguir entre domínios maliciosos e benignos. Isso é conhecido como engenharia de recursos no mundo do machine learning.
Compreender os recursos que melhor distinguem os domínios benignos dos maliciosos é um processo iterativo. Por exemplo, começamos com alguns recursos simples, como comprimento de nome de domínio e entropia de nome de domínio, mas os modelos resultantes não eram particularmente precisos em comparação com outros métodos, como o LSTM. Esses modelos tiram proveito das características sequenciais das strings, portanto, examinamos outros recursos que codificariam as sequências de maneira mais eficaz.
Depois de iterar por meio de várias abordagens de engenharia de recursos, concluímos que usar a presença de substrings de vários comprimentos capturaria melhor a diferença entre domínios maliciosos e benignos no modelo.
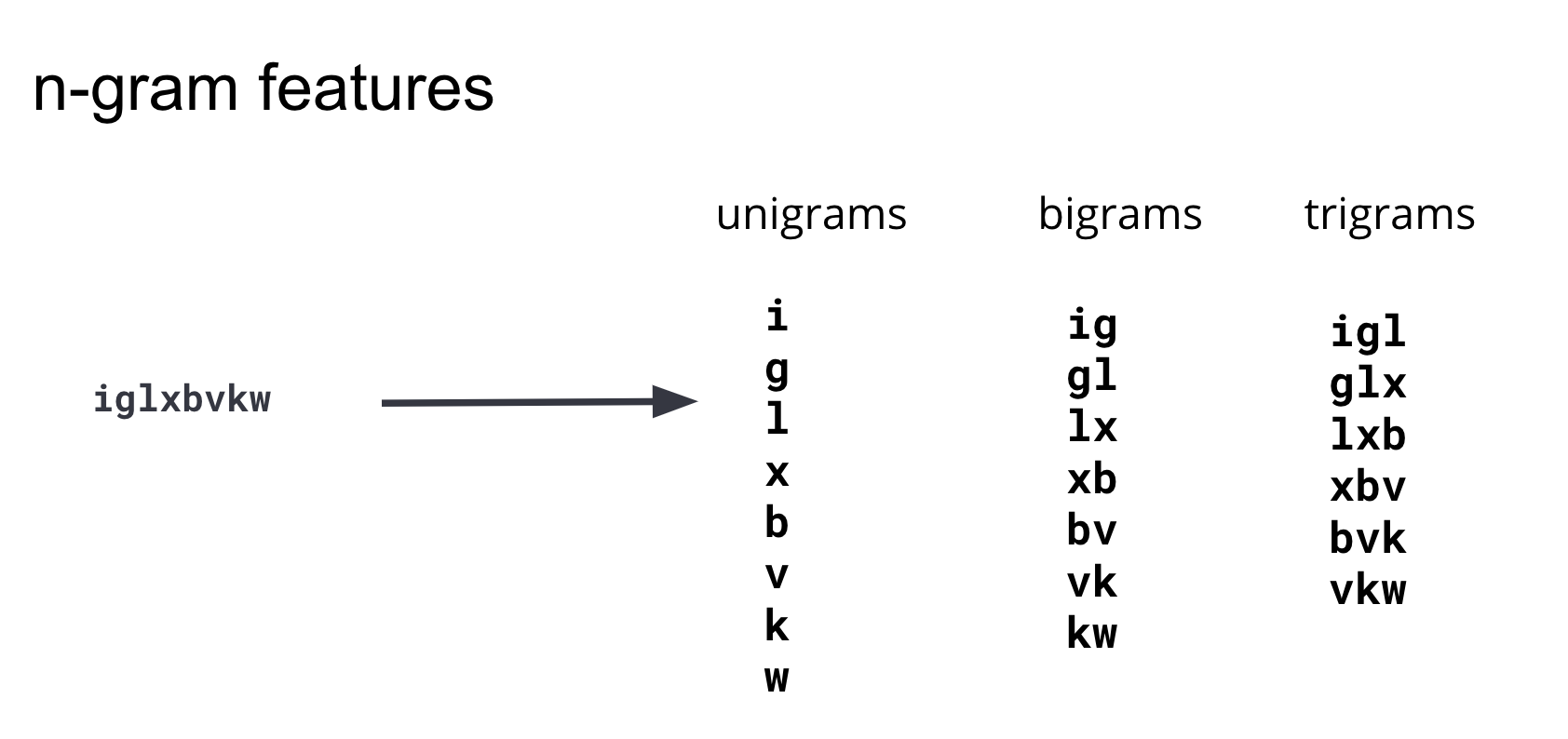
Essas substrings são comumente conhecidas como n-gramas. Ao desenvolver recursos, é importante equilibrar o número de recursos (a dimensionalidade do conjunto de dados de treinamento) e a complexidade de calcular os recursos com seu benefício para o modelo. Após iterar e testar n-gramas de vários comprimentos, concluímos que n-gramas com comprimento 4 ou mais não adicionavam informações preditivas significativas ao modelo, razão pela qual nosso conjunto de recursos é restrito a unigramas, bigramas e trigramas. O diagrama na Figura 3 ilustra como esses recursos são gerados a partir de um domínio de exemplo.
Para gerar um índice do Elasticsearch que tenha cada domínio de DGA dividido em unigramas, bigramas e trigramas, você pode reindexar o índice de origem por meio de um pipeline de ingestão com um processador de script Painless. Um exemplo é mostrado na Figura 4 abaixo. Para obter configurações completas, instruções e várias opções de customização, consulte o repositório de exemplos.
POST _scripts/ngram-extractor-reindex
{
"script": {
"lang": "painless",
"source": """
String nGramAtPosition(String fulldomain, int fieldcount , int n){
String domain = fulldomain.splitOnToken('.')[0];
if (fieldcount+n>=domain.length()){
return ''
}
else
{
return domain.substring(fieldcount, fieldcount+n)
}
}
for (int i=0;i<ctx['domain'].length();i++){
ctx[Integer.toString(params.ngram_count)+'-gram_field'+Integer.toString(i)] = nGramAtPosition(ctx['domain'], i, params.ngram_count)
}
"""
}
}
Normalmente, seria necessário fazer mais pré-processamento para converter as substrings de comprimentos 1, 2 e 3 em vetores numéricos para o algoritmo de machine learning. No nosso caso, o machine learning da Elastic cuidará dessa conversão em valores numéricos, também conhecida como codificação. O machine learning da Elastic também examinará os recursos e selecionará automaticamente aqueles que contiverem mais informações.
Criação de um trabalho de analítica de estruturas de dados
A próxima etapa é usar a UI Data Frame Analytics (Analítica de estruturas de dados) para criar um trabalho de classificação. Eu destaquei alguns aspectos importantes desse processo nas capturas de tela abaixo.
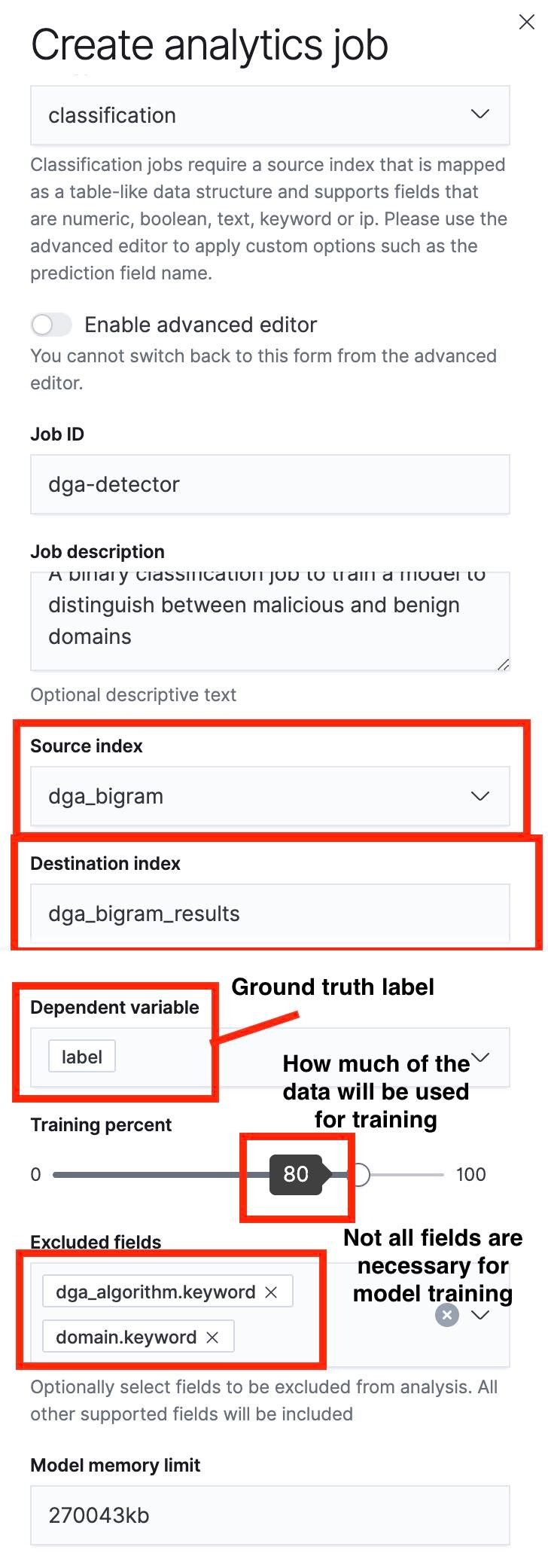
Uma coisa importante a notar é que podemos especificar uma divisão de treinamento/teste usando o controle deslizante. Na captura de tela da Figura 5, a divisão de treinamento/teste é definida como 80%, o que significa que 80% dos documentos no índice de origem serão usados para treinar o modelo, e os 20% restantes serão usados para testar o modelo.
Assim que o processo de treinamento for concluído, poderemos navegar até a UI Data Frame Analytics Results (Resultados da analítica de estruturas de dados) para avaliar o desempenho do modelo. Como dividimos nosso índice de origem em um conjunto de treinamento e um conjunto de teste, poderemos ver o desempenho do modelo em cada um. Embora o desempenho do treinamento e o desempenho do teste forneçam informações valiosas, neste caso, estaremos mais interessados no desempenho do modelo no conjunto de dados de teste, pois isso nos dará uma ideia do erro de generalização em um modelo. Esse erro indica como será o desempenho do modelo em pontos de dados que não encontrou antes.
Avaliação de um modelo de machine learning
Assim que o processo de treinamento for concluído, poderemos clicar em “View” para visualizar os resultados da página de gerenciamento de trabalhos da UI de machine learning da Elastic.
A página de resultados (veja a Figura 6) nos dá duas informações importantes: uma confusion matrix que resume o desempenho do nosso modelo e uma tabela de resultados onde podemos fazer uma busca detalhada para ver como os pontos de dados individuais foram classificados pelo modelo. Podemos alternar entre a confusion matrix e a tabela de resumo para os conjuntos de dados de teste e treinamento usando os filtros Testing (Teste) e Training (Treinamento) no canto superior direito da tabela.
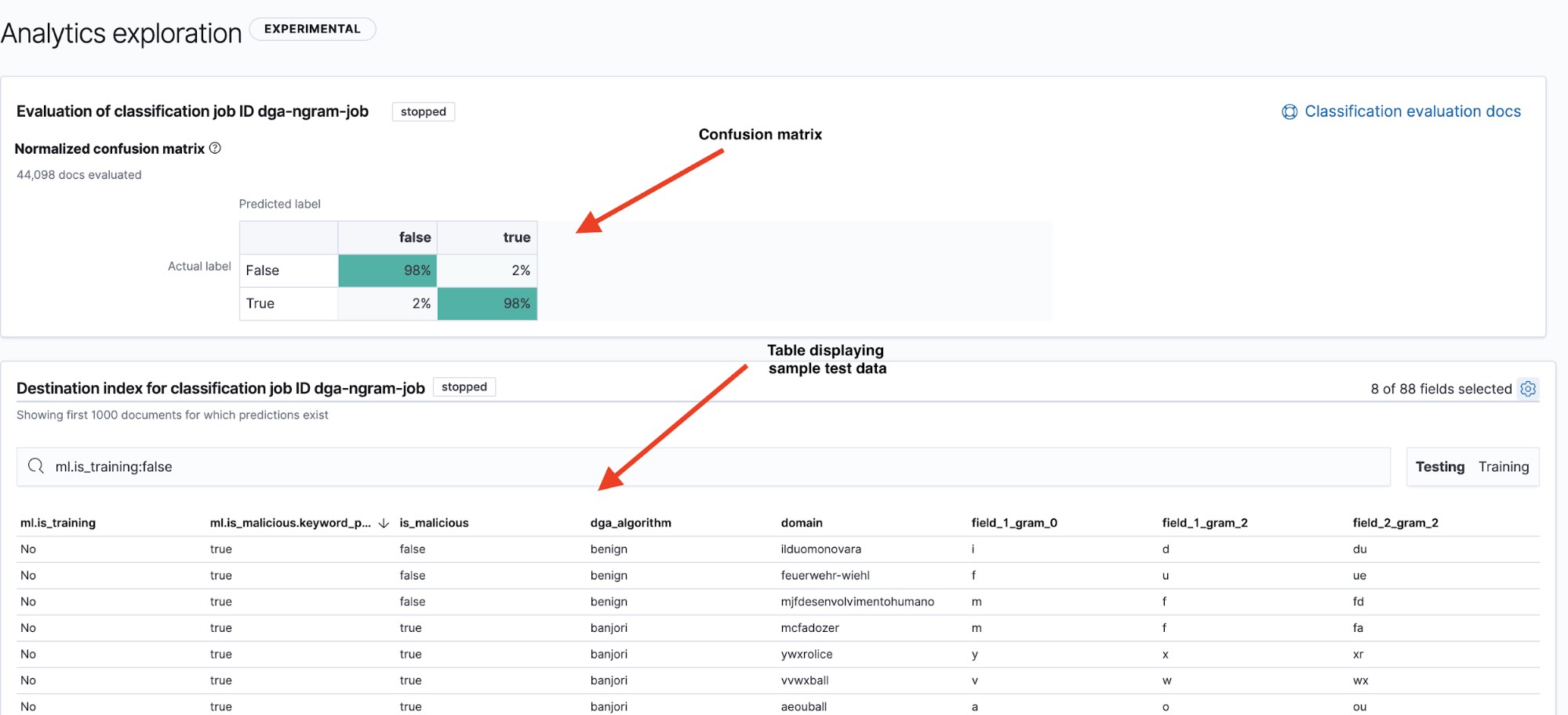
Uma maneira comum de exibir o desempenho de um modelo é com uma visualização conhecida como confusion matrix. A confusion matrix exibe a porcentagem de pontos de dados que foram classificados como true positives (positivos verdadeiros, os domínios maliciosos que o modelo identificou como maliciosos e que realmente eram) e true negatives (negativos verdadeiros, os domínios benignos que o modelo identificou como benignos), bem como a porcentagem de documentos em que o modelo confundiu domínios benignos com maliciosos (false positives ou falsos positivos) ou vice-versa (false negatives ou falsos negativos).
Fiel ao seu nome, a confusion matrix nos mostrará rapidamente se um modelo está confundindo frequentemente instâncias de uma classe com outra.
Na Figura 6, vemos que nosso modelo tem uma taxa de 98% de positivos verdadeiros nos dados de teste. Isso significa que, se implantássemos esse modelo em produção para classificar os dados de DNS recebidos, esperaríamos ver aproximadamente uma taxa de 2% de falsos positivos. Embora pareça ser um número bastante baixo, o alto volume de tráfego de DNS significa que ele ainda levaria a uma taxa de alerta bastante alta. Na parte 2, daremos uma olhada em como a detecção de anomalia pode ser usada para reduzir o número de alertas de falsos positivos.
Conclusão
Neste post do blog, apresentamos uma breve visão geral do uso do machine learning da Elastic para criar e avaliar um modelo de machine learning para detecção de DGA. Examinamos o processo de extração de recursos dos domínios maliciosos e benignos brutos e explicamos um pouco sobre o processo para encontrar recursos adequados. Por fim, vimos como treinar e avaliar um modelo de machine learning usando o Elastic Stack.
Na próxima parte da série, veremos como usar processadores de inferência em pipelines de ingestão para implantar esse modelo a fim de enriquecer os dados de entrada do Packetbeat com previsões de grau de risco do domínio e como usar trabalhos de detecção de anomalia para reduzir o número de alertas de falsos positivos. Enquanto isso, experimente nossos recursos de machine learning gratuitamente para ver que tipo de insights você poderá revelar quando enxergar através do ruído em seus dados.