Um salto de desempenho de 1.000% com o Elasticsearch
A Voxpopme é uma das principais plataformas de insights de vídeo do mundo. A empresa foi criada em 2013 com a ideia de que o vídeo é a forma mais poderosa de dar voz a milhares de pessoas simultaneamente. Nosso software exclusivo usa vídeos criados por consumidores e conteúdos de formatos longos (como grupos de foco) de uma série de parceiros de pesquisa e gera dados de marketing valiosos na forma de gráficos, temas pesquisáveis e pequenos vídeos personalizáveis.
Desde o lançamento, passamos quatro anos otimizando e automatizando o insight que os vídeos podem oferecer para remover as barreiras que dificultam conexões reais entre marcas e clientes. Para melhorar a experiência do cliente, usamos as ferramentas de NLP mais recentes do IBM Watson para identificar e agregar o sentimento dos participantes de pesquisa e temos uma parceria exclusiva com a Affectiva para analisar emoções faciais. Em 2017, incluímos o Elasticsearch em nosso arsenal de ferramentas para oferecer a melhor experiência possível para nossos clientes.
Aumentando a antiga infraestrutura
Na Voxpopme, nosso stack de tecnologia passou por uma série de mudanças nos últimos 12 meses. Em 2017, a nossa plataforma processou meio milhão de pesquisas em vídeo (o mesmo que os 4 anos anteriores juntos) e dobramos esse valor em 2018. Tivemos problemas de tamanho, o que é um problema ótimo, mas ainda é um problema.
Eles aconteceram por causa do nosso sistema antigo, que era composto de um aplicativo PHP monolítico que interagia com uma série de bancos de dados para as funções centrais. A lógica por trás dessa separação original de dados era simples:
- A maioria dos nossos dados estava armazenada em um banco de dados MySQL. Esses usuários, respostas de vídeo individuais, etc, estruturavam dados relacionais que se uniam com chaves de fora e seriam criados, lidos, atualizados e excluídos com um API RESTful.
- Os dados de cliente eram armazenados em um cluster MongoDB, que aceitávamos da forma como vinham. Com isso, os usuários poderiam colocar tags, anotar e filtrar os vídeos usando sua própria terminologia.
- Armazenamos as transcrições dos vídeos dos participantes das pesquisas em um pequeno cluster Elasticsearch, que usamos para pesquisas de texto completo.
Durante muito tempo, essa abordagem funcionou bem, mas havia um problema óbvio.
O poder computacional não é grátis nem infinito.
Uma busca em nossa plataforma pode ser muito simples ou muito complexa. Nas instâncias mais simples, permitimos que os usuários busquem a chave principal de uma resposta em vídeo. Isso é fácil e envolve somente uma consulta simples para o banco de dados indexado MySQL.
Mas e as consultas que um usuário pode querer filtrar com uma integral indexada, algum dado próprio sem formulário ou restringir os resultados a todos os participantes que mencionem um determinado assunto? Por exemplo:
Encontre todos os registros em que a data de resposta esteja entre o primeiro e o último dia de junho, cujo participante tenha uma renda familiar entre US$ 100 mil e US$ 125 mil e que tenham mencionado a expressão “muito caro”.
Esta foi a nossa abordagem:
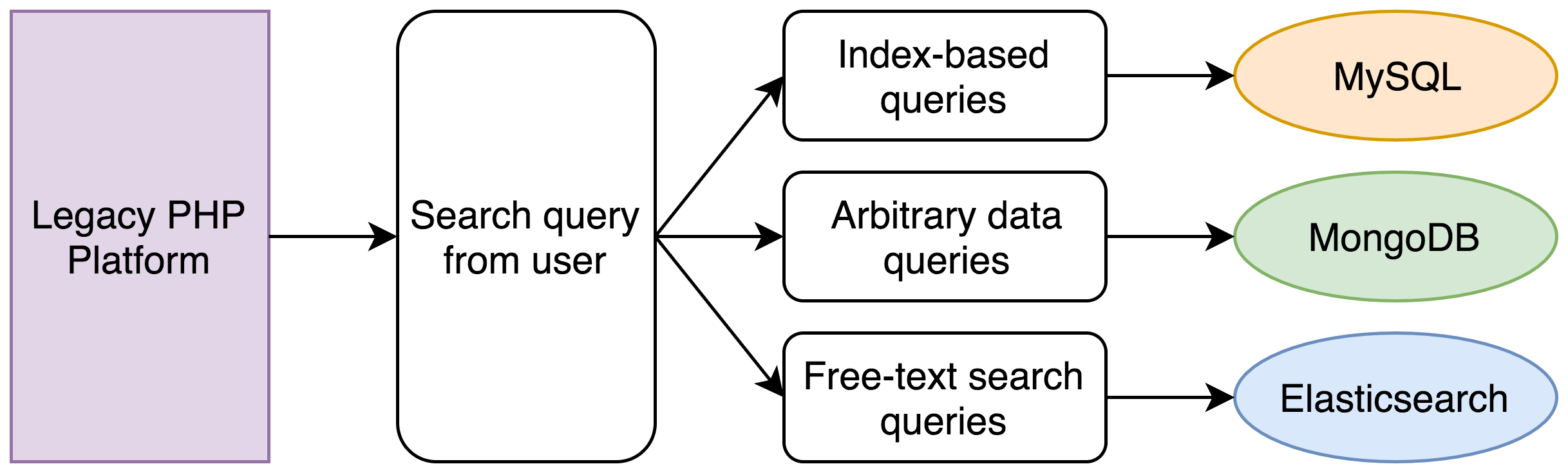
Em nosso sistema antigo, teria acontecido o seguinte:
- Uma consulta MySQL teria encontrado todos os registros dentro da faixa de data.
- Uma consulta MongoDB encontraria todos os registros dentro da faixa de renda (renda é só um exemplo, poderia ser uma série de informações).
- Uma consulta Elasticsearch encontraria todos os registros com uma frase específica.
- Uma interseção de IDs desses três conjuntos de registros seria calculada.
- Um novo conjunto de consultas MySQL e MongoDB seria executado para obter o conjunto de dados completos para cada registro.
- Os registros seriam ordenados e paginados.
Um conjunto simples de critérios de busca envolveria facilmente cinco consultas separadas. Originalmente, isso seria uma operação de menos de um segundo, mas cinco anos de dados e o fato de o PHP ser single-threaded significam que as consultas ao banco de dados teriam que ser feitas uma após a outra, o que poderia levar 30 segundos no total.
Esse modelo nos levou ao mercado rapidamente e nos serviu por muitos anos, mas não funcionaria se a gente crescesse. Quando percebemos que a experiência de nossos usuários começou a se complicar, decidimos que era hora de reescrever o mecanismo de busca.
Já tínhamos alguma experiência com o Elasticsearch com nosso stack existente, por isso fomos falar com um gerente de vendas da Elastic para discutir os problemas que enfrentávamos na hora de realizar buscas complexas em uma série de dados espalhados por diversos locais. Encontrar a solução correta era muito importante. Nosso produto existe para exibir e fazer cálculos rápidos e eficientes em nossos dados, ter gargalos na hora de obter os dados seria inaceitável.
Também consideramos ampliar nosso cluster MongoDB existente, mas depois de uma pequena reunião por telefone com a Elastic, a equipe de desenvolvimento decidiu que a única solução que nos permitiria armazenar, pesquisar e manipular dados (agregações) era o Elasticsearch.
Nossas primeiras impressões
O cluster Elasticsearch que estávamos usando para busca de texto era uma versão 1.5 do Compose.io. Como já investimos muito no AWS para o resto de nossa infraestrutura, optamos inicialmente pelo Amazon Elasticsearch Service com um cluster versão 5.x.
Nosso novo modelo envolvia reunir todos os dados díspares de um registro dentro de um único documento no Elasticsearch usando valores aninhados com chaves conhecidas para os dados mais complicados de nossos clientes. E assim qualquer busca de usuário poderia ser resolvida com uma consulta Elasticsearch única.
Em uma semana, tivemos uma prova de conceito básica carregada em algumas centenas de documentos, e nossas primeiras impressões das consultas executadas no Kibana foram tão boas que foi um prazer seguir adiante com uma reescrita completa de nosso mecanismo de busca de backend.
Esta foi a nova abordagem:
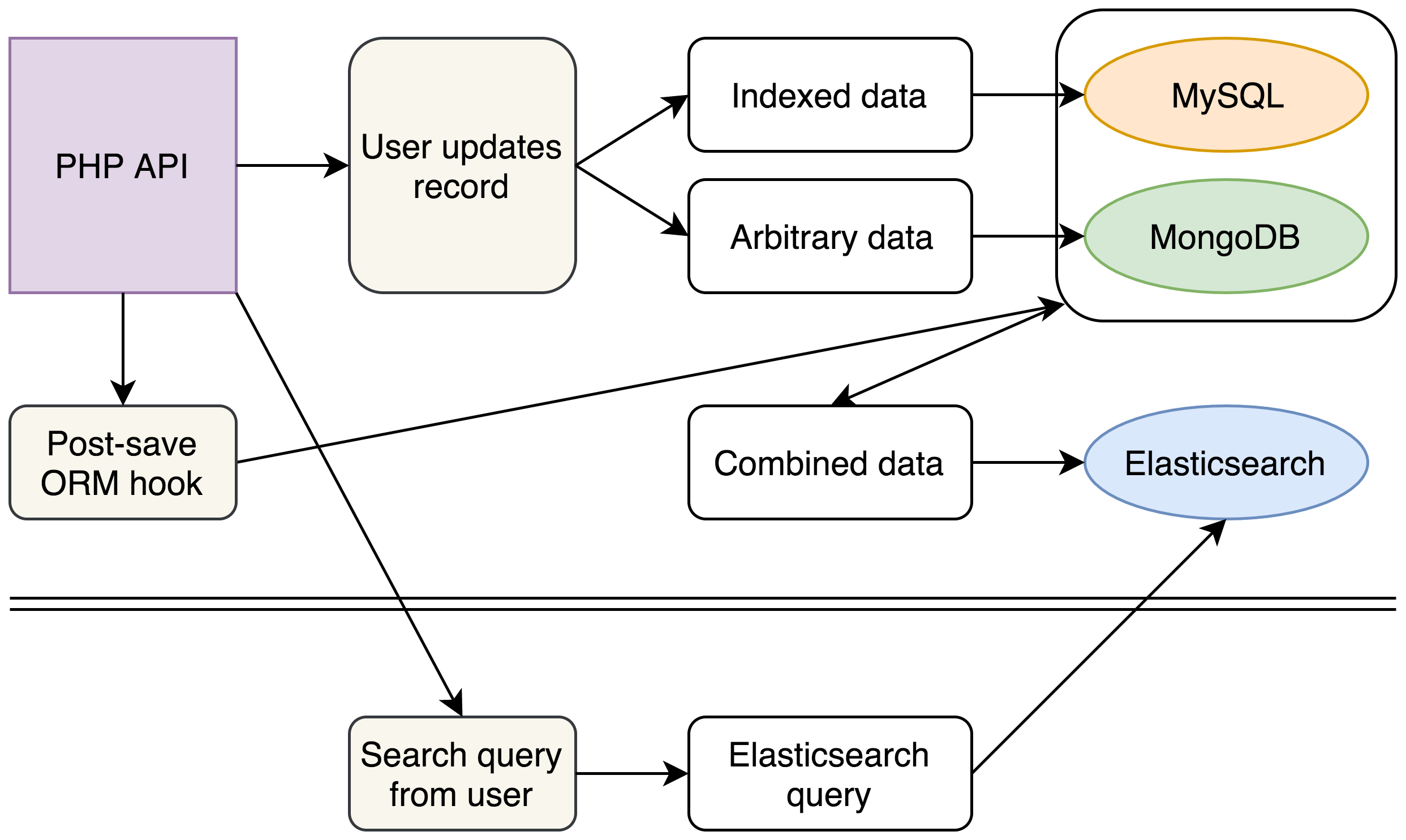
(Por enquanto, nossos bancos de dados antigos permaneceram inalterados, mas, com a introdução de nosso novo cluster Elasticsearch para buscas complexas, conseguimos fazer planos para remover completamente o MongoDB do nosso stack.)
Com o novo stack, continuamos a escrever para MySQL e MongoDB como antes. No entanto, cada escrito deflagraria um evento que reuniria e normalizaria todos os dados de diversas fontes em um único documento JSON inserido no Elasticsearch.
No backend, escrevemos um novo mecanismo de busca que construía consultas Elasticsearch complexas a partir das solicitações de busca existentes de nossos usuários e removia completamente o código antigo que consultava MySQL e MongoDB. Consultar um único cluster Elasticsearch permitiu que obtivéssemos os mesmos dados em uma fração do tempo.
A também tivemos outros ganhos com a estrutura de nossos documentos Elasticsearch. Nossa API retorna documentos JSON e, por isso, conseguimos estruturar nossos documentos Elasticsearch para corresponderem exatamente à nossa saída de API existente, economizando segundos que antes eram gastos combinando e reestruturando os dados que saíam do MySQL e MongoDB.
Conseguimos mostrar um aumento de desempenho de 1.000% nos aspectos mais importantes da plataforma para as partes interessadas.
Não é esse o prestador que você quer
Depois de prometer uma melhora de 1.000% para todos, a próxima etapa era indexar os nossos dados e esperar que o número não sucumbisse à pressão.
Com todos os nossos dados indexados, o cluster AWS, infelizmente, não funcionou bem.
Se fosse só uma questão de indexar os dados uma vez e fazer a consulta diversas vezes, talvez não houvesse problema. Mas nosso modelo precisava combinar e reindexar os dados sempre que eles eram atualizados em MySQL ou MongoDB. E isso poderia acontecer milhares de vezes durante o período em que era mais provável de acontecerem as buscas.
Descobrimos que o desempenho sofreu mudanças e o tempo de consulta caiu para segundos. E isso tinha o efeito adverso de poder travar nosso aplicativo PHP, o que poderia manter nossas conexões MySQL abertas e, em um efeito dominó terrível, tornar todo o nosso stack não responsivo.
Estávamos com esses problemas no momento em que o Elastic{ON} chegou a Londres, então aproveitamos a oportunidade para falar com um representante da Elastic no estande AMA (Ask Me Anything) sobre tamanhos de clusters e os problemas que enfrentamos. Falamos que nossas buscas mais rápidas aconteciam em cerca de 40 ms e soubemos que com o Elastic Cloud, em vez do AWS, conseguiríamos tempos de resposta próximos de 1 ms na configuração padrão.
A disponibilidade do X-Pack no Elastic Cloud foi uma grande vantagem para nós já que só tínhamos registros e sistemas de gráficos limitados na época. Como não existe o X-Pack na oferta do Elasticsearch no AWS, decidimos melhorar um cluster Elastic Cloud para fazer alguns testes simultâneos. Se o desempenho dele fosse pelo menos tão bom quanto o cluster AWS, sabíamos que íamos mudar somente pelos outros benefícios.
A interface do usuário do Elastic Cloud era clean e fácil de usar. Durante a indexação, precisamos ampliar a operação e adicionamos mais profissionais para processar os dados e ficamos impressionados com como foi fácil gerenciar o cluster: só mover uma barra para a esquerda ou direita e clicar em “Update”.
Depois que nossos dados estavam indexados no novo cluster, conseguimos executar consultas complexas em 2ms quase sem travamentos (e desde então já otimizamos tudo para eliminar o problema de travamento como um todo). É claro que alguns milissegundos aqui e ali não são perceptíveis para o usuário final, mas para os profissionais de tecnologia foi um prazer ver que a latência diminuiu 5% comparada ao nível anterior.
Aproveitar ao máximo os dados
Mas não quisemos ser conservadores e usar o Elasticsearch somente como um mecanismo de busca voltado para o usuário. Muitos dos casos de sucesso que ouvimos a respeito da tecnologia estavam focados em registros e descobrimos que, com a gente, não seria diferente.
Definimos um cluster de registro separado para inserir os registros de nossos pods dos Kubernetes e agora temos mais visibilidade sobre a saúde dos nossos servidores, algo que simplesmente não estava disponível para nós antes. E, com isso, reagimos mais rápido a qualquer problema.
Também conseguimos oferecer algo similar aos usuários de nossa plataforma. Ao usar agregações, conseguimos oferecer aos usuários uma forma gráfica de visualizar os próprios dados. Só isso já foi uma grande adição à nossa plataforma e foi simplesmente um bom efeito colateral de ter nossos dados no Elasticsearch.
Ao longo dos últimos meses, aprimoramos e refinamos nossos processos e o resultado é uma grande melhoria do desempenho de nossos clusters Elasticsearch a cada semana. Essa melhoria de desempenho incluiu grandes ganhos de memória ao mover campos que exigiam fielddata de nosso cluster principal para um cluster menor que é acessado com menos frequência (nossa pressão de memória de base passou de 75% para 25%). Também otimizamos nosso código para escrever novos dados em lote, em vez de somente sob demanda, o que tornou o cluster bem mais responsivo durante horários de pico.
Pensando no futuro. temos planos de utilizar bastante o Elasticsearch para analisar os dados internos da empresa. O Elasticsearch já provou ser uma parte crucial de nosso produto para o cliente, mas já começamos a fazer experiências com nossos próprios dados no Elasticsearch e pretendemos usar o Elastic Stack para obter insights sobre nossas eficiências operacionais como empresa.
 David Maidment é Engenheiro de Software Sênior da Voxpopme e é especialista em preparar o código-base da plataforma para o futuro enquanto a empresa cresce exponencialmente.
David Maidment é Engenheiro de Software Sênior da Voxpopme e é especialista em preparar o código-base da plataforma para o futuro enquanto a empresa cresce exponencialmente.
 Andy Barraclough é cofundador e CTO da Voxpopme e tem como foco gerenciar a equipe técnica e coordenar a visão de longo prazo da empresa.
Andy Barraclough é cofundador e CTO da Voxpopme e tem como foco gerenciar a equipe técnica e coordenar a visão de longo prazo da empresa.