Implementação de uma arquitetura hot-warm-cold com gestão de ciclo de vida de índices
OBSERVAÇÃO: não é mais recomendado implementar arquiteturas hot-warm-cold com atributos de nó conforme descrito neste documento (ou seja, -Enode.attr.data=hot). As #camadas de dados formalizaram esse conceito por meio do uso de node.roles (ou seja, node.roles: ["data_hot", "data_content"]). Consulte informações atualizadas em https://www.elastic.co/blog/elasticsearch-data-lifecycle-management-with-data-tiers.
Se você já implementou uma arquitetura hot-warm-cold com atributos de nó, é recomendável adotar o node.roles para camadas de dados e depois usar a API de migração para camadas de dados ou converter a configuração manualmente (ou seja, políticas de ILM, configurações de índice, modelos de índice) para usar as preferências de camada de dados.
Além disso, este documento faz referências a modelos de índice legados (ou seja, PUT _template) e à necessidade de inicializar um índice. Os modelos de índice legados foram substituídos por modelos de índice combináveis (ou seja, PUT /_index_template) e, se você usar fluxos de dados, não haverá necessidade de inicializar o índice.
A Index lifecycle management (ILM) é um recurso que foi introduzido pela primeira vez no Elasticsearch 6.6 (beta) e disponibilizado de forma geral na versão 6.7. O ILM faz parte do Elasticsearch e foi desenvolvido para ajudar na gestão dos seus índices.
Neste blog, exploraremos como implementar uma arquitetura hot-warm-cold usando o ILM. As arquiteturas hot-warm-cold são comuns para dados de série temporal, como logging ou metrics. Por exemplo, suponha que o Elasticsearch esteja sendo usado para agregar arquivos de log de vários sistemas. Os logs de hoje estão sendo indexados ativamente, e os logs desta semana são os mais pesquisados (hot). Os logs da semana passada podem ser pesquisados, mas não tanto quanto os da semana atual (warm). Os logs do mês passado podem ou não ser pesquisados com frequência, mas é aconselhável mantê-los por perto por via das dúvidas (cold).
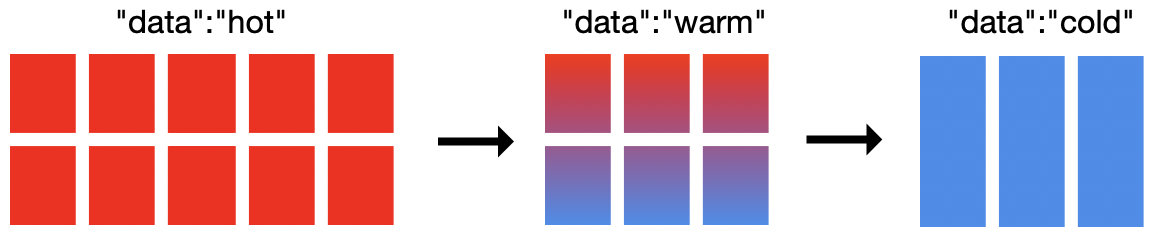
Na ilustração acima, existem 19 nós no cluster: dez nós hot, seis nós warm e três nós cold. * Você não precisa de 19 nós para implementar uma arquitetura hot-warm-cold com o ILM, mas precisará de pelo menos dois. How to size your cluster vai depender dos seus requisitos.* Os nós cold são opcionais e simplesmente fornecem um nível a mais para modelar onde colocar seus dados. O Elasticsearch permite definir quais nós são hot, warm ou cold. O ILM permite definir quando mudar de uma fase para a outra e o que fazer com o índice ao entrar nessa fase.
Não existe uma solução válida para todos os cenários para arquiteturas hot-warm-cold. No entanto, em geral, queremos mais recursos de CPU e E/S mais rápidas para os nós hot. Nós warm e cold geralmente exigem mais espaço em disco por nó, mas também podem se contentar com menos CPU e admitem E/S mais lentas.
OK, então vamos começar...
Configuração do reconhecimento da alocação de shard
A arquitetura hot-warm-cold se baseia no shard allocation awarness; portanto, começamos identificando quais nós são hot, warm e (opcionalmente) cold. Isso pode ser feito por meio de parâmetros de inicialização ou no arquivo de configuração elasticsearch.yml. Por exemplo:
bin/elasticsearch -Enode.attr.data=hot
bin/elasticsearch -Enode.attr.data=warm
bin/elasticsearch -Enode.attr.data=cold
Se você estiver usando o Elasticsearch Service no Elastic Cloud, será necessário escolher o modelo hot/warm com o Elasticsearch 6.7+.
Configuração de uma política de ILM
Em seguida, precisamos definir uma política de ILM. Uma política de ILM pode ser reutilizada em quantos índices você escolher. Ela se divide em quatro fases principais: hot, warm, cold e exclusão. Você não precisa definir todas as fases de uma política, e o ILM sempre executará as fases nessa ordem (ignorando as não definidas). Você definirá quando entrar em cada fase e um conjunto de ações para gerenciar seus índices como achar melhor. Para arquiteturas hot-warm-cold, a ação allocate é o que você pode configurar para mover seus dados de nós hot para nós warm e de nós warm para nós cold.
Além de mover os dados entre os nós hot, warm e cold, existem muitas actions adicionais que você pode configurar. A rollover action é usada para gerenciar o tamanho ou o tempo de existência de cada índice. A ação force merge pode ser usada para otimizar os seus índices. A freeze action pode ser usada para reduzir a pressão da memória no cluster. Há muitas outras. Consulte a documentation da sua versão do Elasticsearch para saber quais são as ações disponíveis.
Política básica de ILM
Vejamos uma política de ILM bem básica:
PUT /_ilm/policy/my_policy
{
"policy":{
"phases":{
"hot":{
"actions":{
"rollover":{
"max_size":"50gb",
"max_age":"30d"
}
}
}
}
}
}
Essa política diz que, após 30 dias ou se o índice atingir 50 GB de tamanho (com base nos shards principais), deverá haver um rollover do índice e será necessário começar a gravar em um novo índice.
ILM e modelos de índice
Em seguida, precisamos associar essa política de ILM a um modelo de índice:
PUT _template/my_template
{
"index_patterns": ["test-*"],
"settings": {
"index.lifecycle.name": "my_policy",
"index.lifecycle.rollover_alias": "test-alias"
}
}
Observação: ao usar a ação de rollover, é required especificar a política de ILM em um index template, em vez de fazê-lo diretamente no índice.
Para políticas que incluírem a rollover action, você também deverá fazer o bootstrap do índice com um alias de gravação depois de criar o modelo de índice.
PUT test-000001
{
"aliases": {
"test-alias":{
"is_write_index": true
}
}
}
Supondo que todos os requirements sejam cumpridos corretamente para o rollover, qualquer novo índice que começar com test-* fará o rollover automaticamente após 30 dias ou 50 GB. O uso de índices gerenciados de rollover com max_size pode reduzir muito o número de shards (e, portanto, a sobrecarga) dos seus índices.
Configuração de uma política de ILM para ingestão
O Beats e o Logstash são compatíveis com o ILM e este, quando habilitado, configura uma política padrão semelhante ao exemplo acima. O Beats e o Logstash também lidam com todos os requirements para a rollover action. Isso significa que, quando o ILM estiver habilitado para o Beats e o Logstash, a menos que você tenha grandes índices diários (mais de 50 GB/dia), o tamanho provavelmente será o principal fator para determinar quando um novo índice será criado (e isso é bom!). O ILM com rollover será o padrão para o Beats e o Logstash a partir da versão 7.0.0.
No entanto, como não há uma solução que vale para todos os cenários para arquiteturas hot-warm-cold, o Beats e o Logstash não serão fornecidos com políticas hot-warm-cold. Poderemos fazer uma nova política que funcione para hot-warm-cold e algumas otimizações ao longo do caminho.
Nós poderíamos atualizar a política padrão do Beats ou do Logstash. No entanto, isso deixa pouco clara a fronteira entre o padrão e o personalizado. Além disso, a atualização da política padrão também aumenta o risco de que as versões futuras não apliquem a política correta (os padrões de modelo do Beats estão mudando para as versões 7.0+). Poderíamos usar as configurações do Beats e do Logstash para definir políticas personalizadas por meio de suas respectivas configurações. Isso funciona também, mas você pode não querer alterar a configuração de centenas (ou milhares) de Beats para alterar a política de ILM. A terceira abordagem descrita aqui utiliza multiple template matching para permitir que o Elasticsearch mantenha controle total sobre a política de ILM.
Otimização da sua política de ILM para hot-warm-cold
Primeiro, vamos criar uma política de ILM otimizada para uma arquitetura hot-warm-cold. Novamente, essa não é uma solução que vale para todos os cenários e é provável que seus requisitos sejam diferentes.
PUT _ilm/policy/hot-warm-cold-delete-60days
{
"policy": {
"phases": {
"hot": {
"actions": {
"rollover": {
"max_size":"50gb",
"max_age":"30d"
},
"set_priority": {
"priority": 50
}
}
},
"warm": {
"min_age": "7d",
"actions": {
"forcemerge": {
"max_num_segments": 1
},
"shrink": {
"number_of_shards": 1
},
"allocate": {
"require": {
"data": "warm"
}
},
"set_priority": {
"priority": 25
}
}
},
"cold": {
"min_age": "30d",
"actions": {
"set_priority": {
"priority": 0
},
"freeze": {},
"allocate": {
"require": {
"data": "cold"
}
}
}
},
"delete": {
"min_age": "60d",
"actions": {
"delete": {}
}
}
}
}
}
Hot
Essa política de ILM começará definindo a index priority com um valor alto para que os índices hot se recuperem antes dos demais. Após 30 dias ou 50 GB (o que ocorrer primeiro), o índice fará o rollover, e um novo índice será criado. Esse novo índice iniciará a política novamente, e o índice atual (o que acabou de fazer o rollover) aguardará até sete dias desde a data do rollover para entrar na fase warm.
Warm
Quando o índice estiver na fase warm, o ILM shrink o índice para um shard, force merge o índice para reduzi-lo a um segmento, set the index priority com um valor inferior ao do hot (porém maior do que o do cold) e moverá o índice para os nós warm por meio da ação allocation. Feito isso, aguardará 30 dias (desde o rollover) para entrar na fase cold.
Cold
Quando o índice estiver na fase cold, o ILM diminuirá novamente a index priority para garantir que os índices hot e warm se recuperem primeiro. Então, freeze o índice e o moverá para o(s) nó(s) cold. Feito isso, aguardará 60 dias (desde o rollover) para entrar na fase cold.
Exclusão
Ainda não discutimos a fase de exclusão. Simplificando, a fase de exclusão tem a ação delete que exclui o índice. Você sempre vai querer ter um min_age para a fase de exclusão para permitir que seu índice permaneça na fase hot, warm ou cold por um determinado período.
Criação de uma política de ILM no Kibana
Não gosta de escrever um monte de códigos em JSON? Eu também não. Vamos usar a interface do usuário do Kibana para inspecionar ou criar a política:
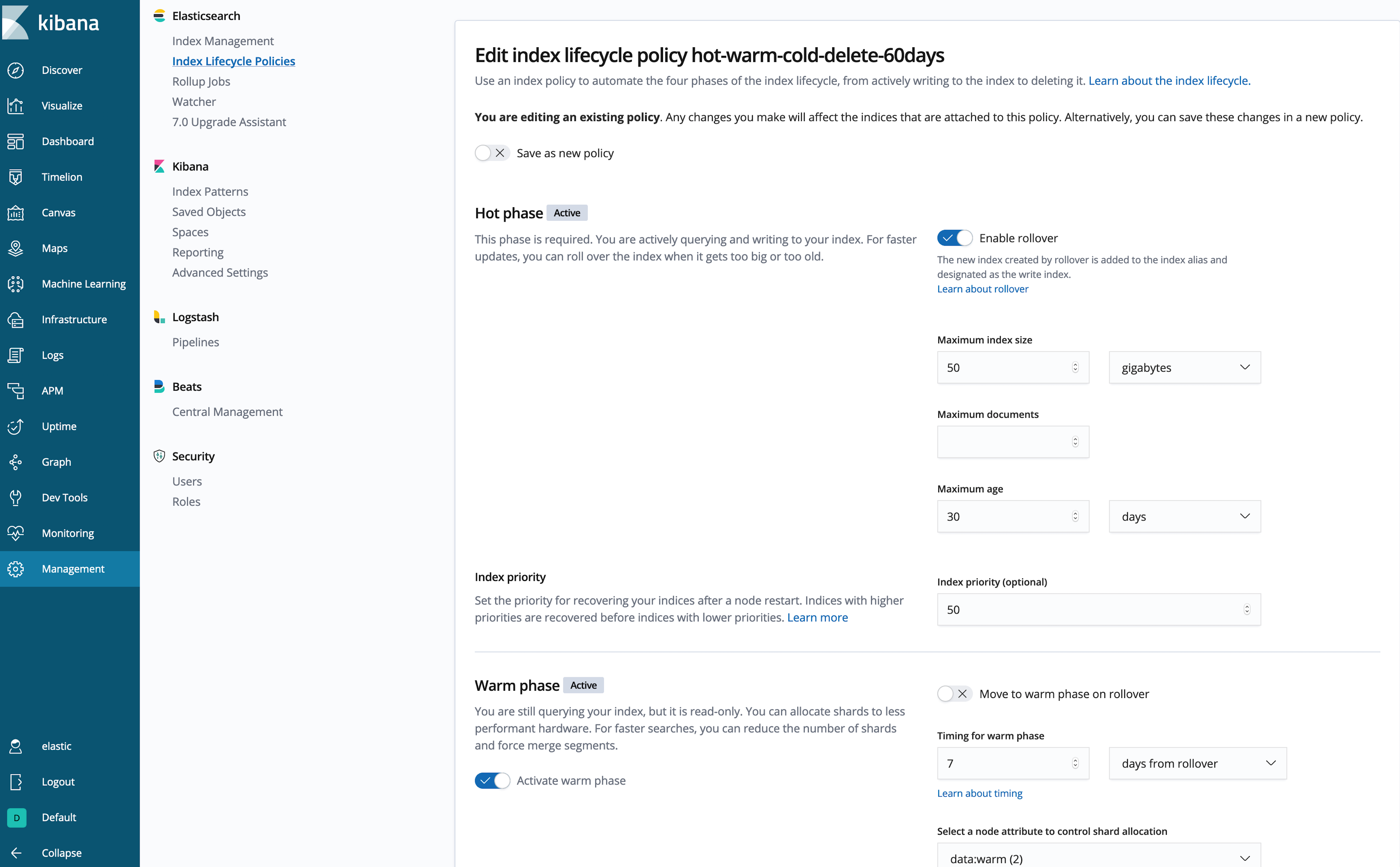 Bem melhor!
Bem melhor!
Agora precisamos associar a nova política hot-warm-cold-delete-60days aos índices do Beats e do Logstash e garantir que estejam gravando nos nós de dados hot. Como o Beats e o Logstash (por padrão) gerenciam seus próprios modelos, usaremos multiple template matching para adicionar as regras de política e alocação dos padrões de indexação que você deseja aplicar à política de ILM. Como esse modelo corresponde aos padrões de indexação do Beats e do Logstash, você precisará saber em quais padrões de indexação você quer fazer a correspondência. Aqui, usamos logstash- *, metricbeat- * e filebeat- *. Você pode adicionar quantos quiser, pressupondo que o Beats e o Logstash estejam com o suporte para ILM habilitado em suas configurações. Se você adicionar padrões de indexação aqui para produtores de dados que não dão suporte ao ILM, precisará cumprir os requirements manualmente para o rollover nessa política.
PUT _template/hot-warm-cold-delete-60days-template
{
"order": 10,
"index_patterns": ["logstash-*", "metricbeat-*", "filebeat-*"],
"settings": {
"index.routing.allocation.require.data": "hot",
"index.lifecycle.name": "hot-warm-cold-delete-60days"
}
}
Habilitação do ILM no Beats e/ou no Logstash
Por fim, vamos habilitar o ILM para o Beats e o Logstash.
Para o Beats 6.7:
output.elasticsearch:
ilm.enabled: true
Para o Logstash 6.7:
output {
elasticsearch {
ilm_enabled => true
}
}
Consulte a respectiva versão da documentação para saber como habilitar no Beats e no Logstash, pois isso pode mudar nas versões mais recentes.
Agora, qualquer novo índice que corresponder aos padrões de indexação criará os novos índices nos nós hot, e o ILM aplicará a política hot-warm-cold-delete-60days.
Atualização da sua política de ILM
Você pode atualizar a política de ILM a qualquer momento. No entanto, as alterações feitas na política serão aplicadas apenas quando a fase mudar. Por exemplo, se o seu índice estiver atualmente na fase hot (e aguardando a fase warm), quaisquer alterações feitas na fase hot não terão efeito nesse índice, mas quaisquer alterações na fase warm serão efetuadas assim que ele entrar nessa fase. Isso é feito para evitar a repetição das ações para uma determinada fase. Você pode visualizar o estado do ILM para o índice por meio da explain API.
Grande parte das prior information sobre como obter uma arquitetura hot-warm pré-ILM ainda se aplica, pois ela usa a mesma mecânica subjacente. No entanto, agora com o ILM, o Curator não é necessário para atingir esse padrão.
Daqui para a frente
A partir da versão 7.0, o Beats e o Logstash usam a gestão de ciclo de vida de índices por padrão quando se conectam a um cluster que dá suporte à gestão de ciclo de vida. O Beats também moved a maioria das configurações de ILM do espaço de nome output.elasticsearch.ilm para o espaço de nome setup.ilm. Para ver um exemplo, consulte a 7.0 Filebeat documentation. Também a partir da versão 7.0, índices de sistema como .watcher-history- * podem ser gerenciados pelo ILM.
O ILM facilita a implementação de uma arquitetura com economia de custos como a hot-warm-cold para os seus índices de série temporal. Experimente hoje mesmo e conte-nos o que achou em nossos Discuss forums. Bom proveito!