Dimensionamento de arquiteturas Hot-Warm para registro em log e métricas no Elasticsearch Service na Elastic Cloud
Quer aprender sobre as diferenças entre o Amazon Elasticsearch Service e nosso Elasticsearch Service oficial? Visite nossa página de comparação do AWS Elasticsearch.
Vivemos em uma época empolgante! O Elasticsearch Service na Elastic Cloud adicionou recentemente suporte para uma ampla gama de escolhas de hardware e modelos de implantação, que o tornam perfeito para lidar de maneira eficiente com cargas de trabalho relacionadas ao registro em logs e métricas. Com toda essa nova flexibilidade surgem também muitas escolhas a serem feitas. Pode ser difícil escolher a arquitetura mais adequada para seu caso de uso e estimar o tamanho de cluster necessário. Mas não se preocupe, viemos para ajudar!
Esse post vai ensiná-lo sobre as diferentes arquiteturas que geralmente são usadas para casos de uso de registro em log e métricas, e sobre quando usar cada uma delas. Ele também servirá de guia sobre como dimensionar e gerenciar seu(s) cluster(s) para aproveitá-lo(s) ao máximo.
Quais arquiteturas estão disponíveis para meu cluster de registro em log?
Nos clusters da Elasticsearch mais simples possíveis, todos os nós de dados têm a mesma especificação e lidam com as mesmas funções. Os nós para as tarefas específicas vão sendo adicionados conforme esse tipo de cluster cresce, por exemplo, nó mestre dedicado, nó de ingestão e nó de aprendizado de máquina. Isso tira a carga dos nós de dados e faz com que eles operem de maneira mais eficiente. Nesse tipo de cluster todos os nós de dados compartilham igualmente a carga de indexamento e de consulta e, como todos eles têm a mesma especificação, muitas vezes chamamos isso de arquitetura de cluster homogênea ou uniforme.
Outra arquitetura muito popular, especialmente ao trabalhar com dados baseados em tempo como logs e métricas, é o que chamamos de arquitetura hot-warm. Ela é baseada no princípio de que os dados geralmente são imutáveis e podem ser indexados em índices baseados em tempo. Portanto, cada índice contém dados que cobrem um período de tempo específico, o que faz com que seja possível gerenciar a retenção e o ciclo de vida dos dados ao excluir índices cheios. Essa arquitetura tem dois tipos de nós de dados, com perfis de hardware diferentes: nós de dados “hot” e “warm”.
Os nós de dados hot são os que têm os índices mais recentes e, portanto, lidam com toda a carga de indexação no cluster. Como os dados mais recentes também são, tipicamente, os consultados com mais frequência, esses nós tendem a manter-se muito ocupados. A indexação no Elasticsearch pode usar de forma intensa a CPU e a E/S, e a carga de consulta adicional significa que esses nós precisam ser potentes e ter um armazenamento muito rápido. Isso geralmente significa SSDs anexados locais.
Por outro lado os nós warm são otimizados para lidar com o armazenamento a longo prazo de índices somente leitura no cluster, de maneira econômica. Geralmente eles contam com boas quantidades de RAM e CPU, mas muitas vezes também usam discos de rotação anexados locais ou SAN em vez de SSDs. Assim que os índices nos nós hot ultrapassam o período de retenção desses nós e não são mais indexados, eles são relocados para os nós warm.
É importante observar que mover os dados dos nós hot para os nós warm não necessariamente significa que a consulta será mais lenta. Como esses nós não lidam com indexação intensiva de recursos, muitas vezes eles são capazes de atender a consultas de maneira eficiente contra dados mais antigos em latências lentas, sem ter que usar o armazenamento baseado em SSD.
Como os nós de dados nessa arquitetura são muito especializados e podem ser usados com altas cargas, recomendamos usar os nós mestre dedicado, ingestão, aprendizado de máquina e somente coordenação.
Qual arquitetura devo escolher?
Para muitos casos de uso ambas as arquiteturas vão funcionar bem, e nem sempre fica claro qual é a melhor escolha. Porém, existem certas condições e restrições que podem tornar uma das arquiteturas mais adequada do que a outra.
Os tipos de armazenamento disponíveis no cluster são um fator importante a ser considerado. Como a arquitetura hot/warm requer um armazenamento rápido para os nós hot, ela não será adequada se o cluster for limitado ao uso de armazenamento mais lento. Nesse caso, é melhor usar uma arquitetura uniforme e estender a indexação e consulta pelo máximo de nós que for possível.
Clusters uniformes muitas vezes são suportados por discos rotativos locais ou SAN anexado como um armazenamento em bloco, mesmo que os SSDs estejam cada dia mais comuns. Um armazenamento mais lento pode não conseguir suportar taxas de indexação muito altas, especialmente quando existe a consulta ao mesmo tempo, então pode demorar para preencher o espaço em disco disponível. Portanto, manter altos volumes de dados por nó pode ser possível apenas se você tiver um período de retenção razoavelmente longo.
Se o caso de uso determinar um período de retenção muito curto, de por exemplo menos de 10 dias, os dados não vão ficar parados no disco por muito tempo depois de indexados. Para isso, é preciso um armazenamento de bom desempenho. Uma arquitetura hot/warm pode funcionar, mas um cluster uniforme apenas com os nós de dados hot pode ser melhor e mais fácil de gerenciar.
Eu preciso de quanto armazenamento?
Uma das principais coisas a se considerar ao dimensionar um cluster para um caso de uso de registro em log e/ou métricas é a quantidade de armazenamento. A taxa entre o volume de dados brutos e quanto espaço será usado no disco depois de ser indexado e replicado no Elasticsearch dependerá muito do tipo de dado e de como a indexação é feita. O diagrama abaixo mostra os estágios diferentes pelos quais os dados passam durante a indexação.
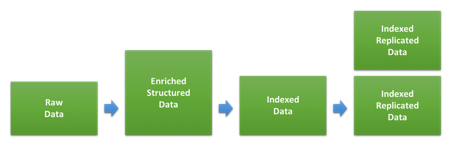
A primeira etapa envolve transformar dados brutos nos documentos JSON que vamos indexar no Elasticsearch. O quanto isso vai mudar o tamanho dos dados vai depender do formato original e da estrutura adicionada, mas também da quantidade de dados adicionados através de vários tipos de enriquecimento. Isso pode ser variar muito para diferentes tipos de dados. Se os seus logs já estiverem no formato JSON e você não estiver adicionando mais dados, o tamanho poderá não mudar. Por outro lado, se você tiver logs de acesso da web baseados em texto, a estrutura e as informações adicionadas sobre o usuário, agente e local poderão ser consideravelmente maiores.
Assim que esses dados forem indexados no Elasticsearch, as configurações e mapeamentos de índice usados vão determinar qual será o espaço utilizado em disco. Os mapeamentos dinâmicos padrão aplicados pela Elasticsearch geralmente são projetados pensando na flexibilidade, e não no tamanho de armazenamento em disco otimizado, então é possível economizar espaço em disco ao otimizar os mapeamentos usados através dos modelos de índice personalizados. É possível encontrar mais orientações sobre isso na documentação de ajuste.
Para estimar quanto espaço em disco um tipo de dado específico vai usar no seu cluster, indexe uma grande quantidade de dados para ter certeza de que você vai alcançar o tamanho de fragmento que deverá ser usado na produção. Fazer testes usando volumes de dados muito pequenos é um erro muito comum, que pode criar resultados imprecisos.
Como equilibrar a ingestão e a consulta?
O primeiro parâmetro de comparação usado pela maioria dos usuários ao dimensionar um cluster é determinar a produção máxima de indexação do cluster. Afinal de contas, esse é um parâmetro de comparação fácil de configurar e executar, e os resultados também podem ser usados para determinar quanto espaço os dados vão ocupar no disco.
Assim que o processo de cluster e ingestão tenha sido ajustado e tivermos identificado a taxa de indexação máxima que podemos manter, podemos calcular quanto tempo vai levar para encher o disco com os nós de dados que pudermos continuar a fazer a indexação com a produção máxima. Isso nos dará uma indicação de qual seria o período de retenção mínimo para o tipo de nó, assumindo que vamos querer maximizar o uso do espaço em disco disponível.
Pode ser tentador usar isso diretamente para determinar o tamanho necessário, mas isso não deixaria nenhum espaço livre para consultas, pois todos os recursos do sistema seriam usados para a indexação. Afinal de contas, a maioria dos usuários estão armazenando dados no Elasticsearch para conseguirem consultar esses dados em algum momento, e esperam ter um bom desempenho ao fazer isso.
Então quando espaço livre precisamos deixar para as consultas? Essa é uma pergunta difícil para oferecer uma resposta genérica, pois depende muito da quantidade e da natureza das consultas esperadas, assim como da latência esperada pelos usuários. A melhor forma de determinar isso é executar um parâmetro de comparação simulando níveis realistas de consulta em volumes de dados e taxas de indexação diferentes conforme descrito nesta palestra Elastic{ON} sobre o dimensionamento quantitativo de cluster e neste webinar sobre definição de parâmetro de comparação e dimensionamento de cluster usando o Rally.
Depois de ter determinado o tamanho da produção máxima de indexação podemos sustentar enquanto atendemos as consultas dos usuários com um desempenho aceitável, podemos ajustar o período de retenção esperado de acordo com essa taxa de indexação reduzida. Se a indexação for feita em um ritmo mais lento, vai demorar mais para encher os discos.
Esse ajuste pode nos dar a habilidade de lidar com pequenos picos no tráfego, mas geralmente assume uma taxa de indexação constante com o tempo. Se houver a expectativa de picos e flutuações nos níveis de tráfego ao longo do dia, poderá ser necessário assumir que a taxa de indexação ajustada corresponde ao nível de pico e reduzir ainda mais a taxa de indexação média que assumimos que cada nó é capaz de lidar. No caso das flutuações serem previsíveis e durarem períodos de tempo extensos, por exemplo, durante o horário comercial, outra opção pode ser aumentar o tamanho da zona hot apenas durante aquele período.
Como usar todo esse armazenamento?
Em arquiteturas hot-warm, espera-se que os nós warm sejam capazes de lidar com grandes quantidades de dados. Isso também é aplicável a nós de dados em uma arquitetura uniforme com um período de retenção longo.
Exatamente quantos dados poderão ser mantidos com sucesso em um nó vai depender, muitas vezes, na capacidade de gerenciar o uso de heap, que muitas vezes acaba se tornando o principal fator limitador de nós densos. Como existem várias áreas que contribuem para o uso de heap em um cluster da Elasticsearch, como por exemplo a indexação, consulta, armazenamento em cache, estado do cluster, dados de campo e sobrecarga de fragmento, os resultados variam entre os casos de uso. A melhor forma de determinar com precisão quais são os limites para seu caso de uso é executar parâmetros de comparação baseados em dados realistas e em padrões de consulta. Porém, existem várias melhores práticas genéricas em relação aos casos de uso de registro em relatório e métrica que vão ajudá-lo a obter o máximo possível dos seus nós de dados.
Não esqueça de otimizar os mapeamentos
Como descrevemos antes, os mapeamentos usados para seus dados podem afetar a compactação do disco. Eles também podem afetar quantos dados de campo serão usados e ter um impacto no uso de heap. Se você estiver usando módulos Filebeat ou módulos Logstash para fazer o parsing e ingerir seus dados, eles vão vir com mapeamentos otimizados de fábrica e você provavelmente não vai precisar se preocupar muito com isso. Mas, se você estiver fazendo parsing de logs personalizados e contando muito com a capacidade do Elasticsearch de mapear novos campos de maneira dinâmica, recomendamos que continue lendo esse tópico.
Quando o Elasticsearch mapeia uma string de maneira dinâmica, o comportamento padrão é usar multicampos para mapear os dados tanto como texto, que pode ser usado para uma pesquisa de texto livre sem identificação de maiúsculas e minúsculas, quanto como palavra-chave, que pode ser usado para agregar dados no Kibana. Esse é um ótimo padrão, pois oferece uma ótima flexibilidade, mas a desvantagem é que ele aumenta o tamanho dos índices no disco e a quantidade de dados de campo usados. Portanto, recomendamos continuar e otimizar os mapeamentos sempre que possível, pois isso pode fazer uma grande diferença conforme os volumes de dados crescem.
Mantenha os maiores fragmentos possíveis
Cada índice no Elasticsearch contém um ou mais fragmentos, e cada fragmento vem com uma sobrecarga que usa um determinado espaço de heap. Fragmentos menores tem mais sobrecarga por volume de dados em comparação com fragmentos maiores, como descrevemos neste post no blog sobre fragmentação. Portanto, para minimizar o uso de heap em nós que devem guardar grandes quantidades de dados é importante tentar manter os maiores fragmentos possíveis. Uma boa regra geral é manter o tamanho de fragmento médio para uma retenção a longo prazo entre 20 GB e 50 GB.
Como cada consulta ou agregação é executado com single-thread por fragmento, a latência mínima de consulta normalmente vai depender do tamanho do fragmento. Isso depende dos dados e das consultas, então pode variar entre índices dentro do mesmo caso de uso. Porém, para um volume de dados e tipo de dados específico, não é garantido que um número maior de fragmentos menores vai ter um desempenho melhor do que um único fragmento maior.
É importante testar o efeito do tamanho dos fragmentos, para chegar a um ponto ideal em relação ao uso de consultas e sobrecarga mínima.
Ajuste para o volume de armazenamento
A compressão eficiente de origem JSON pode ter um impacto significativo em quanto espaço seus dados vão ocupar em disco. Por padrão, o Elasticsearch comprime esses dados usando um algoritmo de compressão ajustado para o equilíbrio entre a velocidade de armazenamento e indexação, mas também oferece uma opção mais agressiva: o best_compression codec.
Isso pode ser especificado para todos os novos índices, mas vem com uma penalidade no desempenho de cerca de 5-10% durante a indexação. O ganho de espaço em disco pode ser significante, então pode ser uma escolha que vale a pena.
Se você seguir o conselho da seção anterior e está fazendo a mesclagem forçada de índices, você também vai ter a opção de aplicar a compressão aprimorada antes da operação de mesclagem forçada.
Evite cargas desnecessárias
A última coisa que contribui para o uso de heap que vamos discutir aqui é como lidar com solicitações. Todas as solicitações que são enviadas para o Elasticsearch são coordenadas no nó assim que chegam.. Então o trabalho é separado e espalhado para onde os dados estão. Isso é aplicável tanto para a indexação quanto para as consultas.
O parsing e a coordenação da solicitação e da resposta podem causar um uso de heap significativo. Certifique-se de que os nós trabalhando como nós de coordenação ou indexação tem espaço livre de heap suficiente para conseguirem lidar com isso.
Para nós ajustados para o armazenamento de dados a longo prazo, muitas vezes faz sentido deixá-los trabalhar como nós de dados dedicados e minimizar qualquer trabalho adicional que eles precisem realizar. Para isso, pode ajudar direcionar todas as consultar para nós hot ou nós dedicados somente para coordenação.
Como aplicar isso à minha implantação do Elasticsearch Service?
O Elasticsearch Service está disponível atualmente no AWS e GCP, e apesar das mesmas configurações de instância e modelos de implantação estarem disponíveis em ambas as plataformas, as especificações são um pouco diferentes. Nesta seção vamos dar uma olhada nas configurações de instância diferentes e em como elas se encaixam nas arquiteturas que discutimos mais cedo. Também vamos ver como podemos estimar o tamanho do cluster necessário para suportar um caso de uso de exemplo.
Configurações de instância disponíveis
O Elasticsearch Service tradicionalmente tem os nós Elasticsearch apoiamos por um armazenamento SSD rápido. Eles são chamados de nós highio e têm excelente desempenho E/S. Isso faz com que eles funcionem muito bem como nós hot em uma arquitetura hot-warm, mas também podem ser usados como nós de dados em uma arquitetura Uniforme. Isso é recomendado muitas vezes se você tiver um período de retenção curto que precise de um armazenamento de alto desempenho.
No AWS e GCP os nós highio têm uma taxa de disco para RAM de 30:1, então para cada 1 GB de RAM há 30 GB de armazenamento disponível. Tamanhos de nós disponíveis no AWS são 1 GB, 2 GB, 4 GB, 8 GB, 15 GB, 29 GB e 58 GB, enquanto seus GCP nos nós vêm nos tamanhos de 1 GB, 2 GB, 4 GB, 8 GB, 16 GB, 32 GB e 64 GB.
Outro tipo de nó que foi introduzido recentemente na Elastic Cloud é o nó highstorage otimizado para armazenamento. Ele é equipado com volumes altos de armazenamento mais lento, com uma taxa de disco para RAM de 100:1. Um nó highstorage de 64 GB no GCP vem com mais de 6.2 TB de armazenamento, enquanto um nó de 58 GB no AWS suporta 5.6 TB. Esses tipos de nó vêm com o mesmo tamanho de RAM que os nós highio nas respectivas plataformas.
Esses nós geralmente são usados como nós warm em uma arquitetura hot/warm. Os parâmetros de comparação em nós highstorage já mostraram que esse tipo de nó no GCP tem uma vantagem de desempenho significante em comparação com o AWS, mesmo considerando a diferença de tamanho.
Como usar 2 ou 3 zonas de disponibilidade
Na maioria das regiões você tem uma opção de escolher operar em 2 ou 3 zonas de disponibilidade, e pode escolher um número diferente de zonas por zona no agrupamento. Ao ficar com um número fixo de zonas de disponibilidade, os tamanhos de cluster disponíveis aumentam quase que dobrando de tamanho, pelo menos para agrupamentos menores. Se você estiver aberto a usar 2 ou 3 zonas de disponibilidade é possível fazer o dimensionamento em etapas menores, já que passar de 2 para 3 zonas de disponibilidade com o mesmo tamanho de nó aumenta a capacidade em apenas 50%.
Exemplo de dimensionamento: Arquitetura hot-warm
Neste exemplo vamos observar o dimensionamento de um cluster hot-warm capaz de lidar com a ingestão de 100 GB de logs brutos de acesso a web por dia com um período de retenção de 30 dias. Vamos comparar a implantação disso com a Elastic Cloud no AWS e no GCP.
Observe que os dados usados aqui são apenas um exemplo, e muito provavelmente seu caso de uso será diferente.
Etapa 1: Estimar o volume de dados total
Para este exemplo, estamos assumindo que os dados são ingeridos usando módulos Filebear e que, portanto, os mapeamentos estão otimizados. Para manter a simplicidade, vamos usar apenas um tipo de dados neste exemplo. Durante os parâmetros de comparação de indexação, vimos que a taxa entre o tamanho de dados brutos e o tamanho indexado no disco é de cerca de 1.1, então estimamos que 100 GB de dados brutos resulte em 110 GB de dados indexados no disco. Assim que uma réplica for adicionada esse número dobra para 220 GB.
Ao longo de 30 dias, isso nos dá um volume total de dados indexados e replicados de 6600 GB com o qual o cluster precisa lidar como um todo.
Esse exemplo assume que 1 fragmento de réplica é usado em todas as zonas, já que isso é considerado a melhor prática para o desempenho e disponibilidade.
Etapa 2: Dimensionar nós hot
Executamos alguns parâmetros de comparação máximos de indexação contra os nós hot usando esse conjunto de dados, e vimos que leva cerca de 3,5 dias para os discos nos nós highio ficarem cheios no AWS e GCP.
Para deixar um espaço livre para consultas e pequenos picos de tráfego, vamos assumir que podemos sustentar a indexação em no máximo 50% do nível máximo. Portanto, se quisermos conseguir usar totalmente o armazenamento disponível nesses nós vamos precisar indexar no nó durante um longo período de tempo, e vamos então ajustar o período de retenção nesses nós para refletir essa necessidade.
O Elasticsearch também precisa de um certo espaço em disco livre para trabalhar de maneira eficiente, então para não ultrapassar as marcas d'água de disco vamos assumir a necessidade de um espaço em disco livre extra de 15%. Isso é exibido na coluna Espaço em disco necessário abaixo. Baseado nisso, podemos determinar a quantidade total de RAM necessário para cada provedor.
| Plataforma | Taxa Disco:RAM | Dias até encher | Retenção efetiva (dias) | Volume de dados mantido (GB) | Espaço em disco necessário (GB) | RAM necessário (GB) | Especificação da zona |
| AWS | 30:1 | 3,5 | 7 | 1440 | 1656 | 56 | 29GB, 2AZ |
| GCP | 30:1 | 3,5 | 7 | 1440 | 1656 | 56 | 32GB, 2AZ |
Etapa 3: Dimensionar nós warm
Os dados que ultrapassam o período de retenção dos nós hot serão relocados para os nós warm. Podemos estimar o tamanho necessário calculando a quantidade de dados que precisam ser guardados nesses nós, levando em conta a sobrecarga por altas marcas d'água.
| Plataforma | Taxa Disco:RAM | Retenção efetiva (dias) | Volume de dados mantido (GB) | Espaço em disco necessário (GB) | RAM necessário (GB) | Especificação da zona |
| AWS | 100:1 | 23 | 5060 | 5819 | 58 | 29GB, 2AZ |
| GCP | 100:1 | 23 | 5060 | 5819 | 58 | 32GB, 2AZ |
Etapa 4: Adicionar outros tipos de nó
Além dos nós de dados, geralmente precisamos de 3 nós mestre dedicados para tornar o cluster mais resiliente e com alta disponibilidade. Como eles não atendem nenhum tráfego, eles podem ser pequenos. Alocar inicialmente nós de 1 GB a 2 GB por 3 zonas de disponibilidade é uma boa forma de começar. Depois escale esses nós em até 16 GB por 3 zonas de disponibilidade conforme o tamanho do cluster gerenciado cresce.
O que vem a seguir?
Comece nossa avaliação gratuita de 14 dias do Elasticsearch Service e experimente o que podemos fazer! Veja você mesmo como isso é fácil de configurar e gerenciar. Se tiver alguma dúvida ou se quiser mais informações sobre como dimensionar seu Elasticsearch Service na Elastic Cloud, entre em contato diretamente conosco ou fale conosco em nosso Fórum de discussão público.