Como monitorar as métricas da GPU da NVIDIA com o Elastic Observability
As unidades de processamento gráfico, ou GPUs, não são apenas para jogos de PC. Hoje, as GPUs são usadas para treinar redes neurais, simular dinâmica de fluidos computacional, minerar bitcoin e processar cargas de trabalho em datacenters. E eles estão no cerne da maioria dos sistemas de computação de alto desempenho, tornando o monitoramento do desempenho da GPU nos datacenters atuais tão importante quanto o monitoramento do desempenho da CPU.
Com isso em mente, vamos ver como usar o Elastic Observability junto com as ferramentas de monitoramento de GPU da NVIDIA para observar e otimizar o desempenho da GPU.
Dependências
Para colocar as métricas de GPU da NVIDIA em funcionamento, precisaremos criar ferramentas de monitoramento de GPU da NVIDIA a partir do código-fonte (Go). E, obviamente, precisaremos de uma GPU da NVIDIA. A AMD e outros tipos de GPU usam diferentes drivers e ferramentas de monitoramento para Linux; então, teremos de abordá-los em outro post.
As GPUs da NVIDIA estão disponíveis em muitos provedores de serviços em nuvem, como Google Cloud e Amazon Web Services (AWS). Para este post, usaremos uma instância em execução no Genesis Cloud.
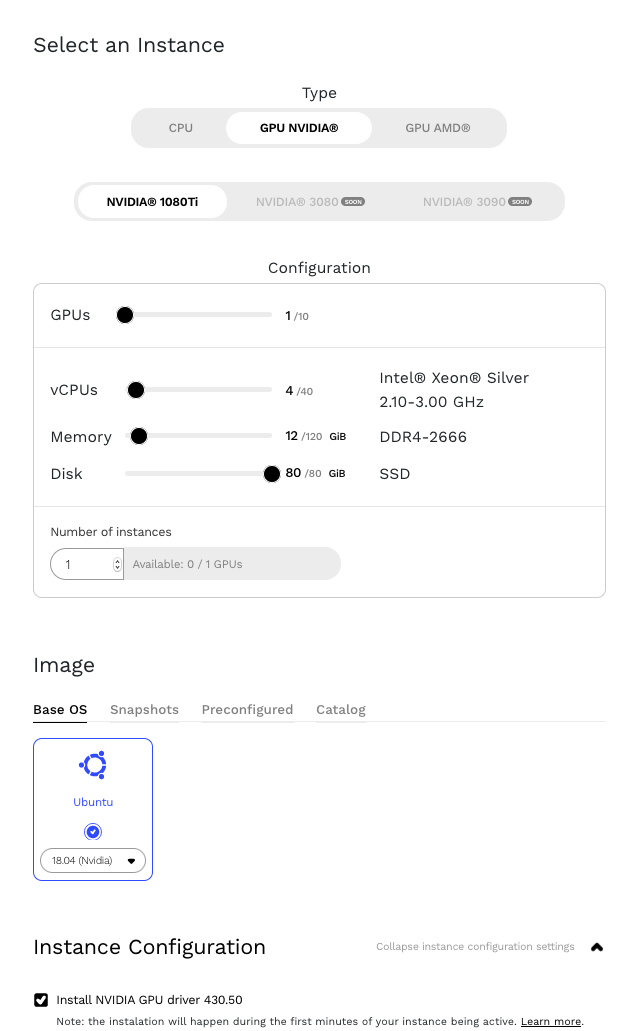
Vamos começar instalando o NVIDIA Datacenter Manager de acordo com a seção de instalação do NVIDIA’s DCGM Getting Started Guide (Guia de introdução ao DCGM da NVIDIA) para Ubuntu 18.04. Observação: ao seguir o guia, preste atenção especial ao substituir o parâmetro <architecture> pelo nosso. Podemos encontrar nossa arquitetura usando o comando uname.
uname -a
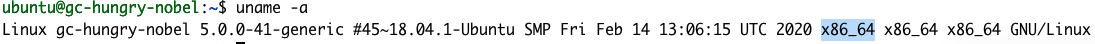
A resposta nos diz que a nossa arquitetura é X86_64. Portanto, a etapa 1 do guia de introdução seria:
echo "deb http://developer.download.nvidia.com/compute/cuda/repos/$distribution/x86_64 /" | sudo tee /etc/apt/sources.list.d/cuda.list
Também há um erro de digitação na etapa 2. Remova o > final de $distribution.
sudo apt-key adv --fetch-keys https://developer.download.nvidia.com/compute/cuda/repos/$distribution/x86_64/7fa2af80.pub
Após a instalação, deveremos conseguir ver os detalhes da nossa GPU executando o comando nvidia-smi.
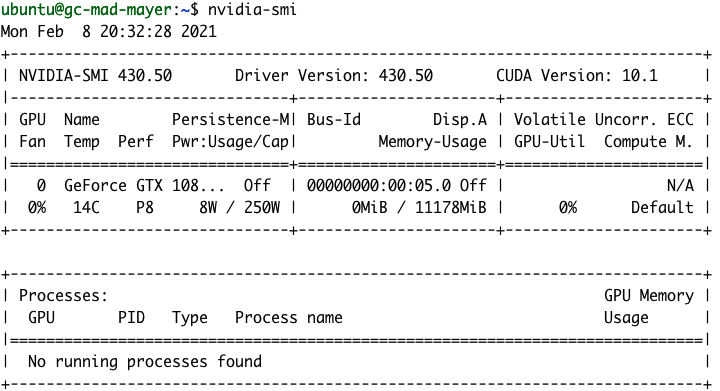
gpu-monitoring-tools da NVIDIA
Para criar o gpu-monitoring-tools da NVIDIA, precisaremos instalar o Golang. Então, vamos cuidar disso agora.
cd /tmp wget https://golang.org/dl/go1.15.7.linux-amd64.tar.gz sudo mv go1.15.7.linux-amd64.tar.gz /usr/local/ cd /usr/local/ sudo tar -zxf go1.15.7.linux-amd64.tar.gz sudo rm go1.15.7.linux-amd64.tar.gz
OK, é hora de terminar a configuração da NVIDIA instalando o gpu-monitoring-tools da NVIDIA a partir do GitHub.
cd /tmp git clone https://github.com/NVIDIA/gpu-monitoring-tools.git cd gpu-monitoring-tools/ sudo env "PATH=$PATH:/usr/local/go/bin" make install
Metricbeat
Agora estamos prontos para instalar o Metricbeat. Verifique rapidamente em elastic.co qual é a versão mais recente do Metricbeat e ajuste o número da versão nos comandos abaixo.
cd /tmp wget https://artifacts.elastic.co/downloads/beats/metricbeat/metricbeat-7.10.2-amd64.deb sudo dpkg -i metricbeat-7.10.2-amd64.deb # 7.10.2 is the version number
Elastic Cloud
OK, vamos colocar o Elastic Stack em funcionamento. Precisaremos de um lugar para armazenar nossos novos dados de monitoramento de GPU. Para isso, criaremos uma nova implantação no Elastic Cloud. Se você ainda não é um cliente do Elastic Cloud, pode se inscrever para fazer uma avaliação gratuita de 14 dias. Como alternativa, você pode configurar sua própria implantação localmente.
Em seguida, crie uma nova implantação do Elastic Observability no Elastic Cloud.
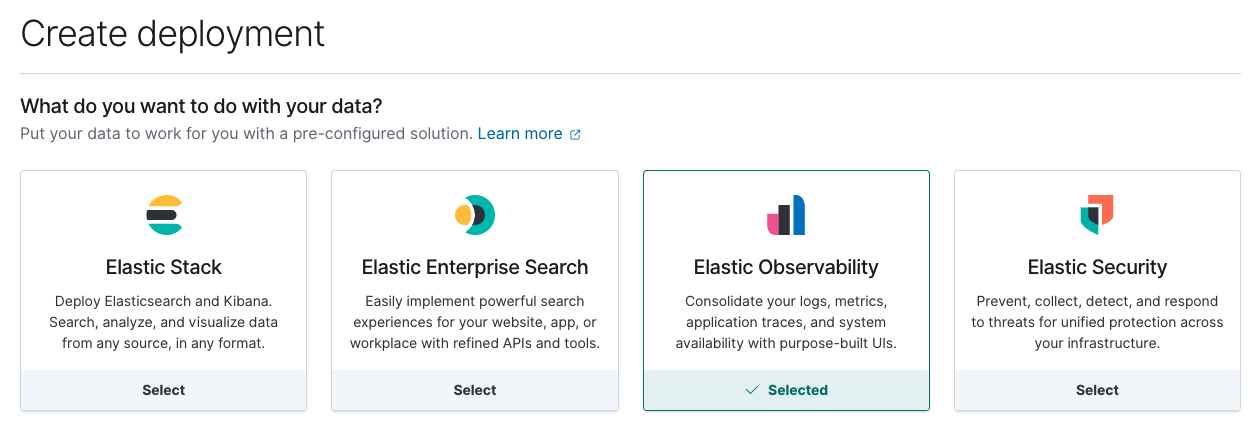
Quando a sua implantação na nuvem estiver em funcionamento, anote seu Cloud ID e as credenciais de autenticação — vamos precisar deles para a configuração do Metricbeat que vem a seguir.
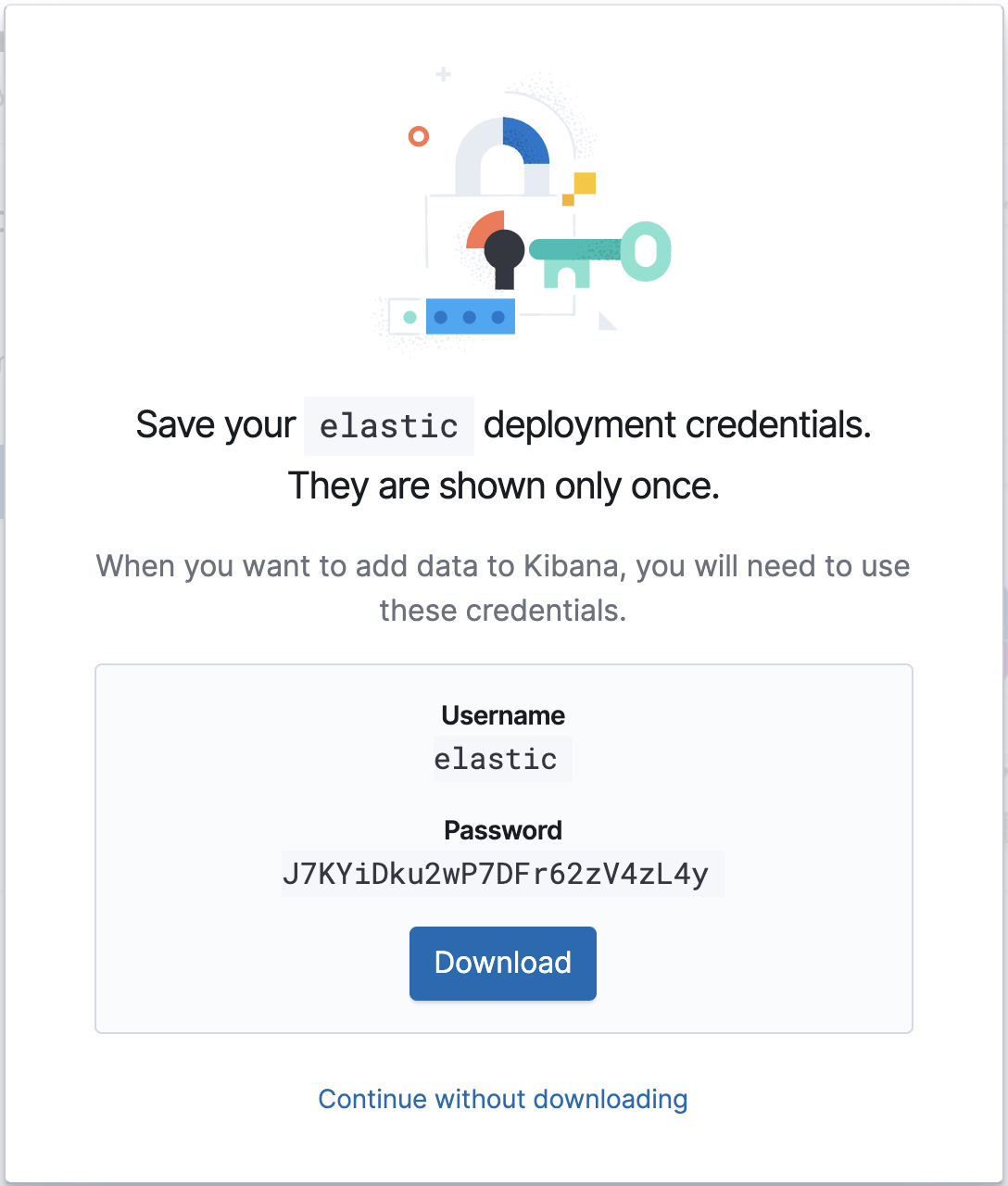
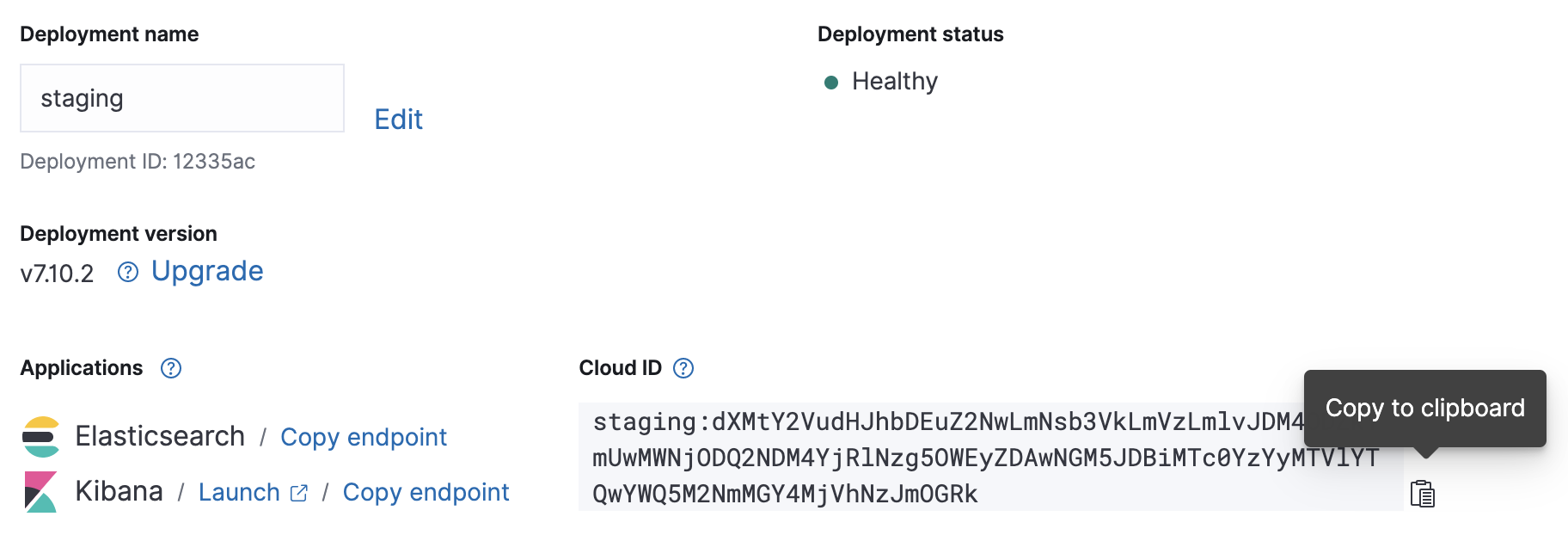
Configuração
O arquivo de configuração do Metricbeat está localizado em /etc/metricbeat/metricbeat.yml. Abra-o no seu editor favorito e edite os parâmetros cloud.id e cloud.auth para corresponderem à sua implantação.
Exemplo de alterações na configuração do Metricbeat usando as capturas de tela acima:
cloud.id: "staging:dXMtY2VudHJhbDEuZ2NwLmNsb3VkLmVzLmlvJDM4ODZkYmUwMWNjODQ2NDM4YjRlNzg5OWEyZDAwNGM5JDBiMTc0YzYyMTVlYTQwYWQ5M2NmMGY4MjVhNzJmOGRk" cloud.auth: "elastic:J7KYiDku2wP7DFr62zV4zL4y"
A configuração de entrada do Metricbeat é modular. O gpu-monitoring-tools da NVIDIA publica as métricas da GPU via Prometheus; então, vamos habilitar o módulo Prometheus do Metricbeat agora.
sudo metricbeat modules enable prometheus
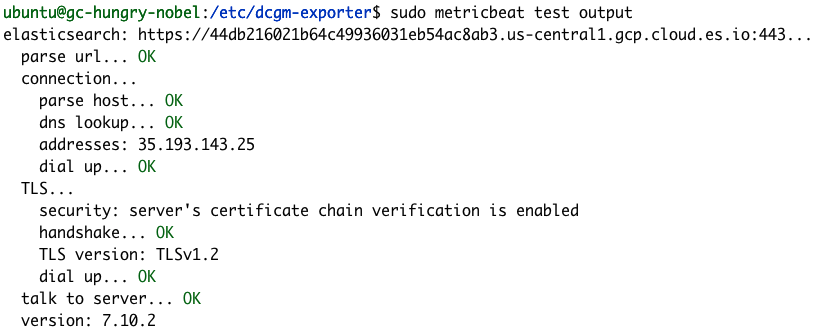
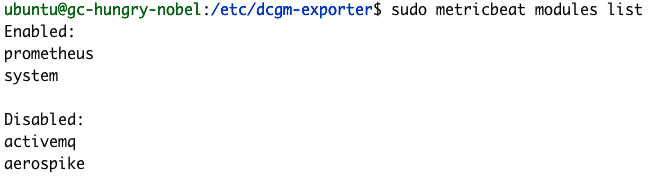
Podemos confirmar que a nossa configuração do Metricbeat foi bem-sucedida usando os comandos de módulos e o teste do Metricbeat.
sudo metricbeat test config

sudo metricbeat test output
sudo metricbeat modules list
Se seus testes de configuração não forem bem-sucedidos como os exemplos acima, consulte nosso Metricbeat troubleshooting guide (Guia de solução de problemas do Metricbeat).
Concluímos a configuração do Metricbeat executando seu comando de configuração, que carregará alguns dashboards padrão e configurará mapeamentos de índice. O comando de configuração normalmente leva alguns minutos para ser concluído.
sudo metricbeat setup

Exportação de métricas
É hora de começar a exportar métricas. Vamos iniciar o dcgm-exporter da NVIDIA.
dcgm-exporter --address localhost:9090 # Saída INFO[0000] Starting dcgm-exporter INFO[0000] DCGM successfully initialized! INFO[0000] Not collecting DCP metrics: Error getting supported metrics: This request is serviced by a module of DCGM that is not currently loaded INFO[0000] Pipeline starting INFO[0000] Starting webserver
Observação: você pode ignorar o aviso do DCP
A configuração das métricas do dcgm-exporter é definida no arquivo /etc/dcgm-exporter/default-counters.csv, no qual 38 métricas diferentes são definidas por padrão. Para obtermos a lista completa de valores possíveis, podemos consultar o DCGM Library API Reference Guide (Guia de referência da API da biblioteca do DCGM).
Em outro console, vamos iniciar o Metricbeat.
sudo metricbeat -e
Agora você pode ir para a instância do Kibana e atualizar o padrão de indexação ‘metricbeat-*’. Podemos fazer isso navegando até Stack Management > Kibana > Index Patterns (Gerenciamento da stack > Kibana > Padrões de indexação) e selecionando o padrão de indexação metricbeat-* na lista. Em seguida, clique em Refresh field list (Atualizar lista de campos).
Agora, nossas novas métricas da GPU estão disponíveis no Kibana. Os novos nomes de campos são prefixados por prometheus.metrics.DCGM_. Aqui está um snippet mostrando os novos campos do Discover.
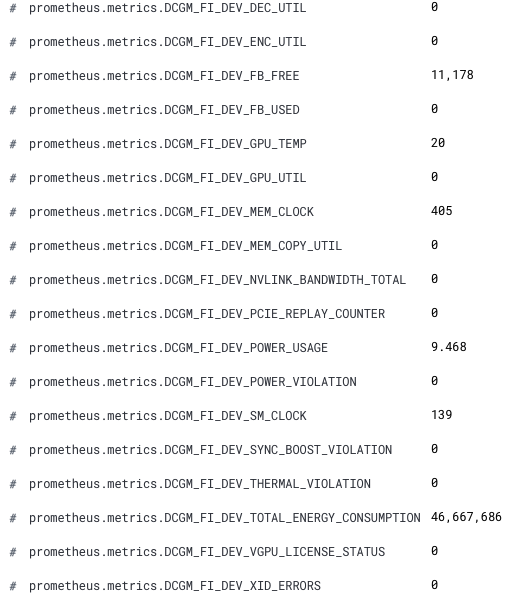
Parabéns! Agora estamos prontos para analisar nossas métricas da GPU no Elastic Observability.
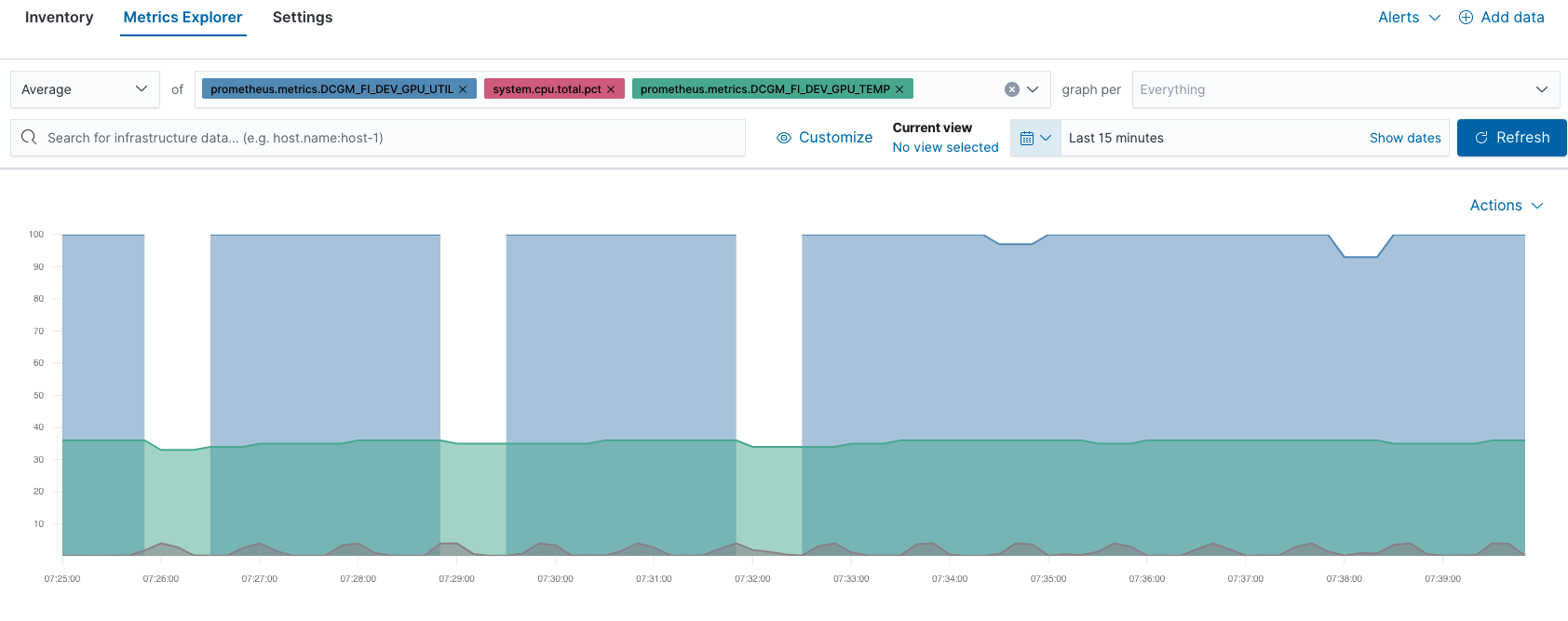
Por exemplo, você pode comparar o desempenho da GPU e da CPU no Metrics Explorer (Explorador de Métricas):
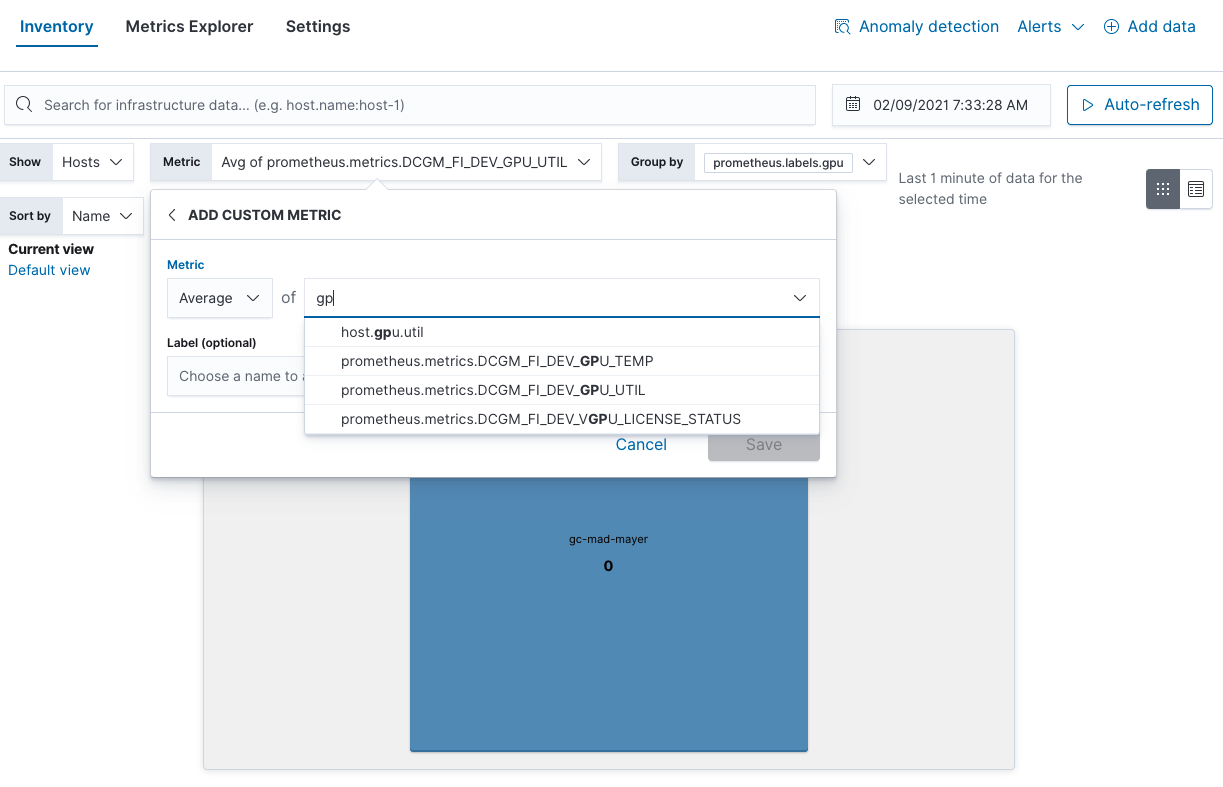
Pode também encontrar pontos significativos de utilização da GPU na visualização Inventory (Inventário):
Considerações sobre o monitoramento da GPU
Esperamos que este post tenha sido útil. Essas são apenas algumas opções de monitoramento, mas o Elastic Observability lhe permite trabalhar com todos os seus objetivos. Aqui estão alguns outros exemplos de aspectos interessantes da GPU para monitorar de acordo com a NVIDIA:
- Temperatura da GPU: verifique se há pontos quentes
- Uso de energia da GPU: uso de energia superior ao esperado => possíveis problemas de hardware
- Velocidades de clock atuais: abaixo do esperado => limitação de energia ou problemas de hardware
E, se precisar simular a carga da GPU, você poderá usar o comando dcgmproftester10.
dcgmproftester10 --no-dcgm-validation -t 1004 -d 30
Vá ainda mais longe no seu monitoramento usando o alerta da Elastic para automatizar as recomendações da NVIDIA. Em seguida, eleve o nível, encontrando anomalias na sua infraestrutura de GPU com machine learning. Se você ainda não é um cliente do Elastic Cloud e gostaria de experimentar as etapas deste post do blog, pode se inscrever para fazer uma avaliação gratuita de 14 dias.