Elasticsearch 7.2.0 released
Today we are pleased to announce the release of Elasticsearch 7.2.0, based on Lucene 8.0.0. This is the latest stable release, and is already available for deployment via our Elasticsearch Service on Elastic Cloud.
Latest stable release in 7.2.0:
You can read about all the changes in the release notes linked above, but there are a few changes which are worth highlighting:
Geo and Time Proximity as Ranking Consideration
In many scenarios, things that are closer are more relevant, and now there is a simple and effective way to include proximity among the relevance ranking considerations. When searching for information, records that are nearer to a point in time (typically more recent) are typically more relevant. When searching for anything with physical presence, the geographical proximity should typically play a part in defining relevancy. In other words, including proximity (time or geo) in relevance ranking will improve ranking in most scenarios. With Elasticsearch 7.2.0 users can normalize the time or geographical distance using saturation normalization function and add them to the relevance ranking score, using distance feature query to achieve better relevance ranking. This feature already leverages the ‘top-k faster queries’ performance improvement we introduced in 7.0. Read more about this capability and how to configure it in our blog post Distance Feature Query: Time and Geo in Elasticsearch Result Ranking.
Typeahead Search
Those of you that have worked with search systems, probably noticed that getting suggested search results while you type the query can save you a lot of time.
The needs and benefits are thus clear and simple. The engineering challenge is, however, significant: there are typically many words in the index that start with the few letters that the user keyed in, yet the system has but tens of milliseconds to come up with a few top ranking suggestions before the user types in the next letter, potentially with a spelling mistake… This is a clear case in which there is no need to know the number of results or make some aggregation about them, but rather to bring the few top ranking results, typically the ones that are most frequently found in the index. Because only the top ranking results are of interest, we can leverage the ‘top-k faster queries’ mechanism to achieve better performance with lower hardware requirements. The improved performance and reduced consumption of computing resources in turn allows us to do more: in 7.2 we support cases in which the word that the user keyed in is not necessarily the first word in the field, so a user may key in e.g. ‘hem’ and get the suggestion ‘Ernest Hemingway’ from the field.
To achieve that we introduced a new field type -- search_as_you_type -- that is optimized for providing results from the field while the user is typing the query. The number of shingles used is configurable so that any user can balance index size and recall considerations according to their particular needs.
Resiliency Improvements
Elasticsearch used to be, you know, just for search. Nowadays, it is also rapidly becoming the main data repository and analytical system for many users, or in other words, the source of truth. One of the reasons for this change is the system’s reliability and resilience. We at Elastic take this responsibility very seriously, and we keep improving the mechanisms that allow users to deal with malfunctions if they occur, and to do that in an economic manner. Features like replication, snapshot and backup allow our customers to maintain a more reliable service. In 7.2 we added two new mechanisms for that: replicated closed indices and snapshot UI.
Replicated Closed Indices
In 7.2 we have added a layer on top of the closed indices mechanism, that allows replicating closed indices. We made this improvement in response to many users’ requests and as part of our commitment to resiliency and ease of use. We do expect, however, that the majority of our users will be using Frozen Indices instead of Closed Indices. Frozen Indices have nearly no memory footprint, which is the main reason for which users use Closed Indices, but Frozen Indices can be searched almost as if they were open indices, without having to actively manage the logic and workflow of opening and closing the index.
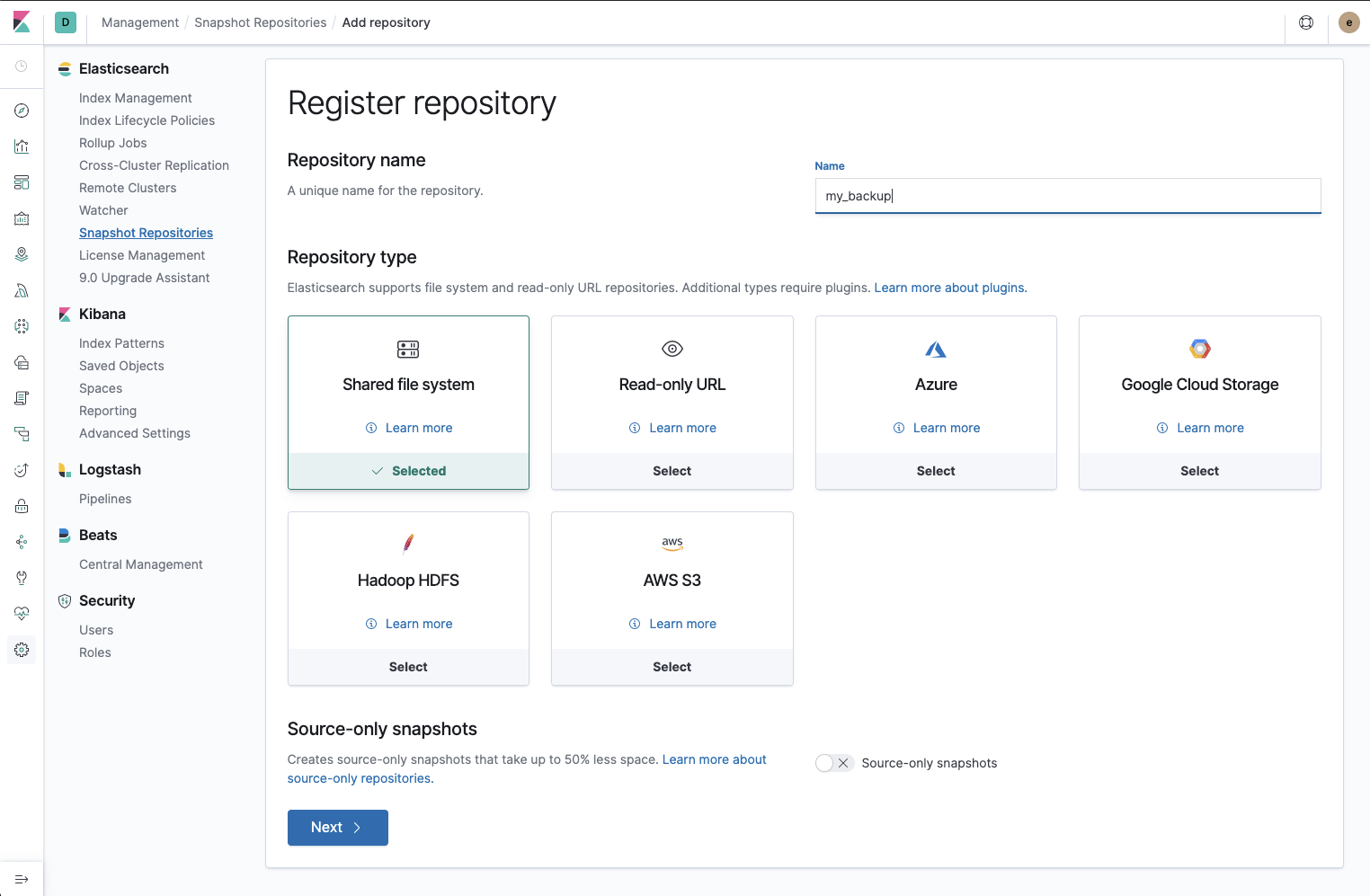
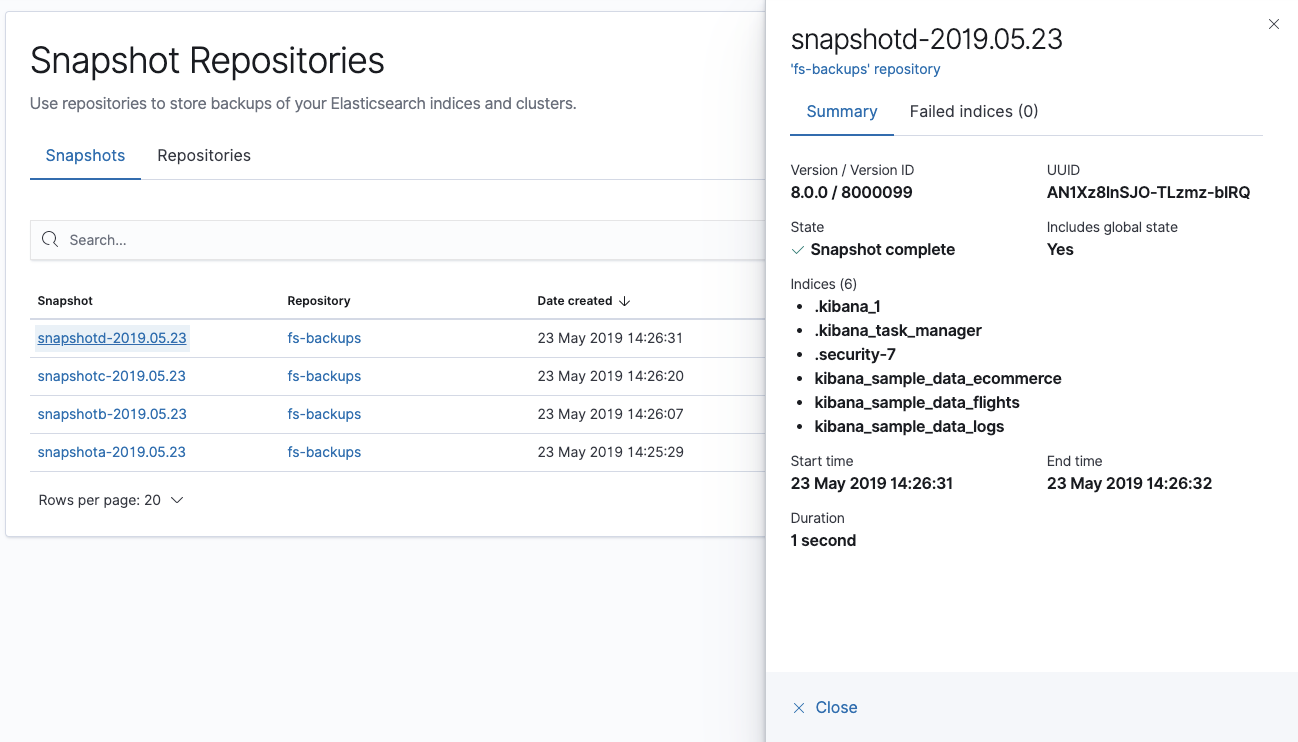
Snapshot Repositories UI
Elasticsearch’s snapshot mechanism allows keeping a backup of data at a point in time, using an efficient incremental snapshotting mechanism.
With 7.2 we added a new Snapshot Repositories app to Kibana. This app allows you to register repositories using all the cloud and on-prem storage plugins. It also allows you to browse the repositories and snapshots that you've created. We plan to enhance this app with functionality for taking, restoring, and deleting snapshots in future releases.
Snapshot Repositories is released under Basic license.
Enhancements to Elasticsearch SQL
The ability to query Elasticsearch using SQL statements has just recently been made generally available as part of Elasticsearch 6.7 and is gaining popularity, in particular with those who are fluent in SQL but new to DSL and in scenarios of integration, including with BI tools, which frequently have built in integration through SQL. In line with its popularity, we keep expanding Elasticsearch’s SQL capabilities. Here are some of the things we added in 7.2:
- Geographical queries through SQL statements
- Median Absolute Deviation, which calculates the median of each data point’s deviation from the median of the whole sample, i.e. for random variable x it is median(|median(x)-xi|)
- CASE/WHEN/ELSE/END to define a set of if-else statements
The above SQL functionality is released under Basic license.
Data Frames
In 7.2 we have added Data Frames, a new plugin that allows you to pivot and aggregate your data from one or multiple indices to a single, separate index. This enables you to transform existing indexed data for specific use-cases. For example, you can now summarize users’ behaviors and gain new insights using a data frame pivot transform.
Data frames are available under Basic license.
HTML Strip Processor
The HTML Strip Processor simply replaces all HTML tags with “\n”. This operation means the _source field contains text that is more readable to humans. If you want to display the source data but not as an HTML, this new processor will probably save you some development time. It’s a fairly frequent case, so we decided to include it in the product.
OpenID Connect Realm
In today’s software world security is a top priority. Unfortunately, security needs sometimes end up burdening users, e.g. by requesting users to authenticate separately to different systems. To avoid that, modern software systems use authentication layers to allow users to roam freely between various systems while automatically identifying themselves to every new system they access and retaining their permissions.
So what is OpenID Connect? OpenID Connect is a commonly used authentication layer on top of oAuth2. oAuth2 is a protocol that allows third-party applications to grant limited access to an HTTP service. OpenID Connect is the authentication backbone used by Okta, Google and others, to allow users to authenticate in the background when moving between connected systems.
OpenID Connect (OIDC) support is widely adopted by enterprise systems, so the newly added support in Elasticsearch and Kibana provides many of our customers with new (but commonly asked for) choices of how to secure their stack.
OpenID support is provided under Platinum license.
Conclusion
Please download Elasticsearch 7.2.0, try it out, and let us know what you think on Twitter (@elastic) or in our forum. You can report any problems on the GitHub issues page.