Replicação entre datacenters com replicação entre clusters do Elasticsearch
A replicação entre datacenters é um requisito para aplicativos de missão crítica no Elasticsearch há algum tempo e anteriormente era resolvida parcialmente com tecnologias adicionais. Com o lançamento da replicação entre clusters no Elasticsearch 6.7, nenhuma tecnologia adicional é necessária para replicar dados em datacenters, regiões geográficas ou clusters do Elasticsearch.
A CCR (replicação entre clusters) permite a replicação de índices específicos de um cluster do Elasticsearch para um ou mais clusters do Elasticsearch. Além da replicação entre datacenters, há uma variedade de casos de uso adicionais para a CCR, incluindo a localidade de dados (a replicação de dados para que residam mais próximos a um servidor de aplicativo/usuário, como a replicação de um catálogo de produtos para 20 datacenters diferentes no mundo inteiro) ou a replicação de um cluster do Elasticsearch para um cluster de relatórios central (p. ex.: 1000 agências bancárias no mundo todo que gravam em seu cluster local do Elasticsearch e replicam de volta para um cluster na sede para fins de relatórios).
Neste tutorial para replicação entre data centers com o CCR, trataremos brevemente sobre os aspectos básicos do CCR, destacaremos as opções de arquitetura e os meios termos, configuraremos uma amostra de implantação entre data centers e destacaremos os comandos administrativos. Introdução à replicação entre clusters no Elasticsearch.
O CCR é um recurso de nível platinum e está disponível por meio da licença de avaliação de 30 dias que pode ser ativada pela API de avaliação inicial ou diretamente no Kibana.
Aspectos básicos da CCR
A replicação é configurada no nível do índice (ou com base em um padrão de índice)
O CCR é configurado no nível do índice no Elasticsearch. Configurando a replicação no nível do índice, há inúmeras estratégias de replicação disponíveis, incluindo a replicação de alguns índices em uma direção, outros índices em outra direção e arquiteturas entre datacenters granulares.
Os índices replicados são somente leitura
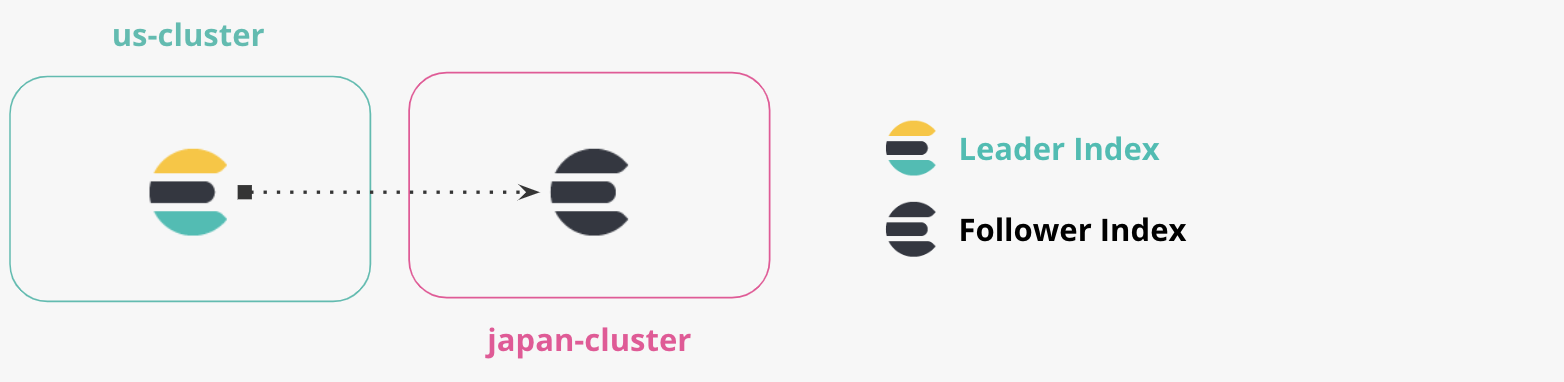
Um índice pode ser replicado por um ou mais clusters do Elasticsearch. Cada cluster que está sendo replicado no índice mantém uma cópia somente leitura do índice. O índice ativo capaz de aceitar gravações é chamado líder. As cópias somente leitura passivas desse índice são chamadas seguidoras. Não existe um conceito de uma eleição para um novo líder; quando um índice líder não está disponível (como em uma falha de cluster/datacenter), outro índice precisa ser escolhido explicitamente para gravações pelo administrador de aplicativo ou cluster (mais provavelmente em outro cluster).
Os padrões do CCR foram escolhidos para uma ampla variedade de casos de uso de alto throughput
Não é recomendável alterar os valores padrão sem um entendimento total de como o ajuste de um valor afetará o sistema. A maioria das opções pode ser encontrada na API seguidora de criação, como "max_read_request_operation_count" ou "max_retry_delay". Em breve publicaremos uma postagem sobre como ajustar esses parâmetros para cargas de trabalho exclusivas.
Requisitos de segurança
Conforme descrito no CCR Getting Started Guide (Guia de introdução ao CCR), o usuário no cluster de origem deve ter o privilégio de cluster “read_ccr”, e os privilégios de índice “monitor” e “read”. No cluster de destino, o usuário deve ter o privilégio “manage_ccr”, e os privilégios de índice “monitor”, “read”, “write” e “manage_follow_index”. Os sistemas de autenticação centralizados também podem ser usados, como LDAP.
Amostras de arquiteturas de CCR entre datacenters
Datacenters de produção e de DR
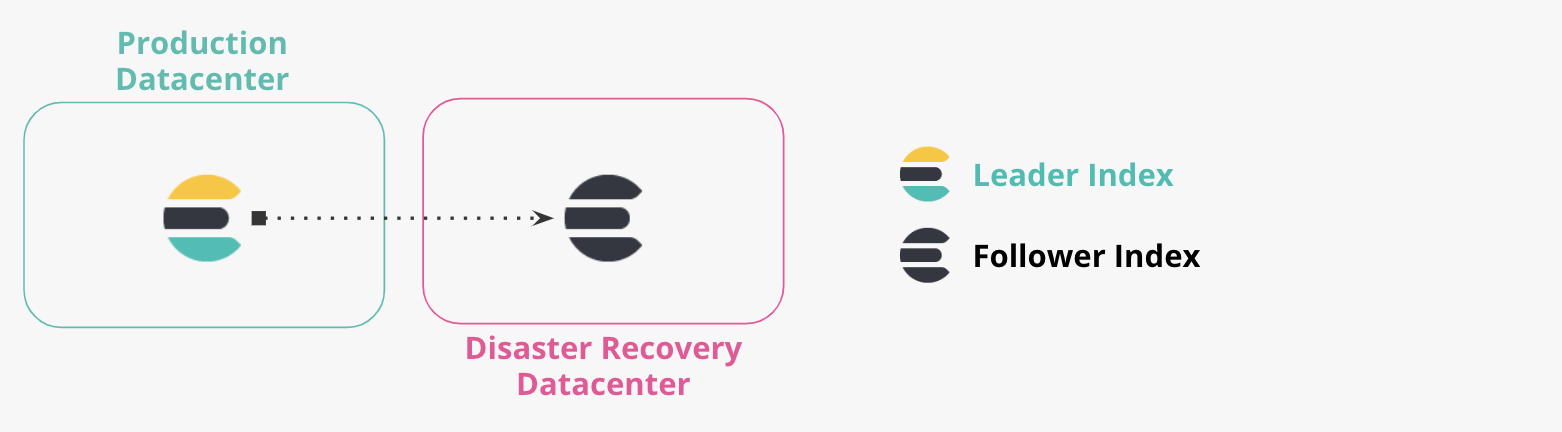
Mais de dois datacenters
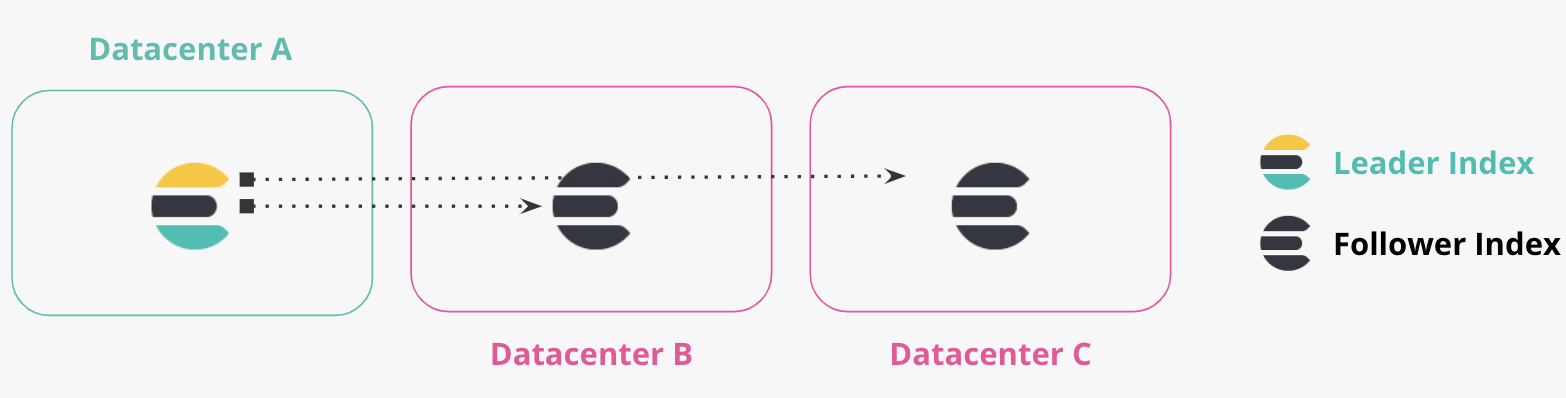
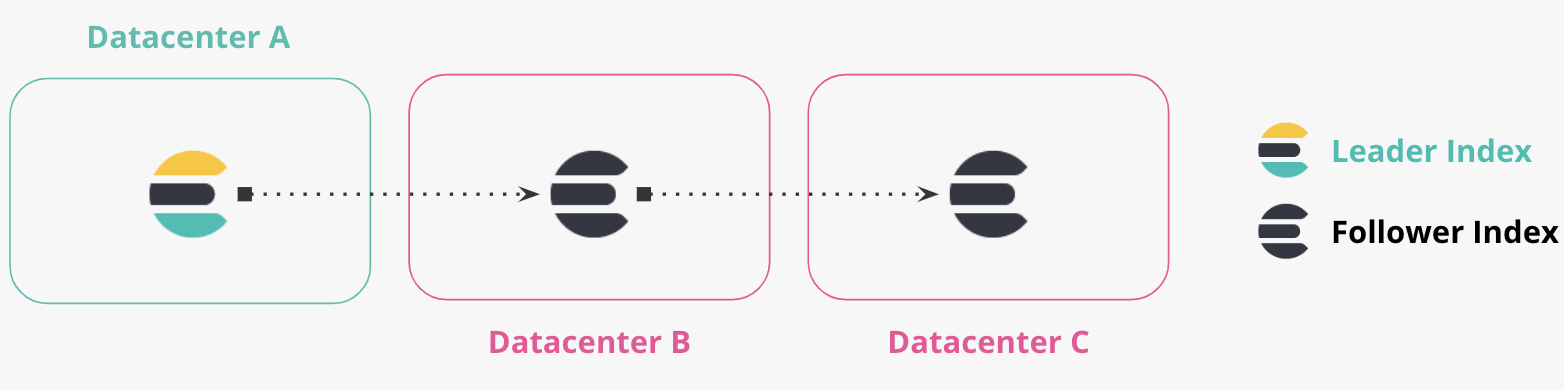
Replicação em cadeia
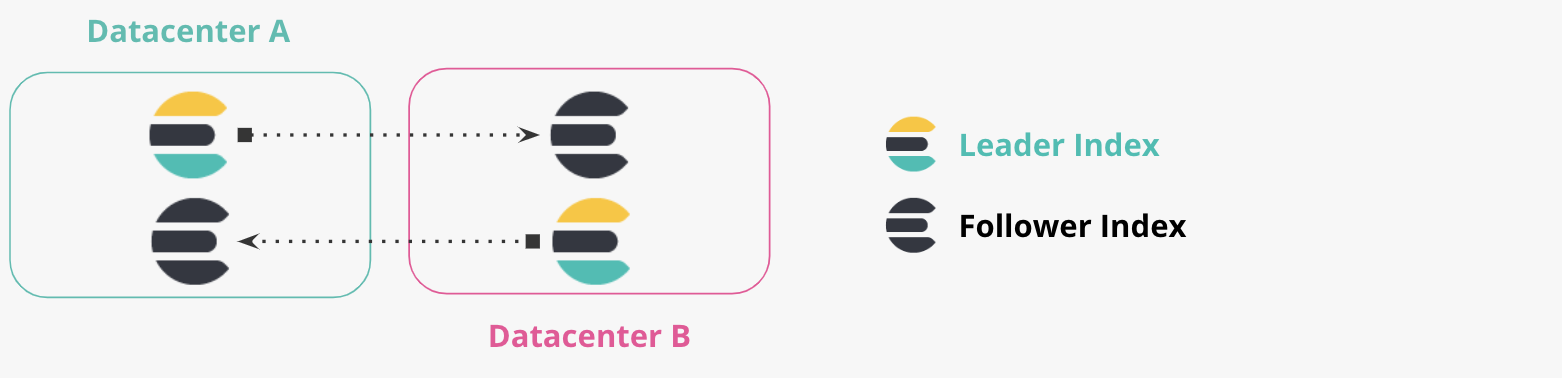
Replicação bidirecional
Tutorial de implantação entre datacenters
1. Instalação
Para este tutorial, usaremos dois clusters e ambos estarão no computador local. Fique à vontade para localizar os clusters em qualquer lugar desejado.
- ‘us-cluster’ : este é o nosso “cluster US ”, e vamos executar localmente na porta 9200. Vamos replicar os documentos do cluster dos EUA para o cluster do Japão.
- ‘japan-cluster’ : este é o nosso "Japan cluster”; vamos executar localmente na porta 8200. O cluster do Japão manterá um índice replicado do cluster dos EUA.
2. Definir os clusters remotos
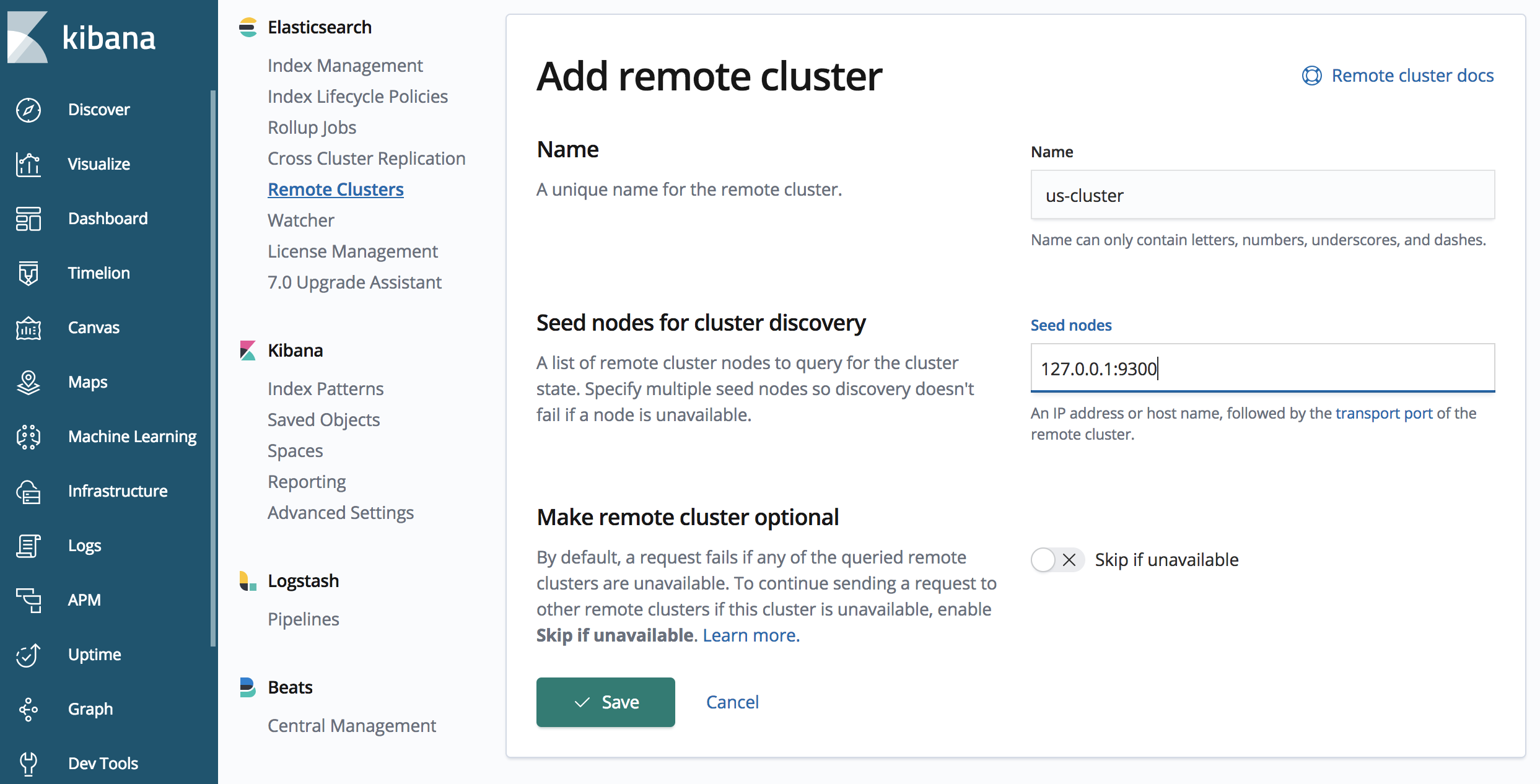
Ao instalar o CCR, os clusters do Elasticsearch devem saber dos outros clusters do Elasticsearch. Esse é um requisito unidirecional, em que o cluster de destino manterá as conexões unidirecionais com o cluster de origem. Definiremos outros clusters do Elasticsearch como clusters remotos e especificaremos um alias para descrevê-los.
Queremos garantir que o nosso ‘japan-cluster’ saiba do ‘us-cluster’. A replicação no CCR se baseia em pull e não exige especificarmos uma conexão do ‘us-cluster’ com o ‘japan-cluster’.
Vamos definir o ‘us-cluster’ por meio de uma chamada à API no ‘japan-cluster’
# No japan-cluster, vamos definir como o us-cluster pode ser acessado
PUT /_cluster/settings
{
"persistent" : {
"cluster" : {
"remote" : {
"us-cluster" : {
"seeds" : [
"127.0.0.1:9300"
]
}
}
}
}
}
(Para comandos baseados em API, recomendamos usar o console de ferramentas de desenvolvimento no Kibana, que pode ser encontrado por meio de Kibana -> Dev tools -> Console)
A chamada à API anterior define um cluster remoto com alias “us-cluster” que pode ser acessado em "127.0.0.1:9300". Um ou mais seeds podem ser especificados, e geralmente é recomendável especificar mais de um para o caso de um seed não estar disponível durante a fase de handshake.
Mais detalhes sobre como configurar clusters remotos podem ser encontrados em nossa documentação de referência sobre como definir um cluster remoto.
Também é importante observar a porta 9300 para conexão com o ‘us-cluster’; o ‘us-cluster’ está escutando o protocolo HTTP na porta 9200 (como é o padrão, e especificado no arquivo elasticsearch.yml para o nosso 'us-cluster'). Entretanto, a replicação ocorre usando o protocolo de transporte do Elasticsearch (para comunicação entre nós); o padrão é a porta 9300.
Há uma IU de gerenciamento para clusters remotos no Kibana; neste tutorial vamos apresentar a IU e a API para o CCR. Para acessar a IU de cluster remoto no Kibana, clique em “Management” (ícone de engrenagem) no painel de navegação esquerdo e navegue para “Remote Clusters” (Clusters remotos) na seção Elasticsearch.
3. Criar um índice para replicação
Vamos criar um índice chamado ‘products’ em nosso ‘us-cluster’, vamos replicar esse índice do nosso ‘us-cluster’ de origem para o ‘japan-cluster’ de destino:
No ‘us-cluster’:
# Criar índice do produto
PUT /products
{
"settings" : {
"index" : {
"number_of_shards" : 1,
"number_of_replicas" : 0,
"soft_deletes" : {
"enabled" : true
}
}
},
"mappings" : {
"_doc" : {
"properties" : {
"name" : {
"type" : "keyword"
}
}
}
}
}
Talvez você tenha percebido a configuração “soft_deletes”. As exclusões suaves são necessárias para que um índice atue como índice líder para o CCR (consulte Those Who Don’t Know History para saber mais):
soft_deletes: Uma exclusão suave ocorre sempre que um documento existente é excluído ou atualizado. Retendo essas exclusões suaves até limites configuráveis, o histórico de operações pode ser retido nos shards líderes e disponibilizados às tarefas de shard seguidor à medida que ele reproduz o histórico de operações.
Como os shards seguidores replicam operações do líder, ele deixará marcadores nos shards líderes para que os líderes saibam onde no histórico os seguidores estão. As operações de exclusão suave abaixo desses marcadores são qualificadas para serem mescladas. Acima desses marcadores, os shards líderes reterão essas operações durante o período de arrendamento de retenção do histórico de um shard, que tem como padrão doze horas. Esse período determina a quantidade de tempo em que um seguidor pode estar offline antes de estar sob risco de falhar fatalmente bem atrás e precisando fazer novo bootstrap do líder.
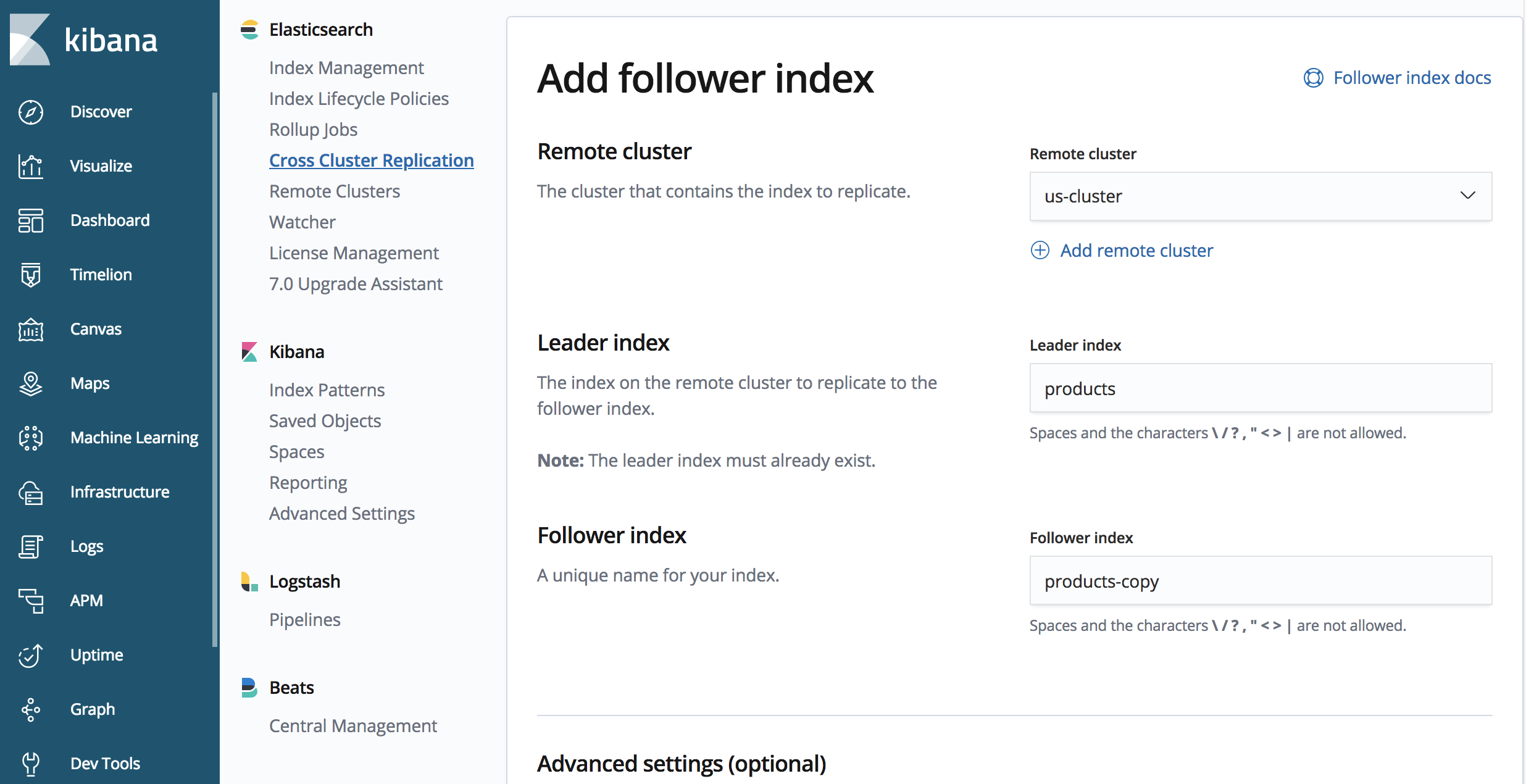
4. Iniciar replicação
Agora que criamos um alias para o nosso cluster remoto e criamos um índice que gostaríamos de replicar, vamos iniciar a replicação.
Em nosso ‘japan-cluster’:
PUT /products-copy/_ccr/follow
{
"remote_cluster" : "us-cluster",
"leader_index" : "products"
}
O endpoint contém ‘products-copy’, que é o nome do índice replicado no cluster ‘japan-cluster’. Estamos replicando do cluster ‘us-cluster’ que definimos anteriormente, e o nome do índice que estamos replicando é chamado ‘products’ no cluster ‘us-cluster’.
É importante observar que o nosso índice replicado é somente leitura e não pode aceitar operações de gravação.
E é isso! Configuramos um índice para replicar de um cluster do Elasticsearch para outro!
Iniciar replicação para padrões de índice
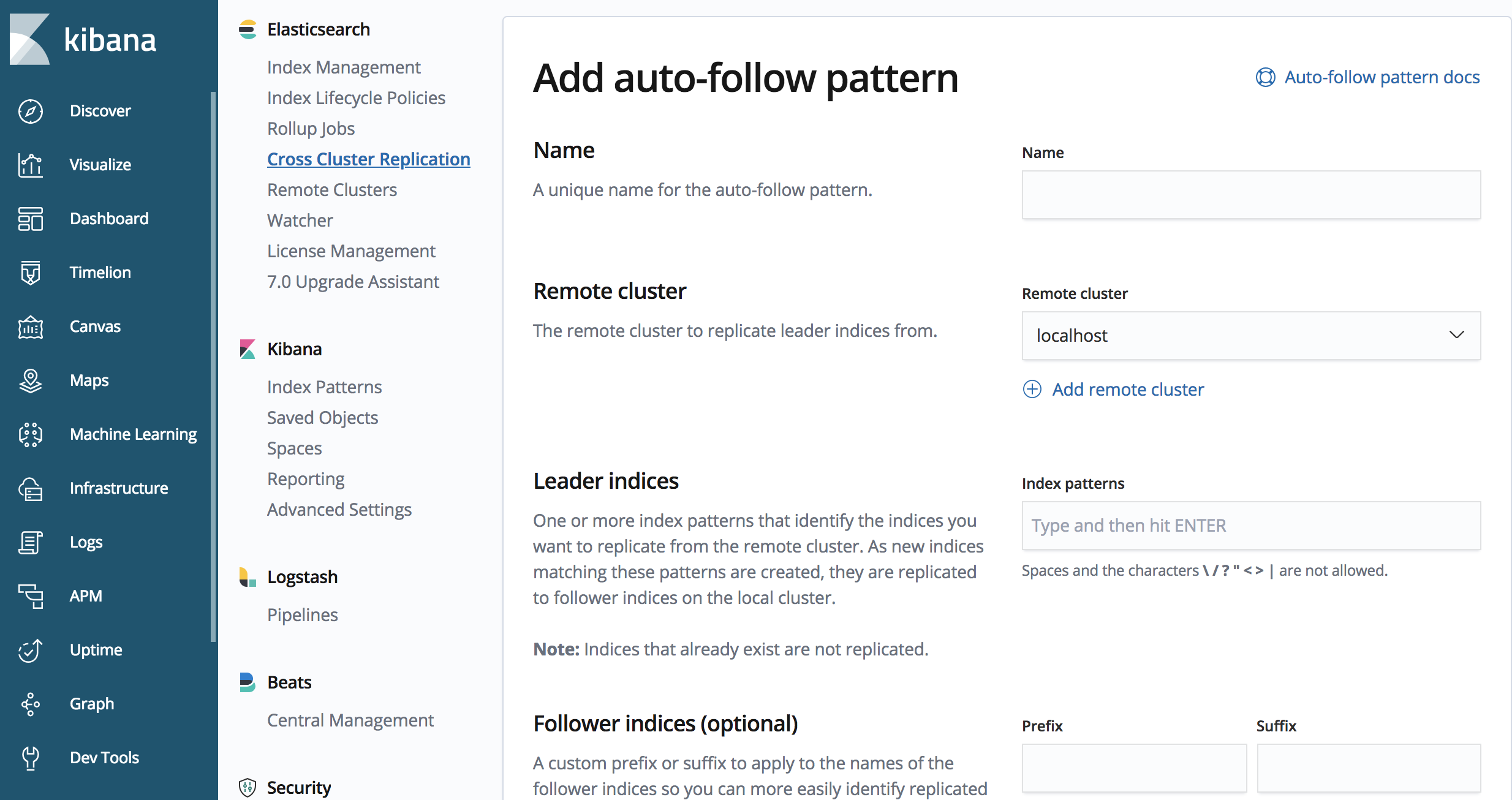
Você pode ter reparado que o exemplo anterior não funcionará muito bem para casos de uso baseados em tempo, em que há um índice por dia ou para uma quantidade de dados. A API do CCR também contém métodos para definir padrões de autoseguimento, ou seja, quais padrões de índice devem ser replicados.
Podemos usar a API do CCR para definir um padrão de autoseguimento
PUT /_ccr/auto_follow/beats
{
"remote_cluster" : "us-cluster",
"leader_index_patterns" :
[
"metricbeat-*",
"packetbeat-*"
],
"follow_index_pattern" : "{{leader_index}}-copy"
}
A amostra de chamada à API anterior replicará um índice que começa com ‘metricbeat’ ou ‘packetbeat’.
Também podemos usar a IU do CCR no Kibana para definir um padrão de autoseguimento.
5. Teste de instalação de replicação
Agora que temos o índice dos nossos produtos replicado do ‘us-cluster’ para o ‘japan-cluster’, vamos inserir um documento de teste e verificar se ele foi replicado.
No cluster ‘us-cluster’:
POST /products/_doc
{
"name" : "My cool new product"
}
Agora vamos consultar o ‘japan-cluster’ para garantir que o documento foi replicado:
GET /products-copy/_search
Devemos ter um único documento presente, que foi gravado no ‘us-cluster’ e replicado para o ‘japan-cluster’.
{
"took" : 1,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : 1,
"max_score" : 1.0,
"hits" : [
{
"_index" : "products-copy",
"_type" : "_doc",
"_id" : "qfkl6WkBbYfxqoLJq-ss",
"_score" : 1.0,
"_source" : {
"name" : "My cool new product"
}
}
]
}
}
Obervações de administração entre datacenters
Vamos analisar algumas APIs administrativas para o CCR, configurações ajustáveis, e vamos descrever o método para converter um índice replicado para um índice normal no Elasticsearch.
APIs administrativas para replicação
Há inúmeras APIs administrativas úteis para o CCR no Elasticsearch. Elas podem ser úteis em depurar a replicação, modificar configurações de replicação ou reunir diagnósticos detalhados.
# Retornar todas as estatísticas relacionadas ao CCR
GET /_ccr/stats
# Pausar replicação para um determinado índice
POST //_ccr/pause_follow
# Retomar replicação, na maioria dos casos depois que ela foi pausada
POST //_ccr/resume_follow
{
}
# Desacompanhar um índice (parar a replicação para o índice de destino), que primeiramente exige que a replicação esteja pausada
POST //_ccr/unfollow
# Estatísticas para um índice seguidor
GET //_ccr/stats
# Remover um padrão de autoseguimento
DELETE /_ccr/auto_follow/
# Exibir todos os padrões de autoseguimento ou obter um padrão de autoseguimento por nome
GET /_ccr/auto_follow/
GET /_ccr/auto_follow/
Mais detalhes sobre as APIs administrativas do CCR estão disponíveis na documentação de referência do Elasticsearch.
Conversão de um índice seguidor em um índice normal
Podemos usar um subconjunto das APIs administrativas anteriores para converter um índice seguidor em um índice normal no Elasticsearch, capaz de aceitar gravações.
Em nosso exemplo anterior, tínhamos uma instalação bem simples. Lembre-se de que o índice ‘products-copy’ replicado em nosso ‘japan-cluster’ é somente leitura e não pode aceitar gravações. Na hipótese de querermos converter o índice ‘products-copy’ em um índice normal no Elasticsearch (capaz de aceitar gravações), poderemos executar os comandos a seguir. Lembre-se de que as gravações em nosso índice original ('products') pode continuar, e queremos restringir as gravações primeiro ao nosso índice ‘products’, antes de converter nosso índice ‘products-copy’ para um índice normal do Elasticsearch.
# Pausar replicação
POST //_ccr/pause_follow
# Fechar o índice
POST /my_index/_close
# Desacompanhar
POST //_ccr/unfollow
# Abrir o índice
POST /my_index/_open
Continuar análise de CCR no Elasticsearch
Elaboramos este guia para ajudá-lo a começar com o CCR no Elasticsearch e esperamos que ele seja suficiente para você se familiarizar com o CCR, conhecer as várias APIs do CCR (incluindo as IUs disponíveis no Kibana) e experimentar o recurso. Entre os recursos adicionais estão o guia de introdução à replicação entre clusters e o guia de referência das APIs de replicação entre clusters.
Como sempre, faça seus comentários em nossos fóruns de discussão e envie dúvidas, pois certamente as responderemos assim que for possível.