인덱스 수명 주기 관리를 통해 Hot-Warm-Cold 아키텍처 구현
참고: 이 문서에 설명된 대로 노드 속성을 사용하여 hot-warm-cold 아키텍처를 구현하는 방식은 더 이상 권장되지 않습니다(즉, -Enode.attr.data=hot). 데이터 #티어는 node.roles를 사용함으로써 이 개념을 공식화했습니다(즉, node.roles: ["data_hot", "data_content"]). 업데이트된 정보는 https://www.elastic.co/blog/elasticsearch-data-lifecycle-management-with-data-tiers를 참조하세요.
노드 속성을 사용하여 hot-warm-cold 아키텍처를 이미 구현한 경우 데이터 티어에 node.roles를 적용한 다음 데이터 티어 API로 마이그레이션하거나 구성(즉, ILM 정책, 인덱스 설정, 인덱스 템플릿)을 직접 변환하여 데이터 티어 기본 설정을 사용하는 것이 좋습니다.
또한 이 문서에서는 레거시 인덱스 템플릿(즉, PUT _template)과 인덱스 부트스트랩의 필요성에 대한 참조를 제공합니다. 레거시 인덱스 템플릿은 구성 가능한 인덱스 템플릿(즉, PUT /_index_template)으로 대체되었으며 데이터 스트림을 사용하는 경우 인덱스를 부트스트랩할 필요가 없습니다.
인덱스 수명 주기 관리(ILM)는 Elasticsearch 6.6(베타)에서 처음 소개되었으며 6.7에서 공식 출시된 기능입니다. ILM은 Elasticsearch의 일부로, 인덱스 관리를 돕도록 설계되었습니다.
이 블로그에서는 ILM을 사용하여 hot-warm-cold 아키텍처를 구현하는 방법을 살펴보겠습니다. Hot-warm-cold 아키텍처는 로깅 또는 메트릭과 같은 시계열 데이터에 일반적으로 사용됩니다. 예를 들어 Elasticsearch를 사용하여 여러 시스템에서 로그 파일을 집계한다고 가정해 보겠습니다. 오늘 로그는 활발하게 색인되고 있으며 이번 주 로그는 가장 많이 검색됩니다(hot). 지난주 로그는 검색되기는 하지만 이번 주 로그만큼 자주 검색되지는 않습니다(warm). 지난달 로그는 자주 검색되지 않을 수 있지만 만약의 경우를 대비하여 유지하는 것이 좋습니다(cold).
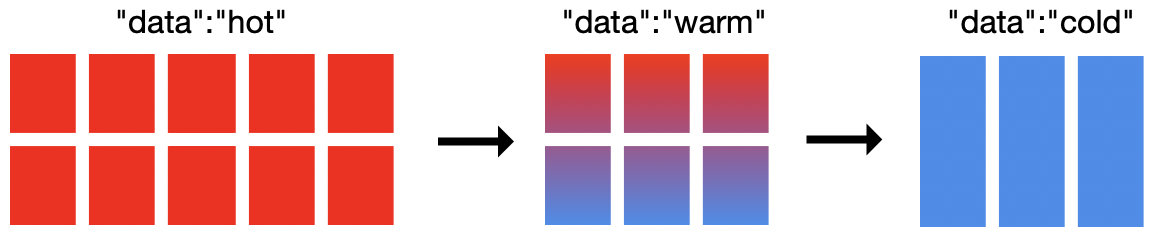
위 그림을 보면 이 클러스터에는 19개의 노드(hot 노드 10개, warm 노드 6개, cold 노드 3개)가 있습니다. ILM을 사용하여 hot-warm-cold를 구현하는 데 19개의 노드가 필요하지는 않으며, 최소 2개의 노드면 됩니다. 클러스터 크기 조정 방법은 요구 사항에 따라 다릅니다. Cold 노드는 선택 사항이며 데이터 저장 모델에 레벨을 하나 더 제공합니다. Elasticsearch를 사용하면 어떤 노드가 hot, warm 또는 cold 노드인지 정의할 수 있습니다. ILM을 사용하면 단계 간에 이동할 시점과 해당 단계에 진입할 때 인덱스를 사용해 수행할 작업을 정의할 수 있습니다.
hot-warm-cold 아키텍처에서 모든 상황에 맞는 한 가지 접근 방식은 없습니다. 그러나 일반적으로 hot 노드에는 더 많은 CPU 리소스와 더 빠른 IO가 필요하며, Warm 및 cold 노드에는 일반적으로 노드당 더 많은 디스크 공간이 필요하지만 CPU는 더 적어도 되고 IO는 더 느려도 괜찮습니다.
자, 그럼 시작해보죠...
샤드 할당 인식 구성
hot-warm-cold는 샤드 할당 인식을 사용하므로 우선 어떤 노드가 hot, warm, cold(선택 사항) 노드인지 레이블을 지정합니다. 이 작업은 스타트업 파라미터를 통해 또는 elasticsearch.yml 구성 파일에서 수행할 수 있습니다. 예를 들어 다음과 같습니다.
bin/elasticsearch -Enode.attr.data=hot
bin/elasticsearch -Enode.attr.data=warm
bin/elasticsearch -Enode.attr.data=cold
(Elastic Cloud의 Elasticsearch Service를 사용하는 경우 Elasticsearch 6.7+로 hot/warm 템플릿을 선택해야 합니다.)
ILM 정책 구성
다음으로, ILM 정책을 정의해야 합니다. ILM 정책은 원하는 수만큼 많은 인덱스에서 재사용할 수 있습니다. ILM 정책은 hot, warm, cold 및 delete의 네 가지 기본 단계로 나뉩니다. 정책의 모든 단계를 정의할 필요는 없으며 ILM은 항상 이 순서대로 단계를 실행합니다(정의되지 않은 단계는 생략). 각 단계에 대해 해당 단계 진입 시점과 인덱스를 관리하는 일련의 작업을 원하는 대로 정의합니다. Hot-warm-cold 아키텍처의 경우 할당 작업을 통해 hot 노드에서 warm 노드로, warm 노드에서 cold 노드로 데이터를 이동하도록 구성할 수 있습니다.
hot-warm-cold 노드 간에 데이터를 이동하는 것 외에도 구성할 수 있는 추가 작업이 많이 있습니다. 롤오버 작업은 각 인덱스의 크기 또는 기간을 관리하는 데 사용합니다. 강제 병합 작업은 인덱스를 최적화하는 데 사용할 수 있습니다. 고정 작업은 클러스터의 메모리 부담을 줄이는 데 사용할 수 있습니다. 그 외에도 많은 작업이 지원되므로 설명서에서 Elasticsearch 버전별로 사용 가능한 작업을 참조하시기 바랍니다.
기본 ILM 정책
매우 기본적인 ILM 정책을 살펴보겠습니다.
PUT /_ilm/policy/my_policy
{
"policy":{
"phases":{
"hot":{
"actions":{
"rollover":{
"max_size":"50gb",
"max_age":"30d"
}
}
}
}
}
}
이 정책에는 30일 후 또는 인덱스의 크기가 50gb에 도달하면(기본 샤드를 기준으로) 인덱스를 롤오버하고 새 인덱스에 쓰기 시작한다고 명시되어 있습니다.
ILM 및 인덱스 템플릿
다음으로, 해당 ILM 정책을 인덱스 템플릿에 연결해야 합니다.
PUT _template/my_template
{
"index_patterns": ["test-*"],
"settings": {
"index.lifecycle.name": "my_policy",
"index.lifecycle.rollover_alias": "test-alias"
}
}
참고: 롤오버 작업을 사용할 때는 ILM 정책을 인덱스에 직접 지정하는 것이 아니라 인덱스 템플릿에 지정해야 합니다.
롤오버 작업이 포함된 정책의 경우, 인덱스 템플릿을 생성한 후 쓰기 별칭으로 인덱스를 부트스트랩해야 합니다.
PUT test-000001
{
"aliases": {
"test-alias":{
"is_write_index": true
}
}
}
롤오버에 대한 모든 요구 사항이 충족되면 test-*로 시작하는 모든 새 인덱스가 30일 후 또는 50gb에 도달한 후 자동으로 롤오버됩니다. max_size가 포함된 롤오버 관리형 인덱스를 사용하면 인덱스의 샤드 수를(즉, 오버헤드) 크게 줄일 수 있습니다.
수집을 위한 ILM 정책 구성
Beats 및 Logstash는 ILM을 지원하며, 활성화되면 위의 예와 유사한 기본 정책을 설정합니다. 또한, Beats 및 Logstash는 롤오버 작업에 대한 모든 요구 사항도 처리합니다. 즉, Beats 및 Logstash에서 ILM이 활성화된 경우 일일 인덱스 크기가 크지 않은 한(>50gb/일), 크기가 새로운 인덱스가 생성되는 시점을 결정하는 주요 요인이 될 수 있습니다. 그리고 이는 좋은 일입니다! 롤오버가 구성된 ILM은 7.0.0부터 Beats 및 Logstash의 기본값이 됩니다.
그러나 hot-warm-cold 아키텍처에서 모든 상황에 맞는 한 가지 접근 방식은 없으므로, Beats 및 Logstash는 hot-warm-cold 정책을 제공하지 않습니다. Elastic에서는 hot-warm-cold에 적합한 새로운 정책을 만들고 있으며 현재 최적화 작업을 진행하고 있습니다.
Beats 또는 Logstash 기본 정책을 업데이트할 수도 있지만, 그렇게 하면 기본 정책과 사용자 정의 정책 간에 경계가 모호해집니다. 또한, 기본 정책을 업데이트하면 이후 버전에서 올바른 정책이 적용되지 않을 위험이 있습니다*(7.0+에서 Beats 템플릿 기본 정책이 변경됨)*. Beats 및 Logstash 구성을 사용하여 해당 구성을 통해 사용자 정의 정책을 정의하는 방법도 있습니다. 이 또한 효과가 있지만 ILM 정책을 변경하기 위해 수백(또는 수천)의 Beats 구성을 변경하고 싶지는 않으실 것입니다. 여기에 설명된 세 번째 접근 방식은 여러 템플릿 별칭을 활용하여 Elasticsearch가 ILM 정책을 완전히 제어할 수 있도록 하는 것입니다.
hot-warm-cold에 맞게 ILM 정책 최적화
먼저, hot-warm-cold 아키텍처에 맞게 최적화된 ILM 정책을 만들어 보겠습니다. 다시 말씀드리지만, 모든 상황에 맞는 한 가지 접근 방식은 없으며, 요구 사항이 다를 가능성이 큽니다.
PUT _ilm/policy/hot-warm-cold-delete-60days
{
"policy": {
"phases": {
"hot": {
"actions": {
"rollover": {
"max_size":"50gb",
"max_age":"30d"
},
"set_priority": {
"priority": 50
}
}
},
"warm": {
"min_age": "7d",
"actions": {
"forcemerge": {
"max_num_segments": 1
},
"shrink": {
"number_of_shards": 1
},
"allocate": {
"require": {
"data": "warm"
}
},
"set_priority": {
"priority": 25
}
}
},
"cold": {
"min_age": "30d",
"actions": {
"set_priority": {
"priority": 0
},
"freeze": {},
"allocate": {
"require": {
"data": "cold"
}
}
}
},
"delete": {
"min_age": "60d",
"actions": {
"delete": {}
}
}
}
}
}
Hot
이 ILM 정책은 hot 인덱스가 다른 인덱스보다 먼저 복구되도록 인덱스 우선순위를 높은 값으로 설정하는 것으로 시작합니다. 30일 후 또는 50gb에 도달하면(둘 중 먼저 충족하는 조건이 적용됨) 인덱스가 롤오버되고 새 인덱스가 생성됩니다. 이 새 인덱스는 정책을 처음부터 다시 시작하며, 현재 인덱스(방금 롤오버된 인덱스)는 롤오버된 후 최대 7일 동안 기다렸다가 warm 단계로 진입합니다.
Warm
인덱스가 warm 단계로 진입하면 ILM이 인덱스를 샤드 1개로 축소하고, 인덱스를 세그먼트 1개로 강제 병합하고, hot보다 낮은 값으로 인덱스 우선순위를 설정하여 할당 작업을 통해 인덱스를 warm 노드로 옮깁니다. 이동이 완료되면 30일(롤오버된 후)을 기다렸다가 cold 단계로 진입합니다.
Cold
인덱스가 cold 단계로 진입하면 ILM이 다시 한번 인덱스 우선순위를 낮춰 hot 및 warm 인덱스가 먼저 복구되도록 합니다. 그런 다음 인덱스를 고정하고 cold 노드로 옮깁니다. 이동이 완료되면 60일(롤오버된 후)을 기다렸다가 delete 단계로 진입합니다.
Delete
Delete 단계에 대해서는 아직 설명하지 않았는데요. 간단히 말해...delete 단계는 인덱스를 삭제하는 삭제 작업을 말합니다. 주어진 기간 동안 인덱스가 hot, warm 또는 cold 단계에 유지될 수 있도록 항상 삭제 단계에 대한 min_age를 지정해야 합니다.
Kibana 내에서 ILM 정책 생성
JSON 문서를 작성하는 것이 내키지 않으신가요? (저도 마찬가지입니다.) 다음과 같이 Kibana UI를 사용하여 정책을 검사하거나 생성할 수 있습니다.
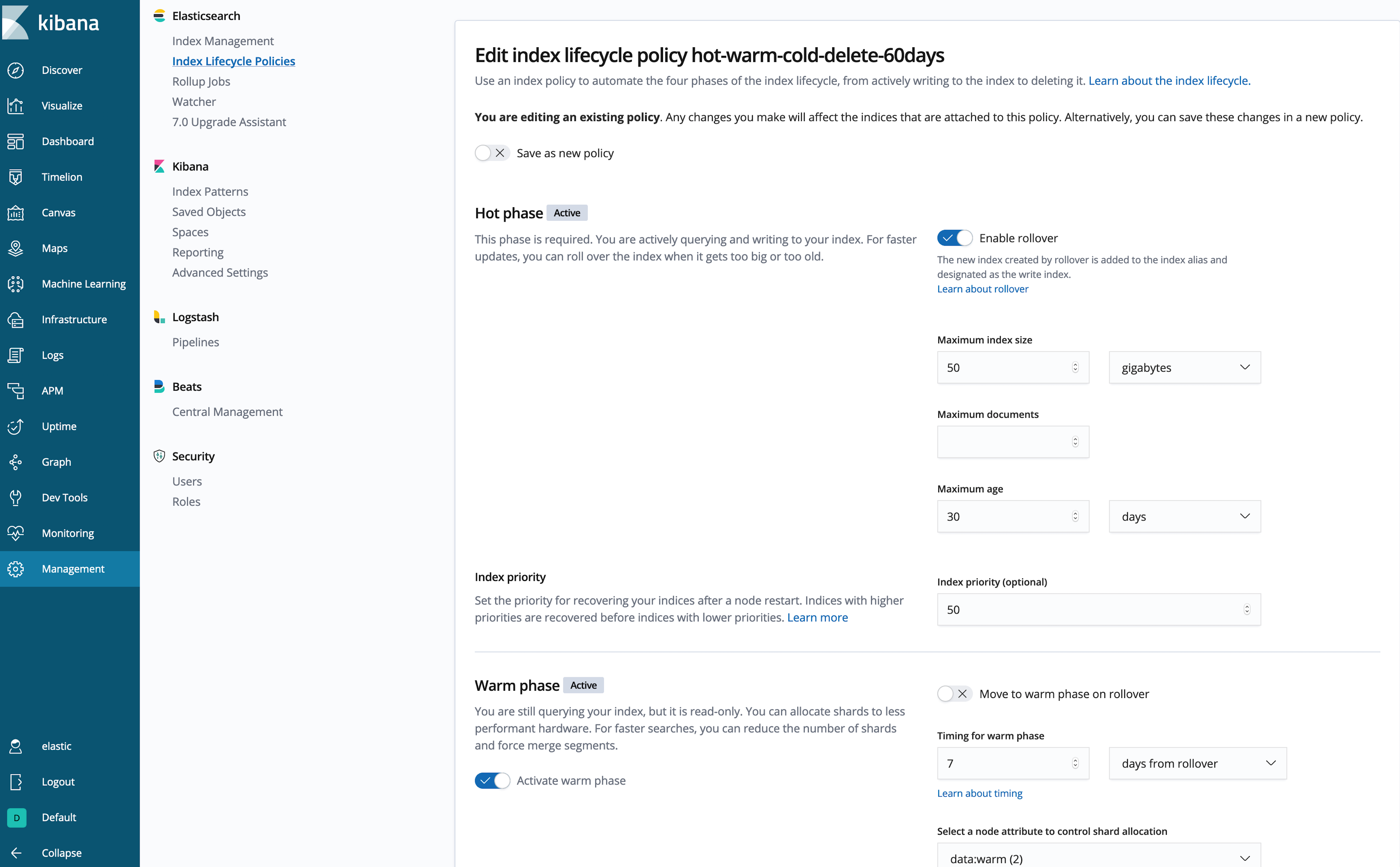 훨씬 낫군요!
훨씬 낫군요!
이제 새로운 hot-warm-cold-delete-60days 정책을 Beats 및 Logstash 인덱스에 연결하고 이러한 인덱스가 hot 데이터 노드에 작성되고 있는지 확인해야 합니다. Beats 및 Logstash는 모두 기본적으로 자체 템플릿을 관리하므로 우리는 여러 템플릿 매칭을 사용하여 ILM 정책을 적용하려는 인덱스 패턴에 대한 정책 및 할당 규칙을 추가하겠습니다. 이 템플릿은 Beats 및 Logstash 인덱스 패턴과 매칭되므로 어떤 인덱스 패턴을 매칭할지 알아야 합니다. 여기서는 logstash-, metricbeat-, filebeat-*를 사용합니다. Beats 및 Logstash가 구성에서 ILM 지원을 활성화했다는 가정하에 여기에 원하는 만큼 추가할 수 있습니다. ILM을 지원하지 않는 데이터 생산자의 인덱스 패턴을 여기에 추가하는 경우 이 정책의 롤오버 요구 사항을 수동으로 충족해야 합니다.
PUT _template/hot-warm-cold-delete-60days-template
{
"order": 10,
"index_patterns": ["logstash-*", "metricbeat-*", "filebeat-*"],
"settings": {
"index.routing.allocation.require.data": "hot",
"index.lifecycle.name": "hot-warm-cold-delete-60days"
}
}
Beats 및/또는 Logstash에서 ILM 활성화
마지막으로, Beats 및/또는 Logstash에서 ILM을 활성화해 보겠습니다.
6.7 Beats의 경우:
output.elasticsearch:
ilm.enabled: true
6.7 Logstash의 경우:
output {
elasticsearch {
ilm_enabled => true
}
}
새로운 버전에서는 Beats 및 Logstash에서 ILM을 활성화하는 방법이 변경될 수 있으므로 해당 버전의 설명서를 참조하시기 바랍니다.
이제 인덱스 패턴과 매칭되는 모든 새 인덱스가 hot 노드에 새 인덱스를 생성하고 ILM이 hot-warm-cold-delete-60days 정책을 적용합니다.
ILM 정책 업데이트
언제든지 ILM 정책을 업데이트할 수 있습니다... 그러나 정책에 대한 변경 사항은 단계가 바뀔 때만 적용됩니다. 예를 들어, 인덱스가 현재 hot 단계에 있고 warm 단계를 기다리는 경우, hot 단계에 대한 변경 사항은 해당 인덱스에 적용되지 않지만 warm 단계에 대한 변경 사항은 해당 단계에 진입할 때 적용됩니다. 이렇게 하는 이유는 주어진 단계에 대해 작업이 반복되지 않도록 하기 위해서입니다. explain API를 통해 인덱스의 ILM 상태를 볼 수 있습니다.
ILM이 출시되기 이전의 hot-warm 아키텍처를 구현하는 방법에 대한 대부분의 이전 정보는 여전히 유효합니다. 동일한 기본 메커니즘을 사용하기 때문입니다. 그러나 이제 ILM을 사용하면 큐레이터 없이도 이 패턴을 달성할 수 있습니다.
향후 계획
버전 7.0부터 Beats 및 Logstash에서는 수명 주기 관리를 지원하는 클러스터에 연결할 때 기본적으로 인덱스 수명 주기 관리를 사용합니다. 또한 Beats에서는 대부분의 ILM 설정이 output.elasticsearch.ilm 네임스페이스에서 setup.ilm 네임스페이스로 이동되었습니다. 예제는 7.0 Filebeat 설명서를 참조하시기 바랍니다. 그리고 7.0부터 .watcher-history-*와 같은 시스템 인덱스도 ILM에서 관리할 수 있습니다.
ILM을 사용하면 시계열 인덱스에 대해 hot-warm-cold와 같은 비용 절감 아키텍처를 쉽게 구현할 수 있습니다. 지금 사용해 보시고 토론 포럼에 피드백을 남겨주세요. 즐겁게 사용하셨으면 합니다!