Kibana에서 Vega 시각화 시작하기
Vega 선언적 문법은 사용자의 데이터를 시각화하는 강력한 방법입니다. Kibana 6.2의 새로운 기능을 통해 사용자는 이제 자신의 Elasticsearch 데이터를 통해 풍부한 Vega 및 Vega-Lite 시각화를 구현할 수 있습니다. 그러면, 몇 가지 간단한 예제를 통해 Vega 언어를 배워 보겠습니다.
먼저, 원시 Vega(Elasticsearch 사용자 정의가 적용되지 않음)를 실험하는 데 편리한 도구인 Vega 편집기를 열어 보겠습니다. 아래 코드를 복사하면 오른쪽 패널에 "Hello Vega!" 텍스트가 나타날 것입니다.

{
"$schema": "https://vega.github.io/schema/vega/v3.json",
"width": 100, "height": 30,
"background": "#eef2e8",
"padding": 5,
"marks": [
{
"type": "text",
"encode": {
"update": {
"text": { "value": "Hello Vega!" },
"align": { "value": "center"},
"baseline": { "value": "middle"},
"stroke": { "value": "#A32299" },
"angle": { "value": 15 },
"x": { "signal": "width/2" },
"y": { "signal": "height/2" }
}
}
}
]
}
마크 블록은 텍스트, 라인, 직사각형과 같은 일련의 드로잉 기본 형식입니다. 각 마크에는 인코딩 집합 내에 지정된 다수의 매개 변수가 있습니다. 각 매개 변수는 “업데이트” 단계에서 상수(값) 또는 계산 결과(신호) 중 하나로 설정됩니다. 텍스트 마크의 경우, 우리는 텍스트 스트링을 지정하고, 텍스트의 주어진 좌표상의 위치, 회전, 텍스트 색상 설정이 제대로 되었는지 확인합니다. ‘x’ 및 ‘y’ 좌표는 그래프의 너비와 높이에 근거하여 계산되며, 텍스트를 가운데에 위치시킵니다. 그 밖에도 많은 텍스트 마크 매개 변수가 있습니다. 또한 대화형 텍스트 마크 데모 그래프도 있어 다른 매개 변수 값을 적용해 볼 수 있습니다.
$schema는 필수 Vega 엔진 버전의 ID입니다. Background에서 그래프를 불투명하게 합니다. width와 height는 초기 드로잉 캔버스 크기를 설정합니다. 어떤 경우에는 최종 그래프 크기가 콘텐츠와 자동 크기 조정 옵션에 따라 변할 수도 있습니다. Kibana의 기본 autosize는 pad가 아니라 ‘fit’이며, 따라서 height와 width는 옵션이 됩니다. 너비와 높이 이외에도, padding 매개 변수가 그래프 주변에 약간의 공간을 추가합니다.
데이터 기반 그래프
다음 단계는 직사각형 마크를 활용해 데이터 기반 그래프를 그리는 것입니다. 데이터 섹션은 여러 데이터 소스를 하드코딩하거나 URL로 이용할 수 있게 합니다. Kibana에서는 직접 Elasticsearch 쿼리를 이용할 수도 있습니다. 우리의 vals 데이터 테이블에는 4개의 행과 category 및 count의 2개의 열이 있습니다. category를 사용하여 막대를 x 축에 위치시키고, count로 막대의 높이를 정하겠습니다. y 좌표가 0이면 맨 위쪽이며, 증가할수록 아래쪽을 향한다는 점에 유의하십시오.
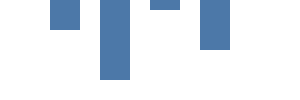
{
"$schema":"https://vega.github.io/schema/vega/v3.json",
"width": 300, "height": 100,
"data": [ {
"name": "vals",
"values": [
{"category": 50, "count": 30},
{"category": 100, "count": 80},
{"category": 150, "count": 10},
{"category": 200, "count": 50}
]
} ],
"marks": [ {
"type": "rect",
"from": { "data": "vals" },
"encode": {
"update": {
"x": {"field": "category"},
"width": {"value": 30},
"y": {"field": "count"},
"y2": {"value": 0}
}
}
} ]
}
rect 마크는 vals를 데이터 소스로 지정합니다. 해당 마크는 소스 데이터 값(테이블 행 또는 데이텀으로도 알려져 있음)별로 한 번씩 그려집니다. 이전 그래프와 달리 x 및 y 매개 변수는 하드코딩되지 않고 데이터 필드에서 나옵니다.
확장
확장은 매우 중요한 부분일 뿐만 아니라 Vega에서는 약간 까다로운 개념이기도 합니다. 이전 예제에서 스크린 픽셀 좌표가 데이터 내에서 하드코딩되었습니다. 이렇게 하면 단순해지기는 하지만, 실제 데이터가 그러한 형식으로 나타나는 경우는 극히 드뭅니다. 대신 소스 데이터는 자체 단위(예: 이벤트의 수)로 나타나며, 소스 값을 픽셀 단위로 원하는 그래프 크기까지 확장하는 것은 그래프마다 다릅니다.
이 예제에서 우리는 소스 데이터 도메인의 값(이 그래프에서는 count 값이 1000..8000이며 ‘count=0’도 포함)을 원하는 범위(이 사례의 경우 그래프의 높이는 0..99)로 변환시켜 주는 필수적인 수학적 기능인 선형 스케일을 사용합니다. "scale": "yscale"을 y와 y2 매개 변수 모두에 추가하면 yscale 배율 조정기를 사용하여 count를 화면상의 좌표(0이 99가 되고 소스 데이터 내 최대값인 8000이 0이 됨)로 변환합니다. height 범위 매개 변수는 특별한 경우이며 값을 대칭 이동시켜 0이 그래프의 하단에 나타나게 한다는 점에 유의하십시오.
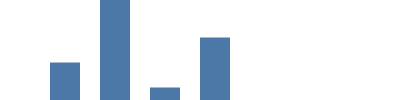
{
"$schema":"https://vega.github.io/schema/vega/v3.json",
"width": 400, "height": 100,
"data": [ {
"name": "vals",
"values": [
{"category": 50, "count": 3000},
{"category": 100, "count": 8000},
{"category": 150, "count": 1000},
{"category": 200, "count": 5000}
]
} ],
"scales": [
{
"name": "yscale",
"type": "linear",
"zero": true,
"domain": {"data": "vals", "field": "count"},
"range": "height"
}
],
"marks": [ {
"type": "rect",
"from": { "data": "vals" },
"encode": {
"update": {
"x": {"field": "category"},
"width": {"value": 30},
"y": {"scale": "yscale", "field": "count"},
"y2": {"scale": "yscale", "value": 0}
}
}
} ]
}
구간 확장
자습서를 위해 15가지가 넘는 Vega 스케일 유형 가운데 또 다른 하나인 구간 스케일이 필요할 것입니다. 이 스케일은 구간으로서 나타나는 여러 값(카테고리 등)이 있을 때 사용되며 각각은 그래프의 전체 너비에서 동일한 가변 너비를 차지합니다. 여기 구간 스케일은 4개의 고유한 카테고리에 동일한 가변 너비(막대와 양쪽 끝 사이에 약 400/4, -5% 패딩)를 부여합니다. {"scale": "xscale", "band": 1}는 마크의 ‘width’ 매개 변수에 대해 구간 너비의 100%를 차지합니다.
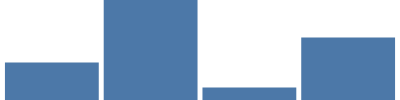
{
"$schema":"https://vega.github.io/schema/vega/v3.json",
"width": 400, "height": 100,
"data": [ {
"name": "vals",
"values": [
{"category": "Oranges", "count": 3000},
{"category": "Pears", "count": 8000},
{"category": "Apples", "count": 1000},
{"category": "Peaches", "count": 5000}
]
} ],
"scales": [
{
"name": "yscale",
"type": "linear",
"zero": true,
"domain": {"data": "vals", "field": "count"},
"range": "height"
},
{
"name": "xscale",
"type": "band",
"domain": {"data": "vals", "field": "category"},
"range": "width",
"padding": 0.05
}
],
"marks": [ {
"type": "rect",
"from": { "data": "vals" },
"encode": {
"update": {
"x": {"scale": "xscale", "field": "category"},
"width": {"scale": "xscale", "band": 1},
"y": {"scale": "yscale", "field": "count"},
"y2": {"scale": "yscale", "value": 0}
}
}
} ]
}
축
일반적인 그래프는 축 라벨 없이 작성되지 않을 것입니다. 축 정의는 이전에 정의한 것과 동일한 스케일을 사용하기 때문에, 이를 추가하는 일은 이름에 따라 참조하고 어느 쪽에 배치될 것인지 지정하는 것만큼이나 단순합니다. 이 코드를 마지막 코드 예제에 최상위 수준 요소로 추가하십시오.
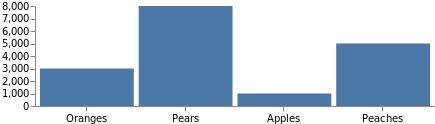
"axes": [
{"scale": "yscale", "orient": "left"},
{"scale": "xscale", "orient": "bottom"}
],
전체 그래프 크기가 이들 축을 포함하는 수준까지 자동으로 증가한다는 점에 유의하십시오. "autosize": "fit"을 상단 지정 부분에 추가하면 그래프가 원래의 크기를 유지하도록 설정할 수 있습니다.
데이터 변형 및 조건
데이터를 드로잉에 활용하기 전에 흔히 추가적인 조작을 수행해야 합니다. Vega에서는 이러한 추가 조작을 돕는 변형을 제공합니다. 가장 보편적인 공식 변형을 사용하여 무작위 count 값 필드를 각 소스 데이터에 동적으로 추가해 보겠습니다. 또한, 이 그래프에서 우리는 막대의 채우기 색을 조작하여 값이 333 미만이면 빨간색, 666 미만이면 노란색, 666을 초과하면 녹색으로 설정할 것입니다. 이러한 작업은 스케일 대신 소스 데이터 도메인을 색상 집합 또는 색 구성표로 매핑하여 이뤄질 수 있다는 점에 유의하십시오.
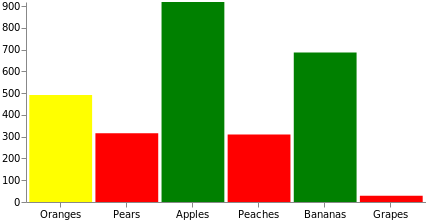
{
"$schema":"https://vega.github.io/schema/vega/v3.json",
"width": 400, "height": 200,
"data": [ {
"name": "vals",
"values": [
{"category": "Oranges"},
{"category": "Pears"},
{"category": "Apples"},
{"category": "Peaches"},
{"category": "Bananas"},
{"category": "Grapes"}
],
"transform": [
{"type": "formula", "as": "count", "expr": "random()*1000"}
]
} ],
"scales": [
{
"name": "yscale",
"type": "linear",
"zero": true,
"domain": {"data": "vals", "field": "count"},
"range": "height"
},
{
"name": "xscale",
"type": "band",
"domain": {"data": "vals", "field": "category"},
"range": "width",
"padding": 0.05
}
],
"axes": [
{"scale": "yscale", "orient": "left"},
{"scale": "xscale", "orient": "bottom"}
],
"marks": [ {
"type": "rect",
"from": { "data": "vals" },
"encode": {
"update": {
"x": {"scale": "xscale", "field": "category"},
"width": {"scale": "xscale", "band": 1},
"y": {"scale": "yscale", "field": "count"},
"y2": {"scale": "yscale", "value": 0},
"fill": [
{"test": "datum.count < 333", "value": "red"},
{"test": "datum.count < 666", "value": "yellow"},
{"value": "green"}
]
}
}
} ]
}
Elasticsearch와 Kibana를 통한 동적 데이터
지금까지 기본적인 사항에 대해 알아 보았으며, 무작위로 생성된 몇 가지 Elasticsearch 데이터를 활용하여 시간 기반 라인 차트를 만들어 보겠습니다. 이는 우리가 Kibana 기본 설정인 Vega-Lite(Vega의 단순화된 상위 버전) 대신 Vega 언어를 사용하게 되는 점을 제외하고 사용자가 Kibana에서 Vega 그래프를 작성할 때 처음에 보게 되는 것과 비슷합니다.
이 예제에서 우리는 url을 통한 실제 쿼리를 하는 대신 values를 사용하여 데이터를 하드코딩할 것입니다. 이러한 방식으로 우리는 Kibana Elasticsearch 쿼리를 지원하지 않는 Vega 편집기를 계속 테스트해 볼 수 있습니다. 아래 나온 바와 같이 values를 url로 대체하면 그래프는 Kibana 내부에서 완전히 동적 상태가 됩니다.
우리의 쿼리는 대시보드 사용자가 선택한 시간 범위와 컨텍스트 필터를 사용하여 일정한 시간 간격마다 문서의 수를 셉니다. 더 자세한 정보는 Kibana에서 Elasticsearch를 쿼리하는 방법을 참조하십시오.
"url": {
"%context%": true,
"%timefield%": "@timestamp",
"index": "_all",
"body": {
"aggs": {
"time_buckets": {
"date_histogram": {
"field": "@timestamp",
"interval": {"%autointerval%": true},
"extended_bounds": {
"min": {"%timefilter%": "min"},
"max": {"%timefilter%": "max"}
},
"min_doc_count": 0
}
}
},
"size": 0
}
이를 실행하면 결과는 다음과 같이 나타날 것입니다(관련 없는 일부 필드는 간결성을 위해 삭제함).
"aggregations": {
"time_buckets": {
"buckets": [
{"key": 1528061400000, "doc_count": 1},
{"key": 1528063200000, "doc_count": 45},
{"key": 1528065000000, "doc_count": 49},
{"key": 1528066800000, "doc_count": 17},
...
보시다시피 우리에게 필요한 실제 데이터는 aggregations.time_buckets.buckets 배열 내에 있습니다. Vega에게 데이터 정의 내에서 "format": {"property": "aggregations.time_buckets.buckets"}이 있는 배열만 검토하도록 지시할 수 있습니다.
x축은 더 이상 카테고리가 아닌 시간에 기반합니다(key 필드는 Vega가 직접 사용할 수 있는 UNIX 시간임). 따라서 우리는 xscale 유형을 시간으로 변경하고, 모든 필드가 key와 doc_count를 사용하도록 조정할 수 있습니다. 또한 마크 유형을 line으로 변경하고 x와 y 매개 변수 채널만 포함하게 해야 합니다. 자, 보세요. 이제 선 그래프가 생겼습니다. 또한 x 축 라벨을 format, labelAngle, tickCount매개 변수로 사용자 정의하는 데 관심이 있을 수도 있습니다.
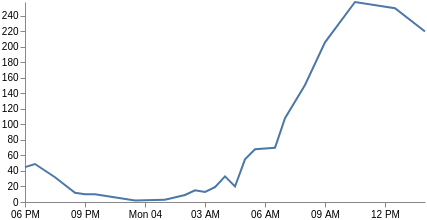
{
"$schema": "https://vega.github.io/schema/vega/v3.json",
"width": 400, "height": 200,
"data": [
{
"name": "vals",
"values": {
"aggregations": {
"time_buckets": {
"buckets": [
{"key": 1528063200000, "doc_count": 45},
{"key": 1528065000000, "doc_count": 49},
{"key": 1528068600000, "doc_count": 32},
{"key": 1528072200000, "doc_count": 12},
{"key": 1528074000000, "doc_count": 10},
{"key": 1528075800000, "doc_count": 10},
{"key": 1528083000000, "doc_count": 2},
{"key": 1528088400000, "doc_count": 3},
{"key": 1528092000000, "doc_count": 9},
{"key": 1528093800000, "doc_count": 15},
{"key": 1528095600000, "doc_count": 13},
{"key": 1528097400000, "doc_count": 19},
{"key": 1528099200000, "doc_count": 33},
{"key": 1528101000000, "doc_count": 20},
{"key": 1528102800000, "doc_count": 55},
{"key": 1528104600000, "doc_count": 68},
{"key": 1528108200000, "doc_count": 70},
{"key": 1528110000000, "doc_count": 108},
{"key": 1528113600000, "doc_count": 151},
{"key": 1528117200000, "doc_count": 206},
{"key": 1528122600000, "doc_count": 258},
{"key": 1528129800000, "doc_count": 250},
{"key": 1528135200000, "doc_count": 220}
]
}
}
},
"format": {"property": "aggregations.time_buckets.buckets"}
}
],
"scales": [
{
"name": "yscale",
"type": "linear",
"zero": true,
"domain": {"data": "vals", "field": "doc_count"},
"range": "height"
},
{
"name": "xscale",
"type": "time",
"domain": {"data": "vals", "field": "key"},
"range": "width"
}
],
"axes": [
{"scale": "yscale", "orient": "left"},
{"scale": "xscale", "orient": "bottom"}
],
"marks": [
{
"type": "line",
"from": {"data": "vals"},
"encode": {
"update": {
"x": {"scale": "xscale", "field": "key"},
"y": {"scale": "yscale", "field": "doc_count"}
}
}
}
]
}
당사 블로그에 Vega에 관한 포스트가 올라올 수 있으니 계속 확인해 주시기 바랍니다. 특히 집계와 중첩된 데이터를 비롯한 Elasticsearch 결과를 처리하는 것과 관련된 다른 포스트도 작성할 예정입니다.