미처 못 다한 이야기들 - Elastic{ON} Tour Seoul
이번 블로그 포스트는 Elasticsearch 의 한국 기술지원 엔지니어인 김기주님이 Elastic{on} Tour Seoul 행사의 AMA(Ask Me Anything) 부스에서 질문을 받은 경험들에 대한 내용입니다.
樂 "6.0에서는 타입이 없어진다는데 parent/child 관계는 어떻게 나타내나요?" 邏 "6.0에서 새로 생기는 join datatype을 사용하시면 됩니다." 樂 "하나의 인덱스에 타입 구별 없이 parent와 child가 저장되면 각각의 문서가 parent인지 child인지는 어떻게 구별하나요?" 邏 '앗! 6.0에서 타입이 없어지고 join datatype으로 대체된다는 얘기를 보기만 했지 실제로 어떻게 하는지 구체적으로 살펴보지 않았더니 여기서 탄로가 나는구나!'
다른 엔지니어에게 물어보아도 역시 최신 변경사항이라 구체적으로 아는 사람이 없고, 유료 고객이라면 좀 더 조사해서 나중에라도 답변을 드릴 텐데 오늘 AMA (Ask Me Anything) 부스에서 만난 분은 어찌 연락을 드릴 지… 아마도 비슷한 궁금증을 갖고 계신 분들이 제법 계실 것 같아 다른 질문들과 함께 블로그를 통해 답변을 드리려고 합니다.
 ( Elastic{ON} Tour Seoul 중 AMA 부스. 사진은 본문의 질문과 직접적인 관련이 없습니다. 邏 )
( Elastic{ON} Tour Seoul 중 AMA 부스. 사진은 본문의 질문과 직접적인 관련이 없습니다. 邏 )
타입 (Type)
엘라스틱서치 6.0부터는 타입이 하나로 제한됩니다. 단 5.x에서 만들어진 인덱스는 6.0으로 업그레이드했을 때도 그대로 여러 타입을 사용할 수 있습니다. 5.x 에서 6.x 으로 롤링 업그레이드는 아래 영상을 참고하세요.
6.0에서 parent/child 관계를 나타낼 때는 앞서 말했듯이 join datatype을 이용하며 아래와 같이 나타냅니다.
PUT my_index
{
"mappings": {
"doc": {
"properties": {
"my_join_field": {
"type": "join",
"relations": {
"question": "answer"
}
}
}
}
}
}
여기서 question이 answer의 parent가 되고, myjoinfield은 관계의 이름입니다. Parent 문서를 인덱싱할 때는 아래와 같이 관계 이름과 parent임을 나타내는 이름(question)을 적어주면 됩니다.
PUT my_index/doc/1?refresh
{
"text": "This is a question",
"my_join_field": {
"name": "question"
}
}
간단히 이렇게 쓸 수도 있습니다.
PUT my_index/doc/1?refresh
{
"text": "This is a question",
"my_join_field": "question"
}
Child 문서를 인덱싱할 때는 아래와 같이 관계 이름과 child임을 나타내는 이름(answer), parent 문서의 ID(1)를 적습니다. Parent와 child 문서를 같은 샤드에 보관하도록 routing도 적어주어야 합니다.
PUT my_index/doc/3?routing=1&refresh
{
"text": "This is an answer",
"my_join_field": {
"name": "answer",
"parent": "1"
}
}
이때 GET my*index/*search로 인덱스 전체를 조회하면 아래와 같은 결과를 얻을 수 있는데,
{
"took": 1,
"timed_out": false,
"_shards": {
"total": 5,
"successful": 5,
"skipped": 0,
"failed": 0
},
"hits": {
"total": 2,
"max_score": 1,
"hits": [
{
"_index": "my_index",
"_type": "doc",
"_id": "1",
"_score": 1,
"_source": {
"text": "This is a question",
"my_join_field": {
"name": "question"
}
}
},
{
"_index": "my_index",
"_type": "doc",
"_id": "3",
"_score": 1,
"_routing": "1",
"_source": {
"text": "This is an answer",
"my_join_field": {
"name": "answer",
"parent": "1"
}
}
}
]
}
}
myjoinfield의 이름이 answer이고 parent ID가 있으므로 child임을 알 수 있습니다. Parent 문서만 조회 하려면
GET my_index/_search
{
"query": {
"match": {
"my_join_field": "question"
}
}
}
Child 문서만 조회하려면
GET my_index/_search
{
"query": {
"match": {
"my_join_field": "answer"
}
}
}
를 실행하면 됩니다.
6.0에서의 타입 관련 변경사항과 parent/child 관계에 대한 추가 정보는 아래 링크를 참고하시기 바랍니다. https://www.elastic.co/guide/en/elasticsearch/reference/current/removal-of-types.html https://www.elastic.co/guide/en/elasticsearch/reference/current/parent-join.html https://www.elastic.co/blog/removal-of-mapping-types-elasticsearch https://www.elastic.co/blog/kibana-6-removal-of-mapping-types
Split Brain (Quorum) 문제
"엘라스틱서치를 이제 막 쓰기 시작했는데요, 클러스터 구성이 적절한 지 살펴봐 주시기 바랍니다. 마스터 노드는 2개…"
아마도 HA (high availability)를 위해서 2대가 필요하다고 생각하시는 것 같은데, split brain이라는 현상을 피하기 위해서는 최소 3대가 필요합니다. Split brain은 마스터 후보 노드(master eligible node) 사이에 네트워크가 단절되었을 때 각각의 마스터 후보 노드가 마스터 노드로 승격하여 두 개의 클러스터로 나뉘어 독립적으로 동작하는 현상입니다. 양쪽 클러스터에서 각각 데이터 업데이트가 이루어지면 나중에 네트워크가 복구되어도 데이터 비동기 문제로 인해 데이터의 손실 없이 클러스터를 복구할 수가 없으므로 매우 위험합니다.
Split brain을 피하려면 마스터 (후보) 노드를 최소 3대, 더 늘릴 경우 개수를 홀수로 유지하고, discovery.zen.minimum_master_nodes를 마스터 노드 개수/2+1로 설정합니다. 즉 마스터 노드가 3개라면 2로 설정하면 됩니다.
추가 정보는 아래 링크를 참고하시기 바랍니다.
https://www.elastic.co/guide/en/elasticsearch/reference/current/modules-node.html#split-brain
https://www.elastic.co/guide/en/elasticsearch/reference/current/modules-discovery-zen.html
Machine Learning
아마도 Machine Learning Deep Dive 세션이 막 끝났나 봅니다. 머신 러닝은 요즘 누구나 관심 갖는 정말 핫한 분야입니다.
"여러 서버에서 수집된 로그에서 anomaly를 찾으려면 어떻게 해야 할까요? 서버별로 따로따로 ML job을 실행해야 하나요?"
현장에서 정신이 없어서 제대로 답변을 못 드렸는데, 그 경우에는 multi-metric job을 만드시면 됩니다.
Kibana에서 Machine Learning을 선택하고 Create new job, 인덱스 패턴, muti metric을 차례로 선택한 뒤, Split Data에 서버 이름을 담고 있는 필드(예: host)를 선택하시면 됩니다.
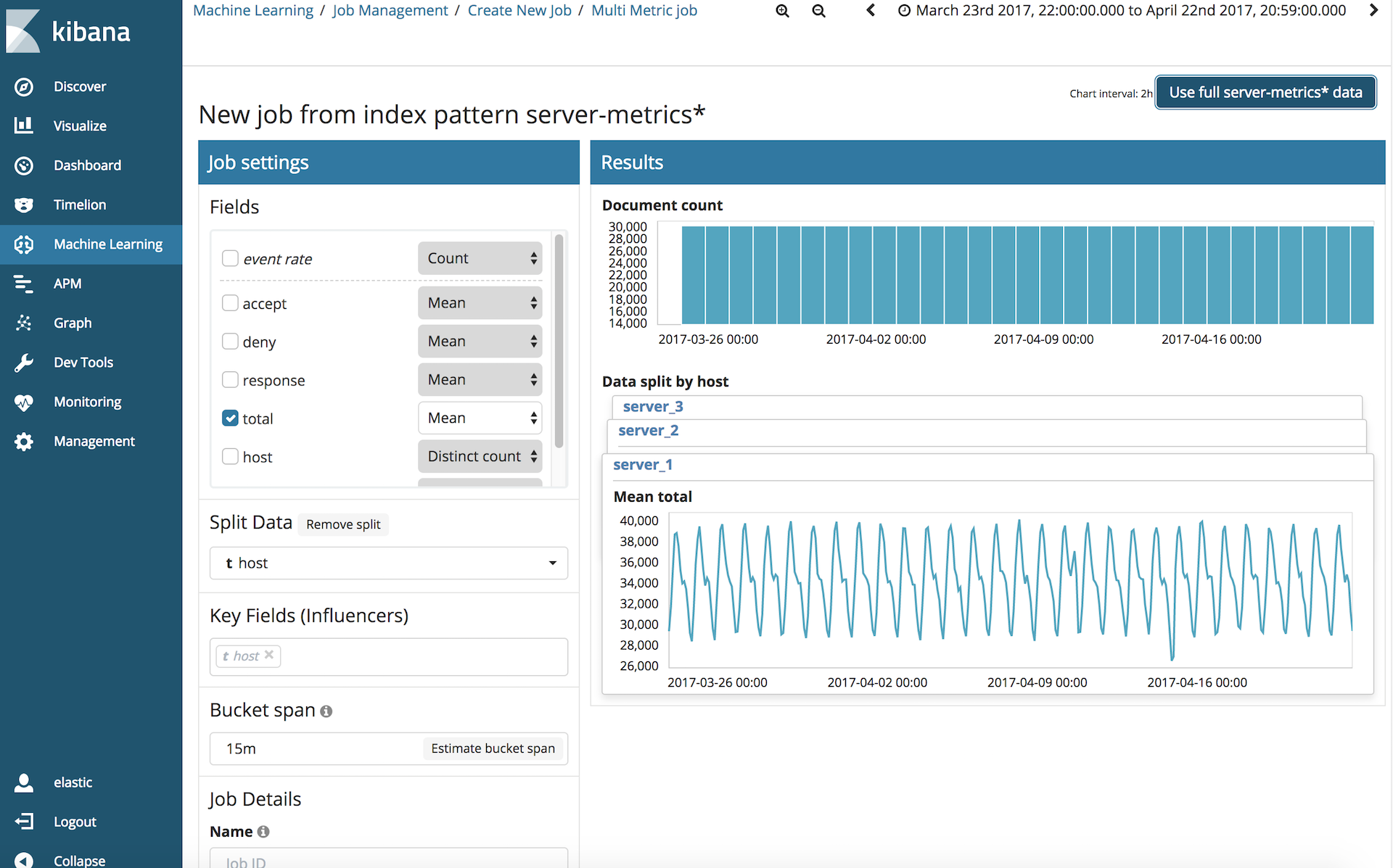 (Multi-metric job 생성)
(Multi-metric job 생성)
Job Details의 Name에 적절한 이름을 적고 Create Job을 누릅니다. 만들어진 작업을 실행한 뒤 Anomaly Explorer를 통해 서버별로 특이점을 찾아볼 수 있습니다.
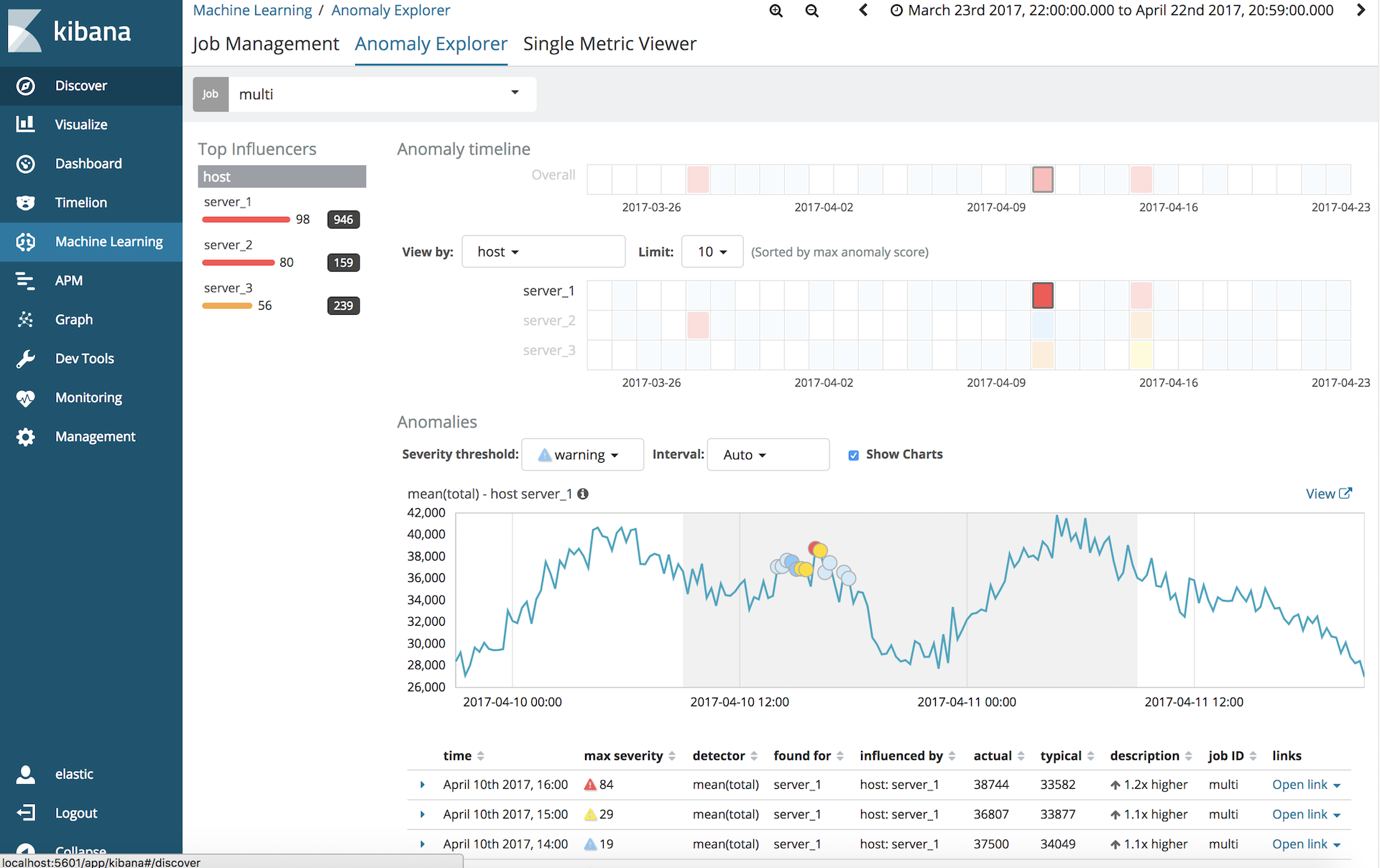 (Anomaly Explorer)
(Anomaly Explorer)
추가 정보는 아래 링크를 참고하시기 바랍니다. https://www.elastic.co/guide/en/x-pack/current/ml-gs-multi-jobs.html https://www.elastic.co/kr/videos/machine-learning-tutorial-creating-a-multi-metric-job
Delete Alias
이번 행사 때 이야기는 아닙니다만, 얼마 전에 발표된 6.0과 관련된 이야기라서 여기 적습니다. 작년 가을 모처럼 친구와 함께 맥주 한 잔 하는데 갑자기 옆사람한테 전화가 왔습니다.
"실수로 인덱스를 지워버렸습니다. 중요한 인덱스인데…"
Alias는 인덱스와 동일한 객체로 취급되기 때문에 5.x까지는 Delete 명령에 alias 이름을 인자로 넘기면 해당 alias에 등록된 모든 인덱스가 지워졌습니다. Alias와 인덱스의 링크를 지우고자 할 때는 DELETE가 아니라 POST 명령의 remove 옵션을 이용해야 하는데 많은 분들이 혼동할 수 있는 부분이었습니다.
6.0부터는 아래와 같이 alias를 만들고 DELETE를 실행하면
POST /_aliases
{
"actions" : [
{ "add" : { "index" : "my_index", "alias" : "alias1" } }
]
}
DELETE alias1
다음과 같은 에러를 리턴합니다.
{
"error": {
"root_cause": [
{
"type": "illegal_argument_exception",
"reason": "The provided expression [alias1] matches an alias, specify the corresponding concrete indices instead."
}
],
"type": "illegal_argument_exception",
"reason": "The provided expression [alias1] matches an alias, specify the corresponding concrete indices instead."
},
"status": 400
}
https://www.elastic.co/guide/en/elasticsearch/reference/6.0/indices-delete-index.html 를 보면 "Aliases cannot be used to delete an index."라고 되어 있습니다.
추가로 말씀드리자면 엘라스틱서치에서 Delete 명령으로 인덱스를 지우면 다시 복구할 수 없습니다. 따라서 반드시 스냅샷을 통해 주기적으로 백업을 하시기 바랍니다. 스냅샷에 대해서는 아래 링크를 참고하시기 바랍니다. https://www.elastic.co/guide/en/elasticsearch/reference/current/modules-snapshots.html
Elastic{ON} Tour Seoul을 통해 여러분들을 만날 수 있어 반가웠습니다. 다음 달 샌프란시스코에서 열리는 Elastic{ON} 2018 Conference (https://www.elastic.co/elasticon/conf/2018/sf)에도 많은 분들이 참석하시어 새로운 정보를 많이 얻는 기회가 되시기를 바랍니다. 고맙습니다!
