ハイブリッド検索とは?
2つ以上の検索方法。1つのランク付けされたリスト。
ハイブリッド検索は、2つ以上の検索方法(語彙検索やセマンティック検索など)を1つのランク付けされたリストに組み合わせて、関連性と想起率を高める情報検索技術です。最も一般的な組み合わせは、単語や語句を正確に一致させるのに優れた全文語彙検索と、クエリの背後にある意味を解釈するセマンティックベクトル検索を組み合わせたものです。語彙面は精度を高め、セマンティック面はユーザーの根底にある意図を深く理解します。
これらの方法が1つのクエリで一緒に実行され、その結果は特殊な融合戦略を使用して1つのまとまりのあるランキングにまとめられます。語彙+セマンティックが最も一般的な組み合わせですが、ハイブリッド検索では、地理空間+セマンティック検索、さらにはテキスト+画像検索など、他のアプローチを組み合わせてさまざまなニーズに合わせることができます。
ハイブリッド検索が重要な理由
ハイブリッド検索は、個々の検索方法の弱点を軽減しつつ、単一のパイプラインでそれぞれの強みを活用します。最新のAIは、テキスト、画像、音声、ログなど多様なモダリティを処理し、意図とデータを橋渡しする必要があります。関連性はこれまで以上に重要になっています。例えば、eコマースの場合の検索エクスペリエンスはユーザーが結果をすばやくフィルタリングして絞り込むことができれば成功しますが、AIエージェントは、質問に回答したりアクションを実行したりするために、関連性の高い1つの回答を必要とすることがよくあります。そのため、今日では検索技術を組み合わせて最適化する能力が重要になり、この能力が従来の検索結果だけでなく、正確でデータに基づいた応答を提供する会話エージェントも支援しています。
ハイブリッド検索についてさらに詳しく見る前に、語彙検索とセマンティック検索がどう異なり、なぜ互いを補完するのかを簡単に確認しましょう。
語彙検索の概要
語彙検索は、構造化データが整っており、ユーザーが探しているものがわかっている場合に理想的です。正確な用語を一致させるため、非常に正確かつ説明可能であり、BM25Fのような関連性スコアリングアルゴリズムを用いてクエリ語の頻度や稀度で文書をランク付けします。このアプローチは透明なスコアリングを提供し、フィールドブースト、同義語、アナライザーを通じて微調整された関連性をサポートします。モデルのオーバーヘッドがないため、語彙検索は高速で効率的で、フィルターとファセットを使用し、規模を拡大しても速度低下やフルインデックススキャンなしで確実に動作します。特に構造化クエリ、希な用語、ドメイン固有の言語に効果的です。
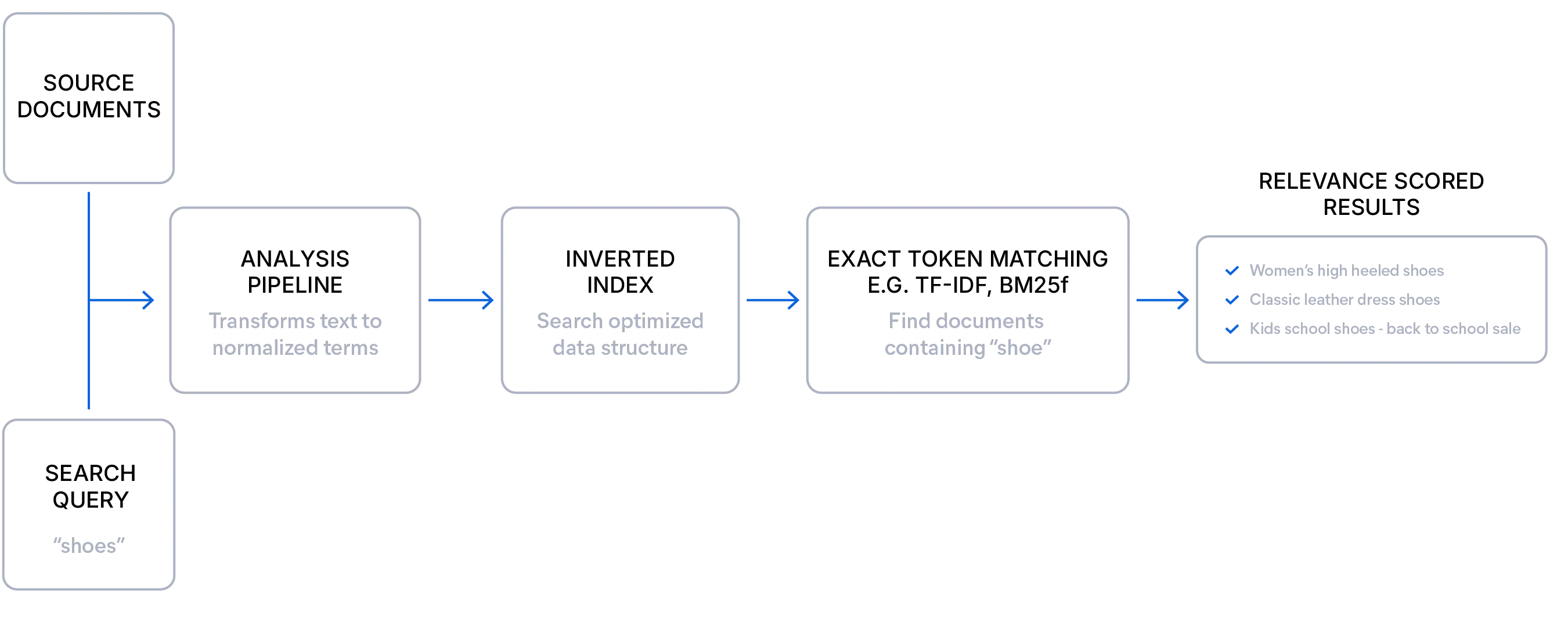
語彙検索クエリの簡単な例を示します。
GET example-index/_search
{
"query": {
"term": {
"text": "blue shoes"
}
}
}
Elasticsearch クエリ言語(ES|QL)を使用した料理ブログの同様の語彙検索の例も見てみましょう。ブログには、テキストコンテンツ、カテゴリカルデータ、数値評価など、さまざまな属性を持つレシピが含まれています。
FROM cooking_blog METADATA _score | WHERE description:"fluffy pancakes" | KEEP title, description, _score | SORT _score DESC | LIMIT 1000
このクエリは、「fluffy」または「pancakes」(またはその両方)を含むドキュメントのdescriptionフィールドを検索します。デフォルトでは、ES|QLは検索語間でORロジックを用い、指定された単語を含む文書に一致します。KEEPコマンドを使用して検索結果に含めるフィールドを正確に指定し、_scoreメタデータを要求して検索結果をクエリとの一致度でランク付けできます。
この実践的なチュートリアルで語彙検索についてさらに学びましょう。
セマンティック検索の概要
セマンティック検索 は、語彙検索のように正確な用語を一致させるのではなく、クエリと文書の意味の類似性に基づいて結果を取得します。
埋め込みモデルは、テキストやその他のメディアの意味をベクトルと呼ばれる数値表現に変換します。これらのベクトル(数字のリスト)は、テキストの基本的なコンテキストやトピックを捉え、Elasticsearchのようなベクトルデータベースに格納されます。
これにより、検索エンジンは、クエリと全く同じ単語がない場合でも、概念的に類似した結果を見つけることができます。
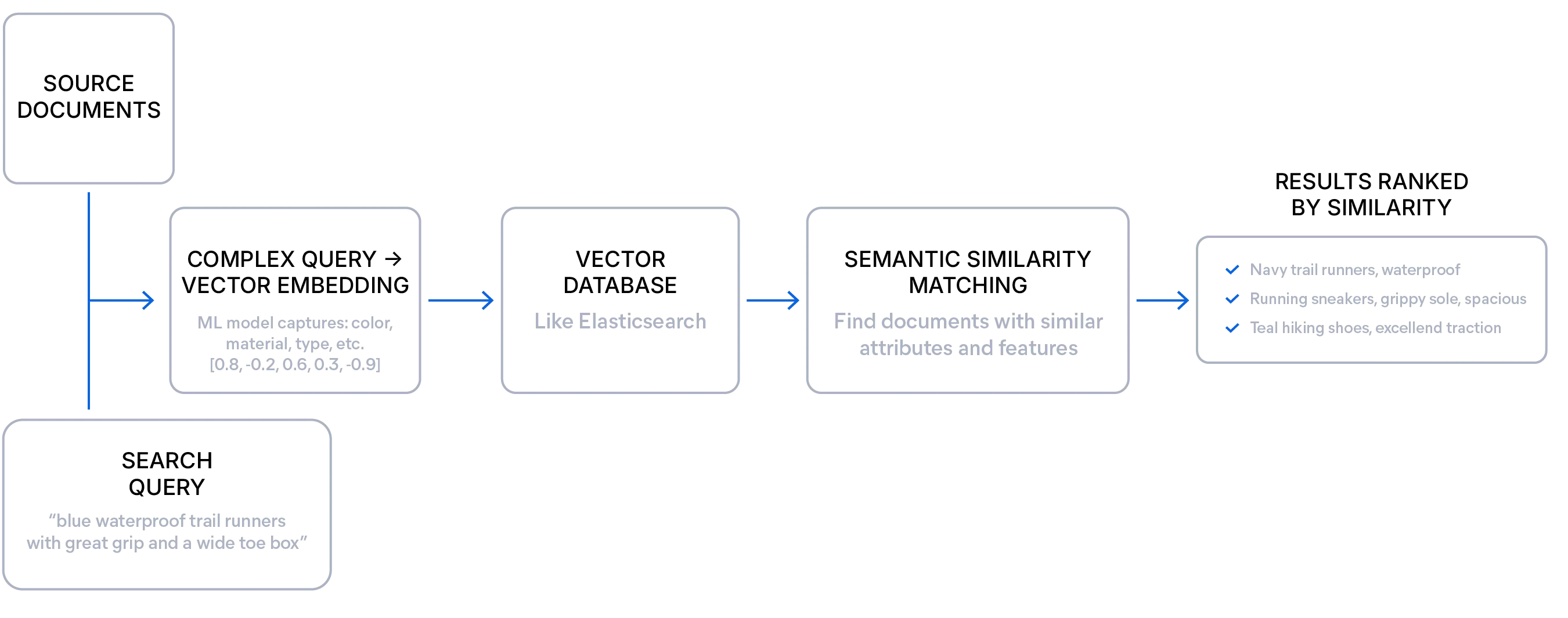
このアプローチは、非構造化データ、探索的クエリ、ユーザーが使用すべき正確な用語を知らない場合に特に役立ちます。開発者は、セマンティック検索を活用して、より関連性の高い結果を提供し、曖昧、冗長、または不明瞭な表現を処理しながら、適切な回答を提示できます。
以下はセマンティック検索クエリの例です。
GET example-index/_search
{
"query": {
"semantic": {
"field": "inference_field",
"query": "blue waterproof trail runners with great grip and a wide toe box"
}
}
}
ES|QLは、マッピングにsemantic_textタイプのフィールドが含まれている場合、セマンティック検索をサポートします。推論エンドポイント上で動作する基盤モデルが文書を処理した後、セマンティック検索を実行できます。以下は、semantic_descriptionフィールドに対する自然言語クエリの例です。
FROM cooking_blog METADATA _score | WHERE semantic_description:"簡単に調理できて栄養価の高いプラントベースの食事にはどのようなものがありますか?" | SORT _score DESC | LIMIT 5
セマンティック検索について詳しく学ぶか、この実践的なチュートリアルでさらに深く理解しましょう。
語彙アルゴリズム(BM25Fなど)は、クエリ用語がドキュメント用語と一致する場合には高い精度を実現しますが、関連コンテンツが異なる表現で表現されている場合には失敗します。(例えば、「athletic footwear」のクエリは、「shoes」や「trail runner」とだけ書かれた文書を見逃してしまうかもしれません。)セマンティックベクトル検索は、高次元の埋め込みと近似近傍(ANN)アルゴリズム(例:HNSW)を使用して、正確な用語の重複に関係なく概念的に類似したドキュメントを取得しますが、コンテキストが曖昧な場合はノイズが発生することがあります。
ハイブリッド検索の仕組み
この両方の長所を組み合わせたのがハイブリッド検索です。適切に実行すれば、ハイブリッド検索は単なる各部分の合計以上の効果を発揮し、語彙検索やセマンティック検索のみよりもはるかに優れた結果を生成できます。ハイブリッド検索はこの両方を兼ね備え、バランスの取れた関連性、より良い正規化割引累積利得(NDCG)、そして2つ目の検索システムの追加なしに再現性を実現できます。
以下はハイブリッド検索クエリの例です。
GET example-index/_search
{
"retriever": {
"rrf": {
"retrievers": [
{
"standard": {
"query": {
"term": {
"description": "shoes"
}
}
}
},
{
"knn": {
"field": "vector",
"query_vector": [1.25, 2, 3.5],
"k": 50,
"num_candidates": 100
}
}
],
"rank_constant": 20,
"rank_window_size": 50
}
}
}
ES|QLでは全文クエリとセマンティッククエリを組み合わせることも可能です。この例では、全文検索とセマンティック検索をカスタムの重み付けで組み合わせています。
FROM my-index METADATA _score
| FORK ( WHERE match(text_field:"shoes") | SORT _score DESC | LIMIT 50)
( WHERE knn(vector, [1.25, 2, 3.5], { "min_candidates" : 100 }) | SORT _score DESC | LIMIT 50 ) // k for knn is derived from LIMIT
| FUSE RRF WITH { "rank_constant": 20 }
| SORT _score DESC
| LIMIT 50
ハイブリッド検索クエリを実行するには、通常、少なくとも1つの語彙検索と1つのセマンティック検索を実行し、それらの結果を組み合わせます。主な課題は、複数のランク付けされたリストを単一の一貫性のあるランキングに統合することです。
BM25FやTF-IDFなどのアルゴリズムによって生成される語彙検索スコアは無制限で、最大値は用語の出現頻度や文書の分布の影響を受けます。対照的に、セマンティック検索のスコアは、通常、類似性関数(例:余弦類似度の場合[0, 2])によって決定される一定の範囲内に収まります。
これらを結合するには、取得したドキュメントの相対的な関連性を維持する融合方法が必要です。
Elasticsearchによるハイブリッド検索
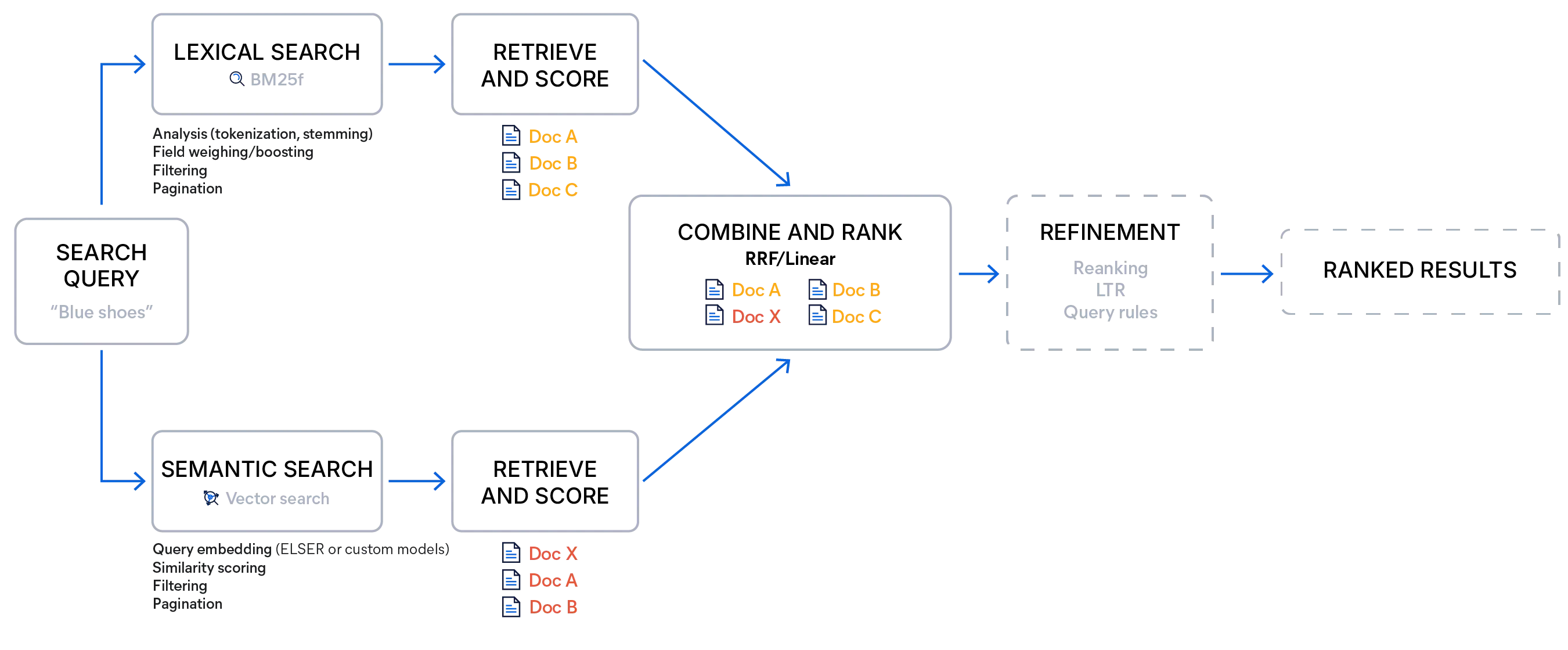
Elasticsearchを用いたハイブリッド検索は、標準的なキーワードクエリとベクトルクエリを組み合わせたり、リトリーバー(複数の異なるタイプのクエリを実行し、それらの結果を選択したスコアリング方式で単一のランク付けリストに統合する検索オプション)を使用することで実装できます。これにより、1 回の検索呼び出し内で多段階の取得パイプラインが可能になり、結果を結合するための複数のリクエストや追加のクライアント側ロジックが不要になります。
Elasticsearchには、逆順位融合(RRF)と線形結合(APIでは線形リトリーバーと呼ばれることが多い)という2つの融合手法が組み込まれています。どちらも各リトリーバーの長所を維持した統一されたランキングを作成することを目指していますが、スコアの扱い方や最も効果的なタイミングが異なります。
逆順位融合は、生のスコアを完全に無視し、各リストでドキュメントがどの程度上位に表示されるかに焦点を当てます。リストの上位にランク付けされたドキュメントには大きな報酬が与えられ、複数のリストに表示されるドキュメントには追加のブーストが加えられます。この方法は、互換性のないスコア範囲に関する問題を回避し、ランク定数を超える調整をほとんど必要とせず、上位の結果の多様性を自然に促進するため、堅牢です。
RRFは、次の式を使用して結果セット内のランクに応じてドキュメントにスコアを付けます。ここで、kは、ランクの低いドキュメントの重要度を調整するための任意の定数です。
![]()
RRFは、リトリーバーが上位の結果と重複している場合や、開発者がラベル付きのトレーニングデータや複雑なキャリブレーションを必要としないプラグアンドプレイソリューションを必要とする場合に特に役立ちます。
対照的に、線形結合は各リトリーバーからの実際のスコアを直接結合します。語彙スコアと意味スコアは非常に異なるスケールで動作するため、線形ではスコアを比較可能な範囲にするために、最小最大スケーリングなどの正規化が必要です。
正規化された後、各リトリーバーの相対的な重要度を表す重みを使用してスコアがブレンドされます。重みが1より大きい場合はリトリーバーの影響力が上がり、重みが1より小さい場合は影響力が下がります。
このアプローチできめ細かな制御が可能になります。開発者は、キーワードの精度が重要な場合はBM25Fを強調し、意図やコンテキストが重要な場合はセマンティックの類似性を重視したり、検索スコアと一緒に追加のビジネスやパーソナライゼーションのシグナルを統合したりできます。重みが慎重に調整された場合、線形結合はRRFよりも正確で予測可能なランキングを生成することで優れた性能を発揮しますが、実験が必要であり、データセット固有の調整に敏感です。
線形結合は、それぞれの重みとβ(0 ≤α, β)を持つ語彙検索結果とセマンティック検索結果を組み合わせ、次のようになります。
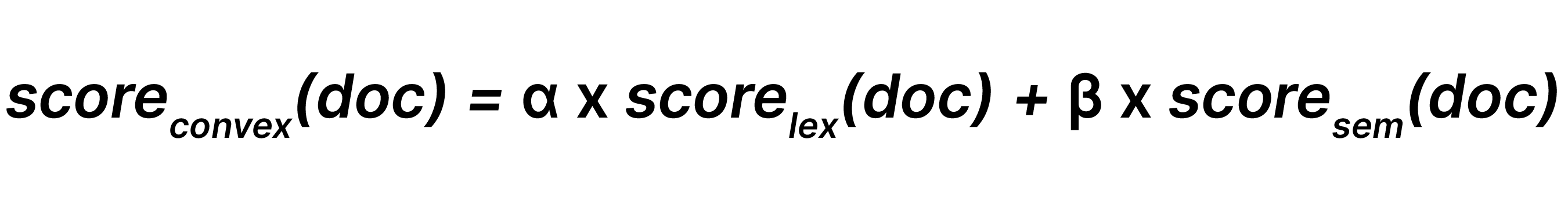
実践においては、RRFはシンプルであり、不一致なスコアスケールに対する耐性があるため、ハイブリッド検索の最適な出発点となります。大幅な調整を行わなくても強力な結果を生成でき、プロトタイプ作成や検索が重複する場合に理想的です。線形結合は、異なる検索方法が別々の結果を返す場合や、語彙、意味、外部信号を慎重にバランスさせる必要がある場合に適しています。つまり、RRFはすぐに使える高速で信頼性の高いハイブリッド化を提供し、一方で線形はアプリケーションとデータに合わせて重みと正規化を調整することで、より高い精度を潜在的に提供します。
要約すると以下のようになります。
| 逆順位融合 | 線形結合 |
|---|---|
堅牢なハイブリッド結果を迅速に得たいなら、RRFから始めましょう。 |
関連性を微調整できるようであれば、線形が適しています。 |
つまり、線形結合は調整すると潜在的な精度が高くなりますが、RRFは実装が簡単で、ラベル付けされたトレーニングデータがなくても機能します。
ハイブリッド検索についてさらに学ぶには、このチュートリアルをお試しください。
ハイブリッド検索の仕組み
- 語彙検索:BM25Fはクエリ用語をインデックス付きトークンと照合します。精度、構造化フィルター、説明可能なスコアリングに最適です。
- セマンティック検索: ベクトル(高密度または低密度)はテキストの意味を表し、類似性検索では共通の単語がなくても関連するコンテンツが見つかります。
- 融合:スコアをRRF、加重ブレンディング、または線形リトリーバーで組み合わせます。フィルターとブーストは両方の検索で一貫して適用されます。
| 検索タイプ | 仕組み | 動作 | 最適な用途 |
|---|---|---|---|
| 語彙検索 クエリ:「赤いランニング シューズサイズ10」 | クエリ内の正確な単語をドキュメント内の単語と一致させます(BM25F、TF-IDF、アナライザー、同義語)。 | タイトル/説明に正確なトークンが含まれる製品を検索します (例:「Nike メンズ レッド ランニング シューズ、サイズ 10 」)。 | 購入者が自分が何を求めているのかを正確に把握している場合。正確で、説明可能、効率的。 |
| セマンティック検索 クエリ:「ジョギング用の軽量シューズ」 | 埋め込みを使用して、キーワードだけでなく意味とコンテキストを捉えます。用語が一致しなくても、概念的に関連した結果を見つけます。 | 「軽量」と「ジョギング」がそのまま出てこない場合でも「 Adidas Cloudfoam ランニング スニーカー、サイズ 10」が返されます。 | 購入者が意図を説明したり、自然言語を使用する場合。曖昧なクエリや説明的なクエリを処理します。 |
| ハイブリッド検索 クエリ:「オフィス用の快適なドレスシューズ」 | 語彙と意味の結果を組み合わせて、ランキングを融合します(例:RRFを使用)。 | 「ブラックレザードレスシューズ、コンフォートフィット」などの完全一致や、「クッションインソール付きローファー」などの意味的に関連するアイテムを取得します。両方が関連性でランク付けされて一緒に表示されます。 | クエリに正確な用語と意図が混在している場合。正確さと発見のバランスをとります。 |
ハイブリッド探索の内部:高密度ベクトルと低密度ベクトルの解説
Elasticsearchのセマンティック検索は、クエリやドキュメントを意味を表すベクトル表現に変換することで機能します。ハイブリッド検索は、高密度モデルと低密度なモデルのどちらを使用しても、語彙検索とセマンティック検索を組み合わせます。
高密度ベクトル
高密度ベクトル は BERT のようなモデルによって生成される固定長の数値配列で、類似のインプット(例えば猫と子猫)がベクトル空間で近接して現れるため、セマンティックマッチング、推奨、類似性検索に強力な効果を発揮します。
テキストが高密度ベクトルとして埋め込まれると、次のようになります。
[ 0.13586345314979553, -0.6291824579238892, 0.32779985666275024, 0.36690405011177063, ... ]
各次元には意味のある情報が含まれており、ベクトルはデータで密集しています。類似したコンテンツは、ベクトル空間内で互いに近い埋め込みを生成します。
Elasticsearchでは、高密度ベクトルはdense_vectorフィールドに格納され、HNSWのような近似最近傍(ANN)アルゴリズムでクエリされます。これは、テキスト、画像、その他のコンテンツの全体的な意味を捉えるのに最適です。
POST my-index/_search
{
"retriever": {
"rrf": {
"retrievers": [
{
"standard": {
"query": {
"match": {
"text_field": "fox"
}
}
}
},
{
"knn": {
"field": "title_vector",
"query_vector": [0.1, 3.2, 2.1],
"k": 5,
"num_candidates": 100
}
}
]
}
}
}
ES|QLの例を次に示します。
FROM my-index METADATA _score
| FORK ( WHERE match(text_field:"fox") | SORT _score DESC | LIMIT 5)
( WHERE knn(image_vector, [0.1, 3.2, 2.1], { "min_candidates" : 100 }) | SORT _score DESC | LIMIT 5 )
| FUSE
| SORT _score DESC上記からわかるように、ハイブリッド検索クエリは単にrrfリトリーバーを活用し、標準のリトリーバーで行われた語彙検索クエリ(例:マッチクエリ)とknnリトリーバーで指定されたベクトル検索クエリを組み合わせます。このクエリは、まずグローバルレベルで上位5件のベクトル一致を取得し、次にそれらを語彙一致と組み合わせて、最後に最も一致する10件のヒットを返します。rrfリトリーバーは、ベクトルマッチと語彙マッチを組み合わせるためにRRFランキングを使用します。
低密度ベクトルとELSERの理解
高密度埋め込みはセマンティック検索を実行する唯一の方法ではありません。
低密度ベクトルは、ほとんどがゼロで、解釈可能な用語に結びついた重み付けされた値がいくつか含まれているため、リソース効率が高く、説明可能で、ゼロショットシナリオで効果的です。
低密度ベクトル表現は次のようになります。
{"f1":1.2,"f2":0.3,… }
Elasticsearchにおいて、Elastic Learned Sparse EncodeR(ELSER) は、テキストを意味的に関連する用語に展開し、重みを割り当てることで、解釈可能性を維持しながら、完全なキーワードを超えた一致を可能にするアウトオブドメインの低密度自然言語処理(NLP)モデルです。
さらに、semantic_textフィールドが埋め込み生成と推論を取り込み時に自動的に処理することで、セマンティック検索を従来のテキスト検索と同じくらい簡単にします。ドキュメントをtextフィールドのようにインデックス化し、シンプルなmatchクエリを実行できます。フィールドタイプが異なるインデックス間でも追加のクエリロジックなしに語彙的・意味的なマッチングを取得できます。高度な制御を行うには、同じフィールドでknnまたはsparse_vectorクエリを使用します。
ELSERを使用した例:
- 約30,000語の語彙を事前学習済み
- sparse_vector(用語/重みのペア)として格納
- semantic_textの取り込み時またはインデックス時に推論インジェストプロセッサで自動生成
- 逆インデックス(語彙検索のように)でクエリされ、効率的で、フィルターに適し、説明可能
POST my-index/_search
{
"retriever": {
"rrf": {
"retrievers": [
{
"standard": {
"query": {
"match": {
"text_field": "fox"
}
}
}
},
{
"standard": {
"query": {
"sparse_vector": {
"field": "ml.tokens",
"inference_id": ".elser_model_1",
"query": "a quick brown fox jumps over a lazy dog"
}
}
}
}
]
}
}
}
高密度ベクトルと低密度ベクトルを組み合わせることで柔軟性が得られます。高密度ベクトルは微妙な意味を捉えるのに優れており、低密度ベクトルは現実世界の検索に透明性と拡張性を提供します。
ELSERによるテキスト拡張で改善された結果が得られる仕組みをご覧ください。
実践における高密度ベクトルと低密度ベクトル
| 疎ベクトル(ELSER) | 高密度ベクトル | |
|---|---|---|
| 仕組み | テキストを意味的に関連した重み付けされた用語に拡張します。各次元は、関連する重みを持つトークンに対応します。 | コンテンツ(テキスト、画像など)を固定長の浮動小数点ベクトルにエンコードします。類似の意味 = ベクトル空間内の近接位置。 |
| 強み |
|
|
| ユースケースの例 |
|
|
| 理想的な用途 | セマンティックの改善と透明性が必要な場合、またはドメイン固有の用語が最も重要である場合 | 意味に基づく発見と類似性(正確な単語ではなく)を、さまざまなデータタイプ間で求める場合 |
高密度モデルと低密度モデルを使用したハイブリッド検索
これまで、ハイブリッド検索を実行する2つの異なる方法を見てきました。それは、検索対象が高密度ベクトル空間か低密度ベクトル空間かによって異なります。同じインデックス内に高密度データと提供するデータを混在させることができます。
POST my-index/_search
{
"_source": false,
"fields": [ "text_field" ],
"retriever": {
"rrf": {
"retrievers": [
{
"knn": {
"field": "image_vector",
"query_vector": [0.1, 3.2, ..., 2.1],
"k": 5,
"num_candidates": 100
}
},
{
"standard": {
"query": {
"sparse_vector": {
"field": "ml.tokens",
"inference_id": ".elser_model_1",
"query": "a quick brown fox jumps over a lazy dog"
}
}
}
}
]
}
}
}
詳細:高密度、低密度、BM25Fを使用したハイブリッド検索
この例は3つのリトリーバーを組み合わせ、ランク付けされたリストとRRFを融合させています。
- BM25F(textのmatch):正確なキーワード/フレーズの一致(「snowy mountain」)
- kNN(image_vector):提供された画像埋め込みを用いた視覚的類似性(kはnum_candidatesの結果)
- セマンティック(semantic_text):クエリのセマンティック拡張によるコンセプト一致
rank_window_sizeは結果の融合数を制御し、rank_constantは各リストの寄与をバランスよく調整します。
GET my-index/_search
{
"retriever": {
"rrf": {
"retrievers": [
{
"standard": {
"query": {
"match": {
"text": {
"query": "snowy mountain"
}
}
}
}
},
{
"knn": {
"field": "image_vector",
"query_vector": [
0.01,
0.3,
-0.4
],
"k": 10,
"num_candidates": 100
}
},
{
"standard": {
"query": {
"semantic": {
"field": "semantic_text",
"query": "snowy mountain"
}
}
}
}
],
"rank_window_size": 50,
"rank_constant": 60
}
}
}
ES|QLの同様の例も見てみましょう。
FROM my-index METADATA _score
| FORK (WHERE match(text, "snowy mountain") | SORT _score DESC | LIMIT 50)
(WHERE knn(image_vector, [0.01, 0.3, -0.4], {"min_candidates": 100 }) | SORT _score DESC | LIMIT 50)
(WHERE match(semantic_text, "snowy mountain") | SORT _score DESC | LIMIT 50)
| FUSE RRF WITH {"rank_constant": 60 } // 60はデフォルト値?
| SORT _score DESC
| LIMIT 50まとめ
ハイブリッド検索は、全文検索の精度とセマンティック検索のコンテキスト範囲を組み合わせ、多様なコンテンツに対してより正確で関連性の高い結果を提供します。高密度モデルと低密度モデルの両方をサポートし、線形結合や逆順位融合(RRF)のような柔軟な融合方法を提供することで、クエリとベクトルを直接ペアリングする場合でも、リトリーバーを使用した多段階検索を効率化するユースケースでも、検索をカスタマイズできます。この柔軟性により、ハイブリッド検索は複雑なクエリ、多様なデータ、厳しい関連性要件に対応する強力なアプローチとなっています。
ハイブリッド検索についてさらに詳しく:
- このブログでは、ハイブリッド検索の概要、Elasticsearch がサポートするクエリタイプ、そしてその構築方法について説明します。
- ハイブリッド検索とコンテキストエンジニアリングの進化
- ES|QLにおけるハイブリッド検索と多段階検索
- 面倒なしにハイブリッド検索を実現:レトリバーによるハイブリッド検索の簡素化
ベクトルを超えて先に進みませんか?ElasticsearchのLLMエージェントによるインテリジェントなハイブリッド検索をご覧ください。
実際に使ってみる準備はできましたか?ハイブリッド検索チュートリアルに従って全文とkNNの結果を組み合わせるか、ES|QL チュートリアルを試してES|QLを使用して検索とフィルタリングしてみましょう。