Elasticsearch:データベースやビジネスシステム全体で検索する
ご紹介
Elasticsearchが登場
Elasticsearchにはさまざまな検索手法があり、テキスト検索の業界標準であるBM25も利用できます。また、AIモデルによって強化されたセマンティック検索を提供しており、コンテキストや意図に基づいて結果を改善します。
このガイドでは、外部データベースからElasticsearchへのデータ同期方法と、セマンティック検索を活用してデータベースを簡単に検索する方法を学ぶことができます。
データを取り込む
検索のデータをインジェストし、充実させる方法
Elasticsearchには、ビジネス上の課題の解決に役立つ幅広いデータインジェスト機能が含まれています。このウェビナーでは、次のことを確認できます。
- 分散したデータを1つの場所にまとめて検索エクスペリエンスを構築する方法
- 特定のデータタイプに適したツールを理解しましょう。これには、Open Crawler、コネクタのカタログ、データ、ML推論パイプラインなどが含まれます。
- カスタマーサポートデータセットを使用したライブデモ
Elastic Cloudプロジェクトを作成する
14日間のトライアルをお試しください。cloud.elastic.coにアクセスしてアカウントを作成後、次の手順に従って最初のElasticsearch Serverlessプロジェクトをクラウドで立ち上げます。
開始するには、Elasticsearchを選択します。
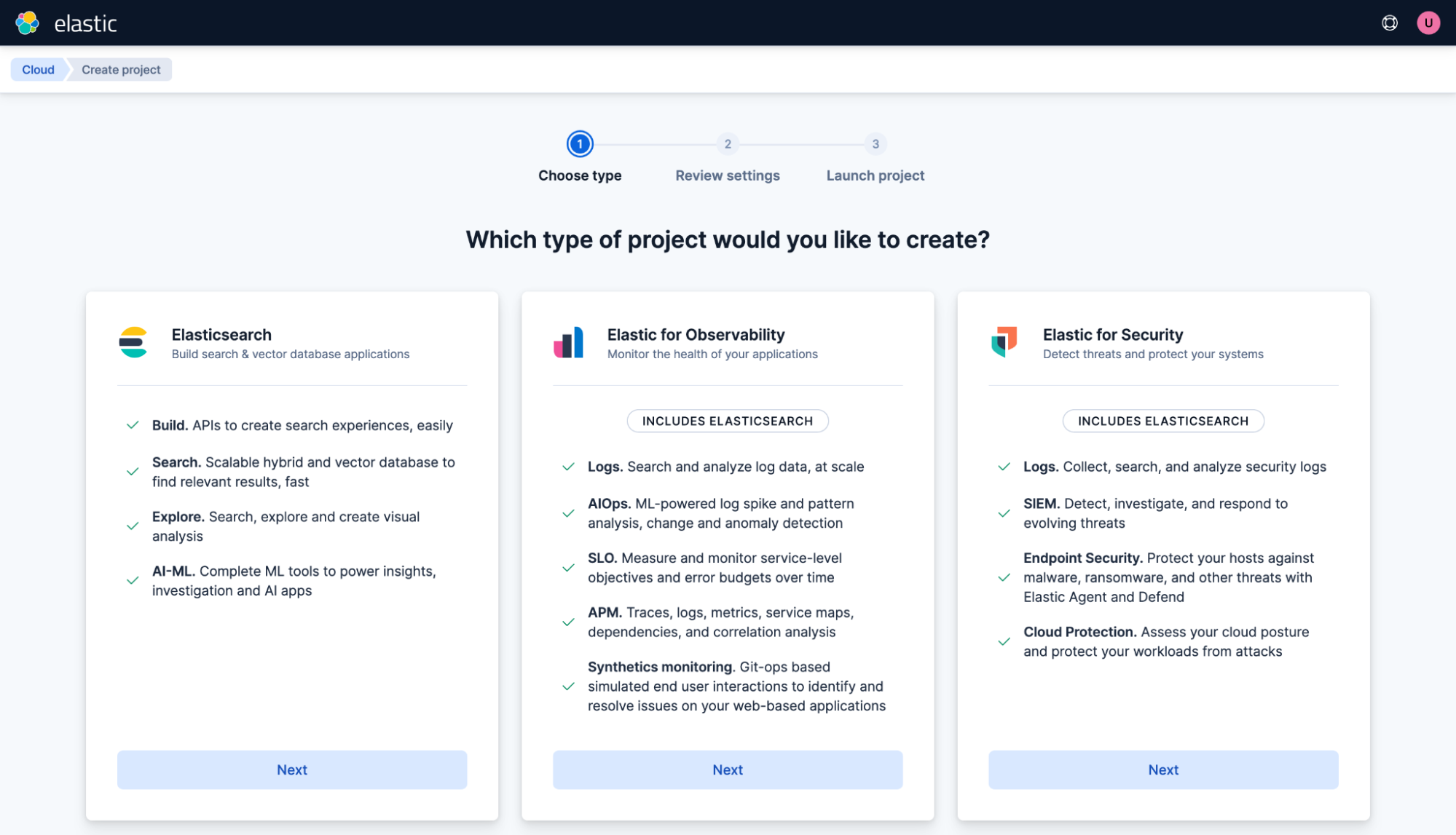
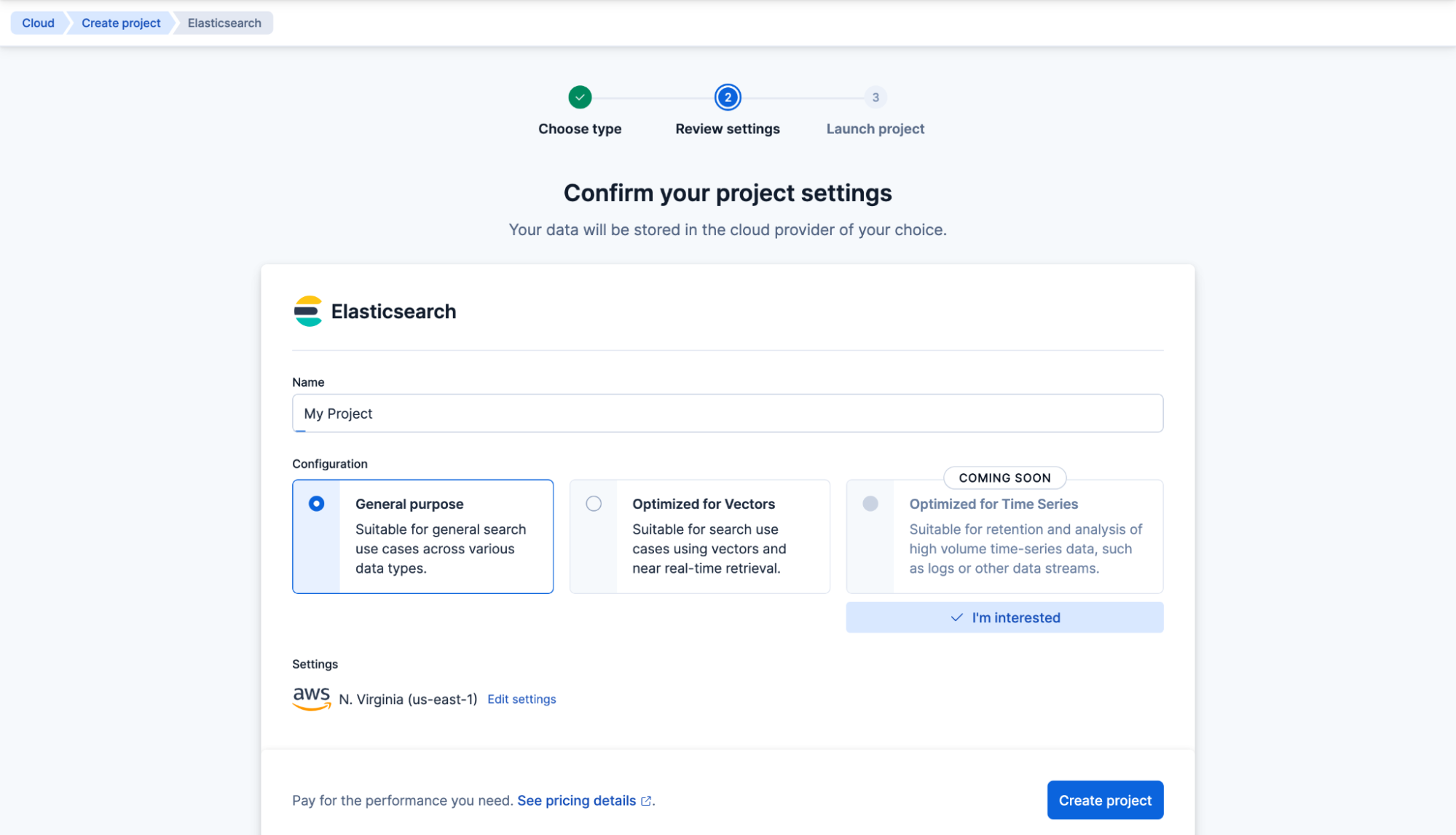
汎用のプロジェクトを作成します。「マイプロジェクト」と名前を付けて、プロジェクトの作成をクリックしてください。
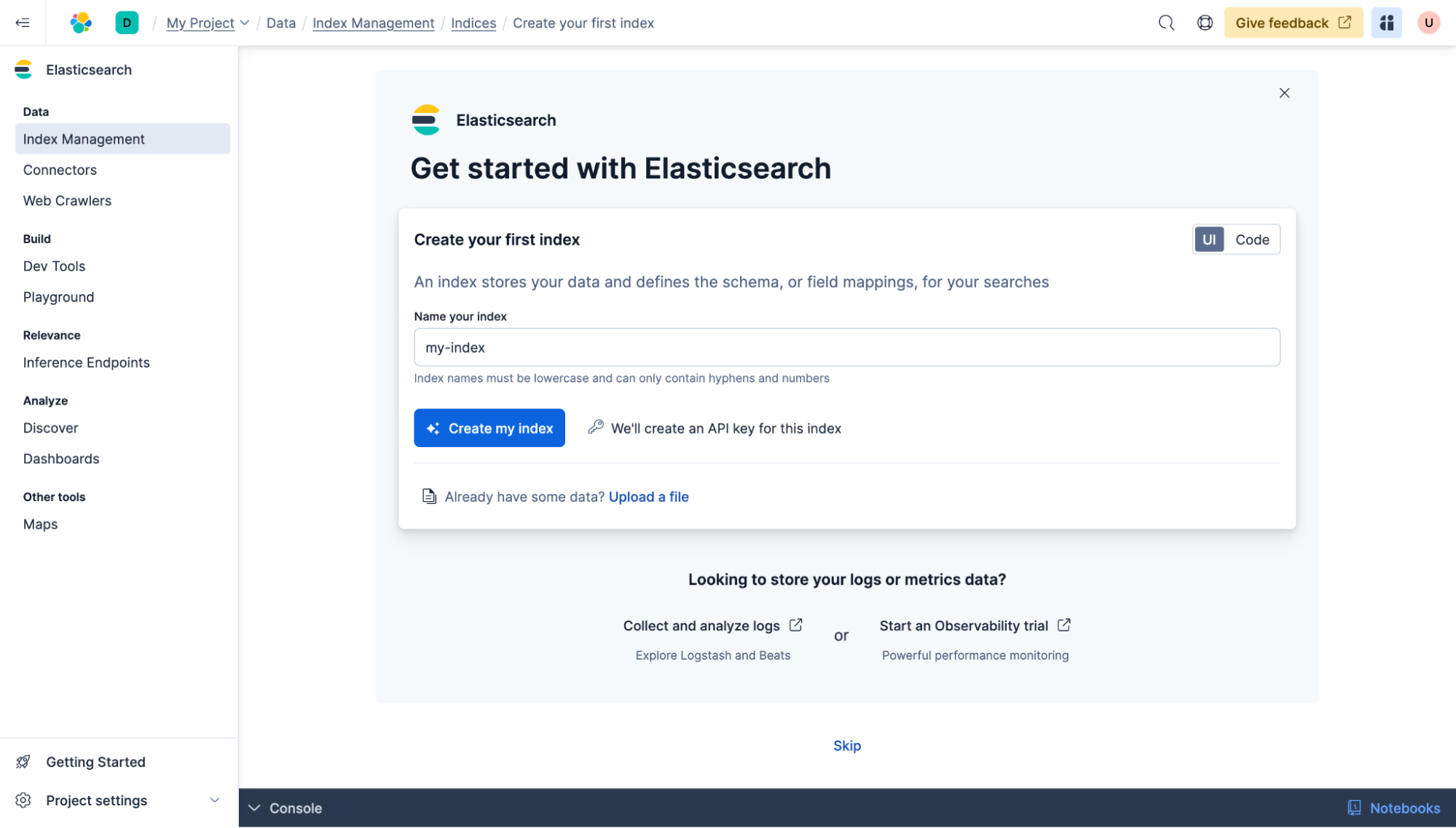
Elasticsearch Serverlessプロジェクトが作成されます。次に、最初のElasticsearchインデックスを作成し、名前を「my-index」にしてください。「インデックスを作成」をクリックしてください。
次に、Elasticsearchにサードパーティのデータソースを追加できます。この例では、約150,000件のビデオゲームタイトルを含むMongoDBデータベースがあり、カラムは「id」、「name」、「description」、「date」です。このデータベースをElasticsearchに同期し、さらに一歩進んで、セマンティック検索機能を追加します。
基本的なインデックスマッピングを作成します。同じフィールド名を使用し、追加で「description_semantic」を作成して、セマンティック検索用のベクトルを保持します。Dev Toolsを開き、次のコマンドを貼り付けてインデックスのマッピングを更新してください:
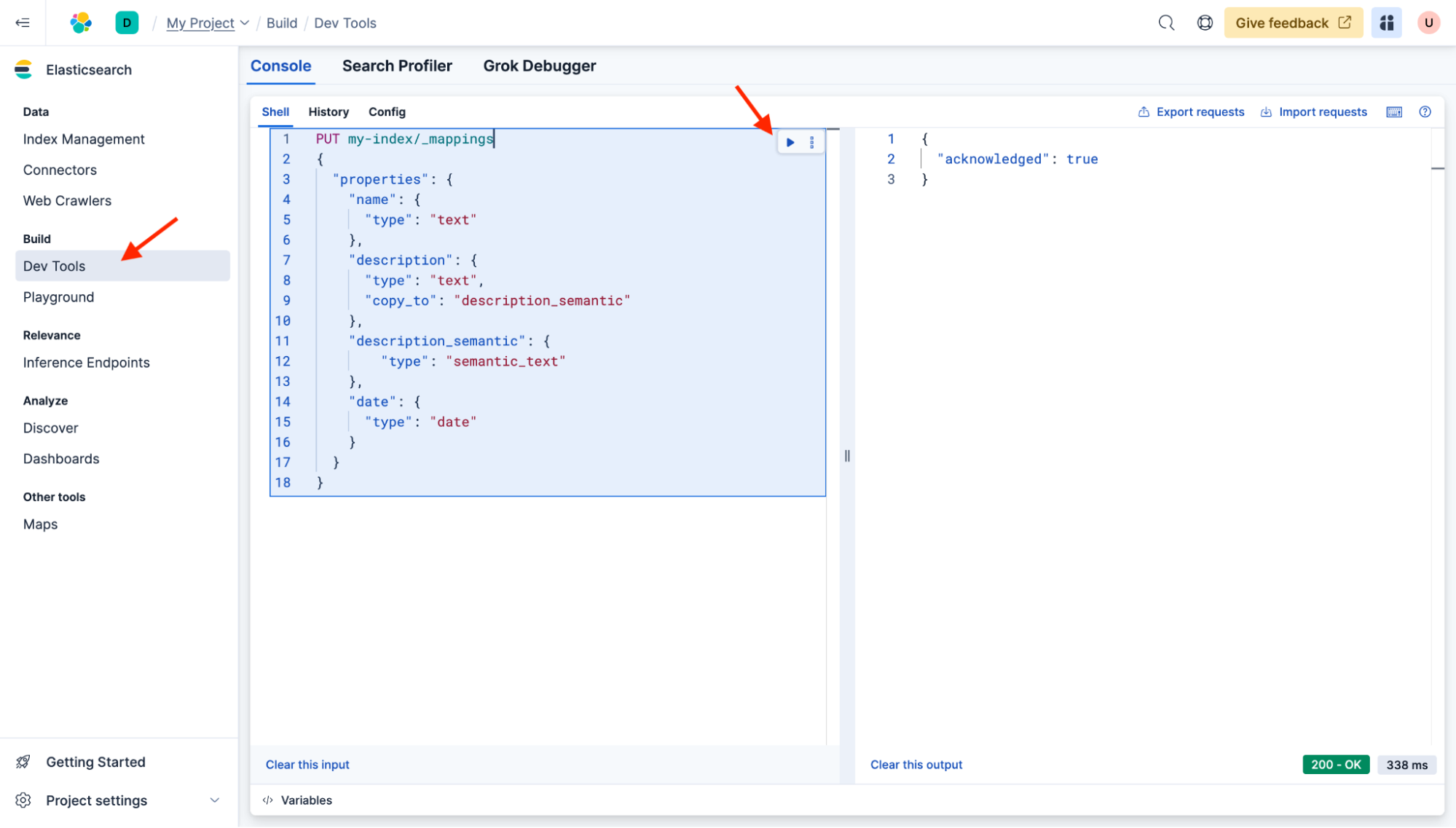
PUT my-index/_mappings
{
"properties": {
"name": {
"type": "text"
},
"description": {
"type": "text",
"copy_to": "description_semantic"
},
"description_semantic": {
"type": "semantic_text"
},
"date": {
"type": "date"
}
}
}
既存のデータベースからのデータの取得
既存のデータベースに接続する準備が整いました。コネクターをクリックし、+セルフマネージド・コネクターをクリックします。
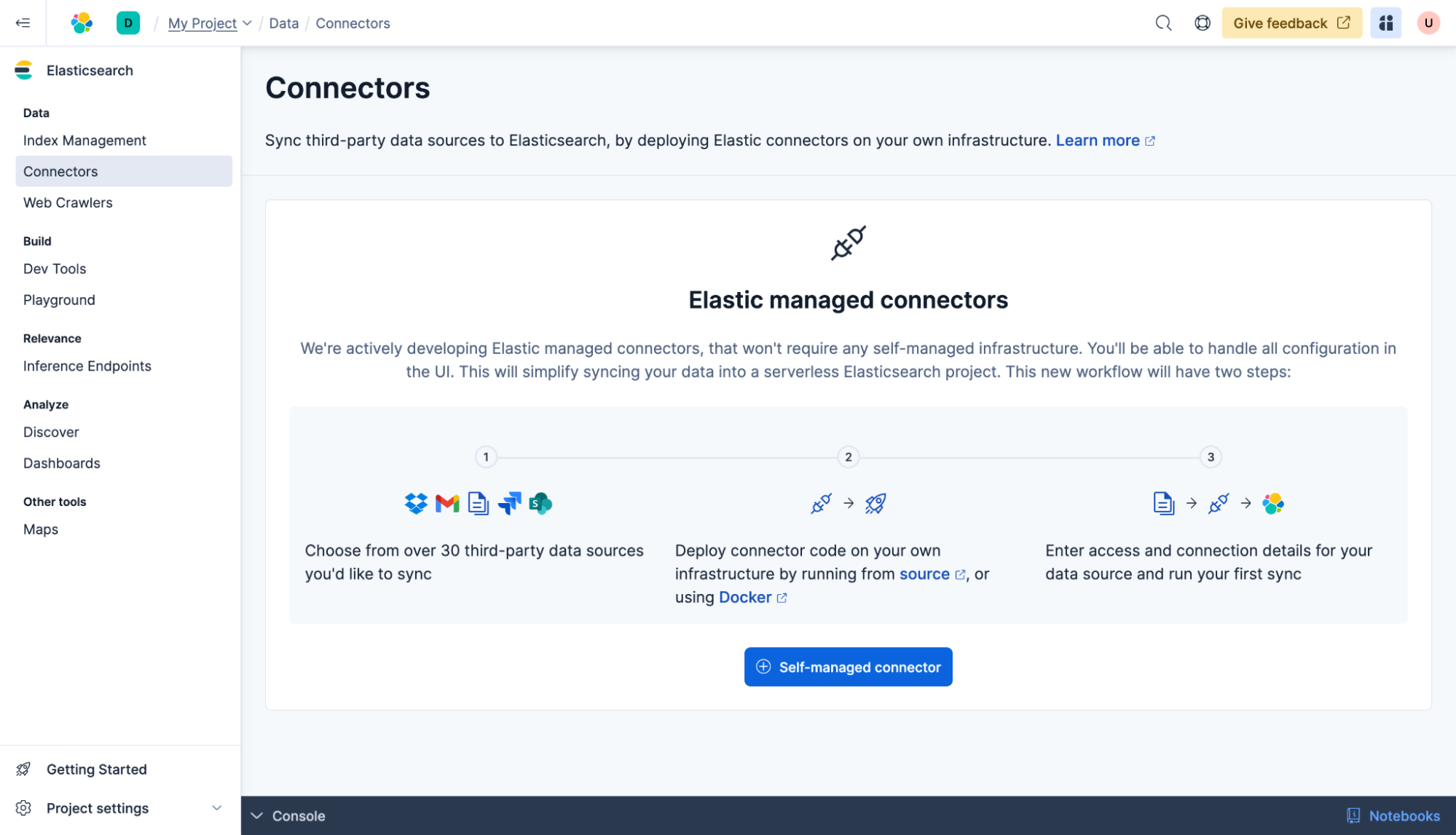
このガイドでは、MongoDBデータベースを使用します。コネクタタイプリストからMongoDBを選択します。
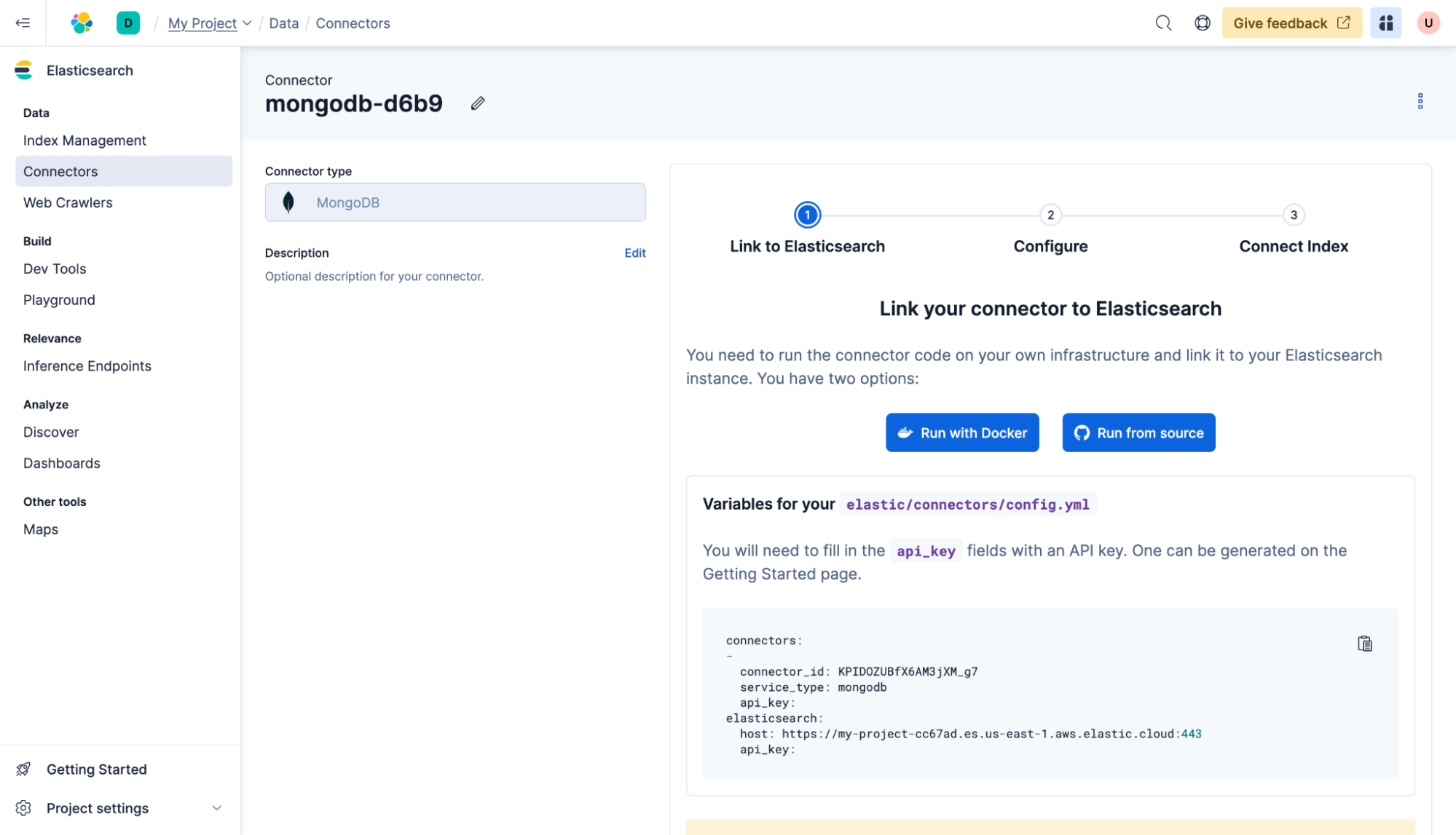
手順に沿って、Dockerを使用してセルフホスト型コネクタをデプロイします。config.ymlファイルを作成する必要があります。ConnectorとElasticsearchの両方で、api_keyは同じであることをご注意ください。例:
connectors:
-
connector_id: KPIDOZUBfX6AM3jXM_g7
service_type: mongodb
api_key: RGZMUU9KVUJmWDZBTTNqWFRQano6R3RRb01jR2kxRkNqWTA5eGtSa3NFZw==
elasticsearch:
host: https://my-project-cc67ad.es.us-east-1.aws.elastic.cloud:443
api_key: RGZMUU9KVUJmWDZBTTNqWFRQano6R3RRb01jR2kxRkNqWTA5eGtSa3NFZw==
次に、以下を使用してセルフマネージドコネクタを起動します。
docker run -v "./connectors-config:/config" --tty --rm docker.elastic.co/enterprise-search/elastic-connectors:8.17.0 /app/bin/elastic-ingest -c /config/config.yml
次に、MongoDBデータベースに設定を追加し、次へ をクリックしてください。
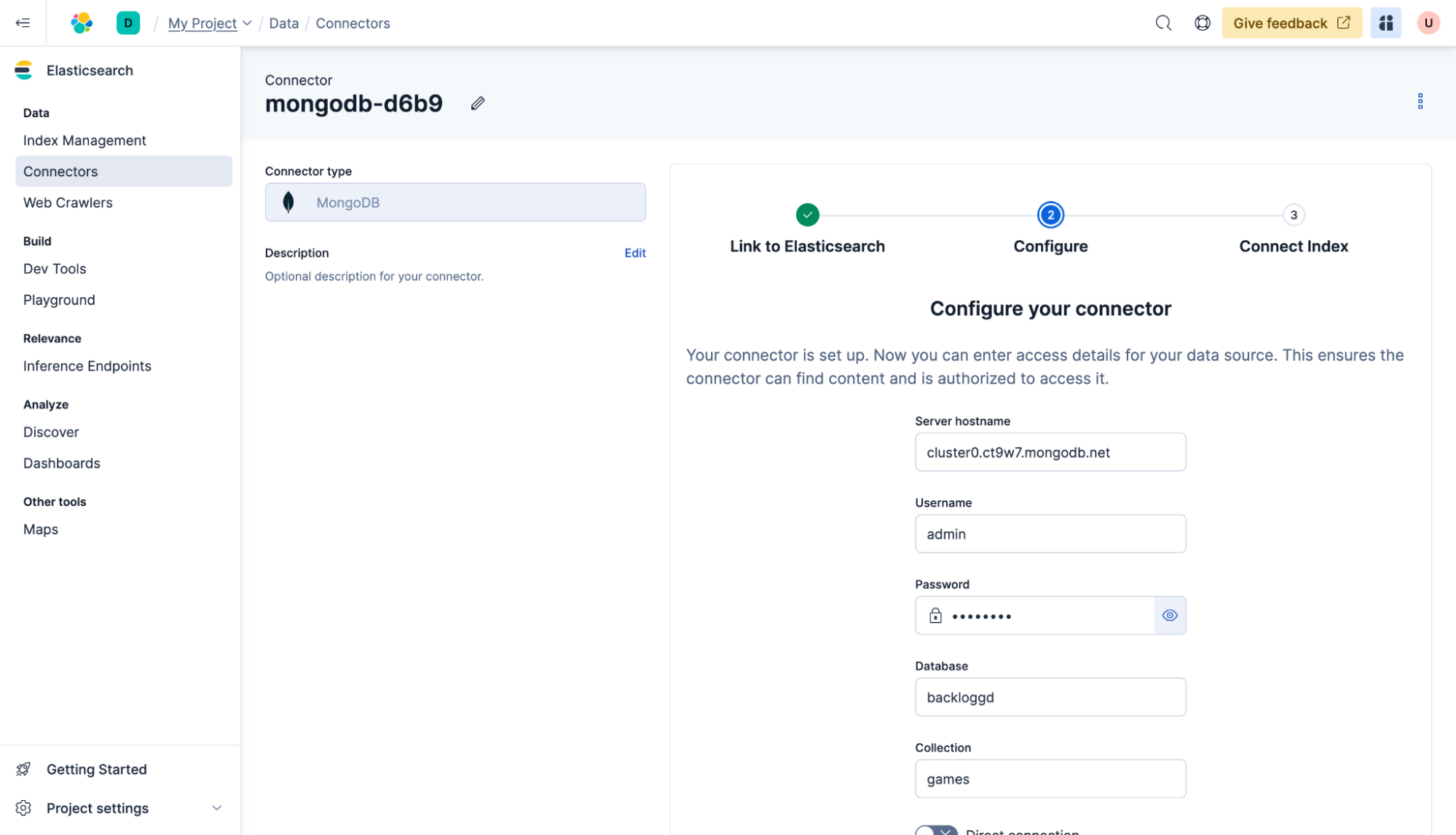
データを同期するインデックスを選択します。この場合は、以前作成した「my-index」です。同期をクリックします。
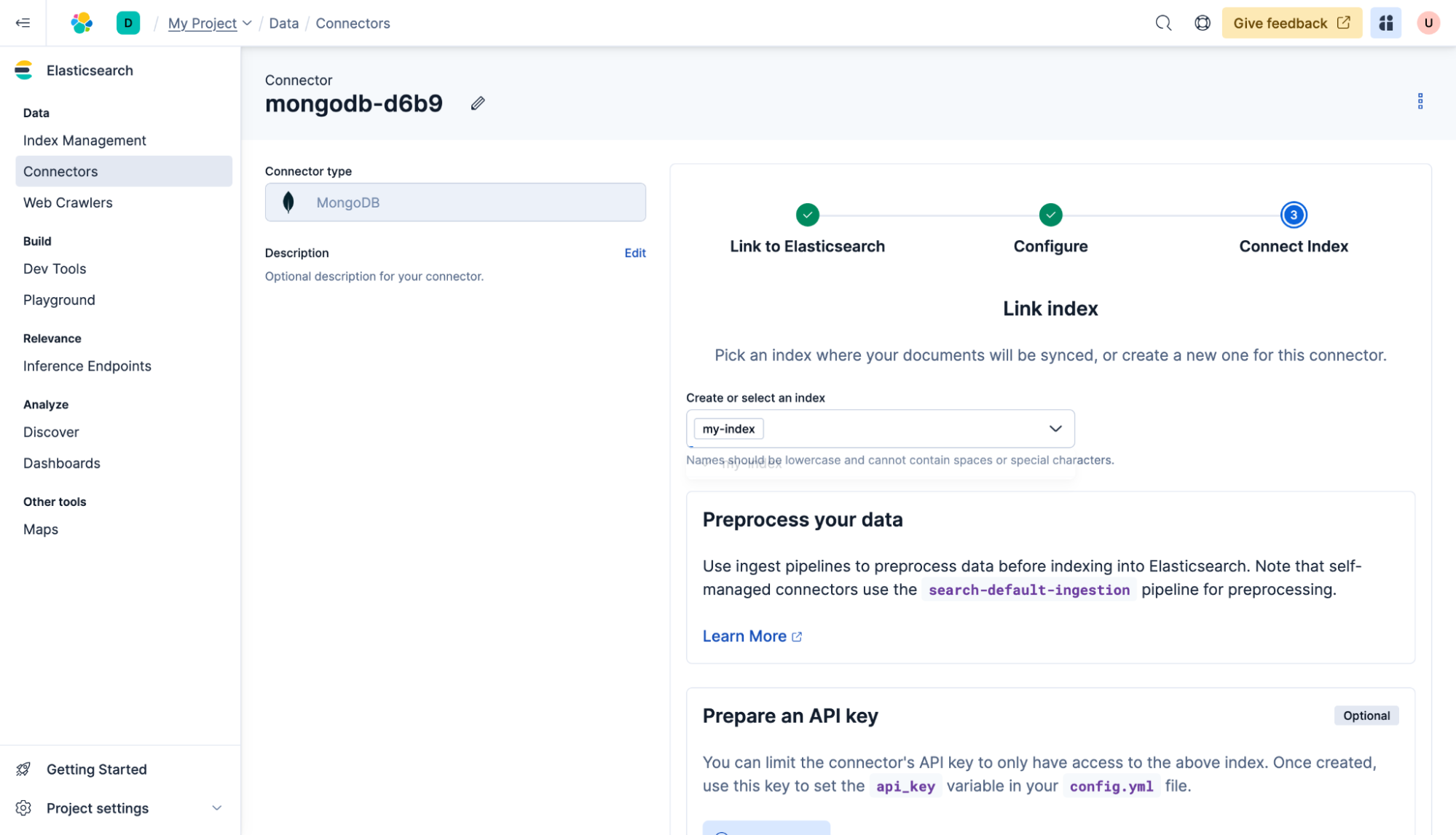
これで完了です!コネクタは、データベースをElasticsearchに定期的に同期するように設定することもできます。メインのコネクタページには、現在のステータスが表示されます。
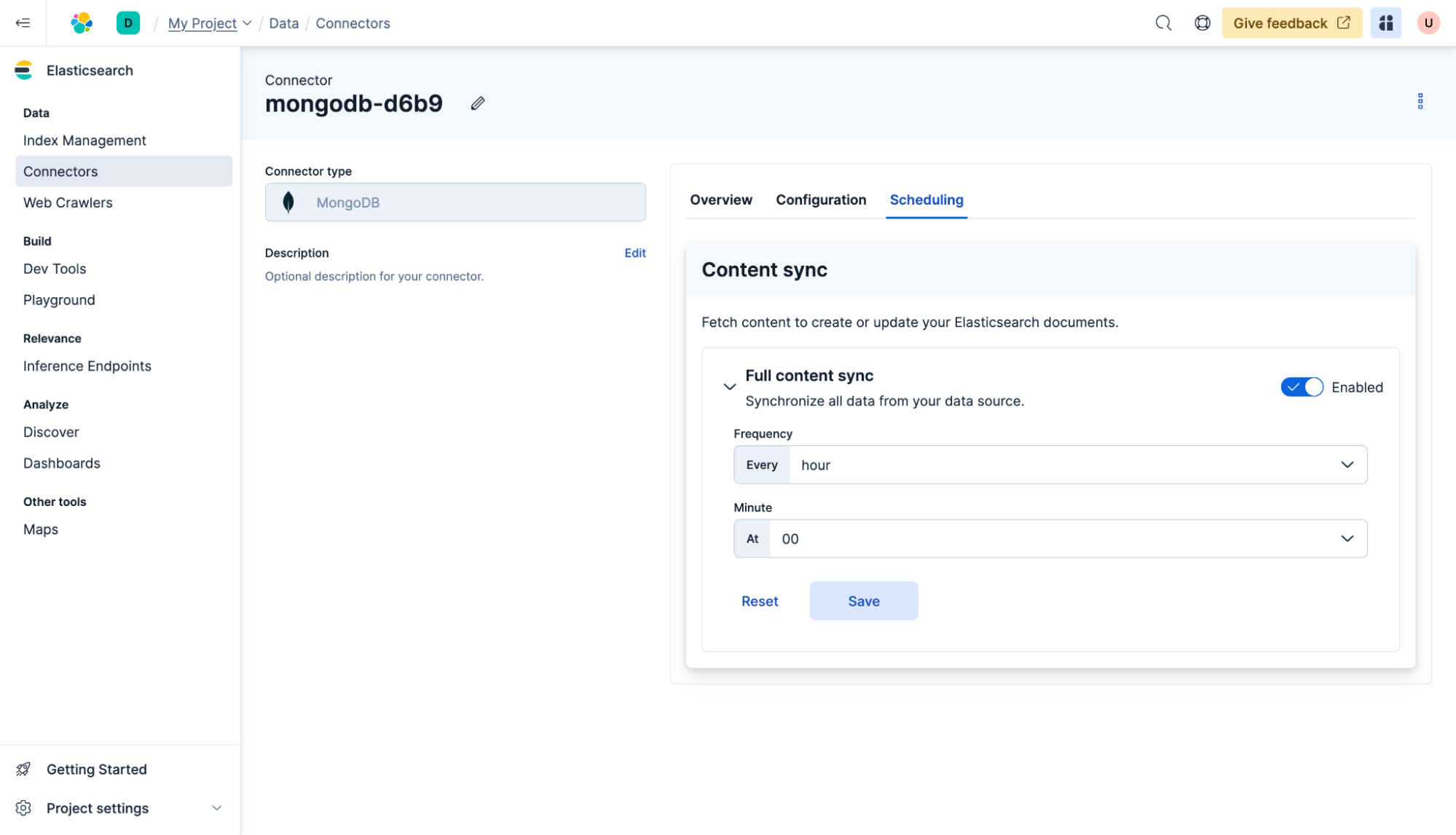
コネクタは、データベースを定期的にElasticsearchに同期するように設定することもできます。そのためには、コネクタをクリックし、次にスケジュール設定をクリックして、毎時間を選択し、保存をクリックします。これで、コンテンツは毎時の最初に同期されるようになります。ただし、自己ホスト型コネクタが稼働している限りです。
Elasticsearchを使用する
データをクエリする
ここからが楽しい部分です。Build > Dev Tools(インデックスマッピングの更新に使用したのと同じセクション)に進み、次のクエリを実行すると、「name」と「description」フィールドの全文検索が行われます。
GET my-index/_search
{
"query": {
"multi_match": {
"query": "adventure game on a desert island",
"fields": [
"name",
"description"
]
}
}
}
インデックスに現在「semantic_text」フィールドが追加されたため、次のようにクエリを実行できます:
GET my-index/_search
{
"query": {
"semantic": {
"field": "description_semantic",
"query": "game about ghosts in medieval times"
}
}
}
これで、外部データベースからElasticsearchにデータを同期し、その上にセマンティック検索を追加する方法を学びました!
今後の見通し
Elastic CloudでPythonを使用し、最初の検索クエリを構築する方法を学んでいただき、誠にありがとうございます。Elasticの導入を始めるにあたって、環境全体でデプロイを行うときにユーザーとして管理すべき運用、セキュリティ、データの要素について理解しましょう。
準備は整いましたか?Elastic Cloudで無料の14日間トライアルを開始するか、こちらのSearch AI 101の15分間ハンズオン学習をお試しください。