信頼できるコンテキストを備えたRAG
AIアプリケーションがユーザーの信頼を構築するには、正確な結果を大規模に提供する必要があります。大規模な言語モデル(LLM)をElasticsearchハイブリッド検索の精度でグラウンディングし、低レイテンシで高効率な検索拡張生成(RAG)を大規模に展開します。
RAGは比類のない精度と効率的なベクトルスケーリングを実現するために構築されています。
本番環境で求められるベクトル性能、コスト効率、セキュリティを備え、適切なコンテキストを提供します。
ハイブリッド検索、セマンティックリランキング、サードパーティ製またはネイティブの最高クラスのJina AIモデルを使用した組み込み推論を活用して、RAGアプリケーションに適切なコンテキストを提供します。単純なベクトルのみの検索を、キーワード、ベクトル、フィルターを組み合わせた単一のクエリに置き換えましょう。

再現の質と支出のトレードオフを強いることなく、構造化データ、非構造化データ、ベクトルデータにまたがる何十億もの文書にコンテキストをスケールできます。DiskBBQのような量子化とディスク最適化アルゴリズムは、低レイテンシで高いランキング品質を保ちながら、メモリを最大95%削減します。

単一のクエリでドキュメント、非構造化レコード、構造化レコードからコンテキストを引き出す統合Platformにより、パイプラインを簡素化します。ドキュメントレベルおよびRBACを実施することで、LLMはユーザーが見るべきデータのみを公開します。
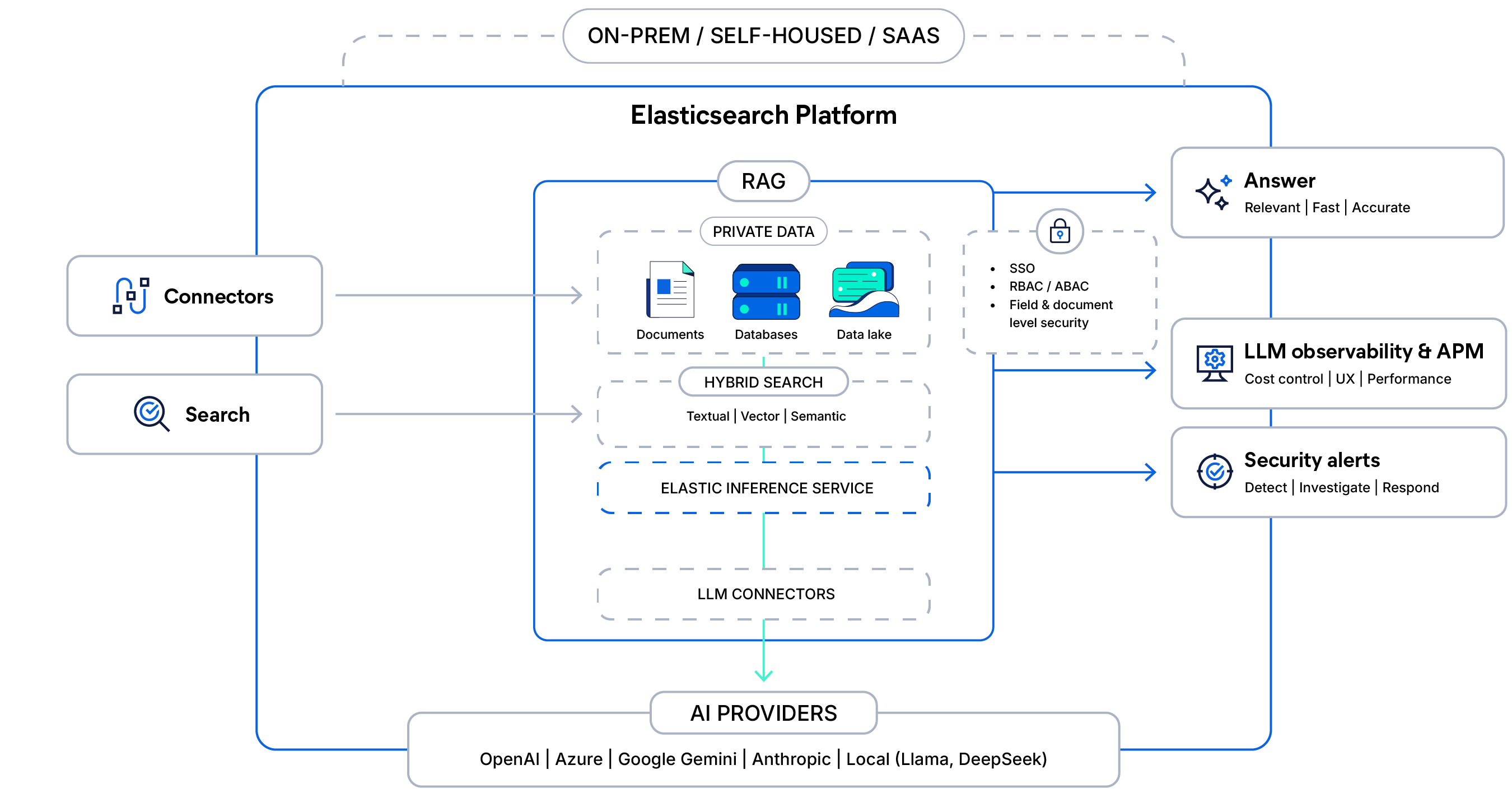
コンテキスト認識型RAGの背後にあるアーキテクチャー
プライベートデータを安全なハイブリッド検索とマネージド推論で結び付け、アクセス制御を使用してLLMの応答を根拠づけ、迅速で観察可能な本番環境対応の回答を大規模に提供します。
何を構築しますか?
データに基づいたチャットを構築し、コンテキストに基づいてエージェントをガイドします。完全なトレーニングカタログをご覧いただくか、Elasticsearch Labsのチュートリアルをご覧ください。


よくあるご質問
AIにおけるRAGとは何ですか?
AIにおけるRAGとは何ですか?
検索拡張生成(通称RAG)は、企業が独自のデータソースを検索し、大規模言語モデルの基盤となるコンテキストを提供する自然言語処理パターンです。これにより、生成AIアプリケーションにおいて、より正確でリアルタイムな対応が可能になります。
RAGの利点は何ですか?
RAGの利点は何ですか?
RAGを最適に実装すれば、関連するドメイン固有の専有データへの安全なアクセスがリアルタイムで提供されます。生成AIアプリケーションにおけるハルシネーションの発生率を低下させ、応答の精度を向上させることができます。
ElasticをRAGワークフローに使用する利点は何ですか?
ElasticをRAGワークフローに使用する利点は何ですか?
Elasticは、質の高いデータの取り込み、大規模での正確で効率的な取得、ロールレベルとドキュメントレベルのセキュリティ、信頼できる対応のためのソースアトリビューションの維持など、最も難しい部分をすぐに解決することで、本番環境のRAGに対応できるようにしています。ネイティブベクトル、レキシカル、ハイブリッド検索、ELSERのようなファーストパーティモデル、生成AIエコシステム全体にわたる柔軟なサードパーティモデル統合、エンタープライズスケールでの実証済みのパフォーマンスにより、Elasticはチームが迅速に立ち上げられ、チューニングが容易で、信頼性の高いRAGシステムを構築できるよう支援します。
Elasticsearchはどのようにしてコンテキストエンジニアリングを可能にするのでしょうか?
Elasticsearchはどのようにしてコンテキストエンジニアリングを可能にするのでしょうか?
Elasticsearchは、コンテキストエンジニアリングの基盤となるスケールでの関連性を実現するように構築されています。ベクトル、キーワード、構造化された検索と分析、推論、オブザーバビリティを1つのプラットフォームにまとめています。これにより、開発者は構造化および非構造化ビジネスデータを正確に格納、取得、ランク付けすることが容易になり、エージェントは常に正しいコンテキストを把握できます。
Agent Builderを使用すると、Elasticsearchはチャット、検索、ツール作成、オーケストレーションをプラットフォームに直接組み込むことで、この性能をさらに強化できます。開発者は、Elasticsearchの関連性、セキュリティ、パフォーマンスによってサポートされている独自のデータ、モデル、ツールを使用して、コンテキスト駆動型エージェントを数分で構築、テスト、スケールできます。