Reindex APIを使用し、トラブルシューティングを行うための3つのベストプラクティス


 Share on Twitter
Share on TwitterTwitter

 Share on LinkedIn
Share on LinkedInリンクトイン

 Share on Facebook
Share on FacebookFacebook

 Share by Email
Share by Emailメール

 Print this page
Print this page印刷
Elasticsearchを使用していると、インデックス間や、Elasticsearchクラスター間でデータを移動したくなることがあります。使用できるバリエーションや機能は複数あり、Reindex APIはその1つです。
このブログ記事では、Reindex APIの概要、APIが機能しているかどうかを知る方法、失敗の原因になること、トラブルシューティングの方法について説明します。
このブログ記事を読み終わると、Reindex APIが持つオプションと、それを信頼できる方法で実行する方法を理解できます。
Reindex APIは、次のようなさまざまなユースケースに特に役立つAPIです。
- クラスター間のデータ転送 (リモートクラスターからのインデックス再作成)
- マッピングの再定義、変更、更新
- インジェストパイプラインによる処理とインデックス作成
- 削除されたドキュメントを消去してストレージ領域を確保する
- クエリフィルターを使用して、大きなインデックスを小さなグループに分割する
中規模または大規模インデックスでReindex APIを実行すると、インデックスを完全に再作成するのに120秒以上かかる可能性があります。つまり、Reindex APIの最終的な応答がなく、いつ終わったのか、成功したのか、失敗したのかがわかりません。
では、見てみましょう。
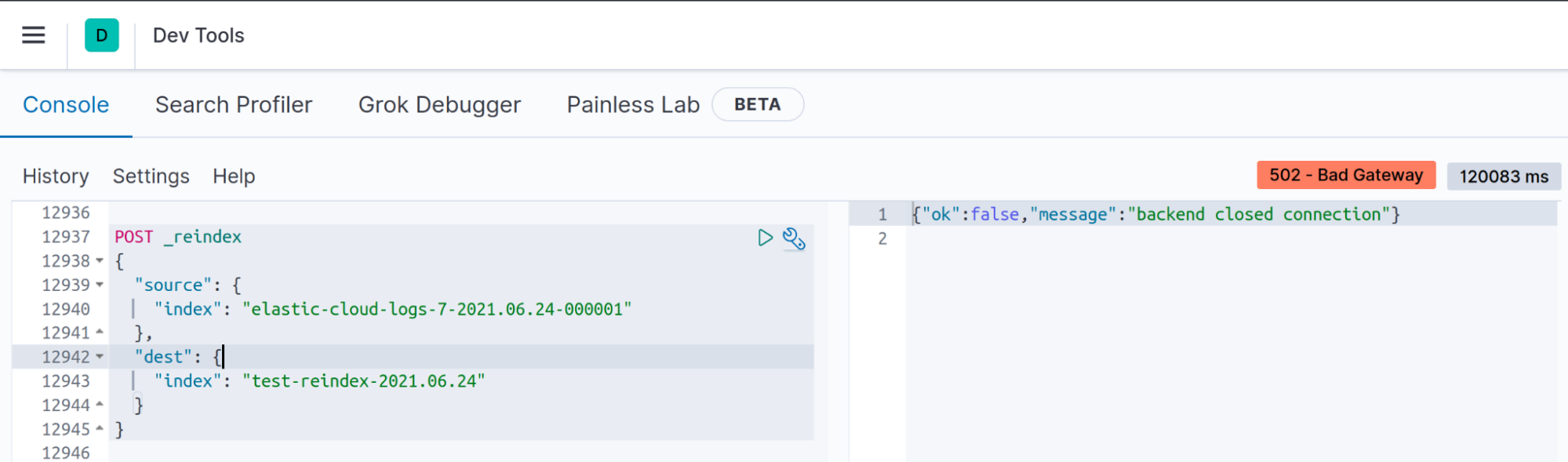
症状:Kibana開発ツールの「Backend closed connection」
中規模または大規模なインデックスでReindex API を実行すると、クライアントとElasticsearchの間の接続がタイムアウトしますが、これはインデックスの再作成が実行されないという意味ではありません。
問題
クライアントはN秒後に非アクティブなソケットをクローズします。たとえば、Kibanaでは、インデックスの再作成処理が120秒未満(v7.13のデフォルトのserver.socketTimeout値)で終了しなかった場合、「backend closed connection」というメッセージが表示されます。
解決策1 - クラスターで実行されているタスクのリストを取得する
Kibanaでこのメッセージが表示されても、裏ではElasticsearchがReindex APIを実行しているので、これは本当の問題ではありません。
Reindex APIの実行を追跡し、_task APIですべてのメトリックを確認できます。
GET _tasks?actions=*reindex&wait_for_completion=false&detailedこのAPIはElasticsearchクラスターで現在実行されているすべてのReindex APIを表示します。もしこのリストにReindex APIが表示されなければ、APIがすでに終了していることを意味します。

図のように、作成されたドキュメント、更新されたドキュメント、あるいは競合に関する詳細が表示されます。
解決策2 - _tasksにインデックス再作成結果を保存する
インデックス再作成処理に120秒以上かかることがわかっている場合(120秒はKibana開発ツールのタイムアウト)、クエリパラメーターwait_for_completion= falseを使ってReindex APIの結果を保存できます。これにより、_task APIを使用して、Reindex APIの最後にステータスを取得できるようになります(wait_for_completion=falseのドキュメントで説明されているように、「.tasks」インデックスからドキュメントを取得することもできます)。
POST _reindex?wait_for_completion=false
{
"conflicts": "proceed",
"source": {
"index": "<source-index-name>"
},
"dest": {
"index": "<dest-index-name>"
}
}
「wait_for_completion=false」を指定してインデックス再作成を実行すると、以下のような応答が返されます。
{
"task" : "a9Aa_I_ZSl-4bjR5vZLnSA:247906"
}
インデックス再作成の結果を検索するには、ここで提供されたタスクを保持する必要があります(作成されたドキュメントの数、競合やエラーの数が表示され、終了時には、かかった時間、バッチ数などが表示されます)。
GET _tasks/a9Aa_I_ZSl-4bjR5vZLnSA:247906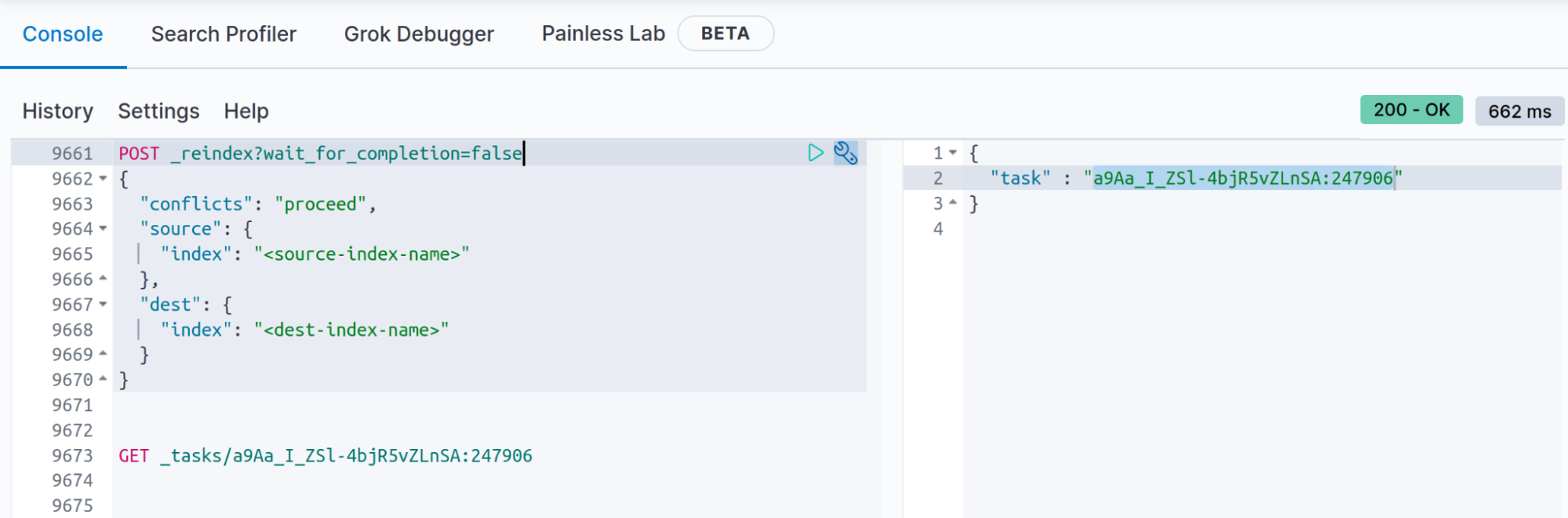
症状:Reindex APIが_task APIリストにない
上記のAPIを使用してもReindex API処理が見つからない場合は、異なる問題が考えられます。1つずつ確認していきましょう。
問題
Reindex APIがリストにない場合は、インデックスを再作成する文書が存在していないか、エラーが発生したために終了したことを意味します。
ここでは、_cat count APIを使って、両方のインデックスに格納されているドキュメント数を確認します。この数値が同じでない場合は、何らかの理由でReindex APIの実行に失敗したことを意味します。
GET _cat/count/<source-index-name>?h=count
GET _cat/count/<dest-index-name>?h=count
解決策1 - 競合の問題
最も頻繁に発生するエラーの1つは、競合が発生することです。デフォルトでは、Reindex APIは競合が発生すると中断します。
今、2つの選択肢があります。
- 「conflicts」の設定を「proceed」にすると、Reindex APIはインデックスを作成できなかったドキュメントを無視し、他のドキュメントのインデックスを作成できるようになります。
- あるいは、競合を修正し、すべてのドキュメントのインデックスを再作成するオプションもあります。
競合を設定した最初のオプションは次のようになります。
POST _reindex
{
"conflicts": "proceed",
"source": {
"index": "<source-index-name>"
},
"dest": {
"index": "<dest-index-name>"
}
}
あるいは、2番目のオプションとして、競合を引き起こすエラーを検索し、修正します。
- この問題を回避するためのベストプラクティスは、デスティネーションインデックスでマッピングまたはテンプレートを定義することです。99%の場合において、これらのエラーは、オリジンインデックスとデスティネーションインデックスの間でフィールド型が一致しないことが原因です。
- マッピングやテンプレートを定義しても問題が残る場合は、一部のドキュメントにインデックスを作成できなかったことを意味し、デフォルトでエラーがログに出力されます。Elasticsearchログでエラーを確認するには、ログを有効にします。
PUT /_cluster/settings
{
"transient": {
"logger.org.elasticsearch.action.bulk.TransportShardBulkAction":"DEBUG"
}
}
- ログが有効になっている状態で、Reindex APIをもう1回実行する必要があります。ソースインデックスとデスティネーションインデックスの間で競合するフィールドが複数ある場合が多いため、可能であれば、「conflicts」設定を「proceed」にします。
- Reindex APIが実行されているため、「failed to execute bulk item」または「MapperParsingException」のログをgrep/検索します。
failed to execute bulk item (index) index {[my-dest-index-00001][_doc][11], source[{
"test-field": "ABC"
}
または
"org.elasticsearch.index.mapper.MapperParsingException: failed to parse field [test-field] of type [long] in document with id '11'. Preview of field's value: 'ABC'",
"at org.elasticsearch.index.mapper.FieldMapper.parse(FieldMapper.java:216) ~[elasticsearch-7.13.4.jar:7.13.4]",
このスタックトレースでは、競合が何であるかを理解するのに十分な情報がすでにあります。このReindex APIでは、デスティネーションインデックスに[long]型の[test-field]というフィールドがあり、Reindex APIはこのフィールドに文字列「ABC」を設定しようとします(「ABC」各自のコンテンツフィールドで置き換えられます)。
Elasticsearchでは、フィールドデータ型を定義できます。インデックス作成の際に設定するか、テンプレートを使用できます。インデックスが作成されると、型を変更することはできないため、まずデスティネーションインデックスを削除してから、先に提供されたオプションを使用して新しい固定マッピングを設定する必要があります。
- エラーを修正したら、ログを詳細度の低いモードに移動することを忘れないでください。
PUT /_cluster/settings
{
"transient": {
"logger.org.elasticsearch.action.bulk.TransportShardBulkAction":NULL
}
}
解決策2 - 競合エラーはないが、インデックス再作成が失敗し続ける
インデックス再作成の実行中に、Elasticsearchのログに次のトレースが見つかった場合:
'search_phase_execution_exception', 'No search context found for id [....]')
異なる理由が考えられます。
- クラスターに不安定性の問題があり、インデックス再作成の実行中にいくつかのデータノードが再起動したり、利用できなくなったりしました。
これが原因の場合、インデックス再作成を実行する前に、クラスターが安定しており、すべてのデータノードが正常に動作していることを確認してください。 - リモートからインデックス再作成操作を行っていて、ノード間のネットワークが信頼できないことがわかっている場合:
- スナップショットAPIは優れたオプションです(このブログ記事の結論を参照)。
- 手動でReindex APIをスライスしてみましょう、この処理によって、リクエストのプロセスをより小さな部分に分割することができます(このオプションは、同一クラスター内でReindex APIを使用する場合です)。
Elasticsearchクラスターにオーバーシャーディングの問題、リソースの使用率の高さ、ガベージコレクションの問題がある場合、スクロール検索クエリ中にタイムアウトが発生する可能性があります。デフォルトのスクロールタイムアウト値は5分なので、Reindex APIのscroll設定をもっと大きな値にして試してみてください。
POST _reindex?scroll=2h
{
"source": {
"index": "<source-index-name>"
},
"dest": {
"index": "<dest-index-name>"
}
}
症状:Elasticsearchのログに「Node not connected」と表示される
クラスターが安定し、ステータスが良好である状態でReindex APIを実行することを常にお勧めします。クラスターは検索とインデックスアクションを実行するのに十分な容量が必要です。
問題
NodeNotConnectedException[[node-name][inet[ip:9300]] Node not connected]; ]
ログにこのエラーがある場合は、クラスターの安定性と接続性に問題があり、Reindex APIだけが失敗しているわけではないことを意味します。
しかし、接続性の問題を認識していながら、Reindex APIを実行する必要があるとします。
ソリューション
接続の問題を修正します。
しかし、接続性の問題は認識していながら、Reindex APIを実行する必要があるとします。失敗する可能性を減らすことはできますが、これは修正ではなく、すべての異なるケースで機能するわけでもありません。
- オリジンまたはデスティネーションインデックス(プライマリまたはレプリカ)のシャードを、接続性に問題があるノードから移動します。シャードを移動するには、allocation filtering APIを使用します。
- また、デスティネーションインデックス上のレプリカを削除することもできます(デスティネーションインデックス上のみ)。これはReindex APIを高速化します。インデックス再作成がより速く実行されれば、失敗の可能性はより低くなります。
PUT /<dest-index-name>/_settings
{
"index" : {
"number_of_replicas" : 0
}
}
両方の処理を行ってもReindex APIが成功しない場合は、まず安定性の問題を解決する必要があります。
症状:ログにエラーはないが、両インデックスのドキュメント数が一致しません
Reindex APIが終了しても、オリジンのドキュメント数とデスティネーションのドキュメント数が一致しないことがあります。
問題
複数のソースから1つの宛先にインデックスを再作成しようとすると(多くのインデックスを1つにマージする)、それらのドキュメントに割り当てられた_idに問題がある可能性があります。
次の2つのソースインデックスがあるとします。
- インデックスA、_id:1、メッセージ:「Hello A」
- インデックスB、_id:1、メッセージ:「Hello B」
両方のインデックスをCにマージすると、次のようになります。
- インデックスC、_id:1、メッセージ:「Hello B」
どちらのドキュメントも同じ_idなので、最後にインデックスされたドキュメントが前のドキュメントを上書きするだけです。
ソリューション
インジェストパイプラインとして、あるいはReindex APIでpainlessを使うなど、さまざまな選択肢があります。このブログ記事では、リクエスト本文に「painless」を指定したスクリプトオプションを使用します。
元の_idを使い、ソースインデックス名を追加するだけです。
POST _reindex
{
"source": {
"index": "<source-index-name>"
},
"dest": {
"index": "<dest-index-name>"
},
"script": {
"source": "ctx._id = ctx._id + '-' + ctx._index;"
}
}
そして、前の例では次のようになります。
- インデックスA、_id:1、メッセージ:「Hello A」
- インデックスB、_id:1、メッセージ:「Hello B」
両方のインデックスをCにマージすると、次のようになります。
- インデックスC、_id:1-A、メッセージ:「Hello A」
- インデックスC、_id:1-B、メッセージ:「Hello B」
まとめ
Reindex APIは、いくつかのフィールドの形式を変更する必要がある場合に最適なオプションです。ここでは、Reindex APIを可能なかぎりスムーズに動作させるために重要な点を挙げます。
- デスティネーションインデックスのマッピング(またはテンプレート)を作成して定義します。
- Reindex APIが可能なかぎり高速にドキュメントのインデックスを作成できるように、デスティネーションインデックスを調整します。インデックス作成を調整し、高速化できるすべてのオプションに関するドキュメンテーションページを用意しました。
https://www.elastic.co/guide/en/elasticsearch/reference/current/tune-for-indexing-speed.html - ソースインデックスのサイズが中程度または大きい場合、「wait_for_completion=false」設定を定義して、Reindex APIの結果を_tasks APIに格納するようにしてください。
- インデックスをより小さなグループに分割するには、クエリ(範囲、条件など)を使用して異なるグループを定義するか、スライシング機能を使用してリクエストをより小さな部分に分割します。
- Reindex APIを実行する際には安定性が重要であり、Reindex APIに関係するインデックスは良好ステータス(最悪の場合でも注意ステータス)である必要があります。そして、データノードに長いGarbageCollectionsがないこと、CPUとディスクの使用率が正常な値であることを確認してください。
v7.11以降、データのインデックス再作成の必要性を回避するための新機能をリリースしました。これは「ランタイムフィールド」と呼ばれます。このAPIでは、インデックスマッピングや検索リクエストでランタイムフィールドを定義することができるため、データのインデックスを再作成することなくエラーを修正できます。どちらのオプションも、インジェスト後にドキュメントのスキーマを柔軟に変更し、検索クエリの一部としてのみ存在するフィールドを生成できます。
ランタイムフィールド機能の優れた例として、マッピングにすでに存在するフィールドと同じ名前のランタイムフィールドを作成する機能があります。ランタイムフィールドがマッピングされたフィールドをシャドーイングするので、それをテストするには、こちらの手順に従ってください。
ランタイムフィールドについての詳細は、ドキュメントまたははじめにブログ記事をご覧ください。
あるクラスター間でデータを移動しようとする場合、スsnapshot-restore APIを使用できます。スナップショットを使用すると、クラスターがデータを検索し、インデックスを再作成する必要がなくなるため、より高速にデータを移動できます。 両方のクラスターが同じスナップショットリポジトリにアクセスできるようにする必要があります。詳細はsnapshot APIを参照してください。
インデックスの再作成に関するよくある質問と、よくあるエラーの解決策を取り上げました。問題解決で行き詰まった際には、お気兼ねなくお知らせください。喜んでサポートいたします。Elastic Discuss、ElasticコミュニティのSlack、コンサルティング、トレーニング、サポートからお問い合わせください。
シェアする
- Share on Twitter
Twitter
- Share on LinkedIn
リンクトイン
- Share on Facebook
Facebook
- Share by Email
メール
- Print this page
印刷