¿Qué es la búsqueda híbrida?
Dos o más métodos de recuperación. Una lista clasificada.
La búsqueda híbrida es una técnica de recuperación de información que combina dos o más métodos de búsqueda (por ejemplo, búsqueda léxica y búsqueda semántica) en una sola lista clasificada para mejorar la relevancia y la recuperación. El emparejamiento más común combina la búsqueda léxica de texto completo, que es excelente para hacer coincidir palabras y frases exactas, con la búsqueda vectorial semántica, que interpreta el significado detrás de una búsqueda. El lado léxico agrega precisión y el lado semántico ofrece una comprensión profunda de la intención subyacente del usuario.
Estos métodos se ejecutan juntos en una sola búsqueda, y luego sus resultados se fusionan en una clasificación cohesiva usando estrategias de fusión especializadas. Si bien léxica + semántica es la combinación más popular, la búsqueda híbrida puede unir otros enfoques, como la búsqueda geoespacial + semántica o incluso la búsqueda de texto + imagen, para adaptarse a diferentes necesidades.
Por qué es importante la búsqueda híbrida
La búsqueda híbrida reduce las inconsistencias de los métodos de recuperación individuales, al tiempo que aprovecha sus fortalezas en un solo pipeline. La IA moderna debe procesar diversas modalidades, texto, imágenes, audio, logs y mucho más y conectar la intención con los datos. La relevancia se está volviendo más crítica que nunca. En el comercio electrónico, por ejemplo, una experiencia de búsqueda puede tener éxito si ayuda a los usuarios a filtrar y refinar rápidamente los resultados, pero un agente de IA a menudo requiere una única respuesta muy relevante para responder a una pregunta o realizar una acción. Por eso la capacidad de combinar y optimizar técnicas de recuperación es importante hoy en día, lo cual impulsa no solo los resultados de búsqueda tradicionales sino también agentes conversacionales que ofrecen respuestas precisas y fundamentadas con datos.
Antes de profundizar en la búsqueda híbrida, veamos rápidamente cómo difieren la búsqueda léxica y la búsqueda semántica, y por qué se complementan entre sí.
Explicación de la búsqueda léxica
La búsqueda léxica es ideal cuando tienes datos bien estructurados y los usuarios saben lo que buscan. Coincide con términos exactos, lo que la hace altamente precisa y explicable, basándose en un algoritmo de puntuación de relevancia (como BM25F) para clasificar documentos por la frecuencia y rareza de los términos de búsqueda. Este enfoque ofrece una puntuación transparente y admite una relevancia ajustada mediante mejoras de campo, sinónimos y analizadores. Debido a que no tiene sobrecarga de modelo, la búsqueda léxica es rápida y eficiente, con filtros y facetas que se desempeñan de manera confiable incluso a escala sin ralentizaciones ni exploraciones de índice completas. Es particularmente efectiva para búsquedas estructuradas, términos poco frecuentes y lenguaje específico del dominio.
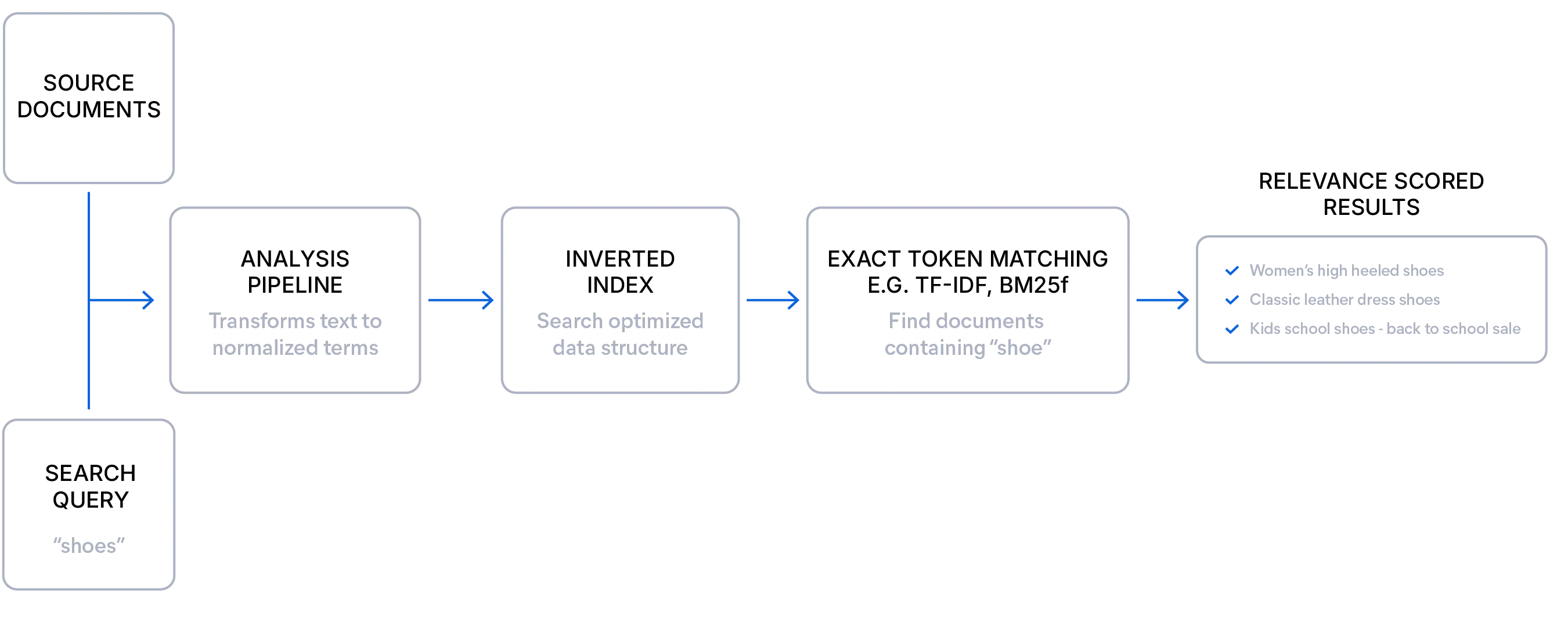
Aquí hay un ejemplo simple de una búsqueda léxica:
GET example-index/_search
{
"query": {
"term": {
"text": "blue shoes"
}
}
}
Veamos también un ejemplo de búsqueda léxica similar con el lenguaje de búsqueda de Elasticsearch (ES|QL) para un blog de cocina. El blog contiene recetas con varios atributos, incluyendo contenido textual, datos categóricos y calificaciones numéricas.
FROM cooking_blog METADATA _score | WHERE description:"fluffy pancakes" | KEEP title, description, _score | SORT _score DESC | LIMIT 1000
Esta búsqueda apunta a encontrar en el campo descripción documentos que contengan "fluffy" O "pancakes" (o ambos). Por defecto, ES|QL emplea lógica O entre términos de búsqueda, por lo que coincide con documentos que contienen cualquiera de las palabras especificadas. Puedes especificar exactamente qué campos incluir en tus resultados usando el comando KEEP y aplicar los metadatos de _score para clasificar los resultados de búsqueda dependiendo de que tan bien coincidan con tu búsqueda.
Aprende más sobre la búsqueda léxica con este tutorial práctico.
Explicación de la búsqueda semántica
La búsqueda semántica recupera resultados basados en la similitud de significado entre una búsqueda y documentos, en lugar de simplemente hacer coincidir términos exactos como en la búsqueda léxica.
Un modelo de incrustación convierte el significado de tu texto u otros medios en una representación numérica llamada vector. Estos vectores —una lista de números— capturan el contexto y tema subyacentes del texto y se almacenan en una base de datos vectorial como Elasticsearch.
Esto permite al motor de búsqueda encontrar resultados conceptualmente similares, incluso cuando no comparten ninguna palabra exacta con la búsqueda.
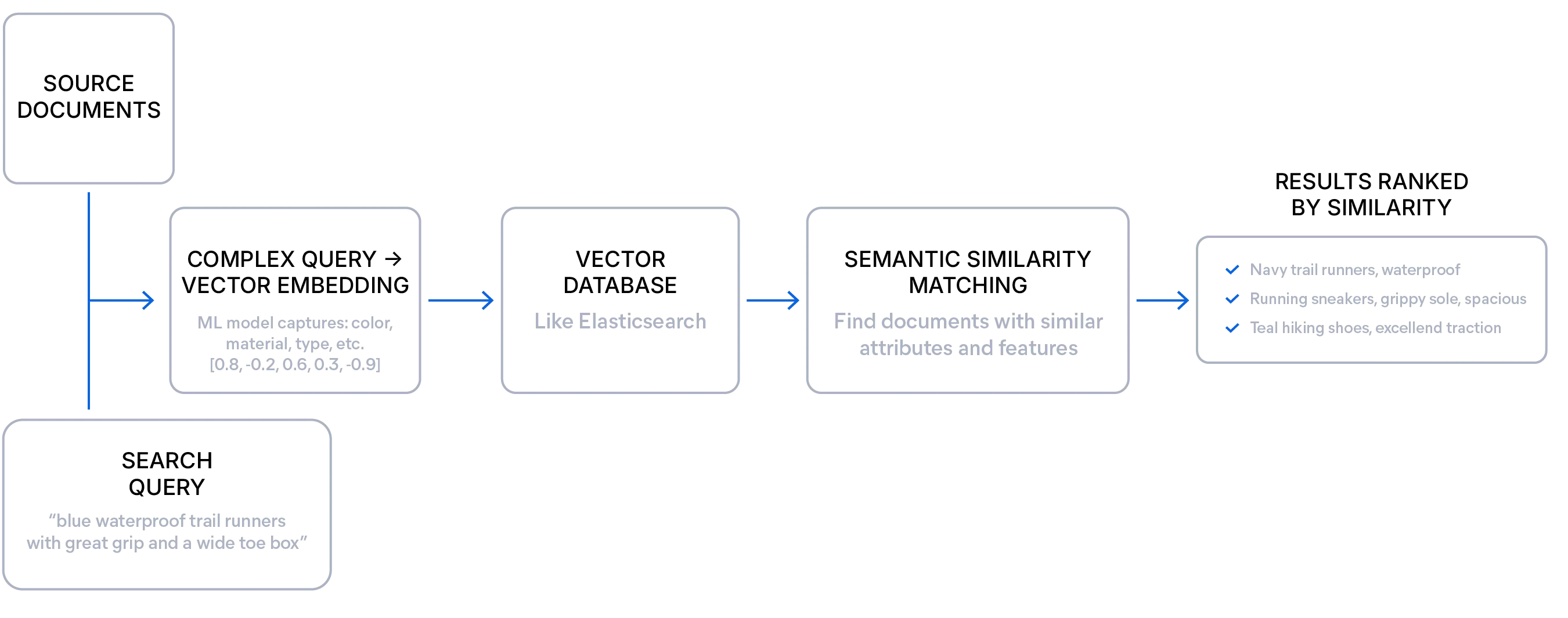
Este enfoque resulta especialmente útil para datos no estructurados, búsquedas exploratorias y casos en los que los usuarios pueden no conocer los términos exactos que deben usar. Los desarrolladores pueden aprovechar la búsqueda semántica para ofrecer resultados más relevantes y manejar frases vagas, verbosas o ambiguas sin dejar de mostrar las respuestas correctas.
A continuación se muestra un ejemplo de consulta de búsqueda semántica:
GET example-index/_search
{
"query": {
"semantic": {
"field": "inference_field",
"query": "blue waterproof trail runners with great grip and a wide toe box"
}
}
}
ES|QL soporta la búsqueda semántica cuando tus mappings incluyen campos del tipo semantic_text. Una vez que el documento ha sido procesado por el modelo subyacente que se ejecuta en el endpoint de inferencia, puedes realizar una búsqueda semántica. Aquí hay un ejemplo de búsqueda de lenguaje natural en relación con el campo semantic_description:
FROM cooking_blog METADATA _score | WHERE semantic_description:"¿Cuáles son algunas comidas a base de plantas fáciles de preparar pero nutritivas?" | SORT _score DESC | LIMIT 5
Obtén más información sobre la búsqueda semántica o prueba este tutorial práctico para un análisis más a fondo.
Los algoritmos léxicos como BM25F sobresalen en precisión cuando los términos de búsqueda coinciden con los términos del documento, pero fallan cuando el contenido relevante se expresa de manera diferente. (Por ejemplo, una búsqueda para "calzado deportivo" podría perder documentos que solo dicen "zapatos" o "corredor de senderos".) La búsqueda vectorial semántica, utilizando incrustaciones de alta dimensión y algoritmos aproximados del vecino más cercano (ANN) (por ejemplo, HNSW), recupera documentos conceptualmente similares independientemente de la superposición exacta de términos, pero puede introducir ruido si el contexto es ambiguo.
Cómo funciona la búsqueda híbrida
¿Y si pudieras obtener lo mejor de ambos mundos? Entra en la búsqueda híbrida. Cuando se hace bien, la búsqueda híbrida es más que la suma de sus partes; puede producir resultados mucho mejores que la búsqueda léxica o semántica por sí sola. Hybrid te da ambos, con relevancia equilibrada, mejor ganancia acumulativa descontada normalizada (NDCG) y mayor recuperación sin necesidad de usar un segundo sistema de búsqueda.
A continuación se muestra una búsqueda híbrida de ejemplo:
GET example-index/_search
{
"retriever": {
"rrf": {
"retrievers": [
{
"standard": {
"query": {
"term": {
"description": "shoes"
}
}
}
},
{
"knn": {
"field": "vector",
"query_vector": [1.25, 2, 3.5],
"k": 50,
"num_candidates": 100
}
}
],
"rank_constant": 20,
"rank_window_size": 50
}
}
}
También puedes combinar texto completo y búsquedas semánticas en ES|QL. En este ejemplo, combinamos la búsqueda semántica y de texto completo con ponderaciones personalizadas:
FROM my-index METADATA _score
| FORK ( WHERE match(text_field:"shoes") | SORT _score DESC | LIMIT 50)
( WHERE knn(vector, [1.25, 2, 3.5], { "min_candidates" : 100 }) | SORT _score DESC | LIMIT 50 ) // k for knn is derived from LIMIT
| FUSE RRF WITH { "rank_constant": 20 }
| SORT _score DESC
| LIMIT 50
Ejecutar una búsqueda híbrida normalmente implica realizar al menos una búsqueda léxica y una búsqueda semántica, y luego combinar sus resultados. El principal desafío radica en fusionar múltiples listas clasificadas en una única clasificación coherente.
Las puntuaciones de búsqueda léxica, generadas por algoritmos como BM25F o TF-IDF, pueden ser ilimitadas, con valores máximos influenciados por la frecuencia de los términos y la distribución de los documentos. Por el contrario, los puntajes de búsqueda semántica generalmente se encuentran dentro de un rango fijo, determinado por la función de similitud (por ejemplo, [0, 2] para similitud de coseno).
Para fusionarlos, necesitas un método de fusión que mantenga la relevancia relativa de los documentos recuperados.
Búsqueda híbrida con Elasticsearch
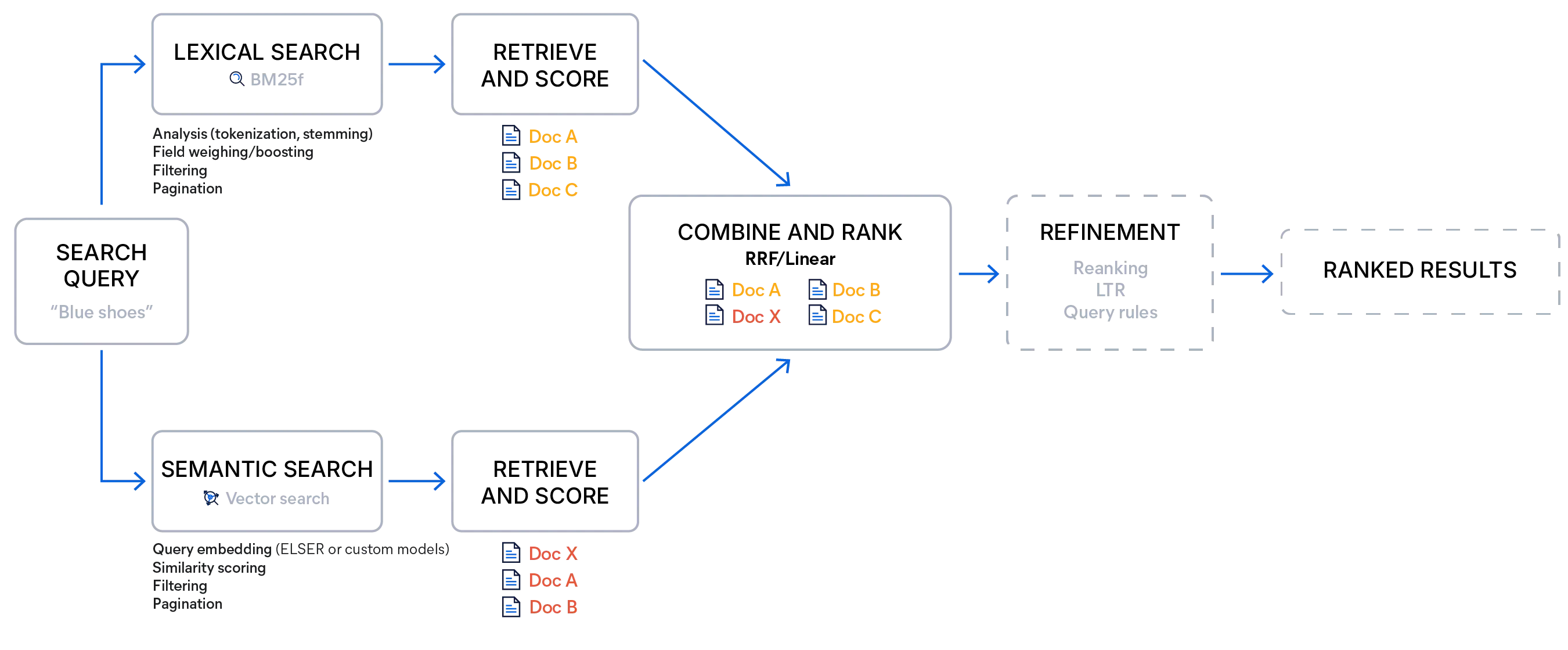
La búsqueda híbrida con Elasticsearch se puede implementar emparejando una búsqueda de palabras clave estándar con una búsqueda vectorial o usando un recuperador, una opción de búsqueda que ejecuta múltiples búsquedas de diferentes tipos y fusiona sus resultados en una sola lista clasificada usando un método de puntuación elegido. Esto permite pipelines de recuperación de varias etapas dentro de una sola llamada de búsqueda, lo que elimina la necesidad de múltiples solicitudes o lógica adicional del lado del cliente para combinar resultados.
Elasticsearch ofrece dos métodos de fusión integrados: fusión de rango recíproco (RRF) y combinación lineal (a menudo denominada «recuperador lineal» en las API). Ambos tienen como objetivo producir una clasificación unificada que preserve las fortalezas de cada recuperador, pero difieren en cómo tratan las puntuaciones y cuándo son más efectivos.
La fusión de rango recíproco ignora las puntuaciones brutas por completo y se centra en qué tan alto aparece un documento en cada lista. Los documentos clasificados cerca de la parte superior de cualquier lista son recompensados fuertemente, y los documentos que aparecen en múltiples listas reciben impulsos aditivos. El método es sólido porque elude problemas con rangos de puntuación incompatibles, requiere casi ningún ajuste más allá de la constante de clasificación y promueve naturalmente la diversidad en los resultados principales.
RRF califica los documentos según su posición en el conjunto de resultados usando la siguiente fórmula, donde k es una constante arbitraria destinada a ajustar la importancia de los documentos de baja clasificación:
![]()
RRF es especialmente útil cuando los recuperadores comparten cierta superposición en sus resultados principales y cuando los desarrolladores necesitan una solución plug-and-play sin datos de entrenamiento etiquetados ni calibración compleja.
La combinación lineal, por el contrario, fusiona directamente las puntuaciones reales de cada recuperador. Debido a que las puntuaciones léxicas y semánticas operan en escalas muy diferentes, la combinación lineal requiere normalización, como el escalado mínimo-máximo, para llevar las puntuaciones a un rango comparable.
Una vez normalizadas, las puntuaciones se combinan utilizando ponderaciones que representan la importancia relativa de cada recuperador. Una ponderación mayor que 1 aumenta la influencia del recuperador, mientras que una ponderación menor que 1 la reduce.
Este enfoque permite un control detallado: los desarrolladores pueden enfatizar BM25F cuando la precisión de las palabras clave es importante, inclinarse hacia la similitud semántica cuando la intención y el contexto son críticos, o integrar señales adicionales de negocio o personalización junto con las puntuaciones de recuperación. Cuando las ponderaciones se calibran cuidadosamente, la combinación lineal puede superar a la RRF al producir clasificaciones más precisas y predecibles, pero requiere experimentación y es sensible al ajuste específico de los sets de datos.
La combinación lineal combina resultados de búsqueda léxicos y resultados de búsqueda semántica con sus ponderaciones respectivas y β (donde 0 ≤α, β), de manera que:
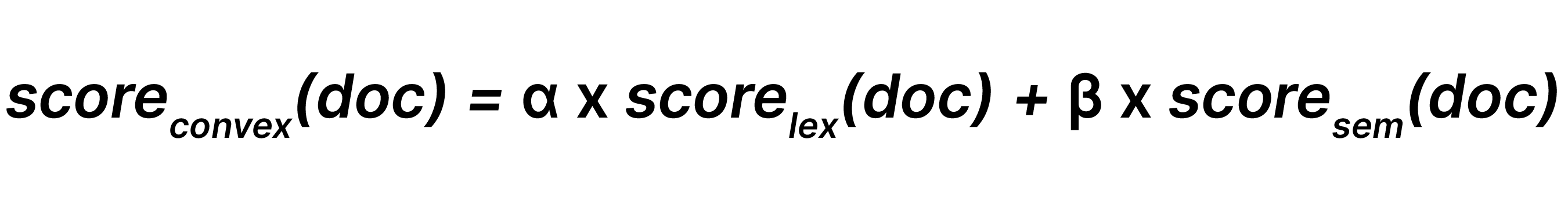
En la práctica, RRF es el mejor punto de partida para la búsqueda híbrida debido a su simplicidad y resistencia a escalas de puntaje desajustadas. Produce resultados sólidos sin un gran ajuste, por lo que es ideal para crear prototipos o cuando los recuperadores se superponen. La combinación lineal es más adecuada cuando los diferentes métodos de recuperación arrojan resultados desarticulados o cuando es necesario equilibrar cuidadosamente las señales léxicas, semánticas y externas. En resumen, RRF proporciona una hibridación rápida y confiable de inmediato, mientras que la combinación lineal ofrece una mayor precisión potencial una vez que las ponderaciones y los normalizadores se ajustan a la aplicación y los datos.
En resumen:
| Fusión de rango recíproco | Combinación lineal |
|---|---|
Comienza con RRF para obtener resultados híbridos sólidos rápidamente. |
Pasa a lineal cuando estés listo para afinar la relevancia. |
En resumen, la combinación lineal ofrece una mayor precisión potencial cuando se ajusta, mientras que RRF es más fácil de implementar y funciona bien sin datos de entrenamiento etiquetados.
Prueba este tutorial para obtener más información sobre la búsqueda híbrida.
Cómo funciona la recuperación de búsqueda híbrida
- Recuperación léxica: BM25F compara los términos de búsqueda con los tokens indexados — excelente para la precisión, los filtros estructurados y la puntuación explicable.
- Recuperación semántica: los vectores (densos o dispersos) representan el significado del texto; la búsqueda por similitud encuentra contenido relacionado incluso sin palabras compartidas.
- Fusión: Combina puntuaciones con RRF, mezcla ponderada o un recuperador lineal. Los filtros y los potenciadores se aplican de manera consistente en ambas recuperaciones.
| Tipo de búsqueda | Cómo funciona | Qué sucede | Ideal para cuando |
|---|---|---|---|
| Búsqueda léxica Búsqueda: "calzado deportivo para correr rojo talla 10". | Coincide con palabras exactas en la búsqueda con palabras en documentos (BM25F, TF-IDF, analizadores, sinónimos). | Busca productos con esos tokens exactos en el título/descripción (por ejemplo, "Calzado deportivo para correr Nike rojo para hombre, talla 10"). | El comprador sabe exactamente lo que quiere. Preciso, explicable y eficiente. |
| Búsqueda semántica Búsqueda: "zapatos livianos para caminar" | Utiliza incrustaciones para capturar el significado y el contexto, no solo palabras clave. Encuentra resultados conceptualmente relacionados incluso si los términos no coinciden. | Devuelve "Calzado deportivo para correr Adidas Cloudfoam, Talla 10" incluso si "liviano" y "caminar" no aparecen textualmente. | Los compradores describen la intención o usan lenguaje natural. Maneja búsquedas vagas o descriptivas. |
| Búsqueda híbrida Búsqueda: "zapatos de vestir cómodos para la oficina" | Combina resultados léxicos y semánticos y luego fusiona las clasificaciones (por ejemplo, mediante RRF). | Recupera coincidencias exactas como "zapatos de vestir de cuero negro cómodos" y artículos semánticamente relacionados como "Mocasines con plantillas acolchadas". Ambos aparecen juntos, ordenados por relevancia. | Las búsquedas mezclan términos precisos e intenciones. Equilibra la precisión con el descubrimiento. |
Búsqueda híbrida interna: explicación de vectores densos y dispersos
La búsqueda semántica con Elasticsearch funciona transformando las búsquedas y los documentos en representaciones vectoriales que capturan el significado. La búsqueda híbrida combina recuperación léxica y semántica, ya sea usando modelos densos como dispersos.
Vectores densos
Los vectores densos son matrices de números de longitud fija producidos por modelos como BERT, donde entradas similares (como gato y gatito) aparecen cerca en el espacio vectorial, lo que los hace muy útiles para la coincidencia semántica, las recomendaciones y la búsqueda de similitud.
Cuando el texto está incrustado como un vector denso, se ve así:
[ 0.13586345314979553, -0.6291824579238892, 0.32779985666275024, 0.36690405011177063, ... ]
Cada dimensión contiene información significativa, lo que hace que los vectores sean densos en datos. El contenido similar produce incrustaciones que están próximas entre sí en el espacio vectorial.
En Elasticsearch, los vectores densos se almacenan en un campo dense_vector y se buscan con algoritmos aproximados de vecino más cercano (ANN) como HNSW. Esto es ideal para capturar el significado semántico general del texto, imágenes u otro contenido.
POST my-index/_search
{
"retriever": {
"rrf": {
"retrievers": [
{
"standard": {
"query": {
"match": {
"text_field": "fox"
}
}
}
},
{
"knn": {
"field": "title_vector",
"query_vector": [0.1, 3.2, 2.1],
"k": 5,
"num_candidates": 100
}
}
]
}
}
}
Aquí tienes un ejemplo de ES|QL:
FROM my-index METADATA _score
| FORK ( WHERE match(text_field:"fox") | SORT _score DESC | LIMIT 5)
( WHERE knn(image_vector, [0.1, 3.2, 2.1], { "min_candidates" : 100 }) | SORT _score DESC | LIMIT 5 )
| FUSE
| SORT _score DESCComo vimos anteriormente, una búsqueda híbrida simplemente aprovecha el recuperador rrf que combina una búsqueda léxica (p. ej., una búsqueda de coincidencia) realizada con un recuperador estándar y una búsqueda vectorial especificada en el recuperador knn. Lo que hace esta búsqueda es primero recuperar las cinco mejores coincidencias de vectores a nivel global, luego combinarlas con las coincidencias léxicas y finalmente devolver los 10 mejores resultados coincidentes. El rrf retriever utiliza la clasificación RRF para combinar coincidencias vectoriales y léxicas.
Comprensión de vectores dispersos y ELSER
Las incrustaciones densas no son la única forma de realizar búsquedas semánticas.
Los vectores dispersos contienen principalmente ceros con unos pocos valores ponderados vinculados a términos interpretables, lo que los hace eficientes en recursos, explicables y efectivos en escenarios de disparo cero.
Una representación de vectores dispersos se ve así:
{"f1":1.2,"f2":0.3,… }
En Elasticsearch, Elastic Learned Sparse EncodeR (ELSER) es un modelo de procesamiento de lenguaje natural disperso (PLN) fuera del dominio que expande el texto en términos semánticamente relacionados y asigna ponderaciones, lo cual permite coincidencias más allá de las palabras clave exactas mientras preserva la interpretabilidad.
Además, el campo semantic_text hace que la búsqueda semántica sea tan fácil como la búsqueda de texto tradicional al manejar la generación de incrustaciones y la inferencia automáticamente en la ingesta. Puedes indexar documentos como un campo de texto y ejecutar una búsqueda de coincidencia simple, incluso en índices donde el tipo de campo difiere, para obtener coincidencias léxicas y semánticas sin necesidad de una lógica de búsqueda adicional. Para control avanzado, usa búsquedas knn o sparse_vector en el mismo campo.
Ejemplo con ELSER:
- Preentrenado con un vocabulario de aproximadamente 30000 términos
- Almacenado como sparse_vector (pares término/peso)
- Generado automáticamente durante la ingesta con semantic_text o en el momento del índice con el procesador de ingesta de inferencia
- Se buscan mediante un índice invertido (como la búsqueda léxica), lo que las hace eficientes, amigables con filtros y explicables
POST my-index/_search
{
"retriever": {
"rrf": {
"retrievers": [
{
"standard": {
"query": {
"match": {
"text_field": "fox"
}
}
}
},
{
"standard": {
"query": {
"sparse_vector": {
"field": "ml.tokens",
"inference_id": ".elser_model_1",
"query": "a quick brown fox jumps over a lazy dog"
}
}
}
}
]
}
}
}
Juntos, los vectores densos y dispersos proporcionan flexibilidad: los vectores densos se destacan en capturar significados matizados, mientras que los vectores dispersos ofrecen transparencia y escalabilidad para búsquedas en el mundo real.
Descubre cómo la expansión de texto con ELSER te ayuda a obtener mejores resultados:
Vectores dispersos vs. densos en la práctica
| Vectores dispersos (ELSER) | Vectores densos | |
|---|---|---|
| Cómo funciona | Expande el texto en términos semánticamente relacionados y ponderados. Cada dimensión corresponde a un token con una ponderación asociada. | Codifica el contenido (texto, imágenes, etc.) en vectores de punto flotante de longitud fija. Significado similar = posiciones cercanas en el espacio vectorial. |
| Fortalezas |
|
|
| Ejemplos de casos de uso |
|
|
| Ideal para | Cuando necesitas una mejora semántica y transparencia, o cuando los términos específicos del dominio son lo más importante | Cuando deseas realizar búsquedas y encontrar similitudes basadas en el significado, no en palabras exactas, en diversos tipos de datos. |
Búsqueda híbrida con modelos densos y dispersos
Hasta ahora, hemos visto dos formas diferentes de ejecutar una búsqueda híbrida, dependiendo de si se estaba buscando un espacio vectorial denso o disperso. Podemos mezclar datos densos y dispersos dentro del mismo índice.
POST my-index/_search
{
"_source": false,
"fields": [ "text_field" ],
"retriever": {
"rrf": {
"retrievers": [
{
"knn": {
"field": "image_vector",
"query_vector": [0.1, 3.2, ..., 2.1],
"k": 5,
"num_candidates": 100
}
},
{
"standard": {
"query": {
"sparse_vector": {
"field": "ml.tokens",
"inference_id": ".elser_model_1",
"query": "a quick brown fox jumps over a lazy dog"
}
}
}
}
]
}
}
}
Ir más allá: búsqueda híbrida con denso, disperso y BM25F
Este ejemplo combina tres recuperadores y fusiona sus listas clasificadas con RRF:
- BM25F (coincidencia en texto): Coincidencias precisas de palabras clave/frases ("montaña nevada")
- kNN (image_vector): similitud visual usando la incrustación de imagen proporcionada (k resultados de num_candidates)
- Semántica (semantic_text): El concepto coincide mediante la expansión semántica de la búsqueda
rank_window_size controla cuántos resultados se fusionan; rank_constant equilibra las contribuciones de cada lista.
GET my-index/_search
{
"retriever": {
"rrf": {
"retrievers": [
{
"standard": {
"query": {
"match": {
"text": {
"query": "snowy mountain"
}
}
}
}
},
{
"knn": {
"field": "image_vector",
"query_vector": [
0.01,
0.3,
-0.4
],
"k": 10,
"num_candidates": 100
}
},
{
"standard": {
"query": {
"semantic": {
"field": "semantic_text",
"query": "snowy mountain"
}
}
}
}
],
"rank_window_size": 50,
"rank_constant": 60
}
}
}
Veamos también un ejemplo similar con ES|QL:
FROM my-index METADATA _score
| FORK (WHERE match(text, "snowy mountain") | SORT _score DESC | LIMIT 50)
(WHERE knn(image_vector, [0.01, 0.3, -0.4], {"min_candidates": 100 }) | SORT _score DESC | LIMIT 50)
(WHERE match(semantic_text, "snowy mountain") | SORT _score DESC | LIMIT 50)
| FUSE RRF WITH {"rank_constant": 60 } // ¿Es 60 el valor predeterminado de todas maneras?
| SORT _score DESC
| LIMIT 50Conclusión
La búsqueda híbrida combina la precisión de la búsqueda de texto completo y el alcance contextual de la búsqueda semántica, lo que proporciona resultados más precisos y relevantes en contenidos diversos. Al brindar soporte tanto a modelos densos como dispersos y ofrecer métodos flexibles de fusión como la combinación lineal y la fusión recíproca de rangos, puedes adaptar la recuperación a tu caso de uso — ya sea haciendo coincidir búsquedas y vectores directamente o simplificando la recuperación multietapa con un recuperador. Esta flexibilidad convierte a la búsqueda híbrida en un enfoque muy eficaz para búsquedas complejas, datos variados y requisitos de relevancia exigentes.
Descubre más sobre la búsqueda híbrida:
- Explora este blog para descubrir qué es la búsqueda híbrida, los tipos de búsquedas que Elasticsearch admite y cómo crearlas.
- Como contexto: la evolución de la búsqueda híbrida y la ingeniería de contexto
- Búsqueda híbrida y recuperación en varias etapas en ES|QL
- Búsqueda híbrida sin complicaciones: simplificando la búsqueda híbrida con los recuperadores
¿Quieres aprender más aparte de los vectores? Echa un vistazo a la búsqueda híbrida inteligente con agentes LLM en Elasticsearch.
¿Listo para poner manos a la obra? Sigue nuestro tutorial de búsqueda híbrida para combinar resultados de texto completo y kNN, o prueba el tutorial de ES|QL para buscar y filtrar usando ES|QL.