Prueba del nivel frío nuevo de Elasticsearch de snapshots buscables a escala
El nivel frío de snapshots buscables, antes en versión beta en Elasticsearch 7.10, ahora está a disposición del público en general en Elasticsearch 7.11. Este nuevo nivel de datos reduce tu almacenamiento de cluster hasta en un 50 % en comparación con el nivel tibio y mantiene el mismo nivel de confiabilidad y redundancia que los niveles caliente y tibio.
En este blog, veremos las situaciones que exploramos para asegurarnos de que el nivel frío funciona sin problemas a escala y destacaremos la importancia que le damos a la calidad y confiabilidad de nuestras soluciones.
Repaso del nivel frío
El nivel frío reduce los costos de cluster gracias a que mantiene solo los shards primarios en el almacenamiento local, lo que elimina la necesidad de shards de réplica y, en su lugar, depende de snapshots (que se mantienen en almacenes de objetos como AWS S3, Google Storage o Microsoft Azure Storage) para brindar la resistencia necesaria. El almacenamiento local básicamente actúa como una versión almacenada en memoria caché de los datos del snapshot en el repositorio.
En el caso de un nodo frío o almacenamiento local que comienzan a tener problemas, los snapshots buscables automáticamente recuperarán y volverán a equilibrar los shards en otros nodos.
En el caso de reinicios de cluster completo o escalonados (o reinicios del nodo), el almacenamiento local es persistente y los datos disponibles de forma local no volverán a descargarse de los snapshots, lo que minimiza el tiempo necesario para volver a un cluster en verde y evita costos de red innecesarios.
Para garantizar que todo esto funcione como se espera a escala, enfocamos nuestros esfuerzos de validación en tres escenarios, todos con lo siguiente:
- Cinco nodos de Elasticsearch (heap 16 G)
- Seis discos magnéticos de 2 TB en configuración de RAID-0
- Un snapshot de 5 TB de datos de logging, distribuido en 10 índices con cinco shards cada uno, fusionados por la fuerza a un solo segmento (la fusión por la fuerza optimiza el índice para el acceso de lectura y reduce la cantidad de archivos que deben restaurarse en caso de un evento de falla)
Situación 1: Reinicio de cluster completo
La primera situación que validamos fue la de reinicios de cluster completo. Para verificar esto, atravesamos los pasos siguientes:
- Montamos el snapshot buscable de 5 TB y esperamos a que la memoria caché local estuviera precalentada por completo (Fase 0).
- Ejecutamos un reinicio de cluster completo según las pautas de reinicio de cluster completo.
- Después de volver a habilitar la asignación, medimos cuánto demora el cluster para lo siguiente:
- Ponerse verde
- Terminar todas las descargas en segundo plano para precalentar las memorias caché
- Nos aseguramos de que no hubiera ningún nuevo balanceo de shards adicional después del paso 3.
Gracias a la capa de persistencia que se incorporó recientemente en Elasticsearch 7.11, después de iniciar todos los nodos y volver a habilitar la asignación, el cluster se puso verde de inmediato y no se realizó ninguna descarga en segundo plano.
A continuación podemos ver el tráfico de red acumulativo durante el montaje (Fase 0) y tras un reinicio de cluster completo y la habilitación nuevamente de la asignación (Fase 1, sin tráfico de red adicional):

Situación 2: Reinicio escalonado
La segunda situación que validamos fue el caso común de reinicios de cluster escalonados.
El experimento fue similar al del reinicio de cluster completo:
- Montamos el snapshot buscable de 5 TB y esperamos a que la memoria caché local estuviera precalentada por completo.
- Ejecutamos el procedimiento de reinicio escalonado en el primer nodo, para lo cual deshabilitamos la asignación de shards antes de detener cada nodo.
- Iniciamos el nodo tras volver a habilitar la asignación de shards, medimos el tiempo que demoraría para ponerse verde. Esperábamos que fuera rápido debido a la memoria caché persistente. También nos aseguramos de que no hubiera descargas en segundo plano innecesarias después de cada reinicio.
- Repetimos los pasos 2 y 3 para todos los otros nodos del cluster.
Este experimento también se completó con éxito y gracias a la memoria caché persistente, que se incorporó en Elasticsearch 7.11, llegar al verde fue prácticamente instantáneo y no hubo descargas adicionales en segundo plano desde el snapshot.
Situación 3: Falla de nodo
Por último, queríamos asegurarnos un comportamiento correcto en el caso de falla de un nodo. Ejecutamos el experimento siguiente:
- Montamos el snapshot buscable de 5 TB y esperamos a que la memoria caché local estuviera precalentada por completo (Fase 0).
- De los cinco nodos, terminamos un nodo de Elasticsearch (node-1, con
SIGKILL) y esperamos a que el cluster se pusiera verde de nuevo (Fase 1).- Nos aseguramos de que las descargas en segundo plano están relacionadas con recibir datos de shards hospedados en el nodo terminado.
- Después de ponerse verde, no debería ocurrir ningún balanceo nuevo adicional.
- Iniciamos nuevamente el nodo que falló (Fase 2):
- Solo debería realizarse la recuperación de pares (dado que todos los datos existen en los cuatro nodos restantes) para balancear nuevamente los shards.
- El cluster debería ponerse verde.
Nuevamente, este experimento se completó con éxito. Después de terminar el node-1, los nodos restantes restauraron automáticamente los shards (desde los snapshots buscables) alojados en el nodo faltante.
No hubo ningún balanceo nuevo adicional una vez que el cluster se puso verde, como se puede observar en el gráfico siguiente en el que podemos visualizar el tráfico de red por nodo:
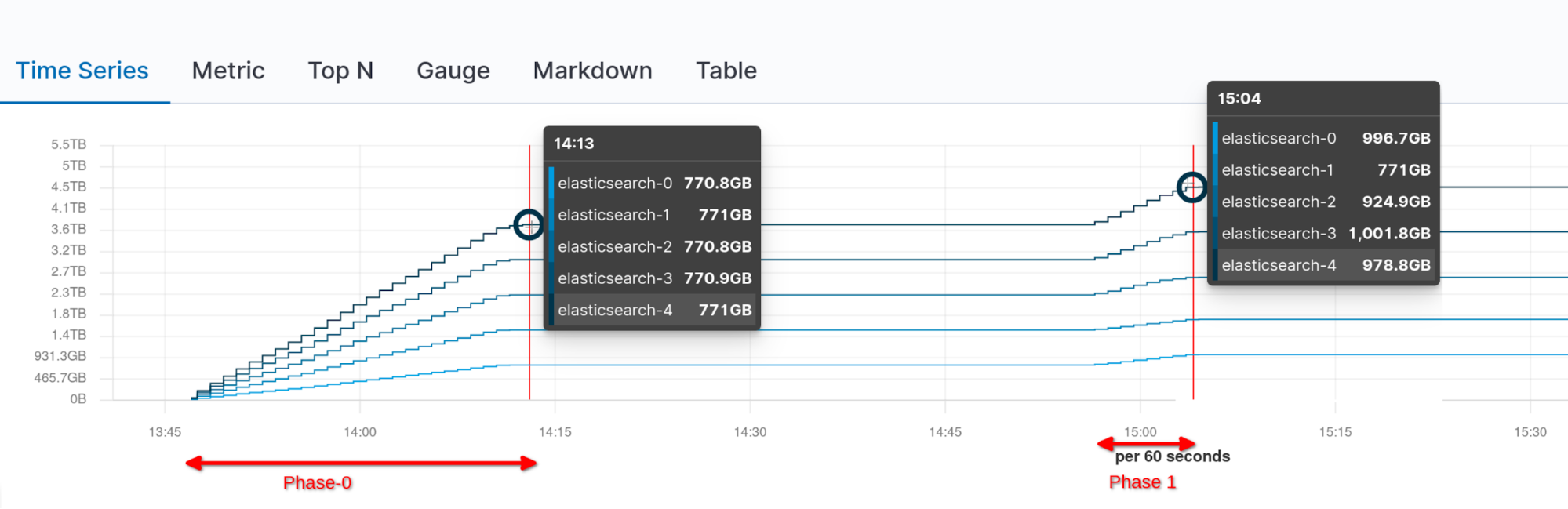
Tras recuperar el nodo faltante, la recuperación de pares entró en escena y el node-1 terminó alojando nuevamente la cantidad necesaria de shards para tener un cluster de distribución pareja.

Comienza hoy mismo
Esperamos que este recorrido por la validación de características te haya resultado tan interesante como a nosotros emocionante.
Para dar los primeros pasos con los snapshots buscables y comenzar a almacenar datos en el nivel frío, activa un cluster en Elastic Cloud o instala la versión más reciente del Elastic Stack. ¿Ya tienes Elasticsearch en ejecución? Solo actualiza los clusters a la versión 7.11 y pruébalo. Si deseas conocer más información, puedes leer la documentación sobre niveles de datos y snapshots buscables.