Machine Learning en la ciberseguridad: Detección de actividad de DGA en los datos de red
En la parte 1 de esta serie de blogs, vimos cómo usar Machine Learning del Elastic Stack para entrenar un modelo de clasificación supervisado con el objetivo de detectar dominios maliciosos. En esta segunda parte, veremos cómo usar el modelo que entrenamos para enriquecer los datos de red con clasificaciones al momento de la ingesta. Esto será útil para quien desee detectar posible actividad de DGA en sus datos de Packetbeat.
Detección de DGA con el Elastic Stack
Un programa malicioso que infecta una máquina, por lo general, necesitará una forma de comunicarse con un servidor controlado por el atacante, un denominado servidor de comando y control (C&C o C2). Para impedir las medidas defensivas que bloquean cualquier URL o dirección IP codificada de forma rígida, los atacantes usan algoritmos de generación de dominios (DGA). Cuando el malware necesita contactarse con un servidor de C&C, usará el DGA para generar cientos o miles de dominios candidatos e intentará resolver una dirección IP para cada uno. El atacante después debe registrar solo uno o algunos dominios generados por el DGA para poder comunicarse con la máquina infectada. Los DGA se esparcen y aleatorizan de diferentes formas para que sea incluso más difícil para los defensores bloquearlos y detectarlos.
Como la actividad de los DGA suele involucrar búsquedas de DNS, se manifestará con frecuencia en las solicitudes de DNS hechas desde una máquina infectada. Packetbeat puede recopilar tráfico de DNS y enviarlo a Elasticsearch para análisis. En este blog, veremos cómo puedes enriquecer la información de la búsqueda de DNS en los datos de Packetbeat con una puntuación para indicar el grado de maliciosidad del dominio.

Procesadores de inferencias y el pipeline de ingesta
Para enriquecer los datos de Packetbeat con predicciones de un modelo entrenado para distinguir los dominios benignos de los maliciosos, necesitaremos configurar un pipeline de ingesta con procesadores de inferencias adecuados. Los procesadores de inferencias ofrecen a los usuarios una forma de usar un modelo entrenado en el Elastic Stack (o un modelo entrenado en una de nuestras bibliotecas externas soportadas) para hacer predicciones sobre documentos nuevos a medida que se ingestan en Elasticsearch. Para comprender cómo encajan todas estas piezas móviles y las configuraciones necesarias, regresemos por un momento a la primera parte de este blog.
En la parte 1, hablamos sobre el proceso de entrenar un modelo de clasificación para predecir si un dominio dado es o no malicioso. Uno de los pasos en este proceso es realizar ingeniería de características sobre los datos de entrenamiento, un conjunto de dominios maliciosos y benignos conocidos que nuestro modelo usará para conocer cómo puntuar dominios nuevos no vistos previamente. Los dominios sin procesar deben manipularse para extraer características (unigramas, bigramas y trigramas) útiles para el modelo. Después se debe aplicar también el mismo procedimiento de ingeniería de características a los dominios en nuestros datos de Packetbeat que deseamos puntuar en cuanto a maliciosidad.
Por eso, además de un procesador de inferencias, nuestro pipeline de ingesta también incluirá procesadores de scripts de Painless para extraer unigramas, bigramas y trigramas de los datos de DNS de Packetbeat al momento de la ingesta. En la Figura 2 se ilustra un diagrama con el pipeline completo.
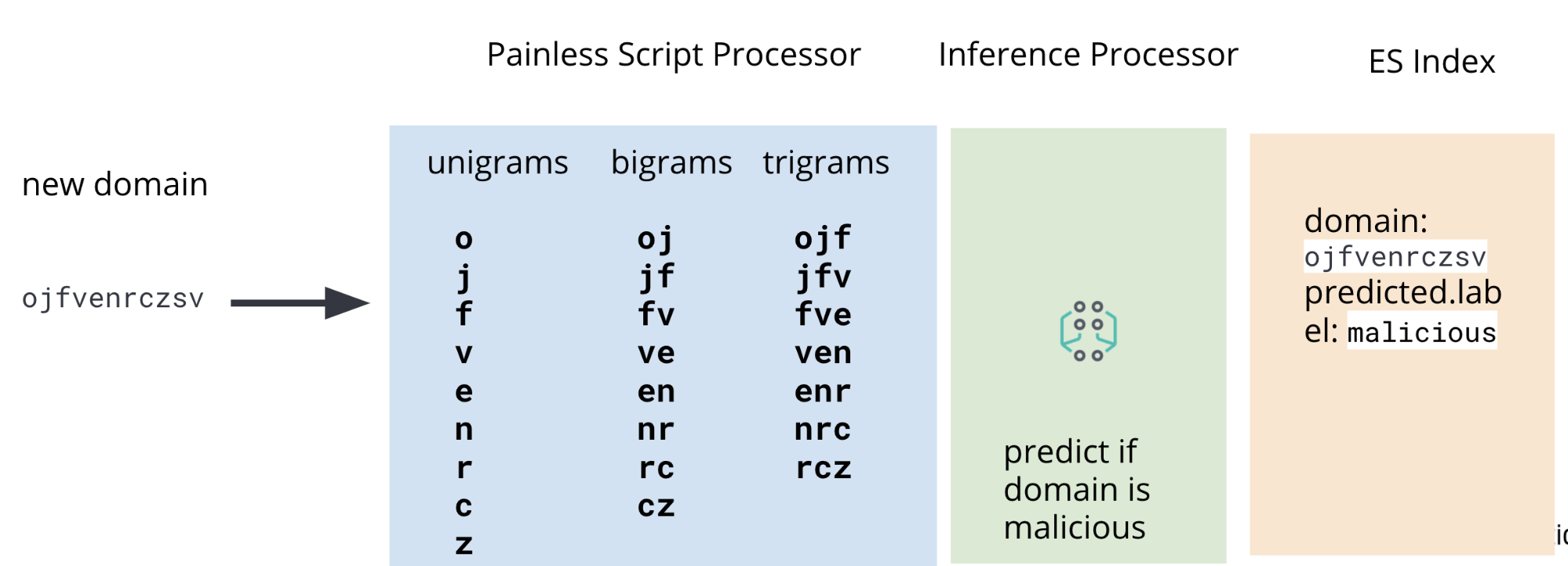
En los datos de Packetbeat, el campo que nos interesa operar es el de dominio registrado de DNS. Aunque hay algunos casos extremos en los que este campo no contendrá el dominio de interés, servirá ilustrar el caso de uso para este blog. La imagen en la Figura 3 ilustra los campos de interés en un documento de Packetbeat de ejemplo.

dns.question.registered_domain.Para extraer unigramas, bigramas y trigramas de dns.question.registered_domain, necesitaremos usar un script de Painless como el de la Figura 4.
POST _scripts/ngram-extractor-packetbeat
{
"script": {
"lang": "painless",
"source": """
String nGramAtPosition(String fulldomain, int fieldcount, int n){
String domain = fulldomain.splitOnToken('.')[0];
if (fieldcount+n>=domain.length()){
return ''
}
else
{
return domain.substring(fieldcount, fieldcount+n)
}
}
for (int i=0;i<ctx['dns']['question']['registered_domain'].length();i++){
ctx['field_'+Integer.toString(params.ngram_count)+'_gram_'+Integer.toString(i)] = nGramAtPosition(ctx['dns']['question']['registered_domain'], i, params.ngram_count)
}
"""
}
}
Una vez extraídas las características necesarias, el documento (aún pasando por el pipeline de ingesta) atravesará el procesador de inferencias en donde el modelo de clasificación que entrenamos en la entrega anterior usará las características extraídas para hacer una predicción. Por último, como no queremos perturbar nuestro índice con todas las características adicionales que necesita el modelo, agregaremos una serie de procesadores de scripts de Painless para eliminar los campos que contienen los unigramas, bigramas y trigramas.
Entonces, al final del pipeline de ingesta, ingestaremos un documento de Packetbeat con los nuevos campos adicionales que contienen el resultado de las predicciones de ML. En la Figura 5 se muestra una configuración de pipeline de ingesta de muestra. Para ver los detalles completos, consulta el repositorio de ejemplos.
PUT _ingest/pipeline/dga_ngram_expansion_inference
{
"description": "Expands a domain into unigrams, bigrams and trigrams and make a prediction of maliciousness",
"processors": [
{
"script": {
"id": "ngram-extractor-packetbeat",
"params":{
"ngram_count":1
}
}
},
{
"script": {
"id": "ngram-extractor-packetbeat",
"params":{
"ngram_count":2
}
}
},
{
"script": {
"id": "ngram-extractor-packetbeat",
"params": {
"ngram_count":3
}
}
},
{
"inference": {
"model_id": "dga-ngram-job-1587729368929",
"target_field": "predicted_label",
"field_mappings":{},
"inference_config": { "classification": {"num_top_classes": 2} }
}
},
{
"script": {
"id": "ngram-remover-packetbeat",
"params":{
"ngram_count":1
}
}
},
{
"script": {
"id": "ngram-remover-packetbeat",
"params":{
"ngram_count":2
}
}
},
{
"script": {
"id": "ngram-remover-packetbeat",
"params": {
"ngram_count":3
}
}
}
]
}
Como no todos los documentos de Packetbeat registrarán una solicitud de DNS, debemos hacer que el pipeline de ingesta se ejecute condicionalmente solo si los campos de DNS necesarios están presentes y completos en el documento ingestado. Podemos hacerlo usando un procesador de pipeline (ver configuración en la Figura 6) para comprobar si los campos deseados están presentes y completos, y después redireccionar el procesamiento del documento al pipeline dga_ngram_expansion_inference que definimos en la Figura 5. Aunque la configuración siguiente es adecuada para un prototipo, en un caso de uso de producción deberás tener en cuenta el tratamiento de errores en el pipeline de ingesta. Para ver las configuraciones completas e instrucciones, consulta el repositorio de ejemplos.
PUT _ingest/pipeline/dns_classification_pipeline
{
"description": "A pipeline of pipelines for performing DGA detection",
"version": 1,
"processors": [
{
"pipeline": {
"if": "ctx.containsKey('dns') && ctx['dns'].containsKey('question') && ctx['dns']['question'].containsKey('registered_domain') && !ctx['dns']['question']['registered_domain'].empty",
"name": "dga_ngram_expansion_inference"
}
}
]
}
Uso de la detección de anomalías como analíticas de segundo orden en los resultados de inferencias
El modelo que entrenamos en la primera parte de la serie tenía una tasa de falsos positivos del 2 %. Aunque parece bastante baja, hay que tener en cuenta que el tráfico de DNS suele tener alto volumen. Por lo tanto, incluso con una tasa de falsos positivos del 2 %, es posible que una gran cantidad de búsquedas se puntúen como maliciosas. Una manera de reducir la cantidad de falsos positivos sería trabajar en más esquemas de ingeniería de características. Otra sería usar la detección de anomalías en los resultados de nuestra clasificación. Exploremos cómo hacer esto último en el Elastic Stack.
Lo primero que debemos observar es que si tomamos los documentos de Packetbeat enriquecidos y graficamos el conteo de documentos de Packetbeat etiquetados como maliciosos en relación con el tiempo, obtenemos una serie temporal (Figura 7).
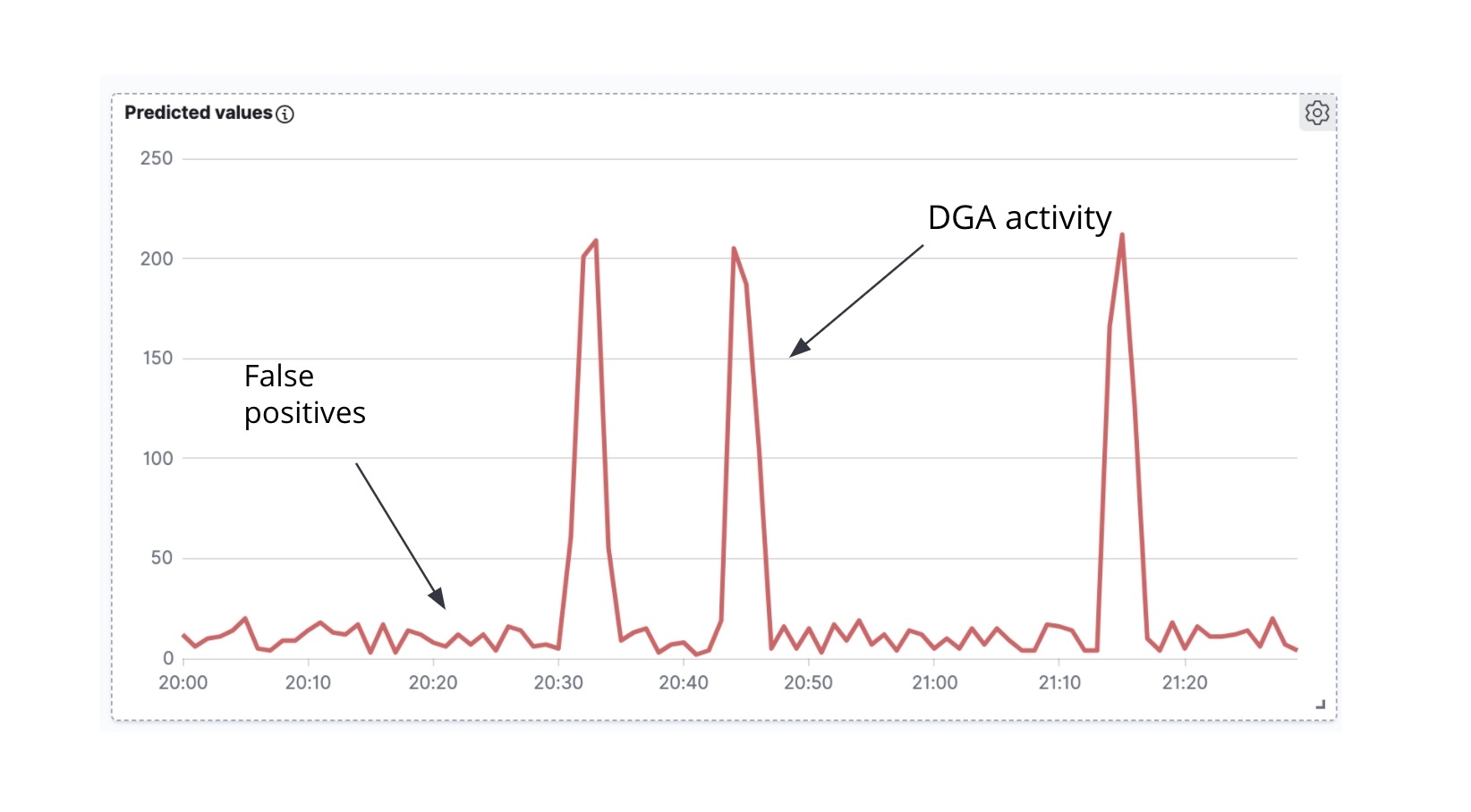
Lo segundo que se debe tener en cuenta es que frecuentemente (aunque hay excepciones) cuando un malware de DGA intenta comunicarse de forma activa con el servidor de C&C, tiende a generar una ola de solicitudes de DNS al mismo tiempo (es decir, el malware recorre muchos de los dominios que generó el algoritmo, intentando resolver la dirección IP de cada uno de los dominios). En el análisis de la serie temporal de dominios maliciosos previstos en el tiempo (Figura 6), podemos ver picos de actividad y un pequeño ruido entre los picos. Los picos indican que nuestro modelo de clasificación clasificó muchos dominios como maliciosos en un período breve y, por lo tanto, probablemente estamos lidiando con un verdadero DGA. Por el contrario, lo más probable es que el ruido de fondo entre los picos sea el resultado de falsos positivos. Es justamente esta intuición la que buscaremos codificar en un trabajo de detección de anomalías high_count para esta serie temporal.
Si superponemos el carril de detección de anomalías con la serie temporal en la Figura 7, veremos que obtenemos alertas por anomalías que corresponden a los picos en la serie temporal (la verdadera actividad de los DGA) y no obtenemos ninguna en los intervalos entre los picos (el ruido de fondo de los falsos positivos).
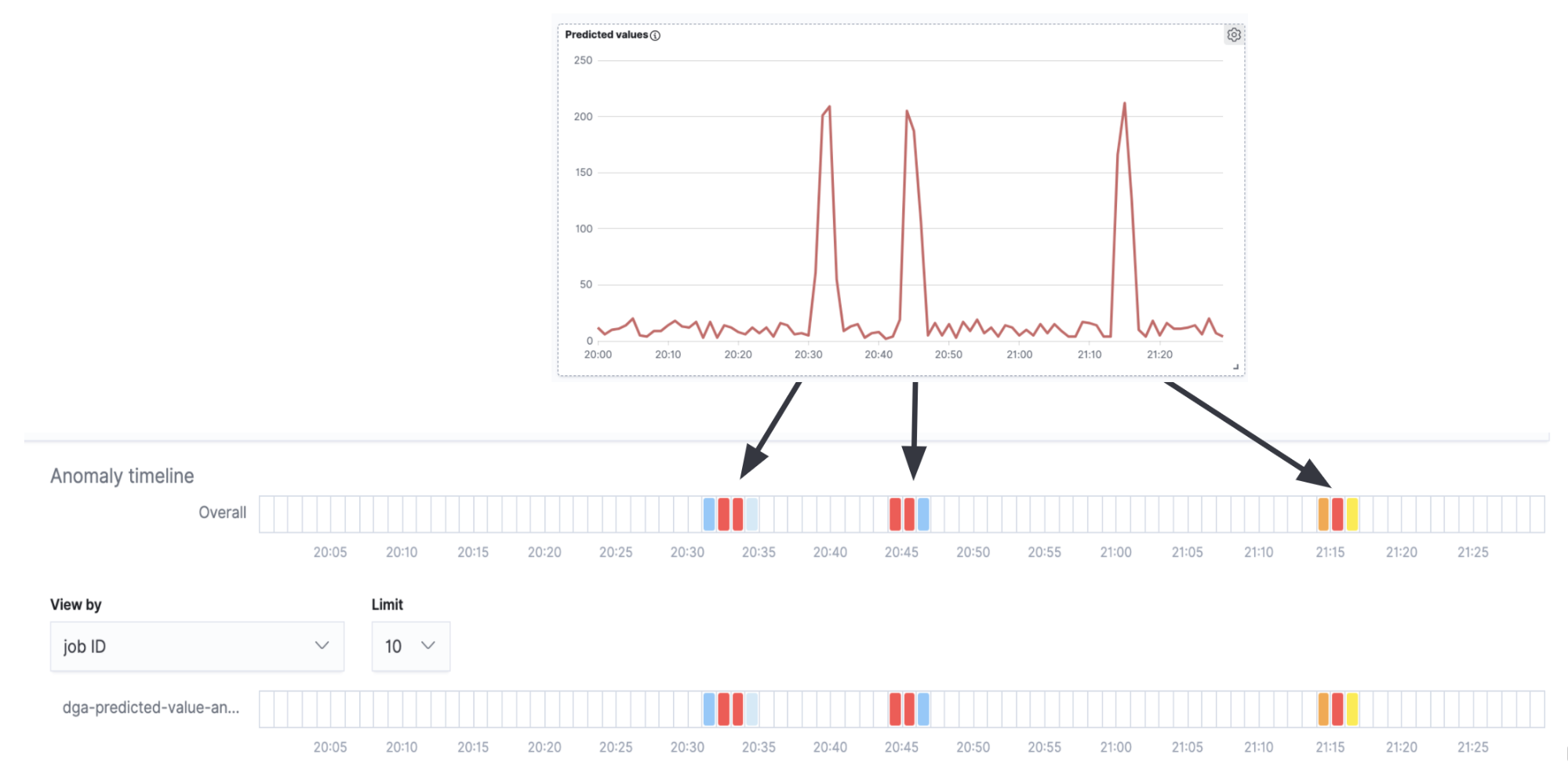
Aunque este es un ejemplo muy simple y para un caso de uso de producción probablemente se requieran más ajustes y configuración, no obstante muestra que los trabajos de detección de anomalías pueden usarse de forma efectiva como análisis de segundo orden en los resultados de inferencias.
Conclusión
En este blog, usamos un modelo de clasificación entrenado para enriquecer los datos de red (documentos de Packetbeat) al momento de la ingesta. El proceso de enriquecimiento, facilitado por el procesador de inferencias y los pipelines de ingesta, agrega una etiqueta de predicción en cada dominio consultado durante una solicitud de DNS. Esto muestra qué tan probable es que el dominio sea malicioso. Además, para reducir las alertas por falsos positivos, también examinamos cómo usar un trabajo de detección de anomalías en los resultados de inferencia. También estamos planificando proporcionar una configuración curada y modelos para la detección de DGA en Elastic SIEM.
Si deseas probarlo por tu cuenta con tus propios datos de red, puedes activar una prueba gratuita de Elasticsearch Service de 14 días para comenzar a ingestar y analizar. Además puedes probar Machine Learning de forma gratuita durante 30 días descargando el Elastic Stack de forma local e iniciando una licencia de prueba. O da los primeros pasos con Elastic SIEM gratuito y abierto para comenzar a proteger tus datos hoy.