Machine Learning en la ciberseguridad: Entrenamiento de modelos supervisados para detectar actividad de DGA
¿Qué tan molesto es recibir una llamada de telemarketing de un número de teléfono aleatorio? Incluso si lo bloqueas, no hará ninguna diferencia porque recibirás la siguiente de un número nuevo. Los atacantes cibernéticos usan los mismos trucos sucios. Con algoritmos de generación de dominios (DGA), los creadores de malware cambian la fuente de su infraestructura de control y comando, evaden la detección y frustran a los analistas de seguridad que intentan bloquear su actividad.
En esta serie de dos partes, usaremos Machine Learning de Elastic para crear y evaluar un modelo destinado a detectar algoritmos de generación de dominios. En esta primera parte, abarcaremos lo siguiente:
- El proceso de extraer características de los dominios benignos y maliciosos sin procesar
- Una breve explicación del proceso para encontrar características adecuadas
- Una demostración de cómo entrenar y evaluar un modelo de Machine Learning usando el Elastic Stack
En la segunda parte, veremos cómo desplegar el modelo entrenado en un pipeline de ingesta para enriquecer los datos de Packetbeat al momento de la ingesta. Los archivos de configuración y los materiales de soporte estarán disponibles en el repositorio de ejemplos.
Si deseas probar esto por tu cuenta, recomendamos activar una prueba gratuita de nuestro Elasticsearch Service, donde tendrás pleno acceso a todas nuestras capacidades de Machine Learning. Bien, comencemos.
DGA: Trasfondo
Después de infectar una máquina objetivo, muchos programas maliciosos intentan contactarse con un servidor remoto (un denominado servidor de comando y control [C&C o C2]) para exfiltrar datos y recibir instrucciones o actualizaciones. Esto significa que el binario malicioso tiene que conocer el dominio o la dirección IP del servidor de C&C. Si esta dirección IP o este dominio están codificados de forma rígida en el binario, resulta relativamente fácil para las medidas defensivas impedir esta comunicación agregando el dominio a una lista de bloqueo.
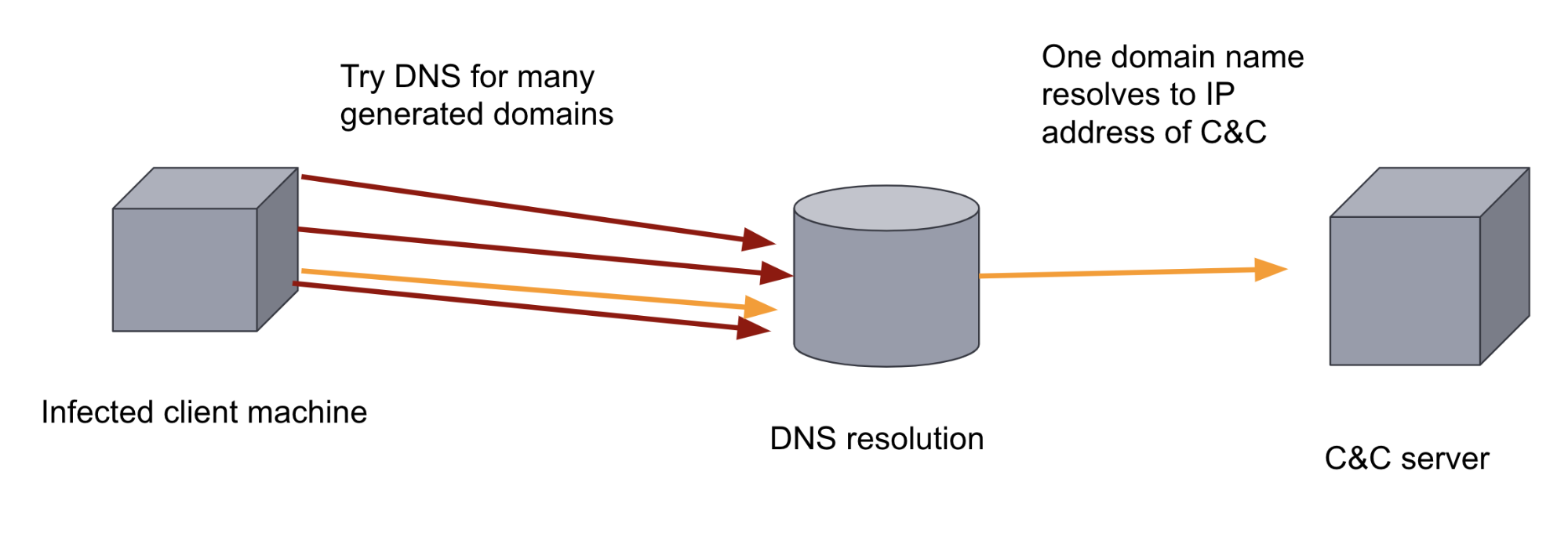
Para subvertir esta medida defensiva, los autores de malware pueden agregar un DGA a su malware. Los DGA generan cientos o miles de dominios de aspecto aleatorio. Después el binario de malware en la máquina infectada recorre cada uno de los dominios generados en un intento por resolver los nombres de dominio y descubrir cuál de ellos se registró como servidor de C&C. El simple volumen y aleatoriedad de los dominios hacen que sea difícil para un enfoque defensivo basado en reglas impedir este canal de comunicación. También dificulta que lo encuentre un analista humano debido a que el tráfico de DNS suele ser de muy alto volumen. Estos dos factores hacen que sea una aplicación ideal de Machine Learning.
Entrenamiento de un modelo de Machine Learning para clasificar dominios
En Machine Learning supervisado, proporcionamos un set de datos de entrenamiento etiquetado que contiene dominios benignos y maliciosos, esto permite a un modelo aprender a partir de dicho set de datos para poder usarse después en la clasificación de dominios no vistos previamente como maliciosos o benignos.
Existen varios tipos diferentes de DGA; no todos tienen la misma apariencia. Algunos DGA generan dominios con apariencia aleatoria, otros usan listas de palabras. Para los modelos de producción, se pueden usar diferentes características y modelos para capturar las particularidades de los distintos algoritmos. En este ejemplo entrenaremos un solo modelo conforme a las particularidades encontradas en los algoritmos más comunes.
Para entrenar nuestro modelo, aquí usaremos un set de datos compuesto por dominios de varias familias de malware y dominios benignos.

cryptolocker, banjori y suppobox
Ingeniería de características
La entrada necesaria para crear un modelo de Machine Learning efectivo consta de características que pueden capturar las particularidades de los dominios generados por DGA. Por lo tanto, debemos indicarle al modelo los aspectos de la cadena que son importantes para distinguir entre dominios maliciosos y benignos. Esto se conoce como ingeniería de características en el mundo de Machine Learning.
Comprender las características que distinguen mejor los dominios benignos de los maliciosos es un proceso iterativo. Por ejemplo, comenzamos con algunas características simples como la longitud del nombre de dominio y la entropía del nombre de dominio, pero los modelos resultantes no fueron particularmente precisos en comparación con otros métodos como LSTM. Estos modelos aprovechan las características secuenciales de las cadenas, por lo que después observamos otras características que codificarían secuencias con más efectividad.
Después de iterar por varios enfoques de ingeniería de características, concluimos que usar la presencia de subcadenas de distintas longitudes capturaría mejor la diferencia entre dominios maliciosos y benignos en el modelo.
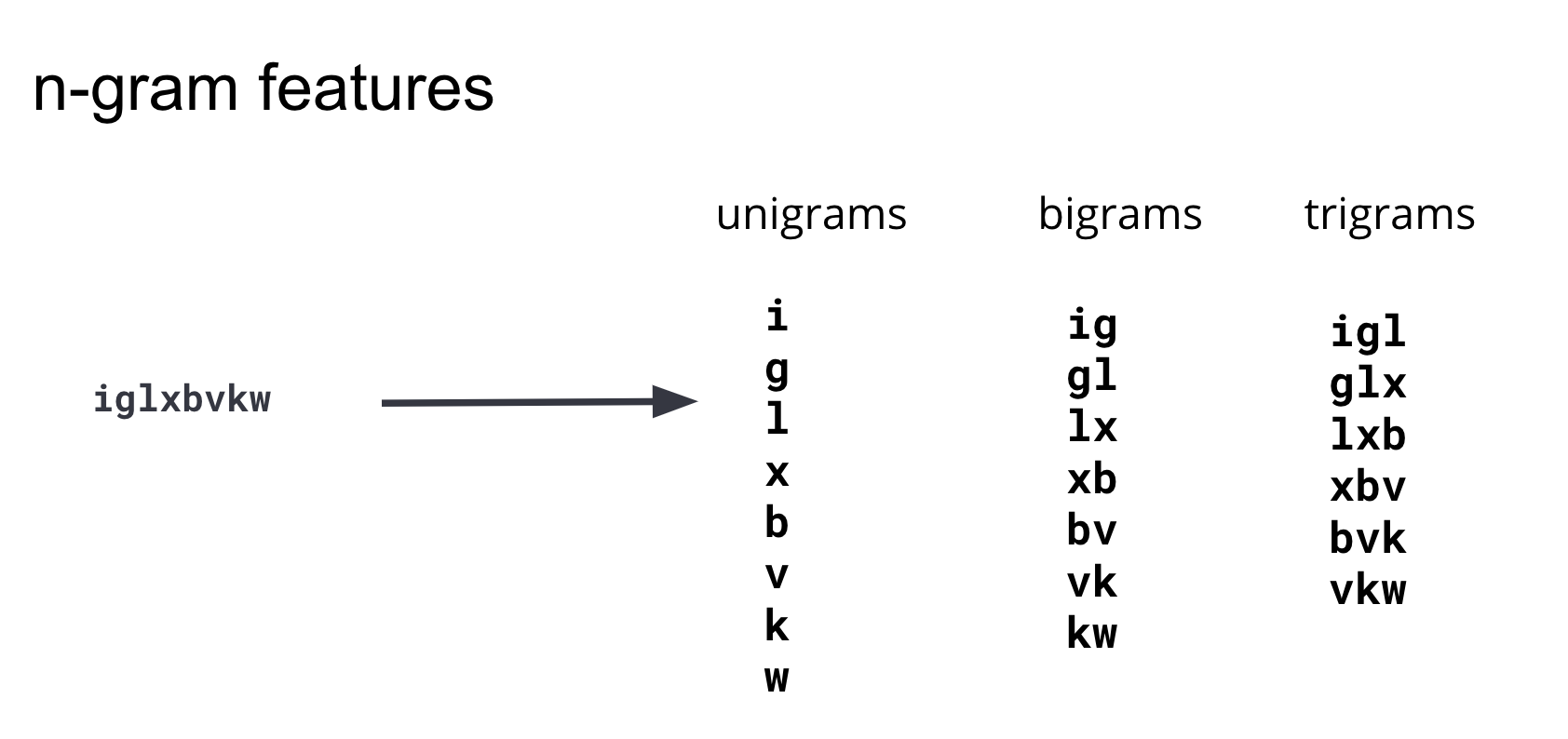
Estas subcadenas se conocen comúnmente como n-gramas. Al desarrollar características, es importante equilibrar su cantidad (la dimensionalidad del set de datos de entrenamiento) y la complejidad de procesar las características con su beneficio para el modelo. Después de iterar y probar n-gramas de varias longitudes, concluimos que los n-gramas con una longitud 4 o mayor no agregaban información predictiva significativa al modelo, por lo tanto nuestro conjunto de características se restringe a unigramas, bigramas y trigramas. El diagrama en la Figura 3 ilustra cómo se generan estas características a partir de un dominio de ejemplo.
Para generar un índice de Elasticsearch en el que cada dominio de DGA esté dividido en unigramas, bigramas y trigramas, puedes volver a indexar el índice fuente original a través de un pipeline de ingesta con un procesador de scripts de Painless. En la Figura 4 a continuación se muestra un ejemplo. Para ver las configuraciones completas, instrucciones y varias opciones de personalización, consulta el repositorio de ejemplos.
POST _scripts/ngram-extractor-reindex
{
"script": {
"lang": "painless",
"source": """
String nGramAtPosition(String fulldomain, int fieldcount , int n){
String domain = fulldomain.splitOnToken('.')[0];
if (fieldcount+n>=domain.length()){
return ''
}
else
{
return domain.substring(fieldcount, fieldcount+n)
}
}
for (int i=0;i<ctx['domain'].length();i++){
ctx[Integer.toString(params.ngram_count)+'-gram_field'+Integer.toString(i)] = nGramAtPosition(ctx['domain'], i, params.ngram_count)
}
"""
}
}
En general, sería necesario un preprocesamiento más exhaustivo para convertir las subcadenas de longitudes 1, 2 y 3 en vectores numéricos para el algoritmo de Machine Learning. En nuestro caso, Machine Learning de Elastic se ocupará de esta conversión en valores numéricos, también llamada codificado. Machine Learning de Elastic también examinará las características y seleccionará automáticamente las que tengan más información.
Creación de un trabajo de Data Frame Analytics
El siguiente paso es usar la UI de Data Frame Analytics para crear un trabajo de clasificación. Resaltamos algunos aspectos importantes de este proceso en las capturas de pantalla a continuación.
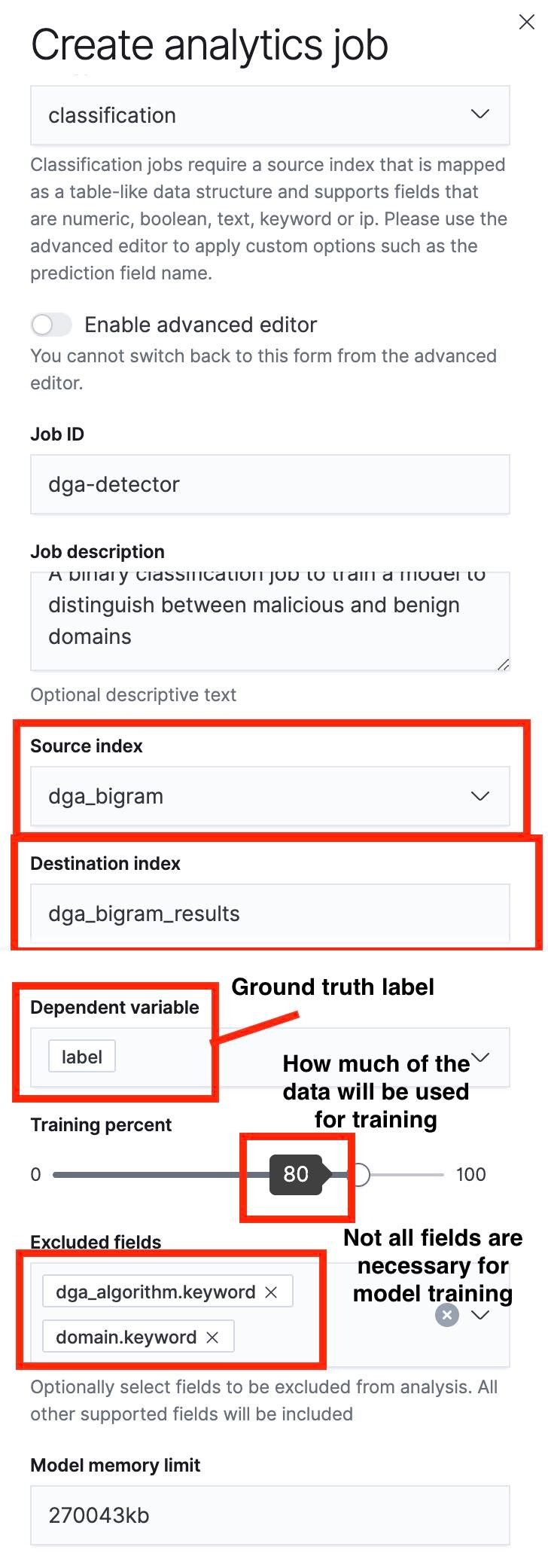
Un aspecto clave para tener en cuenta es que podemos especificar una división de entrenamiento/prueba con el control deslizante. En la captura de pantalla de la Figura 5, la división de entrenamiento/prueba está configurada en 80 %, lo que significa que el 80 % de los documentos del índice fuente se usará para entrenar el modelo y el 20 % restante se usará para probar el modelo.
Una vez completado el proceso de entrenamiento, podemos navegar a la UI de resultados de Data Frame Analytics para evaluar el rendimiento del modelo. Como dividimos nuestro índice fuente en un conjunto de entrenamiento y uno de prueba, podremos ver el rendimiento del modelo en cada uno. Aunque tanto el rendimiento de entrenamiento como el de prueba proporcionan información valiosa, en este caso nos interesa más el rendimiento del modelo con el set de datos de prueba porque nos dará una idea del error de generalización en un modelo. Este error indica cómo rendirá el modelo en puntos de datos con los que no se encontró antes.
Evaluación de un modelo de Machine Learning
Una vez completado el proceso de entrenamiento, podemos hacer clic para ver los resultados de la página de gestión de trabajos de la UI de Machine Learning de Elastic.
La página de resultados (ver Figura 6) nos da dos datos clave: una matriz de confusión que resume el rendimiento de nuestro modelo y una tabla de resultados en la que podemos explorar y ver la clasificación de los puntos de datos individuales realizada por el modelo. Podemos alternar entre la matriz de confusión y la tabla de resumen de los sets de datos de prueba y entrenamiento con los filtros Testing/Training (Pruebas/Entrenamiento) en la parte superior derecha de la tabla.
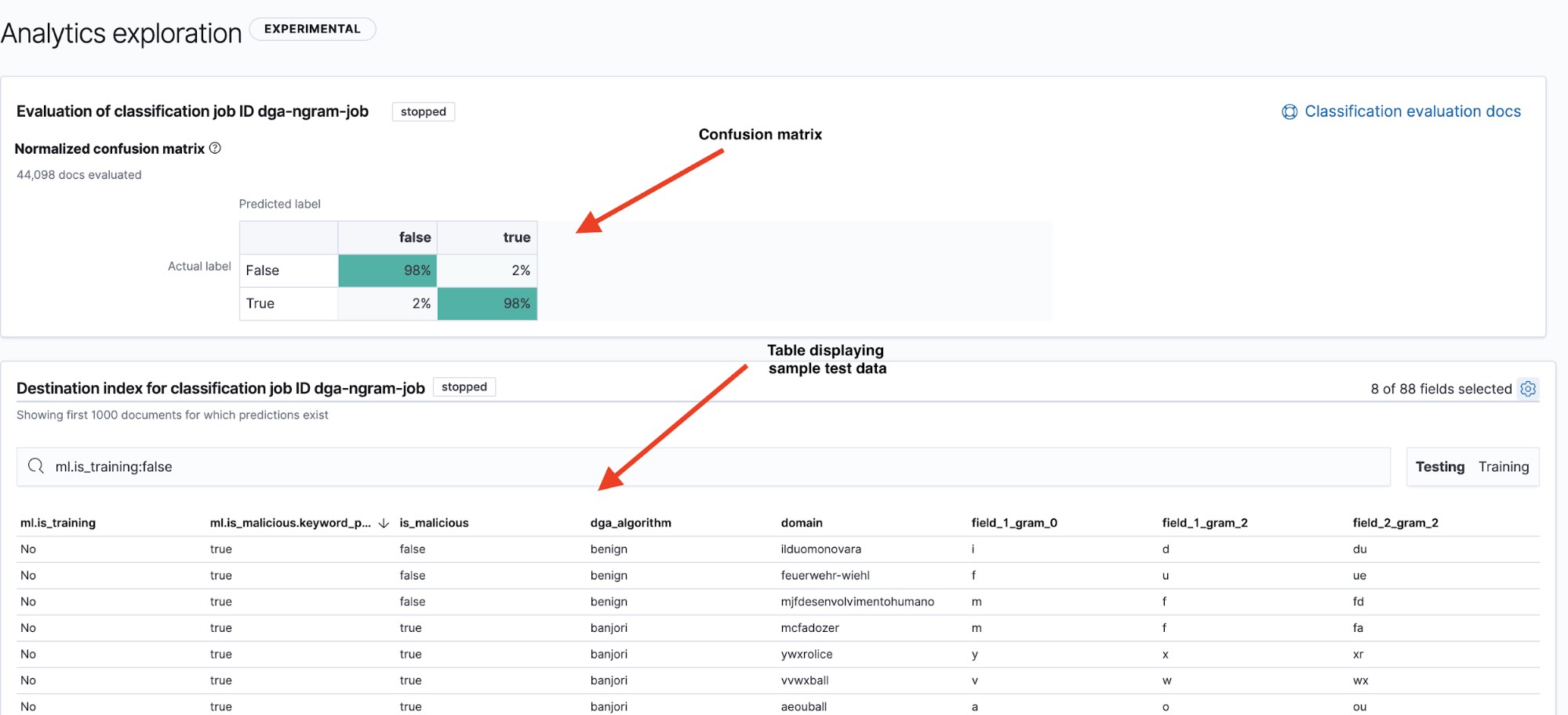
Una forma común de mostrar el rendimiento de un modelo es con una visualización conocida como confusion matrix. La matriz de confusión muestra el porcentaje de puntos de datos que se clasificaron como true positives (los dominios maliciosos que el modelo identificó como maliciosos y que realmente lo eran) y true negatives (los dominios benignos que el modelo identificó como benignos), además del porcentaje de documentos en el que el modelo confundió dominios benignos como maliciosos (false positives) o viceversa (false negatives).
Fiel a su nombre, la matriz de confusión nos mostrará rápidamente si un modelo confunde con frecuencia instancias de una clase por otra.
En la Figura 6, vemos que nuestro modelo tiene una tasa de positivos verdaderos del 98 % en los datos de prueba. Esto significa que si desplegáramos este modelo en producción para clasificar datos de DNS entrantes, podríamos esperar ver una tasa de falsos positivos del 2 % aproximadamente. Aunque parece una cifra razonablemente baja, el alto volumen de tráfico de DNS significa que aún llevaría a una tasa de alertas bastante alta. En la parte 2, veremos cómo se puede usar la detección de anomalías para reducir la cantidad de alertas por falsos positivos.
Conclusión
En este blog, abordamos una breve visión general de cómo usar Machine Learning de Elastic para crear y evaluar un modelo de Machine Learning para la detección de DGA. Examinamos el proceso de extraer características de dominios benignos y maliciosos sin procesar, y explicamos un poco del proceso para encontrar características adecuadas. Por último, echamos un vistazo a cómo entrenar y evaluar un modelo de Machine Learning con el Elastic Stack.
En la parte siguiente de la serie, veremos cómo usar los procesadores de inferencias en los pipelines de ingesta para desplegar este modelo con el objetivo de enriquecer los datos de Packetbeat entrantes con predicciones sobre la maliciosidad de los dominios y cómo usar trabajos de detección de anomalías para reducir la cantidad de alertas por falsos positivos. Mientras tanto, prueba nuestras características de Machine Learning de forma gratuita para ver el tipo de conocimientos que puedes liberar cuando logras sortear las distracciones de tus datos.