



Ingesting and Exploring Scientific Papers using Elastic Cloud
With Elasticsearch 5.0 released, let's explore some of its newest features! One of those features is the brand spanking new Ingest Node. I won’t dive deep into the Ingest Node internals here, but If you’d like a refresher, check out our blog post introducing it.
One specific ingest processor that we will explore is the Ingest Attachment Processor. We will explore how to use it to index a dataset of PDFs for analysis. Previously, you would have used the Mapper Attachment Plugin to index PDFs into Elasticsearch 2.x. Since this is a type of pre-processing step, it should not have been done in Elasticsearch itself. Now that we have a way to manage pre-processing more effectively, this plugin has been converted into an Ingest Node processor.
The Ingest Attachment processor makes it simple to index common document formats (such as PPT, XLS, PDF) into Elasticsearch using the text extraction library Tika.
More specifically, we will walk through an example of using the new Ingest Node on Elastic Cloud to explore the text of thousands of academic documents hosted on the repository for scientific papers ArXiv.
Elastic Cloud With Ingest Attachment
First, we need to set up a new Elasticsearch cluster with Ingest Node (and the attachment plugin) on Elastic Cloud. Here is how we set up a new 5.0 cluster with the relevant ingest plugins:
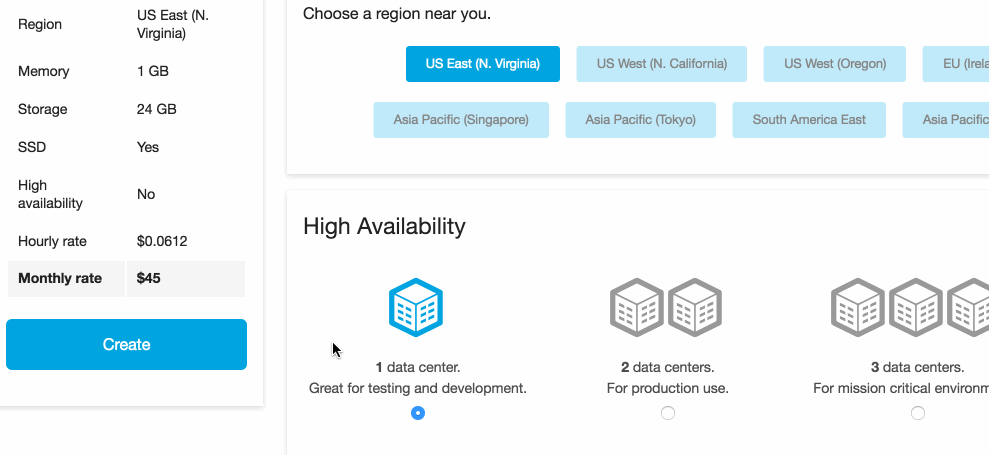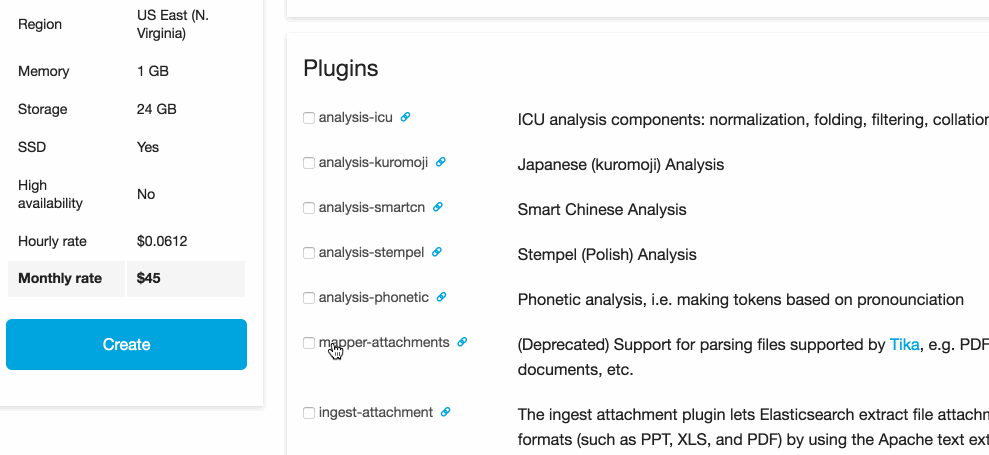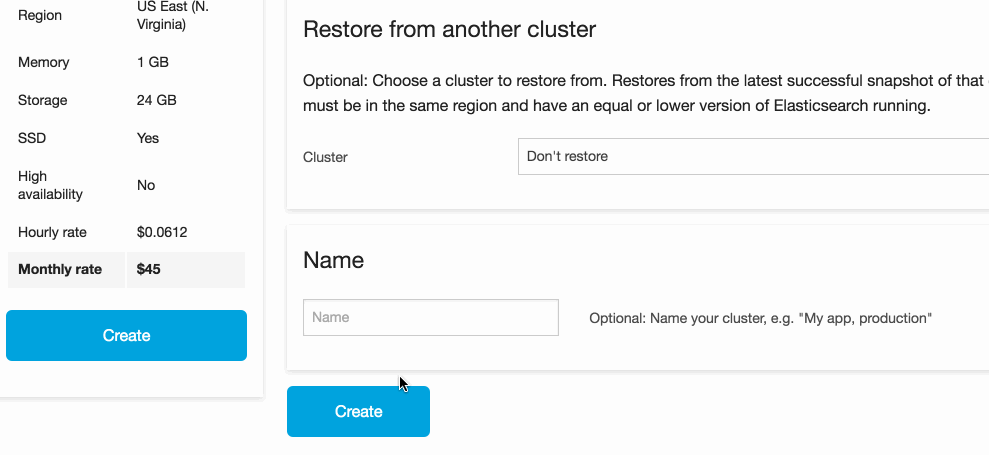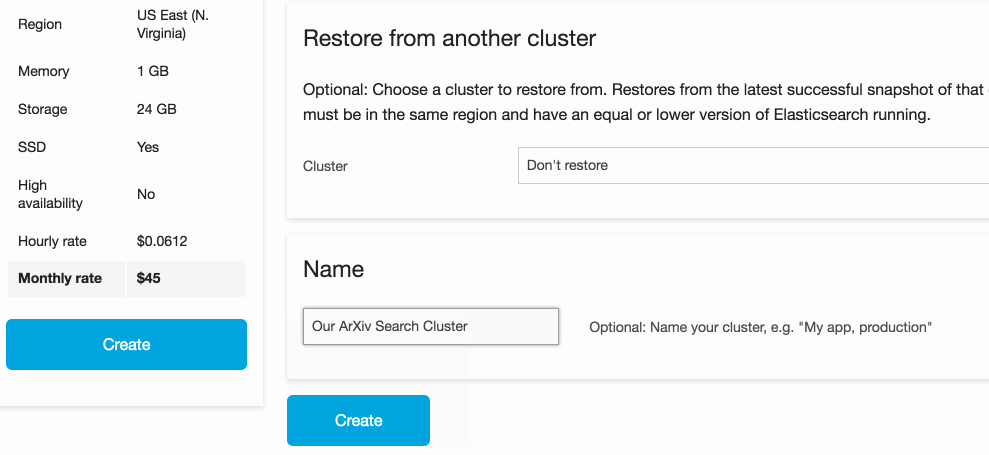
We have selected the Ingest AttachmentProcessor Plugin to be installed into our cluster.
Now that we have a cluster set up, let’s collect the data and index!
Ingest Pipeline
To prepare Elasticsearch for indexing, we will define an ingest pipeline that will process a base64 encoded field called pdf, and then remove the original field. the attachment processor will introduce a new set of fields in the document under the attachment field. Such fields as content_type, language, content_length, and content (the processed text).
PUT _ingest/pipeline/arxiv-pdf
{
"description": "parse arxiv pdfs and index into ES",
"processors" :
[
{ "attachment" : { "field": "pdf" } },
{ "remove" : { "field": "pdf" } },
]
}
ArXiv.org Data Collection and Indexing
Before we start indexing, let me introduce the actual set of documents we will be analyzing. ArXiv.org hosts all of their papers on Amazon’s S3. We follow this guide to download a subset of the papers.
We will be using the Elasticsearch Python Client to index these documents into Elasticsearch. Here is a snippet of the indexing code:
for ok, result in streaming_bulk(
client,
documents(),
index="arxiv",
doc_type="arxiv",
chunk_size=4,
params={"pipeline": "arxiv-pdf"}
):
action, result = result.popitem()
if not ok:
print("failed to index document")
else:
print("Success!")
In the above example code, we use the streaming_bulk helper method of the Elasticsearch client to index our documents. documents() is another helper function to read our files from the pdfs directory and convert them into Elasticsearch documents. The important parameter to highlight here is the pipeline. This parameter tells Elasticsearch to use our arxiv-pdf pipeline when indexing our document so that it can be pre-processed with the attachment processor.
That’s it! Now we can start exploring the textual content of these papers.
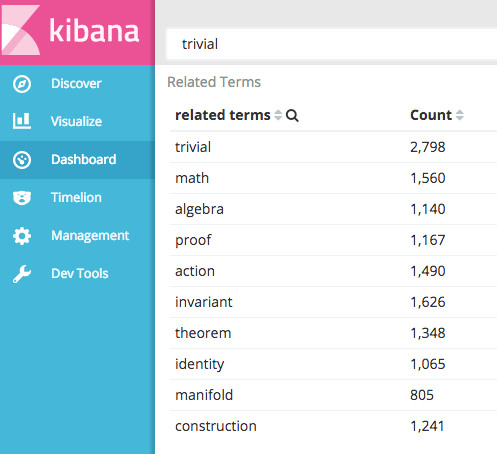
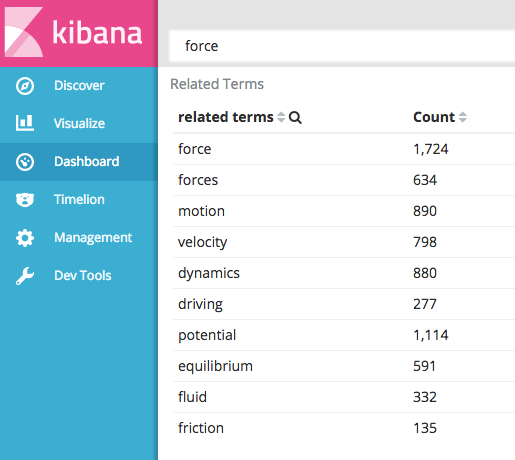
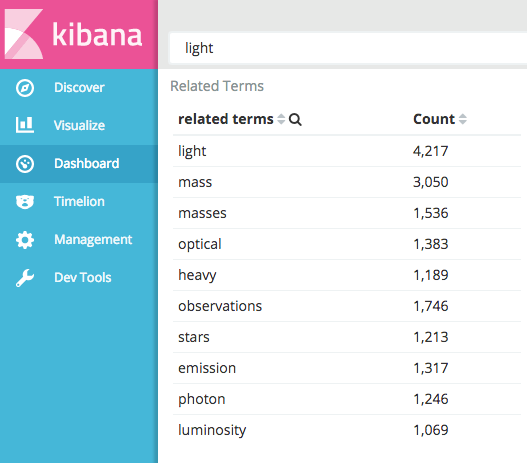
Related Terms in Kibana
Now we can begin exploring the relations between terms in these papers. Using the significant terms aggregation in Kibana, we can begin seeing relationships between keywords in the text that are not necessarily popular, but are interesting or more relevant to our search queries. Here are just a few searches that show words that may be related. This type of analysis is useful to determine potential synonyms for improving term relevancy.
Conclusion
5.0 is out and the new Ingest Node is just one of the many new and exciting features. You can experience all the new features on Elastic Cloud now!