Cómo monitorear las métricas de NVIDIA GPU con Elastic Observability
Las unidades de procesamiento gráfico, o GPU, no sirven solo para juegos de PC. Actualmente, las GPU se usan para entrenar redes neuronales, simular dinámicas de fluido computacionales, minar Bitcoin y procesar cargas de trabajo en centros de datos. Y son la esencia de la mayoría de los sistemas informáticos de alto rendimiento, lo cual hace que el monitoreo del rendimiento de las GPU en los centros de datos actuales sea tan importante como el monitoreo del rendimiento de las CPU.
Con eso en mente, veamos cómo usar Elastic Observability junto con las herramientas de monitoreo de GPU de NVIDIA para observar y optimizar el rendimiento de las GPU.
Dependencias
Para poner en marcha las métricas de GPU de NVIDIA, tendremos que compilar las herramientas de monitoreo de GPU de NVIDIA a partir del código fuente (Go). Y sí, necesitaremos una GPU de NVIDIA. Las GPU de AMD y de otros tipos usan herramientas de monitoreo y controladores de Linux diferentes, por lo que las abordaremos en otro blog.
Las GPU de NVIDIA están disponibles en muchos Proveedores Cloud como Google Cloud y Amazon Web Services (AWS). En este blog, usamos una instancia que se ejecuta en Genesis Cloud.
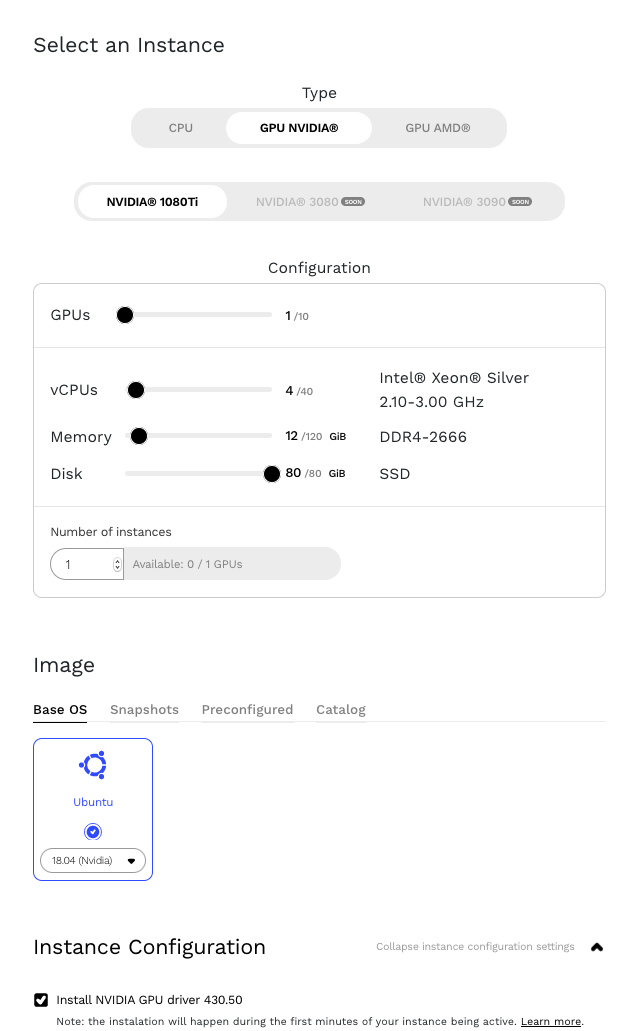
Comencemos por instalar NVIDIA Datacenter Manager según la sección de instalación de la DCGM Getting Started Guide (Guía de primeros pasos con DCGM) de NVIDIA para Ubuntu 18.04. Nota: Cuando sigas las instrucciones de la guía, presta especial atención a reemplazar el parámetro <architecture> con el nuestro. Podemos encontrar nuestra arquitectura con el comando uname.
uname -a
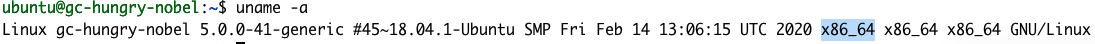
La respuesta nos indica que nuestra arquitectura es X86_64. Entonces, el paso 1 en la guía de primeros pasos sería el siguiente:
echo "deb http://developer.download.nvidia.com/compute/cuda/repos/$distribution/x86_64 /" | sudo tee /etc/apt/sources.list.d/cuda.list
También hay un error tipográfico en el paso 2. Elimina > al final de $distribution.
sudo apt-key adv --fetch-keys https://developer.download.nvidia.com/compute/cuda/repos/$distribution/x86_64/7fa2af80.pub
Después de la instalación, deberíamos poder ver los detalles de nuestra GPU con el comando nvidia-smi.
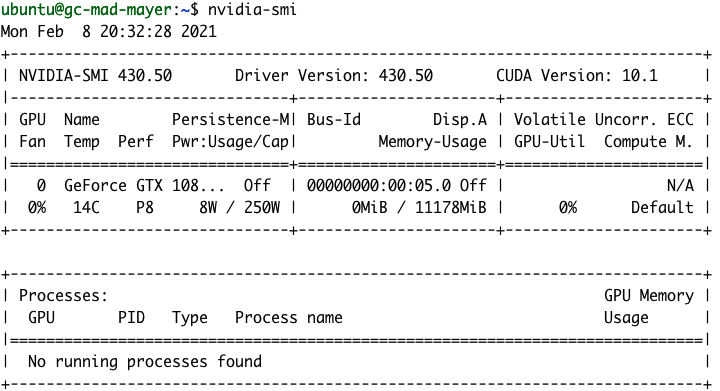
NVIDIA gpu-monitoring-tools
Para compilar NVIDIA gpu-monitoring-tools, tendremos que instalar Golang. Hagamos eso ahora.
cd /tmp wget https://golang.org/dl/go1.15.7.linux-amd64.tar.gz sudo mv go1.15.7.linux-amd64.tar.gz /usr/local/ cd /usr/local/ sudo tar -zxf go1.15.7.linux-amd64.tar.gz sudo rm go1.15.7.linux-amd64.tar.gz
Bien, es hora de terminar la configuración de NVIDIA instalando gpu-monitoring-tools de NVIDIA desde GitHub.
cd /tmp git clone https://github.com/NVIDIA/gpu-monitoring-tools.git cd gpu-monitoring-tools/ sudo env "PATH=$PATH:/usr/local/go/bin" make install
Metricbeat
Ahora estamos listos para instalar Metricbeat. Echa un vistazo rápido a elastic.co para conocer cuál es la versión más reciente de Metricbeat y ajustar el número de versión en los comandos siguientes.
cd /tmp wget https://artifacts.elastic.co/downloads/beats/metricbeat/metricbeat-7.10.2-amd64.deb sudo dpkg -i metricbeat-7.10.2-amd64.deb # 7.10.2 es el número de versión
Elastic Cloud
Bien, pongamos en marcha el Elastic Stack. Necesitaremos un hogar para nuestros nuevos datos de monitoreo de GPU. Para ello, crearemos un nuevo despliegue en Elastic Cloud. Si no eres un cliente existente de Elastic Cloud, puedes registrarte para una prueba gratuita de 14 días. Como alternativa, puedes configurar tu propio despliegue de forma local.
A continuación, crea un nuevo despliegue de Elastic Observability en Elastic Cloud.
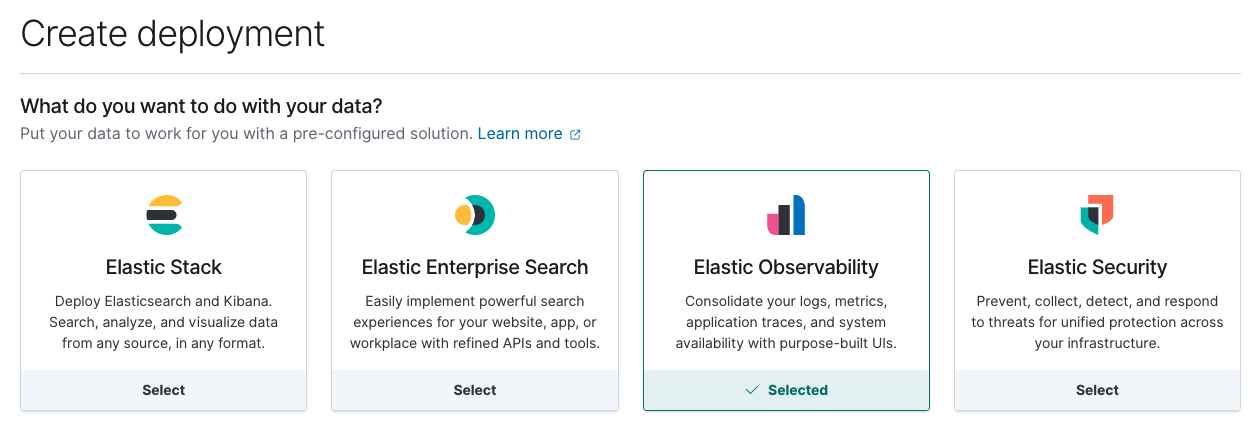
Una vez que el despliegue en el cloud esté en marcha, toma nota de su Cloud ID y credenciales de autenticación; las necesitaremos para la configuración de Metricbeat que haremos.
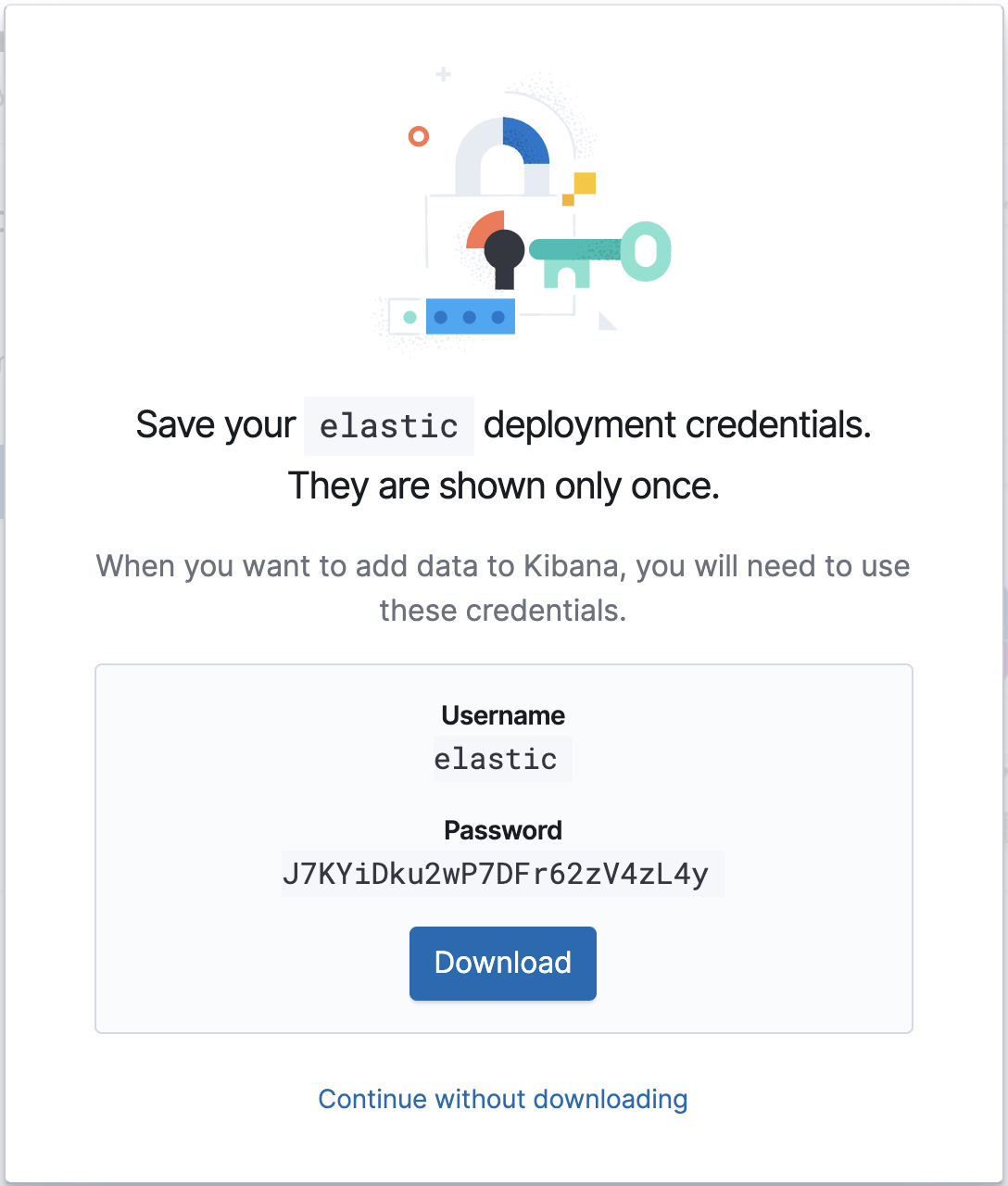
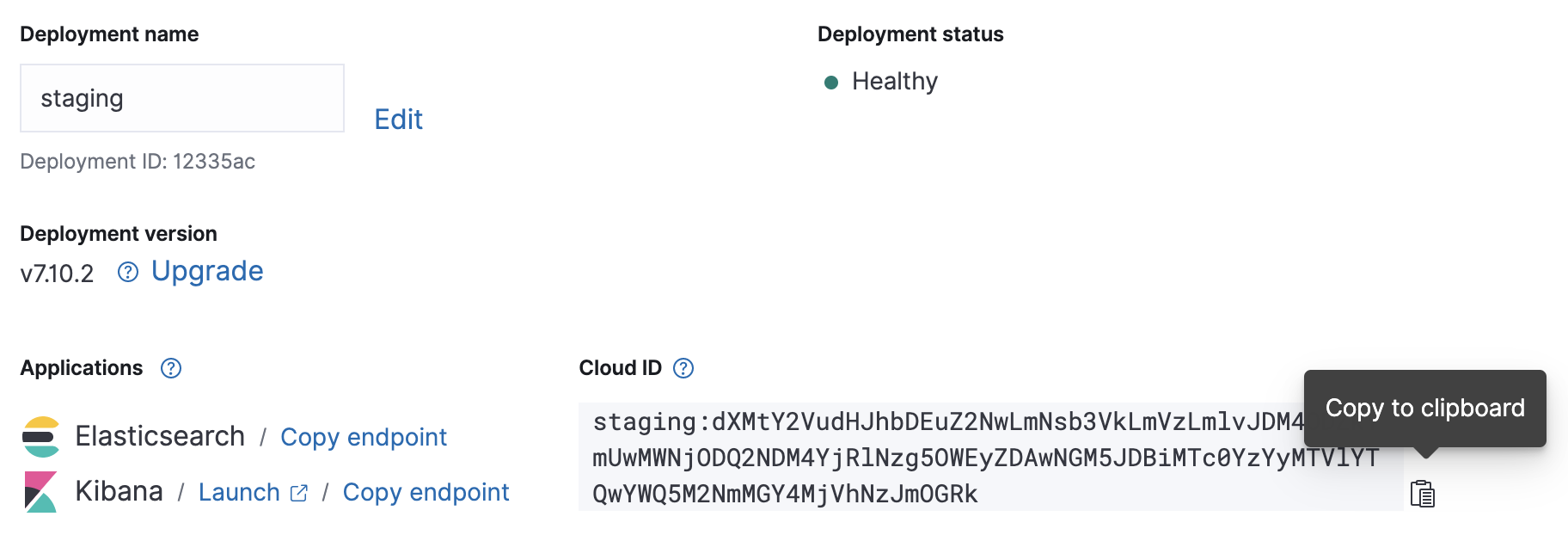
Configuración
El archivo de configuración de Metricbeat se encuentra en /etc/metricbeat/metricbeat.yml. Ábrelo en tu editor favorito y edita los parámetros cloud.id y cloud.auth para que coincidan con tu despliegue.
Ejemplo de cambios de configuración de Metricbeat con las capturas de pantalla anteriores:
cloud.id: "staging:dXMtY2VudHJhbDEuZ2NwLmNsb3VkLmVzLmlvJDM4ODZkYmUwMWNjODQ2NDM4YjRlNzg5OWEyZDAwNGM5JDBiMTc0YzYyMTVlYTQwYWQ5M2NmMGY4MjVhNzJmOGRk" cloud.auth: "elastic:J7KYiDku2wP7DFr62zV4zL4y"
La configuración de entrada de Metricbeat es modular. NVIDIA gpu-monitoring-tools publica las métricas de GPU a través de Prometheus, así que avancemos y habilitemos ahora el módulo de Metricbeat de Prometheus.
sudo metricbeat modules enable prometheus
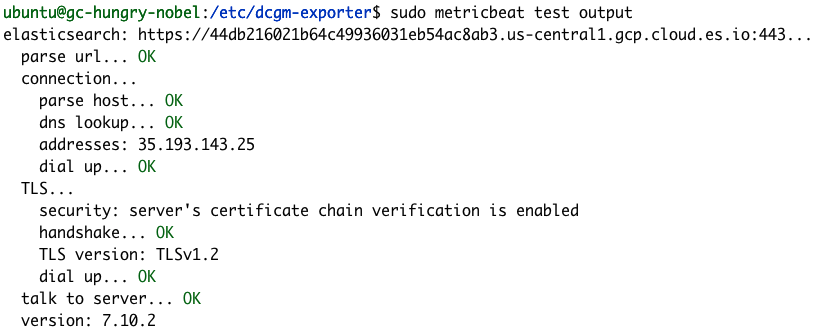
Podemos confirmar que nuestra configuración de Metricbeat se completó correctamente usando los comandos de módulos y prueba de Metricbeat.
sudo metricbeat test config

sudo metricbeat test output
sudo metricbeat modules list
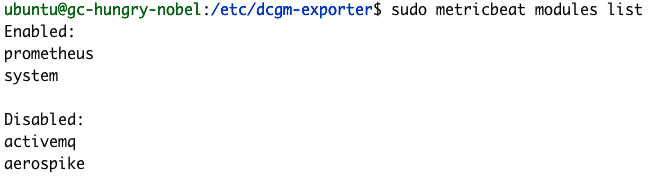
Si tus pruebas de configuración no se completan correctamente como en los ejemplos anteriores, echa un vistazo a la guía de solución de problemas de Metricbeat.
Completamos la configuración de Metricbeat ejecutando el comando de configuración, que cargará algunos dashboards predeterminados y configurará mapeos de índices. El comando de configuración generalmente tarda unos minutos en completarse.
sudo metricbeat setup

Exportación de métricas
Es hora de comenzar a exportar las métricas. Iniciemos dcgm-exporter de NVIDIA.
dcgm-exporter --address localhost:9090 # Salida INFO[0000] Starting dcgm-exporter INFO[0000] DCGM successfully initialized! INFO[0000] Not collecting DCP metrics: Error getting supported metrics: This request is serviced by a module of DCGM that is not currently loaded INFO[0000] Pipeline starting INFO[0000] Starting webserver
Nota: Puedes ignorar la advertencia de DCP.
La configuración de las métricas de dcgm-exporter se define en el archivo /etc/dcgm-exporter/default-counters.csv, en el cual hay 38 métricas diferentes definidas de forma predeterminada. Para conocer la lista completa de valores posibles, podemos consultar la DCGM Library API Reference Guide (Guía de referencia de API de la biblioteca de DCGM).
En otra consola, iniciaremos Metricbeat.
sudo metricbeat -e
Ahora puedes pasar a la instancia de Kibana y actualizar el patrón de índice ‘metricbeat-*’. Podemos hacerlo navegando a Stack Management (Gestión de stacks) > Kibana > Index Patterns (Patrones de índices) y seleccionando el patrón de índice metricbeat-* en la lista. Después haz clic en Refresh field list (Actualizar lista de campos).
Ahora nuestras nuevas métricas de GPU están disponibles en Kibana. Los nombres de campo nuevos tienen el prefijo prometheus.metrics.DCGM_. En este fragmento se muestran los campos nuevos de Discover (Descubrir).
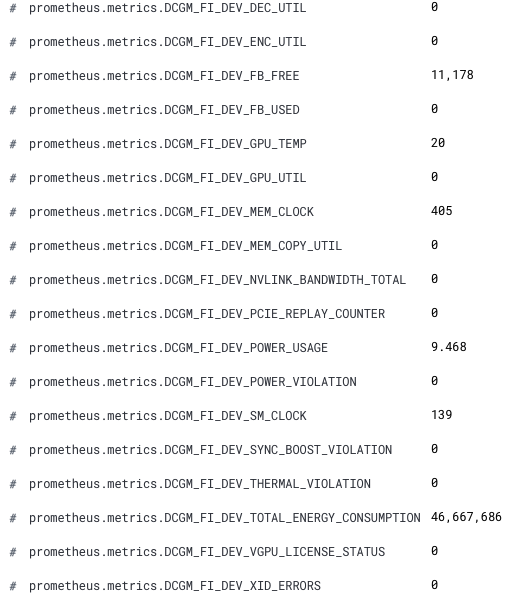
¡Felicitaciones! Ya estás listo para analizar nuestras métricas de GPU en Elastic Observability.
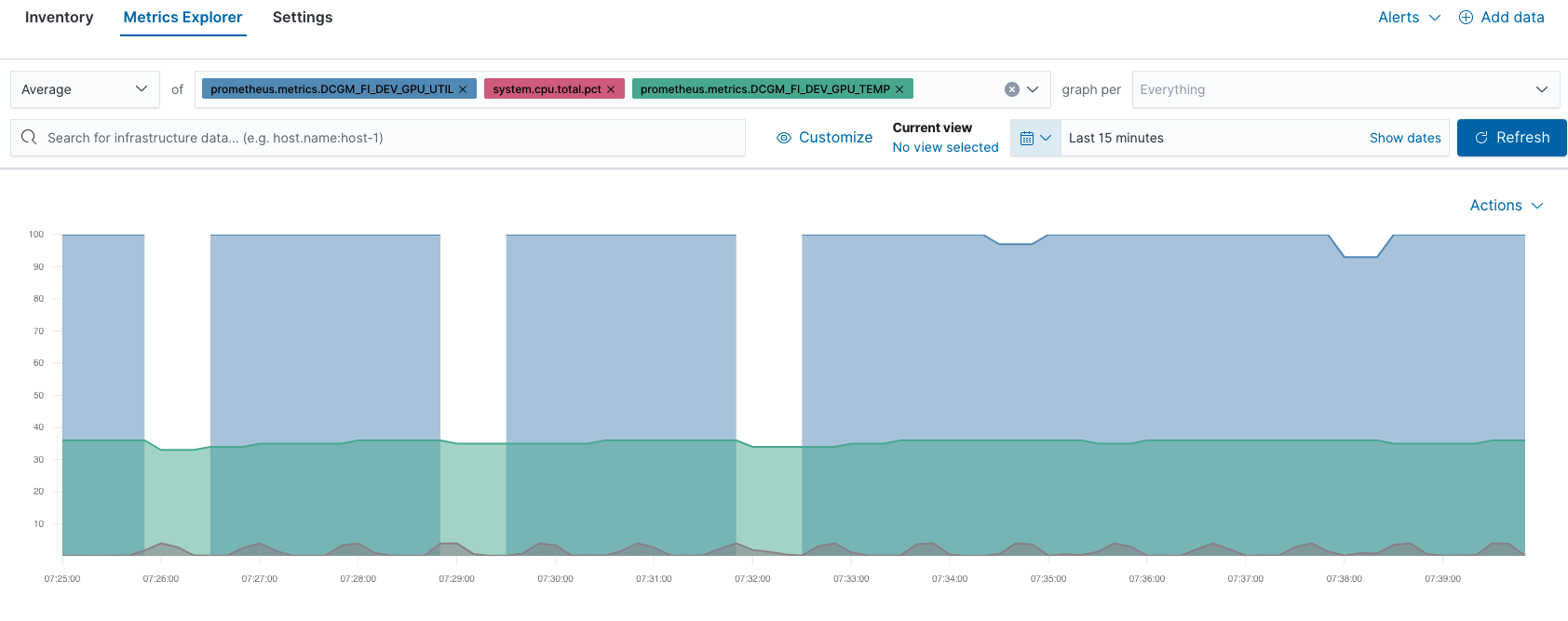
Por ejemplo, puedes comparar el rendimiento de la GPU y la CPU en Metrics Explorer (Explorador de métricas):
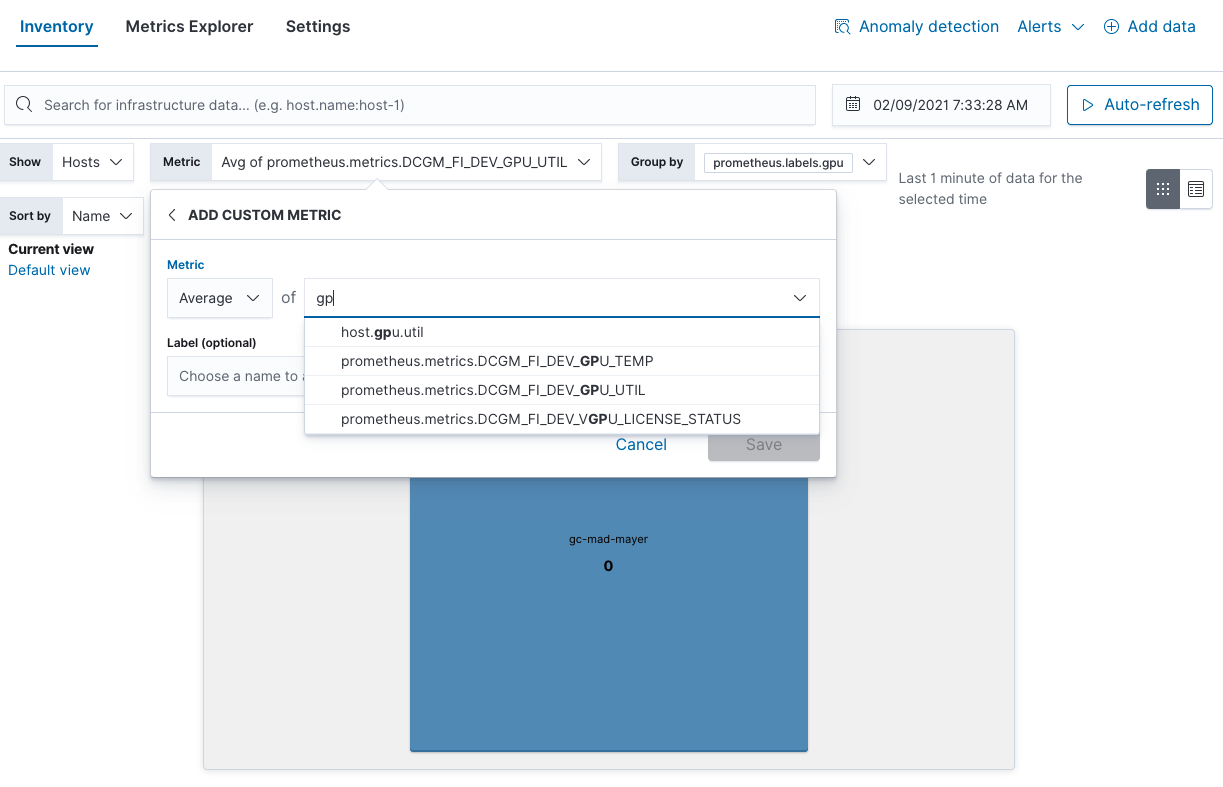
También puedes encontrar los puntos críticos de uso de la GPU en la vista Inventory (Inventario):
Consideraciones de monitoreo de GPU
Esperamos que este blog te haya resultado útil. Son solo algunas opciones de monitoreo, pero Elastic Observability te permite abordar todos tus objetivos. Estos son algunos otros ejemplos de buenas cosas de GPU para monitorear según NVIDIA:
- Temperatura de GPU: buscar puntos críticos
- Consumo de energía de GPU: consumo mayor del esperado => posibles problemas de hardware
- Velocidades actuales de los relojes: inferiores a las esperadas => problemas de limitación de potencia o hardware
Y si alguna vez necesitas simular una carga de GPU, puedes usar el comando dcgmproftester10.
dcgmproftester10 --no-dcgm-validation -t 1004 -d 30
Puedes elevar el monitoreo con las alertas de Elastic para automatizar las recomendaciones de NVIDIA. Y después llevarlo al siguiente nivel buscando anomalías en tu infraestructura de GPU con Machine Learning. Si no eres un cliente existente de Elastic Cloud y te gustaría probar los pasos de este blog, puedes registrarte para una prueba gratuita de 14 días.