Generación y visualización de alfa con sets de datos de Vectorspace AI y Canvas
Resumen
Esta es la historia de cómo los sets de datos de Vectorspace comenzaron a usar el Elastic Stack y Canvas en Kibana, para visualizar información y liberar el poder y el valor de los datos.
Antecedentes
En 2002 en el Laboratorio Nacional Lawrence Berkeley, Vectorspace creó vectores de características basados en Comprensión de lenguaje natural (NLU), también conocidos actualmente como incrustaciones de palabras. Los vectores de características se usaron para generar sets de datos de la matriz de correlaciones con el objetivo de analizar relaciones ocultas entre genes relacionados con la prolongación del tiempo de vida, el cáncer de mama y la reparación del daño al ADN como resultado de la radiación espacial.
Las fuentes de datos incluyeron resultados de experimentos de laboratorio, bibliografía científica de la Biblioteca Nacional de Medicina (NLM), ontologías, vocabularios controlados, enciclopedias, diccionarios y otras bases de datos de investigación genómica.
En su momento, también implementaron AutoClass, un clasificador bayesiano usado para clasificar estrellas, y lo usaron para clasificar grupos de genes conforme a un set de datos que contenía valores de expresión de genes. Las pérdidas se minimizaron y los resultados resultaron más útiles al incrementar los sets de datos con incrustaciones de palabras y modelado de temas. En ese entonces, el objetivo era imitar conexiones conceptuales que pudiera hacer un investigador biomédico justo antes de un descubrimiento, in silico. Una parte de este trabajo se incluyó en una publicación en la que se describen las relaciones ocultas entre los genes relacionadas con la prolongación del tiempo de vida de los nematodos. En 2005, se involucró la división SPAWAR de la Marina de Guerra de EE. UU., lo que permitió más recursos para ampliar la investigación en áreas como los mercados financieros.
Potenciamiento de un set de datos
Con el tiempo, Vectorspace aprendió a potenciar los sets de datos incrementando o uniendo vectores de características representados por incrustaciones de palabras. Esto resultó en la generación de nuevas visualizaciones, interpretaciones, hipótesis o descubrimientos. Incrementar los sets de datos temporales para los mercados financieros con estos tipos de vectores de características puede producir señales únicas o generar alfa. Todo comienza con fuentes de datos optimizadas para un tema o contexto seleccionado como se ilustra a continuación:
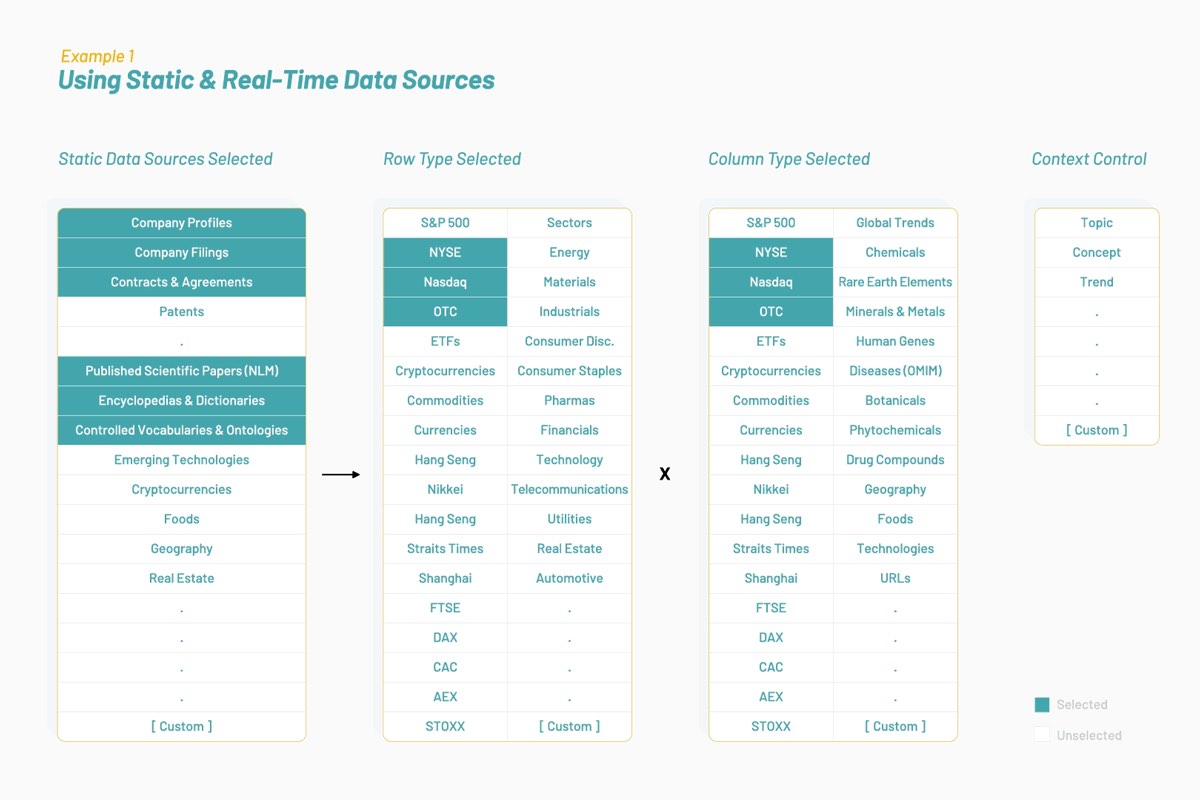
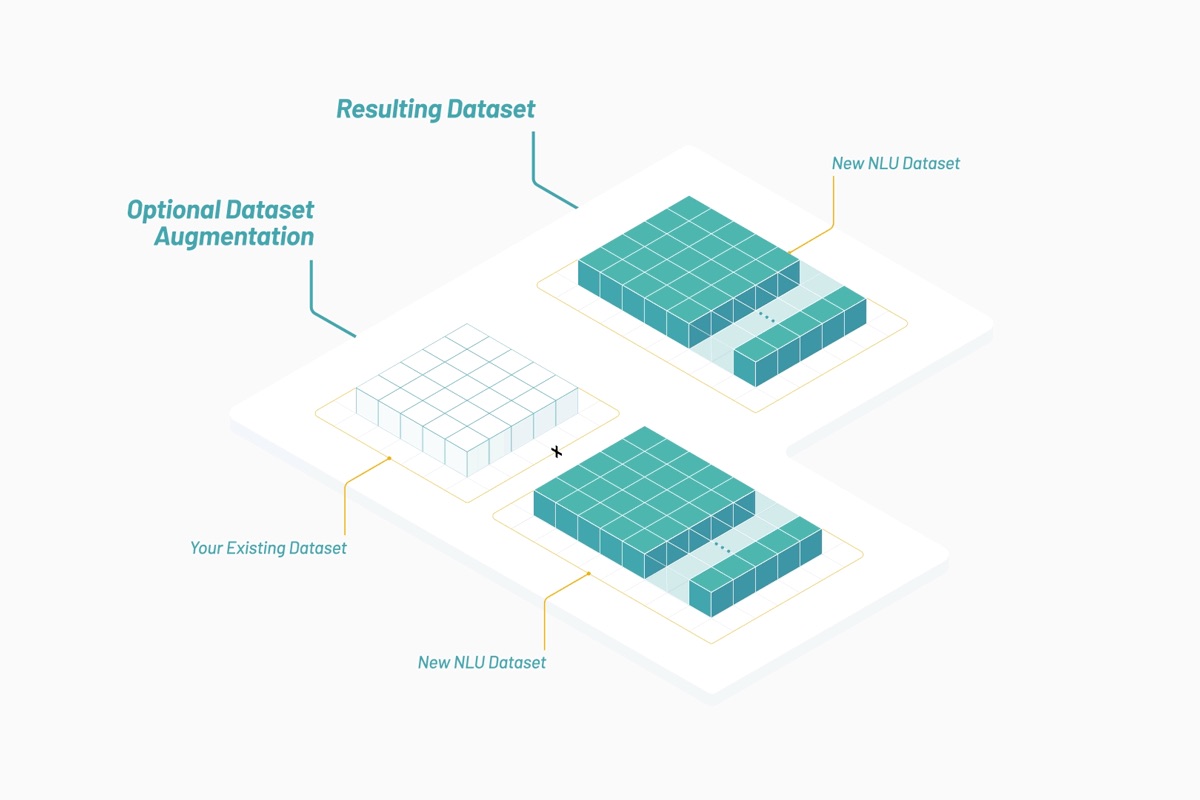
Los sets de datos resultantes están compuestos por vectores de características que son incrustaciones de palabras basadas en bibliografía biomédica y lenguaje humano en torno a empresas que cotizan en NYSE y Nasdaq. Un enfoque interdisciplinario de la investigación podría determinar si los genes y las acciones comparten atributos y comportamientos similares al interactuar en las trayectorias en común.
Establecimiento de un objetivo de dos partes
Parte uno: Determinar dónde aplicar en las acciones el conocimiento sobre las interacciones observadas entre genes, proteínas, fármacos y enfermedades.
Parte dos: Explorar cómo crear un medio para financiar la investigación relacionada con cómo hacer más seguros los vuelos espaciales con humanos a largo plazo mediante sets de datos incrementados para generar alfa en los mercados financieros.
Desencadenantes de eventos en alza
¿Las interacciones que se observaban entre los genes fueron similares a las interacciones entre las acciones? El 20 de septiembre de 2004, un evento proporcionó una respuesta parcial. Merck (MRK) cayó un 21 % (probablemente) debido a que su medicamento Vioxx potencialmente causaba infartos. Este evento desencadenó un movimiento solidario latente en el precio de las acciones de otras empresas farmacéuticas que cotizan en la bolsa, en especial, Pfizer (PFE). El incremento del set de datos que produjo Vectorspace habilitó la predicción de una reacción retrasada en la cotización de PFE basado en sus asociaciones con el medicamento Vioxx, que producía Merck. Veremos más detalles a continuación.
Una investigación más minuciosa descubrió una publicación interesante en The Journal of Finance, edición de febrero de 2001, con el título “Contagious Speculation and a Cure for Cancer: A Non-Event that Made Stock Prices Soar” (Especulación contagiosa y una cura para el cáncer: un no evento que disparó los precios de las acciones). En la publicación se describía un evento con una empresa llamada EntreMed (ENMD eran sus siglas en ese entonces):
“Un artículo de domingo del New York Times sobre un desarrollo potencial de fármacos nuevos para curar el cáncer provocó la suba del precio de las acciones de EntreMed de 12.063, al cierre del viernes, a 85 en la apertura y casi 52 al cierre del lunes. Cerró por encima de 30 durante las tres semanas posteriores. El entusiasmo se extendió a otras acciones de biotecnología. Sin embargo, el descubrimiento potencial en la investigación contra el cáncer ya se había reportado en la revista Nature y en varios periódicos conocidos como Times! más de cinco meses antes. Por lo tanto, la entusiasta atención pública indujo un aumento permanente en los precios de las participaciones, aunque no se presentó ninguna información genuinamente nueva”. Entre las muchas observaciones reveladoras que realizaron los investigadores, se destacó una en la conclusión: “los movimientos [de precios] pueden concentrarse en acciones con ciertas características en común, pero no es necesario que sean fundamentos económicos”. — (Huberman y Regev 387)
Con la experiencia previa de los equipos en áreas relacionadas con el desarrollo de algoritmos cuantitativos, la banca de inversión y la gestión de empresas que cotizan en la bolsa, comenzaron a observar similitudes entre los genes y las acciones. Al igual que los genes, las acciones tienen ‘valores de expresión’, atributos, relaciones ocultas entre sí y con eventos, temas o tendencias globales externos. Estas relaciones son una forma de conocimiento que tiende a estar incrustada en el lenguaje humano más que otra cosa. Como los genes, los clusters de acciones pueden interactuar y moverse de forma solidaria entre sí. Estos datos se pueden usar para predecir correlaciones de precios futuras entre valores según la ‘implicación latente’. Los clusters de acciones pueden actuar como ‘canastas’ que comparten relaciones conocidas y ocultas entre sí y con eventos externos. Los clusters o las canastas se pueden controlar con el contexto.
No todos los botes se elevan cuando sube la marea
Vectorspace se propuso analizar qué causaba las correlaciones observadas dado que identificaban una oportunidad de crear un medio de financiamiento a partir del aprovechamiento de una ineficiencia en los mercados financieros basada en “focos de información aprovechables”. Comenzaron a observar reacciones retrasadas entre las acciones, similares al modo en que un puerto o una bahía se llenan de agua y los botes se elevan minutos u horas luego de que sube la marea del océano afuera. La subida del agua en un puerto puede desencadenarse mediante un evento que luego eleva los botes en el puerto, y en este caso, los botes pueden considerarse clusters de activos negociables como acciones. En los mercados financieros, algunos botes se elevan y otros no. Predecir cuáles activos están correlacionados con un evento junto con la fortaleza y el contexto de esa correlación pueden proporcionar una señal valiosa. Es como tener una forma de información asimétrica que se puede usar para posicionarse al frente del mercado o disminuir el riesgo a largo o corto plazo al invertir capital. Esto también puede conocerse como ‘generar alfa’ que pueda visualizarse e interpretarse.
Para probar esta hipótesis de probabilidad de elevación del bote, se analizaron 20 años de datos para buscar patrones de movimientos solidarios o implicación latente entre los precios de las acciones de empresas que cotizan en la bolsa sobre la base de eventos en el mercado. Se descubrieron muchos ejemplos, incluidos los tres eventos a continuación: EntreMed (ENMD) 1998, Merck (MRK) 2004 y Celgene (CELG) 2019.
Evento 1: EntreMed (ENMD) gana el 608 % (4 de mayo de 1998)
EntreMed publicó noticias de que tenía una cura para un tipo de cáncer un viernes después del cierre del mercado. El precio de sus acciones era de USD 12 el viernes y abrió a USD 85 el lunes. En simpatía, una canasta de acciones también comenzó a subir; esto tenía correlaciones con ENMD basadas en el lenguaje humano en torno a la ciencia de las proteínas relacionada con las terapias contra el cáncer.
La publicación que describe este evento contiene algunos extractos relevantes:
pág. 392 párr. 4 “Los retornos de tres de estas superaron el 100 por ciento, los retornos de dos se encontraban entre el 50 y el 100 por ciento, y los retornos de otras dos empresas se encontraban entre el 25 y el 50 por ciento. Una comparación de estos retornos con la distribución de retorno extrema reportada en la Tabla I muestra lo poco frecuente que eran los retornos de estas siete acciones de biotecnología y, en especial, la falta de precedentes de su agrupación”.
pág. 395 párr. 1 “No es sorprendente esa noticia sobre un descubrimiento en la investigación contra el cáncer que no solo afecta las acciones de una empresa con derechos de comercialización directa para el desarrollo; el mercado puede reconocer efectos potenciales de extensión y suponer que otras empresas pueden beneficiarse con la innovación”.
pág. 396 párr. 3 “los movimientos pueden concentrarse en acciones con ciertas características en común, pero no es necesario que sean fundamentos económicos”.
Evento 2: Merck (MRK) cae un 25.8 % (30 de septiembre de 2004)
Merck retiró Vioxx, un medicamento de USD 2.5 mil millones, del mercado porque causaba infartos y accidentes cerebrovasculares por los inhibidores de la COX-2. Esta correlación tenía una causa. MRK cerró a USD 45.07 el día anterior y abrió a USD 33.40 el 30 de septiembre. Durante la experimentación con la incrustación de palabras como vectores de características, se halló que Pfizer (PFE) era la empresa más relacionada con Merck sobre la base de vectores de características similares dado que en ese momento trabajaban con un compuesto de fármaco similar basado en el inhibidor de la COX-2. Unas semanas después PFE cayó significativamente.
“El 17 de diciembre de 2004, Pfizer y el US National Cancer Institute anunciaron que dejaron de administrar Celebrex (celecoxib), un inhibidor de la ciclooxigenasa-2 (COX-2), en un ensayo clínico en curso para la investigación de su uso en la prevención de pólipos en el colon debido a un mayor riesgo de complicaciones cardiovasculares. El rofecoxib (Vioxx) de Merck, otro inhibidor de la COX-2, se retiró del mercado mundial en septiembre de 2004 debido a un mayor riesgo de infarto de miocardio y accidente cerebrovascular”. - CMAJ.
PFE cayó un 24 %, desde el cierre del día anterior con USD 28.98 a un mínimo de USD 21.99 ese día.
Evento 3: Celgene (CELG) gana el 31.8 % (3 de enero de 2019)
El 3 de enero de 2019, Bristol-Myers Squibb (BMY) adquirió Celgene (CELG) por USD 74 mil millones. CELG subió de la noche a la mañana de USD 66.64 a USD 87.86 por participación o ganó el 31.8 %. En un período de cuatro días, una canasta de acciones relacionadas con CELG produjeron una ganancia del 20 % basada en las relaciones encontradas en el lenguaje humano en torno a estas empresas. Las fuentes de datos que habilitan conexiones entre estas entidades incluyen repositorios de perfiles de empresas que cotizan en la bolsa y bibliografía científica revisada por colegas.
En el análisis de Vectorspace de este proceso, se halló que algunas correlaciones de NLU pueden causar correlaciones basadas en precios latentes entre valores y entre valores y eventos. El equipo observó muchos ejemplos como los anteriores que pueden se pueden usar para posicionarse al frente del mercado o participar en formas de arbitraje de la información.
Visualización de alfa
Actualmente en Vectorspace AI, los sets de datos están diseñados para detectar redes de relaciones ocultas entre interacciones de genes, proteínas, microbios, fármacos y enfermedades en las ciencias biológicas o entre valores en los mercados financieros. La mayoría de las veces, nuestros clientes usan estos sets de datos para incrementar los sets de datos internos existentes. Los sets de datos se generan usando combinaciones de vectores de características que consisten en atributos puntuados según la vectorización de palabras y objetos. Los sets de datos se actualizan casi en tiempo real y se accede a ellos a través de una API mediante créditos de tokens de la utilidad.
Gracias al uso del Elastic Stack y Canvas, Vectorspace puede proporcionar a los clientes una visualización e interpretación de los datos casi en tiempo real mediante vistas completamente configurables y con marca propia. Esto es importante para el proceso general, debido a que las nuevas interpretaciones e información pueden llevar a hipótesis, señales o descubrimientos nuevos.
Es común que las instituciones y empresas de gestión de activos soliciten soluciones de pipeline de ingeniería de datos en las instalaciones por cuestiones de privacidad. Empaquetar nuestro pipeline de ingeniería de datos usando Elastic Cloud Enterprise permite entregar una solución llave en mano para la generación de señales.
Los clientes de Vectorspace en los mercados financieros apuntan a optimizar las proporciones de señal a ruido, la generación de alfa, la minimización de una función de pérdida o la maximización de las proporciones de Sharpe o Sortino. Lo hacen al mismo tiempo que visualizan e interpretan resultados de estrategias de pruebas de comprobación basados en el incremento de sets de datos casi en tiempo real y limitan el sobreajuste de las pruebas de comprobación.
La frecuencia de actualización del set de datos puede ser de un minuto a un mes, según la volatilidad de las fuentes de datos subyacentes. Un paquete de sets de datos popular solicitado consiste en un set de datos de precio de serie temporal en el cual las filas contienen empresas farmacéuticas que cotizan en la bolsa incrementadas con vectores de características que son compuestos de fármacos con una puntuación de correlación basada en NLU. Elegir un contexto en el cual operar puede ser fundamental. Al igual que el contexto puede cambiar una definición, agregar la limitaciones contextuales correctas puede guiar un cambio en el valor de una puntuación de correlación con el tiempo. El contexto también puede controlar la fortaleza de las relaciones entre entidades y entre entidades y eventos.
Visualización con Canvas
Adentrémonos y usemos uno de estos sets de datos para generar y visualizar la canasta de acciones relacionadas con Celgene (CELG) junto con el evento que desencadenó un aumento retrasado del precio entre algunas de esas acciones. Haremos un recorrido por los pasos típicos que puede realizar un cliente de Vectorspace con estos sets de datos e interpretaremos los resultados casi en tiempo real y los resultados de una prueba de comprobación en Canvas. En primer lugar, uno miraría los resultados finales de todo un grupo de canastas para confirmar que la canasta de Celgene no se eligió por conveniencia.
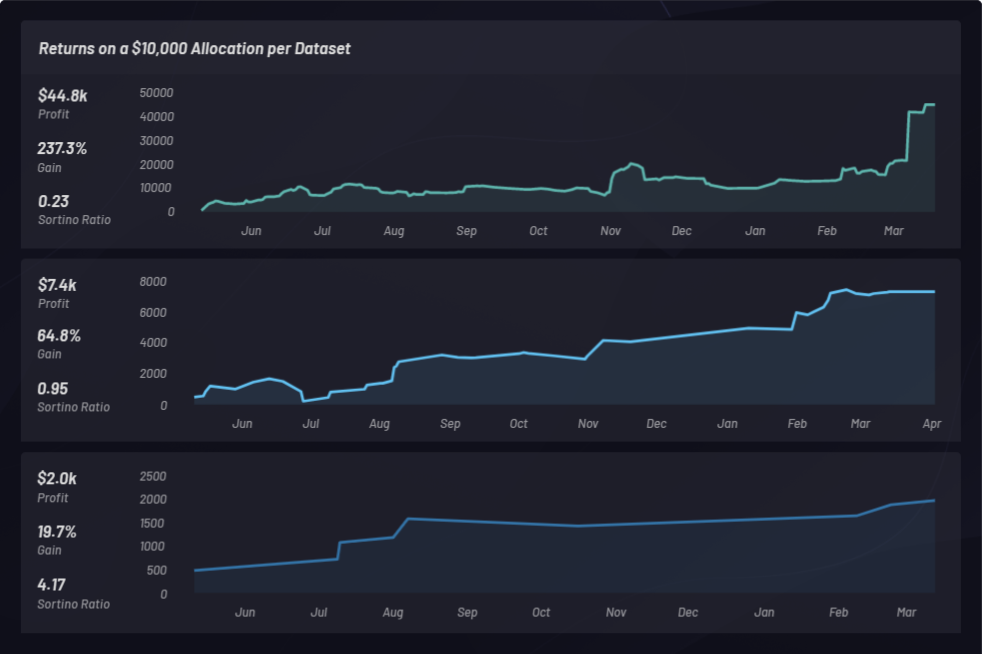
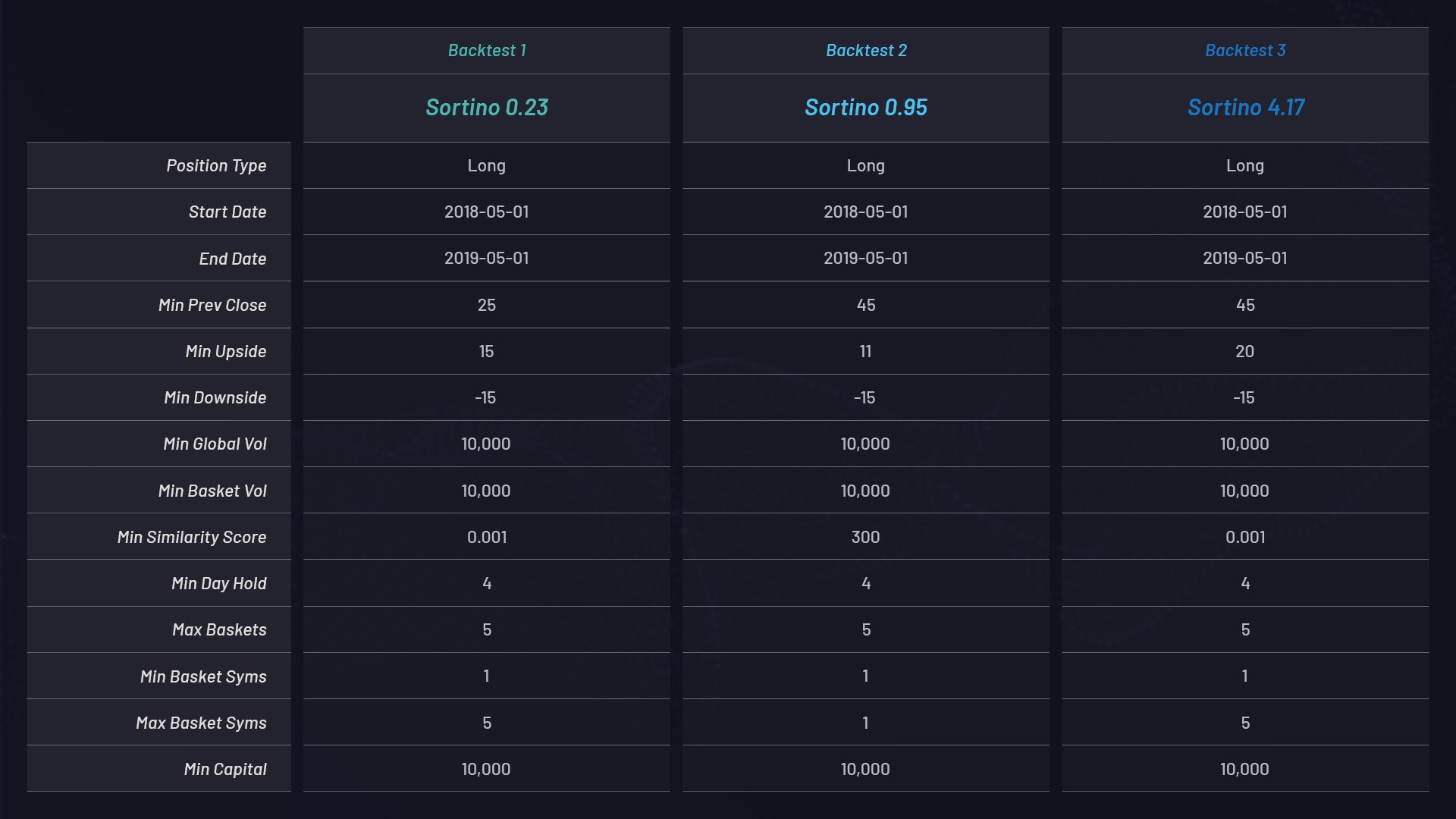
A continuación hay tres pruebas de comprobación diferentes que usan canastas a largo plazo con distintas configuraciones de parámetros. Cada una tiene una asignación de capital de USD 10 000 y está clasificada por su proporción de Sortino:
Configuraciones de parámetros de cada canasta:
A continuación, los resultados de las pruebas de comprobación se cargan en Kibana y se muestran las estadísticas:
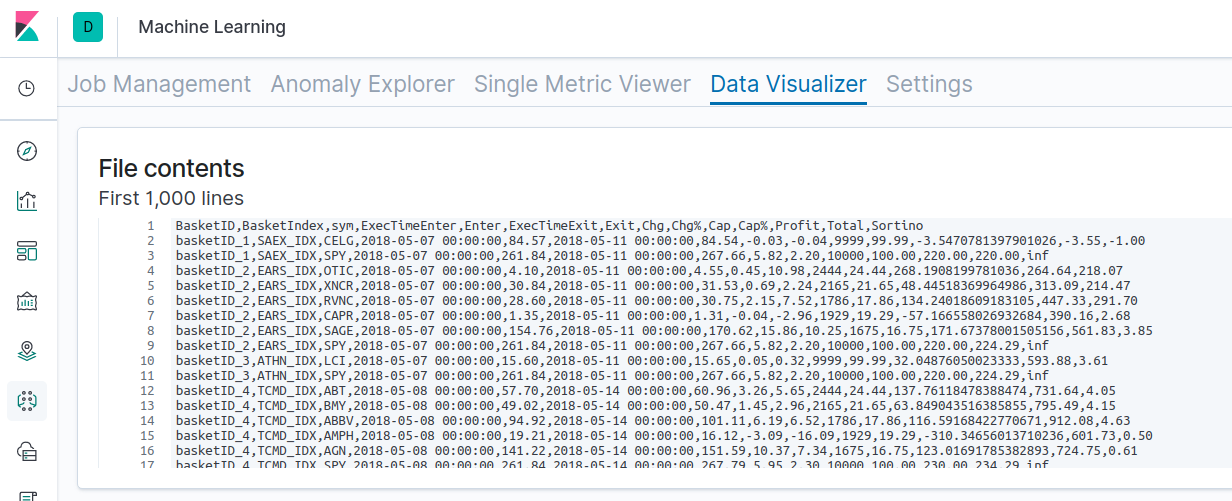
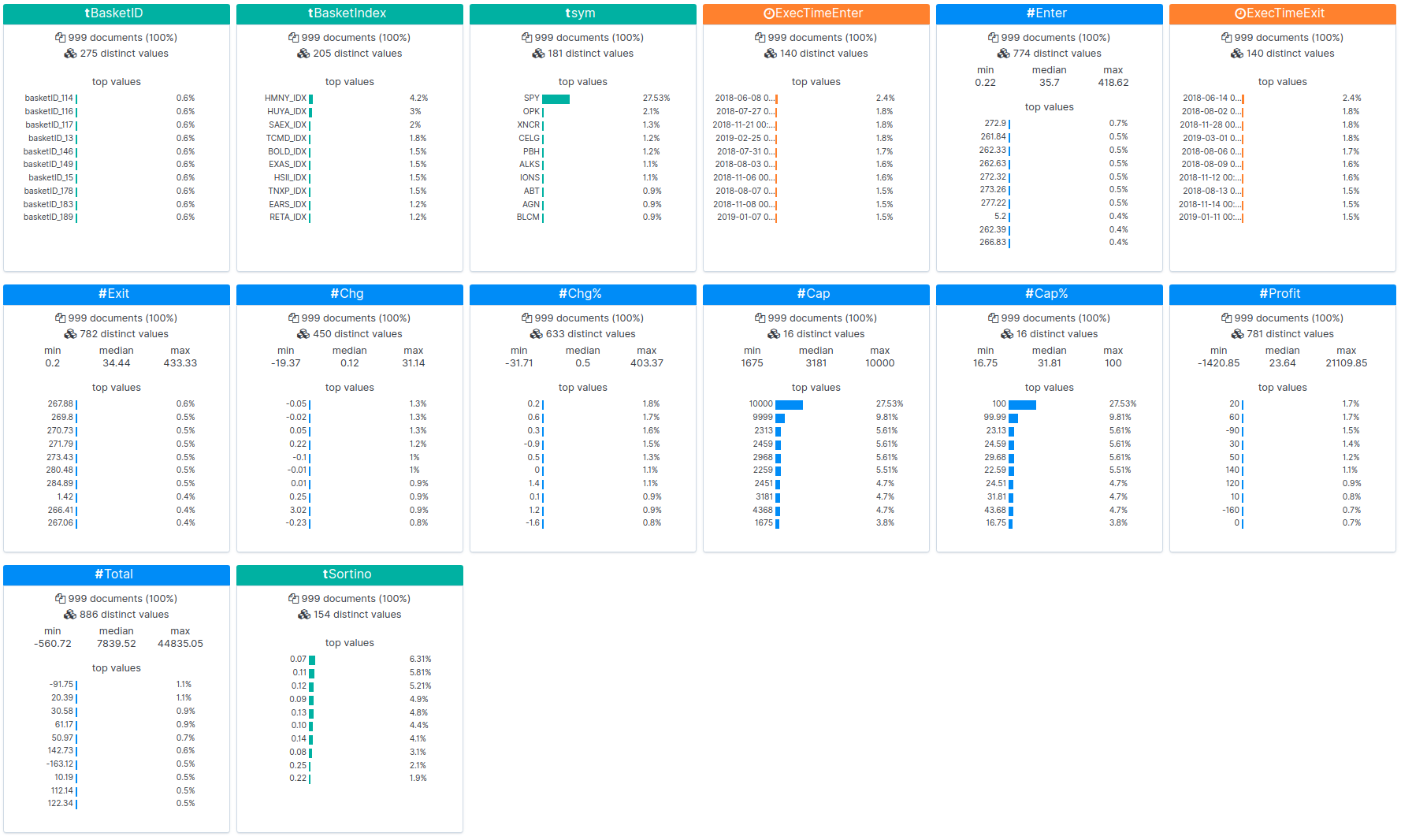
Puedes ver los resultados sin procesar de una de las pruebas de comprobación aquí. La prueba de comprobación de sets de datos de NLU incrementados puede realizarse usando los pasos siguientes. Usamos estos pasos para generar los resultados anteriores.
- La incrustación de palabras como vectores de características se genera para todas las acciones de la NYSE y Nasdaq con la API del set de datos.
- Un período histórico de un año de datos de precios desde el 1 de mayo de 2018 hasta el 1 de mayo de 2019 de todas las acciones de la NYSE y Nasdaq se usa para el análisis en busca de desencadenadores de eventos especiales definidos por un pico en el precio de las acciones.
- En el caso de acciones con un pico que supere el umbral de porcentaje elegido, por ejemplo, +15 %, se genera un cluster o una canasta de acciones relacionadas usando el set de datos. Ve el parámetro MIN_UPSIDE en la tabla anterior.
- La filtración de parámetros como volumen, capitalización en el mercado, emisión, etc. se usa entonces para refinar la canasta.
- Las horas de entrada y salida de negociación en la bolsa se configuran en esperas de cuatro días.
- Los retornos se calculan para canastas a largo y corto plazo con el S&P 500 como comparación de partida además de las proporciones de Sortino.
- Los sets de datos y resultados se monitorean, visualizan e interpretan a través de Canvas.
Resultados de la prueba de comprobación
Echemos un vistazo a los resultados generales de tres pruebas de comprobación de un año con Canvas, desde el 1 de mayo de 2018 al 1 de mayo de 2019, sobre la base del rendimiento de todas las canastas generadas durante este período.
Las pruebas de comprobación permitieron la detección de empresas que cotizan en la bolsa con precios de acciones que aumentaron su valor luego de la adquisición de Celgene. Se carga un set de datos incrementado en el que pueden observarse las correlaciones. Las canastas (clusters) generadas a partir del set de datos también se puede ver según su rendimiento. Se puede comparar una canasta con el rendimiento de partida del S&P 500 para asegurarte de que al menos le estés ganando al mercado. Las canastas individuales se monitorean para determinar si superan el S&P 500 (SPY):
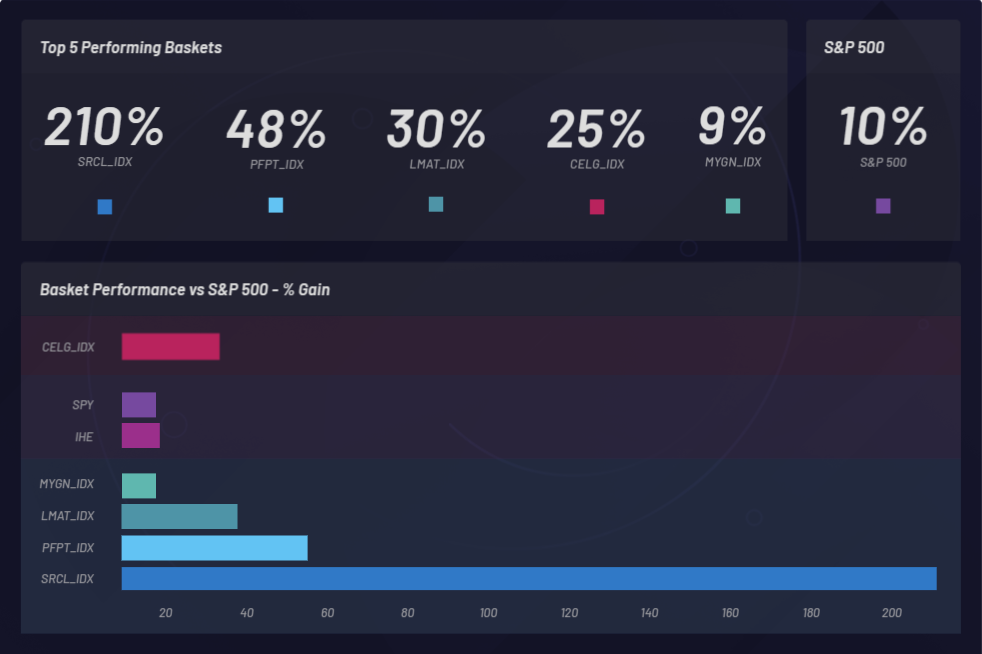
En el gráfico siguiente se muestra el monitoreo de un evento y los movimientos solidarios latentes resultantes en otras acciones. En este caso, CELG (Celgene) fue el evento y EPZM (Epizyme) se eligió como componente de la canasta resultante. Las correlaciones basadas en NLU pueden predecir correlaciones basadas en precios. La captura de correlaciones basadas en NLU que se actualizan entre valores y eventos puede proporcionar una ventaja basada en el arbitraje de información asimétrica. Poder posicionarse al frente del mercado solo es posible si hay una respuesta retrasada en la acción del precio o la correlación del precio a diferencia de cualquier correlación basada en NLU entre CELG y EPZM, que se puede observar aquí:
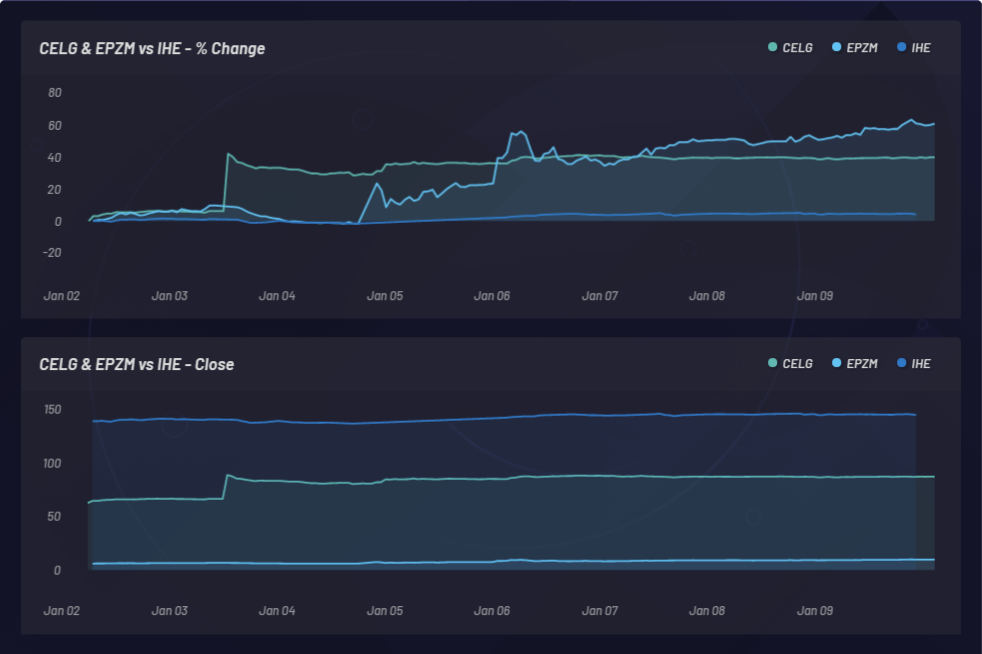
CELG (Celgene) vs comparación con AGIO (Agios Pharmaceuticals):
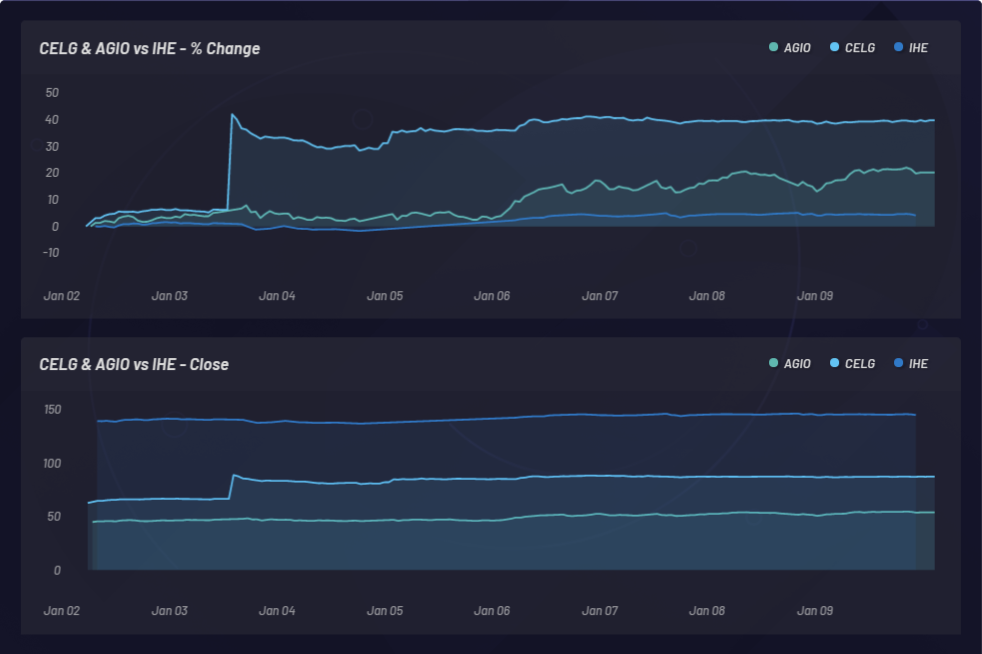
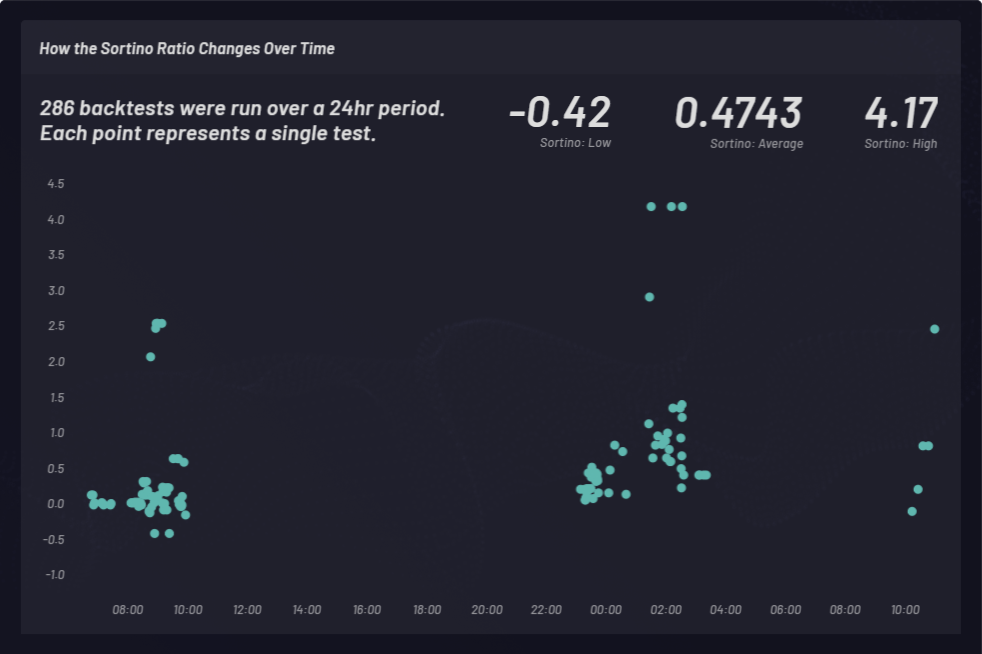
Se calcula una proporción de Sortino para medir los retornos ajustados según el riesgo. En el ejemplo siguiente, la proporción de Sortino se eligió por sobre la de Sharpe para tener un poco mejor en cuenta la volatilidad en alza. La proporción de Sortino cambia con el tiempo. Se realizaron pruebas de comprobación con canastas a largo plazo en tres momentos diferentes durante un período de 24 meses como se muestra a continuación. Se realizó un total de 286 pruebas de comprobación con configuraciones de parámetros globales diferentes. Cada punto en el cluster siguiente representa una sola prueba de comprobación con su proporción de Sortino correspondiente en el eje y:
Aprovechamiento de correlaciones cambiantes
La Biblioteca Nacional de Medicina publica alrededor de 1500 publicaciones científicas revisadas por colegas cada 24 horas. Vectorspace usa la NLM como una de sus fuentes de datos.

Las correlaciones entre genes, compuestos de fármacos, noticias farmacéuticas y empresas que cotizan en la bolsa cambian con el tiempo, a veces en cuestión de segundos. Esto puede afectar las proporciones de señal a ruido al descubrir compuestos que son candidatos para la readaptación y el reposicionamiento de un fármaco.
Si hay cambios en los valores de correlación entre una empresa farmacéutica que cotiza en la bolsa y un gen, una proteína, un compuesto de fármaco, un microbio o una enfermedad, estas relaciones nuevas se verán reflejadas en el set de datos y pueden monitorearse casi en tiempo real con Canvas.

El uso de control del contexto en la creación de sets de datos basados en NLU puede resultar en nuevos tipos de puntuación de correlación. Controlar el contexto de las relaciones de NLU puede ser fundamental para obtener información nueva.
Con el agregado de control del contexto, los sets de datos basados en NLU pueden asistir a los investigadores para responder preguntas como “¿qué acciones farmacéuticas están correlacionadas con estos compuestos de fármacos en el contexto de genes de reparación de daño al ADN según la investigación más reciente?” y ofrecer formas poderosas de visualizar e interpretar las respuestas o resultados en Canvas.
Como se publican aproximadamente 1500 publicaciones científicas nuevas revisadas por colegas cada 24 horas además de noticias y otras presentaciones públicas, ocurren cambios en las puntuaciones de correlación, que a su vez definen relaciones actualizadas entre, por ejemplo, empresas farmacéuticas que cotizan en la bolsa y compuestos de fármacos. En combinación con fuentes de datos internas, los sets de datos basados en NLU pueden proporcionar señales únicas.
Conclusión
Las correlaciones basadas en el procesamiento del lenguaje natural (NLP) y NLU pueden habilitar trayectorias para generar conocimientos, hipótesis o descubrimientos nuevos.
Hay muchas más cosas que se pueden hacer con sets de datos de NLU en las ciencias biológicas y los mercados financieros relacionadas con correlaciones contextualizadas, fuentes de datos alternativas, vectores de características, visualización e interpretación. Quizás en un futuro nuestros equipos debatan algunos de estos temas como el incremento de sets de datos temporales para una variedad de activos negociables. Con vectores de características de NLU individuales, nuestros equipos pueden explicar cómo crear redes de relaciones basadas en grafos o redes completas de clusters representadas con Canvas y otras herramientas en el Elastic Stack. Además, nuestros equipos pueden describir maneras de obtener máquinas para negociar vectores de características entre sí con el objetivo de minimizar las funciones de pérdida seleccionadas según una API de token de la utilidad con un libro de pedidos de mercado abierto.
Vectorspace continúa creando aplicaciones relacionadas para sets de datos en el análisis de la reparación de daño cromosómico relacionado con la radiación LET (radiación espacial), la epigenética y el tiempo de vida relacionado con los vuelos espaciales con humanos. Todo esto se vuelve más creativo y útil con el Elastic Stack, incluidos Canvas y otras herramientas. Si quieres saber más sobre los incrementos de sets de datos o cómo obtener créditos gratis de API de token de la utilidad, comunícate con Vectorspace y nos complacerá proporcionarte los datos necesarios para comenzar.
Y si quieres probar el Elastic Stack, aprovecha una prueba gratis de 14 días de Elasticsearch Service o descárgala como parte de la distribución predeterminada.
Vectorspace inventa sistemas y sets de datos que imitan la cognición humana con el objetivo de arbitrar información y hacer descubrimientos científicos (AI/NLP/ML de alto nivel) para Genentech, Laboratorio Nacional Lawrence Berkeley, el Departamento de Energía de los EE. UU. (DOE), el Departamento de Defensa (DOD), la división de biociencia espacial de la NASA, DARPA y SPAWAR (división de Sistemas de guerra espacial y naval de la Marina de Guerra de EE. UU.) entre otros.
Shaun McGough es gerente de productos en Elastic, con experiencia en el dominio de visualización de datos e inversiones alternativas.