Cinco componentes técnicos de la búsqueda por similitud de imágenes

 Share on Twitter
Share on TwitterComparte en Twitter

 Share on LinkedIn
Share on LinkedInComparte en LinkedIn

 Share on Facebook
Share on FacebookComparte en Facebook

 Share by Email
Share by EmailComparte por correo electrónico

 Print this page
Print this pageImprime
En la primera parte de esta serie de publicaciones de blog, presentamos la búsqueda por similitud de imágenes y revisamos una arquitectura de alto nivel que puede reducir la complejidad y facilitar la implementación. En este blog se explican los conceptos subyacentes y las consideraciones técnicas de cada componente necesario para implementar una aplicación de búsqueda por similitud de imágenes. Conoce más sobre lo siguiente:
- Modelos de incrustación: Modelos de machine learning que generan la representación numérica de tus datos necesaria para aplicar la búsqueda vectorial
- Endpoint de inferencia: API para aplicar los modelos de incrustación a tus datos en Elastic
- Búsqueda de vectores: Cómo funciona la búsqueda por similitud con la búsqueda del vecino más cercano
- Generación de incrustaciones de imágenes: Escalar la generación de representaciones numéricas a grandes conjuntos de datos
- Lógica de las aplicaciones: Cómo se comunica el frontend interactivo con el motor de búsqueda de vectores en el back-end
Profundizar en estos cinco componentes te brinda un plan de cómo puedes implementar experiencias de búsqueda más intuitivas aplicando la búsqueda de vectores en Elastic.
1. Modelos de incrustación
Para aplicar la búsqueda por similitud al lenguaje natural o datos de imágenes, necesitas modelos de machine learning que traduzcan tus datos a su representación numérica, también conocida como incrustaciones de vectores. En este ejemplo:
- El modelo “transformador” de NLP traduce el lenguaje natural a un vector.
- El modelo CLIP (Contrastive Language-Image Pre-training) de OpenAI vectoriza imágenes.
Los modelos de transformadores son modelos de machine learning entrenados para procesar datos de lenguaje natural de varias maneras, como traducción de idiomas, clasificación de texto o reconocimiento de entidades nombradas. Están entrenados en conjuntos de datos extremadamente grandes de datos de texto anotados para aprender los patrones y estructuras del lenguaje humano.
La aplicación de similitud de imágenes encuentra imágenes que coinciden con descripciones textuales dadas en lenguaje natural. Para implementar ese tipo de búsqueda por similitud, necesitas un modelo que haya sido entrenado tanto en texto como en imágenes y que pueda traducir la búsqueda de texto en un vector. Esto se puede usar para encontrar imágenes similares.
Obtén más información sobre cómo cargar y usar el modelo NLP en Elasticsearch >>
CLIP es un modelo de lenguaje a gran escala desarrollado por OpenAI que puede manejar tanto texto como imágenes. El modelo está entrenado para predecir la representación textual de una imagen, dado un pequeño fragmento de texto como entrada. Esto implica aprender a alinear las representaciones visuales y textuales de una imagen de manera que permita al modelo hacer predicciones precisas.
Otro aspecto importante de CLIP es que es un modelo de "disparo cero", lo que le permite realizar tareas para las que no ha sido entrenado específicamente. Por ejemplo, puede traducir entre idiomas que no ha visto durante el entrenamiento o clasificar imágenes en categorías que no ha visto antes. Esto convierte a CLIP en un modelo muy flexible y versátil.
Usarás el modelo CLIP para vectorizar tus imágenes, usando el endpoint de inferencia en Elastic, como se describe a continuación, y ejecutando la inferencia en un gran conjunto de imágenes, como se describe en la sección 3 más adelante.
2. El endpoint de inferencia
POST _ml/trained_models/sentence-transformers__clip-vit-b-32-multilingual-v1/deployment/_infer
{
"docs" : [
{"text_field": "A mountain covered in snow"}
]
}3. Búsqueda por (similitud de) vectores
Después de indexar consultas y documentos con incrustaciones de vectores, los documentos similares son los vecinos más cercanos de tu búsqueda en el espacio de incrustaciones. Un algoritmo popular para lograrlo es k-vecino más cercano (kNN), que encuentra los k-vectores más cercanos a un vector de búsqueda. Sin embargo, en los grandes conjuntos de datos que normalmente procesarías en las aplicaciones de búsqueda de imágenes, kNN requiere recursos computacionales muy altos y puede generar tiempos de ejecución excesivos. Como solución, la búsqueda del vecino más cercano aproximado (ANN) sacrifica la precisión perfecta a cambio de una ejecución eficiente en espacios de incrustación de alta dimensión, a escala.
En Elastic, el endpoint _search admite búsquedas de vecinos más cercanos exactas y aproximadas. Utiliza el siguiente código para la búsqueda de kNN. Asume que las incrustaciones de todas las imágenes en your-image-index están disponibles en el campo image_embedding. En la siguiente sección se explica cómo puedes crear las incrustaciones.
# Run kNN search against <query-embedding> obtained above
POST <your-image-index>/_search
{
"fields": [...],
"knn": {
"field": "image_embedding",
"k": 5,
"num_candidates": 10,
"query_vector": <query-embedding>
}
}Para obtener más información sobre kNN en Elastic, consulta nuestra documentación: https://www.elastic.co/guide/en/elasticsearch/reference/current/knn-search.html.
4. Generación de incrustaciones de imágenes
Las incrustaciones de imágenes mencionadas anteriormente son fundamentales para un buen rendimiento de tu búsqueda por similitud de imágenes. Deben almacenarse en un índice separado que contenga las incrustaciones de imágenes, el cual se denomina you-image-index en el código anterior. El índice consta de un documento por imagen junto con campos para el contexto y la interpretación del vector denso (incrustación de imágenes) de la imagen. Las incrustaciones de imágenes representan una imagen en un espacio de menor dimensión. Las imágenes similares se mapean a puntos cercanos en este espacio. La imagen sin procesar puede tener varios MB de tamaño, dependiendo de su resolución.
Los detalles específicos de cómo se generan estas incorporaciones pueden variar. En general, este proceso implica extraer características de las imágenes y luego mapearlas en un espacio de menor dimensión utilizando una función matemática. Esta función generalmente se entrena en un gran conjunto de datos de imágenes para aprender la mejor manera de representar las características en el espacio de menor dimensión. La generación de incrustaciones es una tarea de una sola vez.
En este blog, emplearemos el modelo CLIP para este propósito. Es distribuido por OpenAI y proporciona un buen punto de partida. Es posible que deba entrenar un modelo de incrustación personalizado para casos de uso especializados para lograr el rendimiento deseado, según qué tan bien se representen los tipos de imágenes que desea clasificar en los datos disponibles públicamente que se usan para entrenar el modelo CLIP.
La generación de incrustaciones en Elastic debe ocurrir en el momento de la ingesta y, por lo tanto, en un proceso externo a la búsqueda, con los siguientes pasos:
- Cargar el modelo CLIP.
- Para cada imagen:
- Cargar la imagen.
- Evaluar la imagen usando el modelo.
- Guardar las incrustaciones generadas en un documento.
- Guardar el documento en el almacén de datos/Elasticsearch.
El pseudocódigo hace que estos pasos sean más concretos y puedes acceder al código completo en el repositorio de ejemplos.
...
img_model = SentenceTransformer('clip-ViT-B-32')
...
for filename in glob.glob(PATH_TO_IMAGES, recursive=True):
doc = {}
image = Image.open(filename)
embedding = img_model.encode(image)
doc['image_name'] = os.path.basename(filename)
doc['image_embedding'] = embedding.tolist()
lst.append(doc)
...O consulta la figura a continuación como una ilustración:
El documento después del procesamiento podría tener el siguiente aspecto. La parte crítica es el campo "image_embedding" donde se almacena la representación vectorial densa.
{
"_index": "my-image-embeddings",
"_id": "_g9ACIUBMEjlQge4tztV",
"_score": 6.703597,
"_source": {
"image_id": "IMG_4032",
"image_name": "IMG_4032.jpeg",
"image_embedding": [
-0.3415695130825043,
0.1906963288784027,
.....
-0.10289803147315979,
-0.15871885418891907
],
"relative_path": "phone/IMG_4032.jpeg"
}
}5. La lógica de las aplicaciones
Sobre la base de estos componentes básicos, finalmente puedes juntar todas las piezas y trabajar a través de la lógica para implementar una búsqueda interactiva por similitud de imágenes. Comencemos conceptualmente, con lo que debe suceder cuando deseas recuperar de forma interactiva imágenes que coincidan con una descripción dada.
Para consultas textuales, la entrada puede ser tan simple como una sola palabra como rosas o una descripción más extensa como "una montaña cubierta de nieve". O también puedes proporcionar una imagen y solicitar imágenes similares a la que tienes.
Aunque estás utilizando diferentes modalidades para formular tu búsqueda, ambas se ejecutan utilizando la misma secuencia de pasos en la búsqueda de vectores subyacente, es decir, utilizando una búsqueda (kNN) sobre documentos representados por sus incrustaciones (como vectores "densos"). Hemos descrito los mecanismos en secciones anteriores que permiten a Elasticsearch ejecutar búsquedas vectoriales muy rápidas y escalables necesarias en grandes conjuntos de datos de imágenes. Consulta esta documentación para obtener más información sobre cómo ajustar la búsqueda de kNN en Elastic para lograr eficiencia.
- Entonces, ¿cómo se puede implementar la lógica descrita anteriormente? En el siguiente diagrama de flujo puedes ver cómo fluye la información: El modelo de incrustación vectoriza la búsqueda emitida por el usuario, como texto o imagen, según el tipo de entrada: un modelo NLP para descripciones de texto, y el modelo CLIP para imágenes.
- Ambos convierten la búsqueda de entrada en su representación numérica y almacenan el resultado en un tipo de vector denso en Elasticsearch ([número, número, número...]).
- La representación vectorial se usa luego en una búsqueda kNN para encontrar vectores similares (imágenes), que se devuelven como resultado.
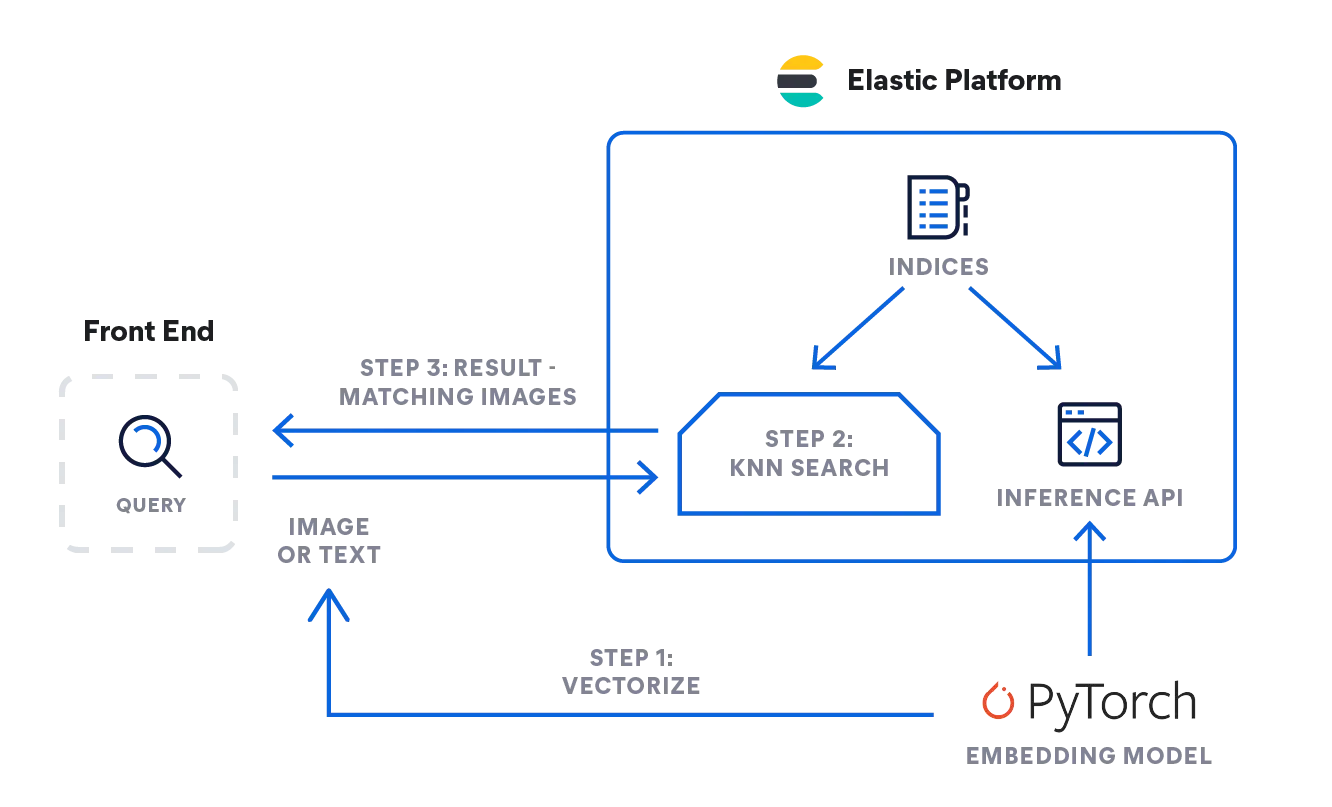
Inferencia: Vectorizar las búsquedas de los usuarios
La aplicación en segundo plano enviará una solicitud a la API de inferencia en Elasticsearch. Para la entrada de texto, es algo como esto:
POST _ml/trained_models/sentence-transformers__clip-vit-b-32-multilingual-v1/deployment/_infer
{
"docs" : [
{"text_field": "A mountain covered in snow"}
]
}Para las imágenes, puedes usar el código simplificado a continuación para procesar una sola imagen con el modelo CLIP, que necesitaba cargar en tu nodo de machine learning de Elastic con anticipación:
model = SentenceTransformer('clip-ViT-B-32')
image = Image.open(file_path)
embedding = model.encode(image)Obtendrás una matriz de 512 valores de Float32, como esta:
{
"predicted_value" : [
-0.26385045051574707,
0.14752596616744995,
0.4033305048942566,
0.22902603447437286,
-0.15598160028457642,
...
]
}Búsqueda: De imágenes similares
La búsqueda funciona igual para ambos tipos de entrada. Envía la búsqueda con la definición de búsqueda kNN contra el índice con incrustaciones de imágenes my-image-embeddings. Pon el vector denso de la búsqueda anterior ("query_vector": [ ... ]) y ejecuta la búsqueda.
GET my-image-embeddings/_search
{
"knn": {
"field": "image_embedding",
"k": 5,
"num_candidates": 10,
"query_vector": [
-0.19898493587970734,
0.1074572503566742,
-0.05087625980377197,
...
0.08200495690107346,
-0.07852292060852051
]
},
"fields": [
"image_id", "image_name", "relative_path"
],
"_source": false
}La respuesta de Elasticsearch te brindará las mejores imágenes coincidentes según nuestra búsqueda de búsqueda kNN, almacenada en Elastic como documentos.
El siguiente gráfico de flujo resume los pasos por los que pasa tu aplicación interactiva mientras procesa una búsqueda de usuario:
- Carga la aplicación interactiva, su frontend.
- El usuario selecciona una imagen que le interesa.
- Tu aplicación vectoriza la imagen aplicando el modelo CLIP, almacenando la incrustación resultante como un vector denso.
- La aplicación inicia una búsqueda kNN en Elasticsearch, que toma la incrustación y devuelve sus vecinos más cercanos.
- Tu aplicación procesa la respuesta y muestra una (o más) imágenes coincidentes.
Ahora que comprendes los componentes principales y el flujo de información necesarios para implementar una búsqueda interactiva por similitud de imágenes, puedes recorrer la parte final de la serie para aprender cómo hacerlo realidad. Obtendrás una guía paso a paso sobre cómo configurar el entorno de la aplicación, importar el modelo NLP y finalmente completar la generación de incrustación de imágenes. Luego podrás buscar imágenes con lenguaje natural, sin necesidad de palabras clave.
Comienza a configurar la búsqueda por similitud de imágenes >>
Comparte
- Share on Twitter
Comparte en Twitter
- Share on LinkedIn
Comparte en LinkedIn
- Share on Facebook
Comparte en Facebook
- Share by Email
Comparte por correo electrónico
- Print this page
Imprime