Was ist hybride Suche?
Zwei oder mehr Abrufmethoden. Eine Rangliste.
Hybridsuche ist eine Technik zur Informationswiedergewinnung, die zwei oder mehr Suchmethoden (z. B. lexikalische Suche und semantische Suche) in einer einzigen Rangliste kombiniert, um Relevanz und Trefferquote zu verbessern. Die gängigste Kombination ist die lexikalische Volltextsuche, die sich hervorragend zum Auffinden exakter Wörter und Phrasen eignet, mit der semantischen Vektorsuche, die die Bedeutung hinter einer Suchanfrage interpretiert. Die lexikalische Suche sorgt für Präzision, während die semantische Suche ein tieferes Verständnis der Nutzerintention ermöglicht.
Diese Methoden werden in einer einzigen Abfrage zusammen ausgeführt, und ihre Ergebnisse werden anschließend mithilfe spezieller Fusionsstrategien zu einer einheitlichen Rangliste zusammengeführt. Die Kombination aus lexikalischer und semantischer Suche ist zwar am weitesten verbreitet, aber die Hybridsuche kann auch andere Ansätze – wie die Suche nach Geodaten und semantischen Daten oder sogar die Suche nach Text und Bildern – integrieren, um unterschiedlichen Anforderungen gerecht zu werden.
Warum die hybride Suche so wichtig ist
Hybride Suche mindert die Schwächen einzelner Abrufmethoden und nutzt deren Stärken in einer einzigen Pipeline. Moderne KI muss verschiedene Modalitäten, Text, Bilder, Audio, Logs und mehr verarbeiten und die Absicht mit Daten verknüpfen. Relevanz wird wichtiger denn je. Im E-Commerce kann beispielsweise eine Suchfunktion dann erfolgreich sein, wenn sie den Nutzern hilft, Ergebnisse schnell zu filtern und zu verfeinern. Ein KI-Agent benötigt jedoch oft eine einzige, hochrelevante Antwort, um auf eine Frage zu reagieren oder eine Aktion auszuführen. Deshalb ist die Fähigkeit, Abruftechniken zu kombinieren und zu optimieren, heute so wichtig und ermöglicht nicht nur traditionelle Suchergebnisse, sondern auch dialogbasierte Systeme, die präzise, datengestützte Antworten liefern.
Bevor wir weiter in die Hybridsuche eintauchen, werfen wir einen kurzen Blick darauf, wie sich die lexikalische und die semantische Suche unterscheiden und warum sie sich gegenseitig ergänzen.
Lexikalische Suche erklärt
Die lexikalische Suche ist ideal, wenn Sie gut strukturierte Daten haben und die Nutzer wissen, wonach sie suchen. Sie gleicht genaue Begriffe ab, was sie sehr präzise und erklärbar macht, und stützt sich auf einen Relevanzscoring-Algorithmus (wie BM25F), der Dokumente nach Häufigkeit und Seltenheit von Abfragebegriffen bewertet. Dieser Ansatz bietet eine transparente Bewertung und unterstützt eine fein abgestimmte Relevanz durch Feld-Boosts, Synonyme und Analysatoren. Da es keinen Modellaufwand gibt, ist die lexikalische Suche schnell und effizient, mit Filtern und Facetten, die auch bei Skalierung zuverlässig funktionieren, ohne Verlangsamungen oder vollständige Index-Scans. Sie ist besonders effektiv für strukturierte Abfragen, seltene Begriffe und domänenspezifische Sprache.
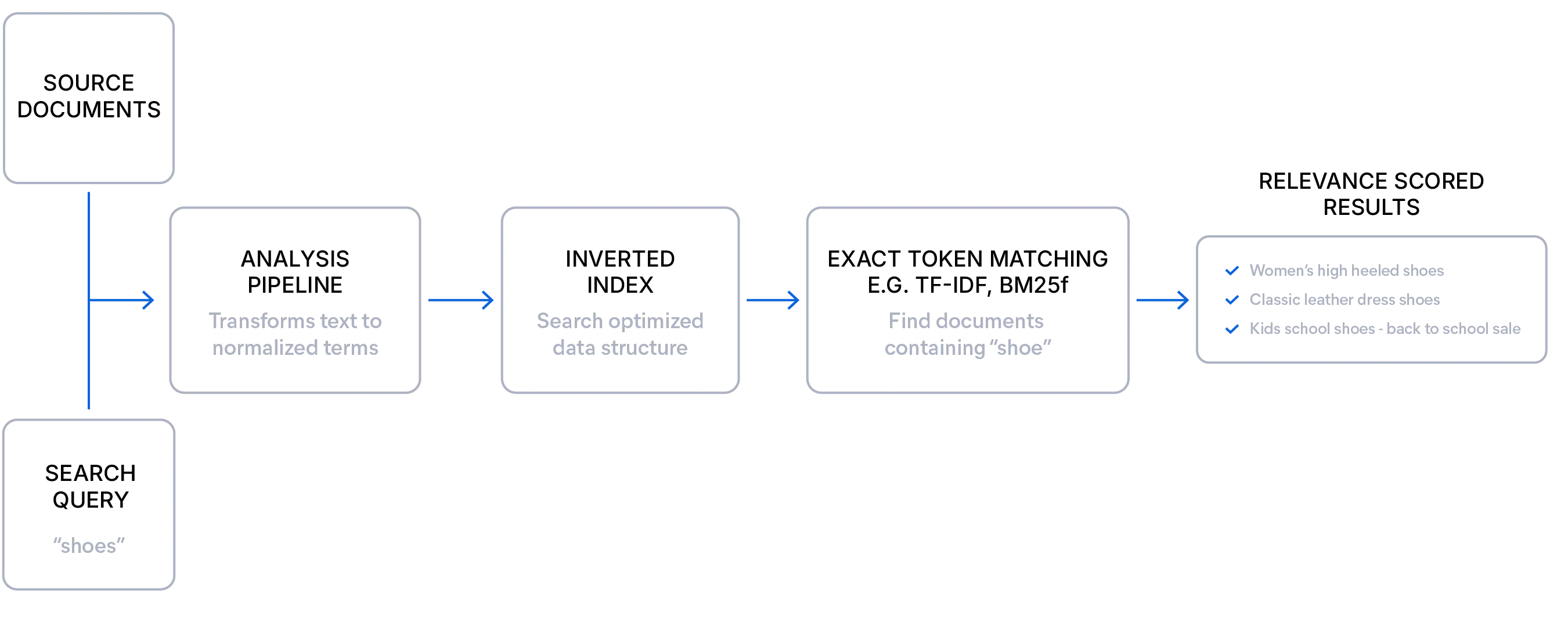
Hier ist ein einfaches Beispiel für eine lexikalische Suchanfrage:
GET example-index/_search
{
"query": {
"term": {
"text": "blue shoes"
}
}
}
Schauen wir uns auch ein ähnliches lexikalisches Suchbeispiel mit der Elasticsearch-Abfragesprache (ES|QL) für einen Kochblog an. Der Blog enthält Rezepte mit verschiedenen Attributen, darunter Textinhalte, kategoriale Daten und numerische Bewertungen.
FROM cooking_blog METADATA _score | WHERE description:"fluffy pancakes" | KEEP title, description, _score | SORT _score DESC | LIMIT 1000
Diese Abfrage sucht im Beschreibungsfeld nach Dokumenten, die entweder „fluffy“ ODER „pancakes“ (oder beides) enthalten. Standardmäßig verwendet ES|QL die ODER-Logik zwischen Suchbegriffen, sodass Dokumente gefunden werden, die eines der angegebenen Wörter enthalten. Sie können genau angeben, welche Felder Sie in Ihre Ergebnisse aufnehmen sollen, mit dem Befehl BEHALTEN und die _score-Metadaten anfordern, um die Suchergebnisse nach der Übereinstimmung mit Ihrer Anfrage zu bewerten.
Erfahren Sie mehr über die lexikalische Suche mit diesem praktischen Tutorial.
Semantische Suche erklärt
Die semantische Suche liefert Ergebnisse basierend auf der Bedeutungsähnlichkeit zwischen einer Anfrage und Dokumenten, anstatt wie bei der lexikalischen Suche nur exakte Begriffe abzugleichen.
Ein Embedding-Modell wandelt die Bedeutung Ihres Textes oder anderer Medien in eine numerische Darstellung um, die als Vektor bezeichnet wird. Diese Vektoren – eine Liste von Zahlen – erfassen den zugrunde liegenden Kontext und das Thema des Textes und werden in einer Vektordatenbank wie Elasticsearch gespeichert.
Dadurch kann die Suchmaschine konzeptionell ähnliche Ergebnisse finden, selbst wenn diese keine exakten Wörter mit der Suchanfrage gemeinsam haben.
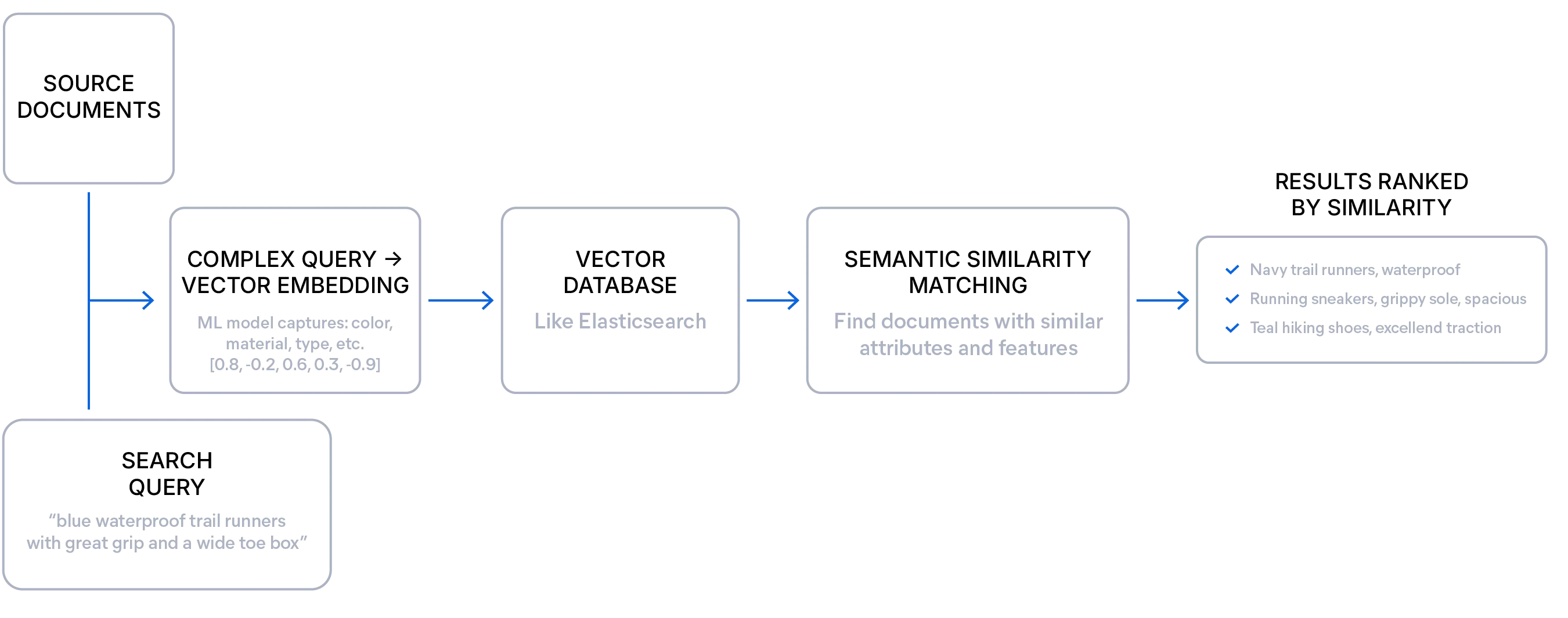
Dieser Ansatz ist besonders nützlich für unstrukturierte Daten, explorative Abfragen und Fälle, in denen die Nutzer die genauen Begriffe nicht kennen. Entwickler können die semantische Suche nutzen, um relevantere Ergebnisse zu liefern und mit vagen, wortreichen oder mehrdeutigen Formulierungen umzugehen, während sie dennoch die richtigen Antworten finden.
Unten finden Sie ein Beispiel für eine semantische Suchabfrage:
GET example-index/_search
{
"query": {
"semantic": {
"field": "inference_field",
"query": "blue waterproof trail runners with great grip and a wide toe box"
}
}
}
ES|QL unterstützt die semantische Suche, wenn Ihre Mappings Felder des Typs semantic_text enthalten. Sobald das Dokument vom zugrunde liegenden Modell verarbeitet wurde, das auf dem Inferenz-Endpoint läuft, können Sie die semantische Suche durchführen. Hier ist ein Beispiel für eine natürliche Sprachabfrage im Feld semantic_description:
FROM cooking_blog METADATA _score | WHERE semantic_description:"What are some easy to prepare but nutritious plant-based meals?" | SORT _score DESC | LIMIT 5
Erfahren Sie mehr über die semantische Suche oder probieren Sie dieses praxisorientierte Tutorial aus, um tiefer einzutauchen.
Lexikalische Algorithmen wie BM25F sind besonders präzise, wenn Anfragebegriffe mit Dokumentbegriffen übereinstimmen, scheitern jedoch, wenn relevante Inhalte anders formuliert werden. (Beispielsweise könnten bei einer Suchanfrage nach „Sportschuhen“ Dokumente übersehen werden, die nur „Schuhe“ oder „Trailrunning-Schuhe“ enthalten.) Die semantische Vektorsuche, die hochdimensionale Einbettungen und Algorithmen für ungefähre nächste Nachbarn (ANN) (z. B. HNSW) verwendet, ruft konzeptionell ähnliche Dokumente unabhängig von exakten Begriffsüberschneidungen ab – kann jedoch Rauschen verursachen, wenn der Kontext mehrdeutig ist.
Wie funktioniert die Hybridsuche?
Was wäre, wenn Sie das Beste aus beiden Welten bekommen könnten? Lernen Sie die Hybridsuche kennen. Wenn sie richtig gemacht wird, ist hybride Suche mehr als die Summe ihrer Teile; Sie kann weitaus bessere Ergebnisse liefern als allein lexikalische oder semantische Suche. Hybrid bietet beides, mit ausgewogener Relevanz, besser normalisiertem reduziertem kumulativem Gewinn (NDCG) und höherem Abruf, ohne dass ein zweites Suchsystem aufgebaut werden muss.
Unten finden Sie ein Beispiel für eine hybride Suchabfrage:
GET example-index/_search
{
"retriever": {
"rrf": {
"retrievers": [
{
"standard": {
"query": {
"term": {
"description": "shoes"
}
}
}
},
{
"knn": {
"field": "vector",
"query_vector": [1.25, 2, 3.5],
"k": 50,
"num_candidates": 100
}
}
],
"rank_constant": 20,
"rank_window_size": 50
}
}
}
Man kann auch Volltext- und semantische Abfragen in ES|QL kombinieren. In diesem Beispiel kombinieren wir Volltext- und semantische Suche mit benutzerdefinierten Gewichten:
FROM my-index METADATA _score
| FORK ( WHERE match(text_field:"shoes") | SORT _score DESC | LIMIT 50)
( WHERE knn(vector, [1.25, 2, 3.5], { "min_candidates" : 100 }) | SORT _score DESC | LIMIT 50 ) // k for knn is derived from LIMIT
| FUSE RRF WITH { "rank_constant": 20 }
| SORT _score DESC
| LIMIT 50
Die Ausführung einer hybriden Suchabfrage beinhaltet typischerweise die Durchführung mindestens einer lexikalischen Suche und einer semantischen Suche und anschließend die Kombination ihrer Ergebnisse. Die größte Herausforderung besteht darin, mehrere Ranglisten zu einem einzigen, kohärenten Ranking zusammenzufassen.
Die von Algorithmen wie BM25F oder TF-IDF generierten lexikalischen Suchwerte können unbegrenzt sein, und die Maximalwerte werden von der Termfrequenz und der Dokumentverteilung beeinflusst. Im Gegensatz dazu liegen semantische Suchwerte normalerweise in einem festen Bereich, der durch die Ähnlichkeitsfunktion bestimmt wird (z. B. [0, 2] für Kosinusähnlichkeit).
Um sie zusammenzuführen, benötigen Sie eine Fusionsmethode, die die relative Relevanz der abgerufenen Dokumente pflegt.
Hybride Suche mit Elasticsearch
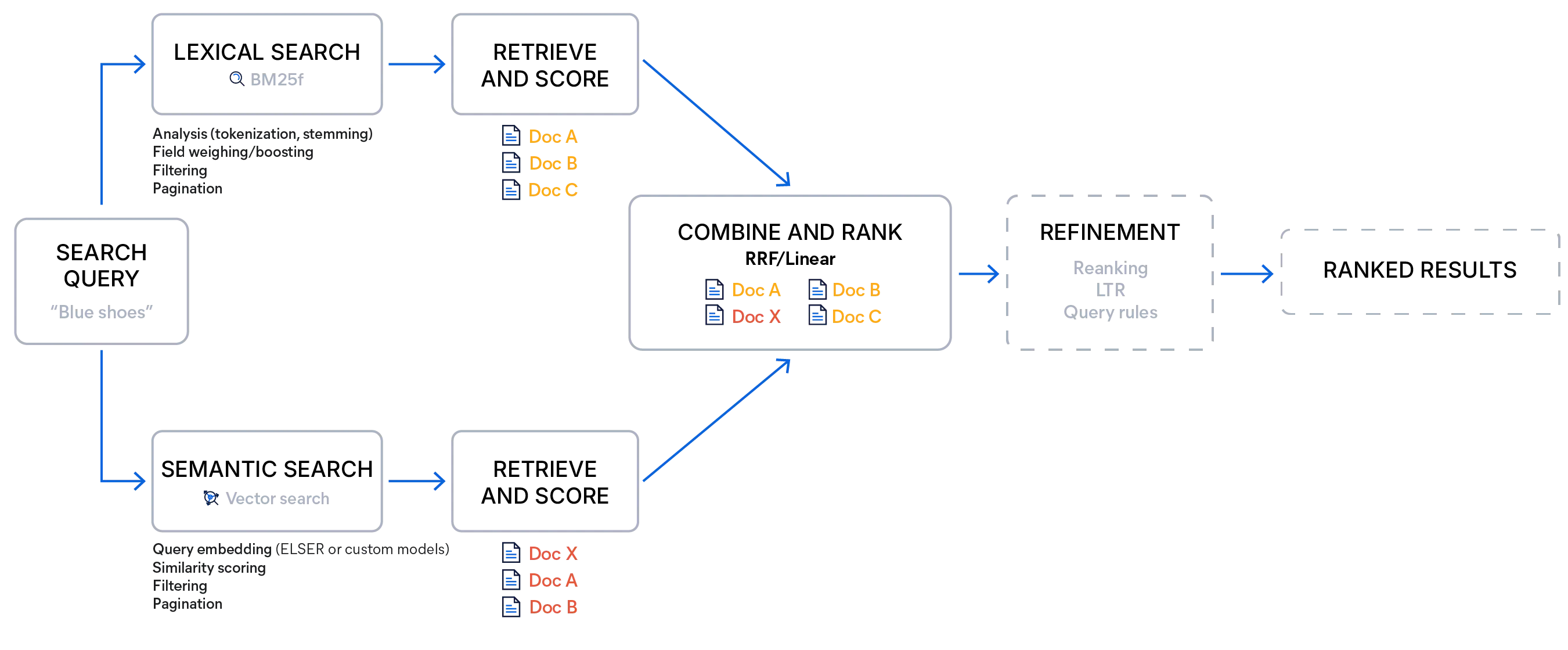
Die hybride Suche mit Elasticsearch kann durch die Kombination einer Standard-Schlüsselwortanfrage mit einer Vektoranfrage oder durch die Verwendung eines Retrievers – einer Suchoption, die mehrere Anfragen unterschiedlicher Art ausführt und deren Ergebnisse mit einer gewählten Bewertungsmethode zu einer einzigen, gerankten Liste zusammenführt – implementiert werden. Dies ermöglicht mehrstufige Retrieval-Pipelines innerhalb eines einzigen Suchaufrufs, wodurch die Notwendigkeit mehrerer Anfragen oder zusätzlicher clientseitiger Logik zur Kombination der Ergebnisse entfällt.
Elasticsearch bietet zwei integrierte Fusionsmethoden: die reziproke Rangfusion (RRF ) und die lineare Kombination (in den APIs oft als linearer Retriever bezeichnet). Beide zielen darauf ab, eine einheitliche Rangliste zu erstellen, die die Stärken der einzelnen Retriever bewahrt, aber sie unterscheiden sich darin, wie sie die Ergebnisse behandeln und wann sie am effektivsten sind.
Die Fusion des reziproken Rangs ignoriert die Rohwerte vollständig und konzentriert sich darauf, wie hoch ein Dokument in jeder Liste erscheint. Dokumente, die an der Spitze einer Liste stehen, werden stark belohnt, und Dokumente, die in mehreren Listen auftauchen, erhalten einen additiven Boost. Die Methode ist robust, weil sie Probleme mit inkompatiblen Bewertungsbereichen umgeht, fast keine Anpassung über die Rangkonstante hinaus erfordert und auf natürliche Weise die Vielfalt der Top-Ergebnisse fördert.
RRF bewertet die Dokumente nach ihrem Rang im Ergebnisset mit der folgenden Formel. Dabei ist k eine beliebige Konstante, die die Bedeutung niedrig eingestufter Dokumente anpassen soll:
![]()
RRF ist besonders nützlich, wenn Retriever Überschneidungen in ihren Top-Ergebnissen teilen und wenn Entwickler eine Plug-and-Play-Lösung ohne gekennzeichnete Trainingsdaten oder komplexe Kalibrierung benötigen.
Die Linearkombination hingegen führt die tatsächlichen Ergebnisse jedes Retrievers direkt zusammen. Da lexikalische und semantische Werte auf sehr unterschiedlichen Skalen operieren, erfordert die lineare Bewertung eine Normalisierung, wie z. B. eine Min-Max-Skalierung, um die Werte in einen vergleichbaren Bereich zu bringen.
Nach der Normalisierung werden die Scores mithilfe von Gewichten kombiniert, die die relative Bedeutung jedes Retrievers darstellen. Ein Gewicht größer als 1 verstärkt den Einfluss eines Retrievers, während ein Gewicht kleiner als 1 ihn verringert.
Dieser Ansatz ermöglicht eine feingranulare Kontrolle: Entwickler können BM25F betonen, wenn die Präzision von Schlüsselwörtern wichtig ist, sich auf semantische Ähnlichkeit konzentrieren, wenn Absicht und Kontext entscheidend sind, oder zusätzliche Geschäfts- oder Personalisierungssignale neben Abrufwerten integrieren. Wenn die Gewichte sorgfältig kalibriert werden, kann die lineare Kombination RRF übertreffen, indem sie genauere und vorhersehbarere Rankings liefert. Sie erfordert jedoch Experimente und ist empfindlich gegenüber datensatzspezifischen Anpassungen.
Lineare Kombination kombiniert lexikalische Suchergebnisse und semantische Suchergebnisse mit jeweiligen Gewichtungen und β (dabei ist 0 ≤α, β), sodass:
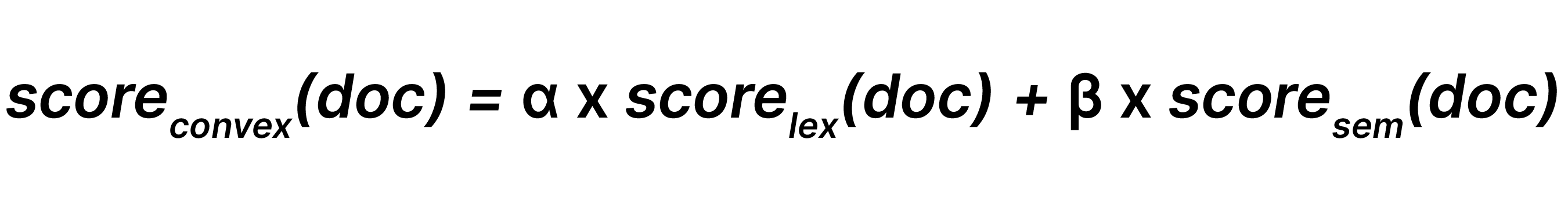
In der Praxis ist RRF der beste Ausgangspunkt für die hybride Suche, da es einfach und widerstandsfähig gegenüber nicht übereinstimmenden Bewertungsskalen ist. Es liefert starke Ergebnisse ohne umfangreiche Anpassungen und ist daher ideal für die Erstellung von Prototypen oder wenn sich Abrufalgorithmen überschneiden. Die Linearkombination eignet sich besser, wenn unterschiedliche Abrufmethoden zu unzusammenhängenden Ergebnissen führen oder wenn lexikalische, semantische und externe Signale sorgfältig gegeneinander abgewogen werden müssen. Kurz gesagt, RRF bietet eine schnelle, zuverlässige Hybridisierung von Anfang an, während lineare Methoden eine höhere potenzielle Genauigkeit bieten, sobald Gewichte und Normalisierer auf die Anwendung und die Daten abgestimmt sind.
Das Ganze im Überblick:
| Reciprocal Rank Fusion | Lineare Kombination |
|---|---|
Beginnen Sie mit RRF, um schnell robuste hybride Ergebnisse zu erzielen. |
Wechseln Sie zur linearen Darstellung, wenn Sie bereit sind, die Relevanz feinabzustimmen. |
Kurz gesagt, lineare Kombinationbietet eine höhere potenzielle Genauigkeit, wenn sie abgestimmt ist, während RRF leichter umzusetzen ist und ohne markierte Trainingsdaten gut funktioniert.
Probieren Sie dieses Tutorial aus, um mehr über hybride Suche zu erfahren.
So funktioniert die hybride Suchabfrage
- Lexikalischer Abruf: BM25F gleicht Abfragebegriffe mit indexierten Token ab – ideal für Präzision, strukturierte Filter und erklärbare Bewertung.
- Semantischer Abruf: Vektoren (dicht oder spärlich) stehen für Textbedeutung; die Ähnlichkeitssuche findet verwandte Inhalte auch ohne gemeinsame Wörter.
- Fusion: Kombinieren Sie Scores mit RRF, gewichtetem Blending oder einem linearen Retriever. Filter und Verstärkungen werden bei beiden Abrufen einheitlich angewendet.
| Suchart | So funktionierts | Was passiert | Ideal für den Fall, dass |
|---|---|---|---|
| Lexikalische Suche Anfrage: „Rote Laufschuhe Größe 10“ | Gleicht exakte Wörter in der Abfrage mit Wörtern in Dokumenten ab (BM25F, TF-IDF, Analysatoren, Synonyme). | Findet Produkte, deren Titel/Beschreibung genau diese Token enthalten (z. B. „Nike Herren-Laufschuhe Rot, Größe 10“). | Der Käufer weiß genau, was er will. Präzise, nachvollziehbar und effizient. |
| Semantische Suche Suchanfrage: „leichte Schuhe zum Joggen“ | Verwendet Embeddings, um Bedeutung und Kontext zu erfassen, nicht nur Schlüsselwörter. Findet konzeptionell verwandte Ergebnisse, auch wenn die Begriffe nicht übereinstimmen. | Gibt „Adidas Cloudfoam Laufschuhe, Größe 10“ aus, auch wenn „leicht“ und „Jogging“ nicht wörtlich erwähnt werden. | Käufer beschreiben ihre Absicht oder verwenden natürliche Sprache. Bearbeitet vage oder beschreibende Anfragen. |
| Hybridsuche Anfrage: „bequeme Business-Schuhe fürs Büro“ | Kombiniert lexikalische und semantische Ergebnisse und führt anschließend Rangfolgen durch (z. B. mittels RRF). | Findet exakte Treffer wie „Schwarze Lederschuhe, Komfortpassform“ und semantisch verwandte Artikel wie „Loafer mit gepolsterten Innensohlen“. Beide werden zusammen angezeigt, nach Relevanz geordnet. | Abfragen mischen präzise Begriffe und Absicht. Balanciert Genauigkeit mit Entdeckung. |
Details der Hybridsuche: dichte und spärliche Vektoren erklärt
Die semantische Suche mit Elasticsearch funktioniert, indem Abfragen und Dokumente in Vektordarstellungen umgewandelt werden, die die Bedeutung erfassen. Die hybride Suche kombiniert lexikale und semantische Abrufe, unabhängig davon, ob dichte oder spärliche Modelle verwendet werden.
Dicht besetzte Vektoren
Dichte Vektoren sind Zahlenreihen mit fester Länge, die von Modellen wie BERT erzeugt werden, wo ähnliche Eingänge (wie Katze und Kätzchen) im Vektorraum nahe beieinander erscheinen, was sie für semantischen Abgleich, Empfehlungen und Ähnlichkeitssuche leistungsstark macht.
Wenn Text als dichter Vektor eingebettet wird, sieht das so aus:
[ 0.13586345314979553, -0.6291824579238892, 0.32779985666275024, 0.36690405011177063, ... ]
Jede Dimension enthält aussagekräftige Informationen, wodurch die Vektoren dicht mit Daten gefüllt sind. Ähnlicher Inhalt erzeugt Embeddings, die dicht beieinander im Vektorraum liegen.
In Elasticsearch werden dichte Vektoren in einem dense_vector-Feld gespeichert und mit approximativen Nächste-Nachbar-(ANN)-Algorithmen wie HNSW abgefragt. Das ist ideal, um die gesamte semantische Bedeutung von Text, Bildern oder anderen Inhalten zu erfassen.
POST my-index/_search
{
"retriever": {
"rrf": {
"retrievers": [
{
"standard": {
"query": {
"match": {
"text_field": "fox"
}
}
}
},
{
"knn": {
"field": "title_vector",
"query_vector": [0.1, 3.2, 2.1],
"k": 5,
"num_candidates": 100
}
}
]
}
}
}
Hier ist ein ES|QL-Beispiel:
FROM my-index METADATA _score
| FORK ( WHERE match(text_field:"fox") | SORT _score DESC | LIMIT 5)
( WHERE knn(image_vector, [0.1, 3.2, 2.1], { "min_candidates" : 100 }) | SORT _score DESC | LIMIT 5 )
| FUSE
| SORT _score DESCWie wir oben sehen können, nutzt eine hybride Suchanfrage einfach den rrf-Retriever, der eine lexikalische Suchanfrage (z. B. eine Match-Anfrage), die mit einem Standard-Retriever erstellt wird, und eine im knn-Retriever angegebene Vektorsuchanfrage kombiniert. Bei dieser Abfrage werden zunächst die fünf besten Vektor-Treffer auf globaler Ebene abgerufen, dann mit den lexikalischen Treffern kombiniert und schließlich die zehn besten Treffer zurückgegeben. Der RRF-Retriever verwendet das RRF-Ranking, um vektorielle und lexikalische Treffer zu kombinieren.
Verständnis von spärlichen Vektoren und ELSER
Dichte Einbettungen sind nicht die einzige Möglichkeit, semantische Suche durchzuführen.
Sparse-Vektoren enthalten hauptsächlich Nullen mit einigen gewichteten Werten, die an interpretierbare Begriffe gebunden sind, wodurch sie ressourceneffizient, erklärbar und in Null-Shot-Szenarien effektiv sind.
Eine spärliche Vektordarstellung sieht so aus:
{"f1":1.2,"f2":0.3,… }
In Elasticsearch ist Elastic Learned Sparse EncodeR (ELSER) ein Out-of-Domain-Modell für spärliche natürliche Sprachverarbeitung (NLP), das Text in semantisch verwandte Begriffe erweitert und Gewichtungen zuweist, wodurch Übereinstimmungen über exakte Schlüsselwörter hinausgehen und gleichzeitig die Interpretierbarkeit erhalten bleibt.
Zusätzlich macht das Feld semantic_text die semantische Suche ebenso einfach wie die traditionelle Textsuche, indem es die Einbettungsgenerierung und Inferenz automatisch beim Ingest abwickelt. Sie können Dokumente wie ein Textfeld indizieren und eine einfache Abgleichsabfrage ausführen – sogar über Indizes hinweg, in denen sich der Feldtyp unterscheidet –, um sowohl lexikalische als auch semantische Übereinstimmungen ohne zusätzliche Abfragelogik zu erhalten. Für fortgeschrittene Steuerung verwenden Sie knn- oder sparse_vector-Abfragen auf demselben Feld.
Beispiel mit ELSER:
- Vortrainiertes Vokabular mit ~30.000 Begriffen
- Gespeichert als sparse_vector (Term/Gewicht-Paare)
- Automatisch beim Ingest mit semantic_text oder zur Indexzeit mit dem Inferenz-Ingest-Prozessor erzeugt
- Abgefragt über einen invertierten Index (wie bei der lexikalischen Suche), was sie effizient, filterfreundlich und erklärbar macht
POST my-index/_search
{
"retriever": {
"rrf": {
"retrievers": [
{
"standard": {
"query": {
"match": {
"text_field": "fox"
}
}
}
},
{
"standard": {
"query": {
"sparse_vector": {
"field": "ml.tokens",
"inference_id": ".elser_model_1",
"query": "a quick brown fox jumps over a lazy dog"
}
}
}
}
]
}
}
}
Zusammen bieten dichte und spärliche Vektoren Flexibilität: Dichte Vektoren zeichnen sich durch die Erfassung nuancierter Bedeutungen aus, während spärliche Vektoren Transparenz und Skalierbarkeit für die Suche in der realen Welt bieten.
Sehen Sie, wie Sie mit ELSER die Texterweiterung nutzen können, um bessere Ergebnisse zu erzielen:
Spärliche und dichte Vektoren im Vergleich in der Praxis
| Sparse Vektoren (ELSER) | Dicht besetzte Vektoren | |
|---|---|---|
| So funktionierts | Erweitert den Text in semantisch verwandte, gewichtete Begriffe. Jede Dimension entspricht einem Token mit zugehörigem Gewicht. | Kodiert Inhalte (Text, Bilder usw.) in Fließkomma-Vektoren mit fester Länge. Ähnliche Bedeutung = nahegelegene Positionen im Vektorraum. |
| Stärken |
|
|
| Beispiel-Anwendungsfälle |
|
|
| Ideal für | Wenn Sie semantische Verbesserungen und Transparenz benötigen oder wenn domänenspezifische Begriffe am wichtigsten sind | Wenn Sie Entdeckungen und Ähnlichkeiten basierend auf der Bedeutung und nicht auf exakten Wörtern über verschiedene Datentypen hinweg suchen |
Hybridsuche mit dichten und spärlichen Modellen
Bisher haben wir zwei verschiedene Möglichkeiten gesehen, eine Hybridsuche durchzuführen, abhängig davon, ob ein dichter oder spärlicher Vektorraum durchsucht wurde. Wir können sowohl dichte als auch spärliche Daten im selben Index mischen.
POST my-index/_search
{
"_source": false,
"fields": [ "text_field" ],
"retriever": {
"rrf": {
"retrievers": [
{
"knn": {
"field": "image_vector",
"query_vector": [0.1, 3.2, ..., 2.1],
"k": 5,
"num_candidates": 100
}
},
{
"standard": {
"query": {
"sparse_vector": {
"field": "ml.tokens",
"inference_id": ".elser_model_1",
"query": "a quick brown fox jumps over a lazy dog"
}
}
}
}
]
}
}
}
Noch einen Schritt weiter: Hybridsuche mit dichten, spärlichen und BM25F-Modellen
Dieses Beispiel kombiniert drei Retriever und verschmilzt ihre Ranglisten mit RRF:
- BM25F (Übereinstimmung mit Text): Genaue Übereinstimmungen mit Schlüsselwörtern/Phrasen („snowy mountain“).
- kNN (image_vector): Visuelle Ähnlichkeit unter Verwendung der bereitgestellten Bildeinbettung (k Ergebnisse aus num_candidates)
- Semantisch (semantic_text): Konzeptübereinstimmung durch semantische Erweiterung der Abfrage
rank_window_size steuert, wie viele Ergebnisse zusammengeführt werden; rank_constant gleicht die Beiträge aus jeder Liste aus.
GET my-index/_search
{
"retriever": {
"rrf": {
"retrievers": [
{
"standard": {
"query": {
"match": {
"text": {
"query": "snowy mountain"
}
}
}
}
},
{
"knn": {
"field": "image_vector",
"query_vector": [
0.01,
0.3,
-0.4
],
"k": 10,
"num_candidates": 100
}
},
{
"standard": {
"query": {
"semantic": {
"field": "semantic_text",
"query": "snowy mountain"
}
}
}
}
],
"rank_window_size": 50,
"rank_constant": 60
}
}
}
Betrachten wir auch ein ähnliches Beispiel mit ES|QL:
FROM my-index METADATA _score
| FORK (WHERE match(text, "snowy mountain") | SORT _score DESC | LIMIT 50)
(WHERE knn(image_vector, [0.01, 0.3, -0.4], {"min_candidates": 100 }) | SORT _score DESC | LIMIT 50)
(WHERE match(semantic_text, "snowy mountain") | SORT _score DESC | LIMIT 50)
| FUSE RRF WITH {"rank_constant": 60 } // 60 is the default anyway?
| SORT _score DESC
| LIMIT 50Fazit
Die Hybridsuche vereint die Präzision der Volltextsuche und die kontextuelle Reichweite der semantischen Suche und liefert genauere und relevantere Ergebnisse für verschiedene Inhalte. Durch die Unterstützung sowohl dichter als auch spärlicher Modelle und das Angebot flexibler Fusionsmethoden wie linearer Kombination und reziproker Rangfusion können Sie die Suche an Ihren Anwendungsfall anpassen – sei es durch die direkte Paarung von Anfragen und Vektoren oder durch die Optimierung der mehrstufigen Suche mit einem Retriever. Diese Flexibilität macht die Hybridsuche zu einem leistungsstarken Ansatz für komplexe Abfragen, vielfältige Daten und anspruchsvolle Relevanzanforderungen.
Erfahren Sie mehr über die hybride Suche:
- Entdecken Sie diesen Blog, um zu erfahren, was Hybridsuche ist, welche Query-Typen Elasticsearch unterstützt und wie man diese erstellt.
- Als Hintergrund zur Einordnung – Die Entwicklung der Hybridsuche und des Kontext-Engineerings
- Hybridsuche und mehrstufiges Retrieval in ES|QL
- Mühelose Hybridsuche: Vereinfachung der Hybridsuche mit Retrievern
Möchten Sie über Vektoren hinausgehen? Entdecken Sie intelligente Hybridsuche mit LLM-Agenten in Elasticsearch.
Bereit, selbst Hand anzulegen? Folgen Sie unserem hybriden Suchtutorial, um Volltext- und kNN-Ergebnisse zu kombinieren, oder probieren Sie das ES|QL-Tutorial zum Suchen und Filtern mit ES|QL.