BM25 in der Praxis – Teil 2: Der BM25-Algorithmus und seine Variablen
Dies ist der zweite Blogeintrag aus der dreiteiligen Reihe BM25 in der Praxis zum Thema Ähnlichkeitsbewertung (Relevanz). Falls Sie neu dazugestoßen sind, sehen Sie sich Teil 1: Auswirkungen von Shards auf das Relevanzscoring in Elasticsearch an.
Der BM25-Algorithmus
Ich werde versuchen, die mathematischen Erklärungen auf das notwendige Minimum zu beschränken, aber in diesem Teil befassen wir uns mit der Struktur der BM25-Formel, um den Prozess genauer zu verstehen. Sehen wir uns zunächst die Formel an, und dann werde ich die Komponenten in leicht verständliche Abschnitte unterteilen:
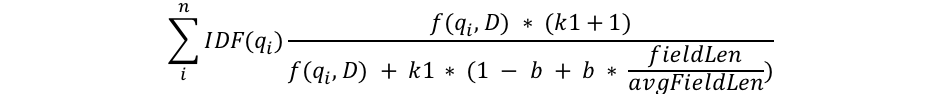
Wir sehen also einige gemeinsamen Komponenten wie etwa qi, IDF(qi), f(qi,D), k1, b und irgendetwas mit Feldlängen. Betrachten wir also die einzelnen Felder:
- qi ist der i-te Abfragebegriff.
Wenn ich beispielsweise nach „shane“ suche, gibt es nur einen Abfragebegriff, darum ist q0 gleich „shane“. Wenn ich auf Englisch nach „shane connelly“ suche, sieht Elasticsearch das Leerzeichen und unterteilt die Abfrage in zwei Token: q0 ist gleich „shane“ und q1 ist gleich „connelly“. Diese Abfragebegriffe werden mit den anderen Komponenten der Gleichung kombiniert, um das Ergebnis zu berechnen. - IDF(gi) ist die umgekehrte Dokumenthäufigkeit des i-ten Abfragebegriffs.
Falls Sie sich schon einmal mit TF/IDF befasst haben, ist Ihnen das Konzept von IDF möglicherweise bekannt. Falls nicht, machen Sie sich keine Sorgen! (Und falls doch, beachten Sie den Unterschied zwischen der IDF-Formel in TF/IDF und IDF in BM25.) Die IDF-Komponente in unserer Formel misst, wie oft ein Begriff in allen Dokumenten vorkommt und belegt häufige Begriffe mit einem Abzug. In der Praxis verwendet Lucene/BM25 die folgende Formel für diesen Teil: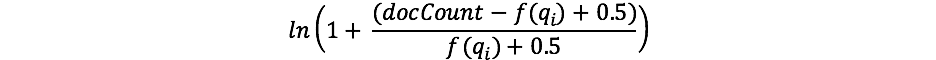
Dabei ist „docCount“ die Gesamtzahl der Dokument, die einen Wert für das Feld in der Shard haben (bzw. in mehreren Shards, falls Siesearch_type=dfs_query_then_fetchverwenden), und f(qi) ist die Anzahl der Dokumente, die den i-ten Abfragebegriff enthalten. Wir sehen in unserem Beispiel, dass „shane“ in allen vier Dokumenten vorkommt. Daher erhalten wir für den Begriff „shane“ also eine IDF(„shane“) von: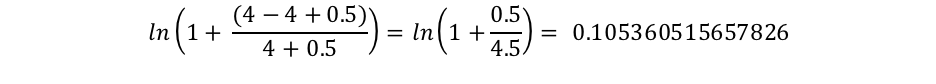
„connelly“ taucht dagegen nur in zwei Dokumenten auf, daher erhalten wir eine IDF(„connelly“) von: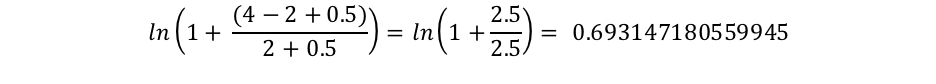
Die Abfragen mit diesen selteneren Begriffen („connelly“ ist in unserem aus vier Dokumenten bestehenden Korpus seltener als „shane“) haben einen höheren Multiplikator und tragen daher mehr zum Endergebnis bei. Das ist intuitiv sinnvoll: Der Begriff „the“ kommt in praktisch jedem englischen Dokument vor, daher ist in einer Suchabfrage nach „the elephant“ also der Begriff „elephant“ vermutlich wichtiger und trägt mehr zum Endergebnis bei als der Begriff „the“, der in praktisch allen Dokumenten vorkommt.
- Wir sehen außerdem, dass die Länge des Felds im Nenner durch die durchschnittliche Feldlänge geteilt wird (fieldLen/avgFieldLen).
Daraus ergibt sich die Länge eines Dokuments im Verhältnis zur durchschnittlichen Dokumentlänge. Wenn ein Dokument länger als der Durchschnitt ist, wird der Nenner größer (und die Bewertung nimmt ab), und wenn es kürzer als der Durchschnitt ist, wird der Nenner kleiner (und die Bewertung nimmt zu). Die Implementierung der Feldlänge in Elasticsearch hängt von der Anzahl der Begriffe ab (anstelle eines anderen Werts wie etwa der Zeichenanzahl). Diese Implementierung folgt dem ursprünglichen BM25-Paper exakt, aber wir haben ein besonderes Flag (discount_overlaps), mit dem Sie bei Bedarf Synonyme verarbeiten können. Je mehr Begriffe ein Dokument also enthält (zumindest Begriffe, die nicht mit der Abfrage übereinstimmen), desto niedriger ist die Bewertung für das Dokument. Das ist ebenfalls logisch verständlich: Wenn ein Do 300 Seiten lang ist und meinen Namen einmal erwähnt, hat es vermutlich weniger mit wir zu tun als ein kurzer Tweet, der mich einmal erwähnt. - Die Variable b steht im Nenner und wird mit dem Verhältnis der Feldlänge multipliziert, das wir uns gerade angesehen haben. Wenn b größer ist, wird die Auswirkung der Länge des Dokuments auf die durchschnittliche Länge verstärkt. Stellen Sie sich zur Veranschaulichung vor, dass für b gleich null die Auswirkung des Längenverhältnisses komplett aufgehoben wird und die Länge des Dokuments keinerlei Auswirkung auf die Bewertung hat. b hat in Elasticsearch standardmäßig den Wert 0,75.
- Zuletzt sehen wir zwei Komponenten der Bewertung, die im Zähler und im Nenner auftauchen: k1 und f(qi,D). Da diese Werte in Zähler und Nenner vorkommen, ist ihre Bedeutung für die Formel weniger offensichtlich, darum werde ich sie hier kurz erklären:
- f(qi,D) steht für „Wie oft kommt der i-te Abfragebegriff in Dokument D vor?“. In sämtlichen Dokumenten ist f(„shane“,D) gleich 1, aber f(„connelly“,D) hat unterschiedliche Werte, und zwar 1 für die Dokumente 3 und 4 und 0 für die Dokumente 1 und 2. Angenommen, es gäbe ein 5. Dokument mit dem Text „shane shane“, dann wäre für dieses Dokument f(„shane“,D) gleich 2. Wir sehen, dass f(qi,D) in Zähler und Nenner vorkommt. Außerdem haben wir den zusätzlichen Faktor „k1“, den wir uns als nächstes ansehen werden. f(qi,D) bedeutet, dass die Bewertung steigt, je öfter die Abfragebegriffe in einem Dokument vorkommen. Das ist logisch: Ein Dokument, in dem unser Name häufig vorkommt, hat vermutlich mehr mit uns zu tun als ein Dokument, das unseren Namen nur einmal erwähnt.
- Die Variable k1 hängt mit Eigenschaften der Sättigung der Begriffshäufigkeit zusammen. Damit wird festgelegt, wie stark ein einzelner Abfragebegriff die Bewertung eines Dokuments beeinflussen kann. Dies wird durch Annäherung an eine Asymptote erreicht. Hier sehen Sie eine Gegenüberstellung von BM25 und TF/IDF:
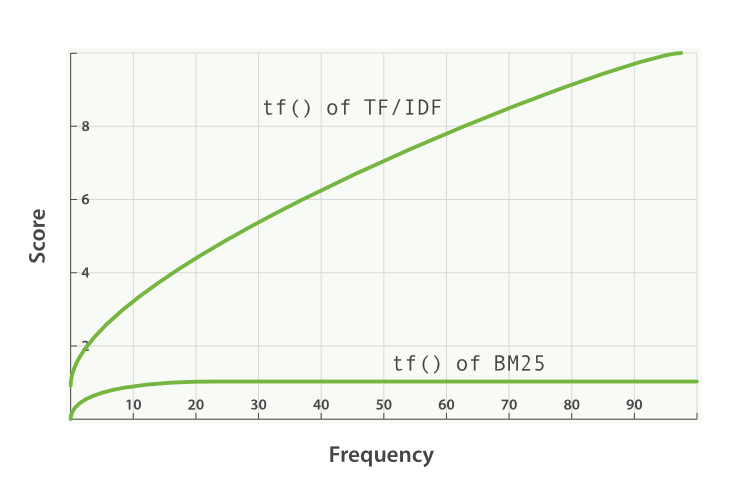
Ein höherer/niedrigerer Wert für k1 wirkt sich auf die Steigung der Kurve „tf() of BM25“ aus. Damit können wir beeinflussen, wie stark sich zusätzliche Vorkommnisse von Begriffen auf die Bewertung auswirken. k1 bewirkt also, dass in Dokumenten mit durchschnittlicher Länge die Worthäufigkeit die Hälfte der maximalen Bewertung für den jeweiligen Begriff beiträgt. Die Auswirkungskurve für tf auf die Auswirkungen steigt schneller für „tf() ≤ k1“ und langsamer für „tf() > k1“.
In unserem Beispiel steuern wir mit k1 die Antwort auf die Frage „Wie viel mehr trägt ein zweites Vorkommnis von „shane“ im Vergleich zum ersten oder zum dritten Vorkommnis zur Bewertung des Dokuments bei?“. Ein höherer Wert für k1 bewirkt, dass die Bewertung einzelner Begriffe für mehr Vorkommnisse des Begriffs stärker zunimmt. Ein Wert von 0 für k1 bewirkt, dass sich alles außer IDF(qi) gegenseitig aufhebt. k1 hat in Elasticsearch standardmäßig den Wert 1,2.
Ein Blick auf unsere Suche mit diesem neuen Wissen
Wir löschen unseren Index people und erstellen ihn erneut mit nur einer Shard, um search_type=dfs_query_then_fetch nicht verwenden zu müssen. Wir testen unser Wissen, indem wir drei Indizes erstellen: einen Index mit k1 gleich 0 und b gleich 0,5, einen zweiten Index (people2) mit b gleich 0 und k1 gleich 10 und einen dritten Index (people3) mit b gleich 1 und k1 gleich 5.
DELETE people
PUT people
{
"settings": {
"number_of_shards": 1,
"index" : {
"similarity" : {
"default" : {
"type" : "BM25",
"b": 0.5,
"k1": 0
}
}
}
}
}
PUT people2
{
"settings": {
"number_of_shards": 1,
"index" : {
"similarity" : {
"default" : {
"type" : "BM25",
"b": 0,
"k1": 10
}
}
}
}
}
PUT people3
{
"settings": {
"number_of_shards": 1,
"index" : {
"similarity" : {
"default" : {
"type" : "BM25",
"b": 1,
"k1": 5
}
}
}
}
}
Anschließend fügen wir einige Dokumente zu allen drei Indizes hinzu:
POST people/_doc/_bulk
{ "index": { "_id": "1" } }
{ "title": "Shane" }
{ "index": { "_id": "2" } }
{ "title": "Shane C" }
{ "index": { "_id": "3" } }
{ "title": "Shane P Connelly" }
{ "index": { "_id": "4" } }
{ "title": "Shane Connelly" }
{ "index": { "_id": "5" } }
{ "title": "Shane Shane Connelly Connelly" }
{ "index": { "_id": "6" } }
{ "title": "Shane Shane Shane Connelly Connelly Connelly" }
POST people2/_doc/_bulk
{ "index": { "_id": "1" } }
{ "title": "Shane" }
{ "index": { "_id": "2" } }
{ "title": "Shane C" }
{ "index": { "_id": "3" } }
{ "title": "Shane P Connelly" }
{ "index": { "_id": "4" } }
{ "title": "Shane Connelly" }
{ "index": { "_id": "5" } }
{ "title": "Shane Shane Connelly Connelly" }
{ "index": { "_id": "6" } }
{ "title": "Shane Shane Shane Connelly Connelly Connelly" }
POST people3/_doc/_bulk
{ "index": { "_id": "1" } }
{ "title": "Shane" }
{ "index": { "_id": "2" } }
{ "title": "Shane C" }
{ "index": { "_id": "3" } }
{ "title": "Shane P Connelly" }
{ "index": { "_id": "4" } }
{ "title": "Shane Connelly" }
{ "index": { "_id": "5" } }
{ "title": "Shane Shane Connelly Connelly" }
{ "index": { "_id": "6" } }
{ "title": "Shane Shane Shane Connelly Connelly Connelly" }
Wenn wir jetzt die folgende Abfrage ausführen:
GET /de/people/_search
{
"query": {
"match": {
"title": "shane"
}
}
}
Dann sehen wir in people, dass alle Dokumente die Bewertung 0,074107975 haben. Das passt zu unserem Verständnis für k1 gleich 0: Nur die IDF des Suchbegriffs wird für die Bewertung berücksichtigt!
Sehen wir uns nun people2 an. Dort haben wir b = 0 und k1 = 10 gesetzt:
GET /de/people2/_search
{
"query": {
"match": {
"title": "shane"
}
}
}
Diese Suchergebnisse verraten uns zwei Dinge.
Einerseits sehen wir, dass die Bewertung ausschließlich darauf basiert, wie oft „shane“ vorkommt. In den Dokumenten 1, 2, 3 und 4 kommt „shane“ jeweils einmal vor, und sie haben allesamt die Bewertung 0,074107975. Dokument 5 enthält „shane“ zweimal und hat daher eine höhere Bewertung (0,13586462) aufgrund von f(„shane“,D5) = 2. Dokument 6 hat aufgrund von f(„shane“,D6) = 3 eine noch höhere Bewertung (0,18812023). Diese Ergebnisse erfüllen unsere Erwartung für b gleich 0 in people2: Die Länge (Gesamtzahl der Begriffe im Dokument) ist irrelevant für die Bewertung. Nur Anzahl und Relevanz der gefundenen Begriffe werden berücksichtigt.
Außerdem fällt uns auf, dass die Differenz zwischen den Bewertungen nicht linear ist, obwohl sie in diesen Dokumenten beinahe linear zu sein scheint.
- Die Differenz zwischen keinen Vorkommnissen unseres Suchbegriffs und dem ersten Vorkommnis ist 0,074107975.
- Die Differenz zwischen dem zweiten Vorkommnis unseres Suchbegriffs und dem ersten Vorkommnis ist 0,13586462 - 0,074107975 = 0,061756645.
- Die Differenz zwischen dem dritten Vorkommnis unseres Suchbegriffs und dem zweiten Vorkommnis ist 0,18812023 - 0,13586462 = 0,05225561.
Die Differenz von 0,074107975 zu 0,061756645 und von 0,061756645 zu 0,05225561 ist zwar sehr klein, nimmt aber eindeutig ab. Dieser Verlauf ist beinahe linear, weil k1 sehr groß ist. Wir sehen zumindest, dass die Bewertung mit zusätzlichen Vorkommnissen nicht linear zunimmt. Andernfalls würden wir für jeden zusätzlichen Begriff dieselbe Differenz erhalten. Wir werden zu dieser Frage zurückkehren, nachdem wir people3 genauer betrachtet haben.
Sehen wir uns nun people3 an. Dort haben wir k1 = 5 und b = 1 gesetzt:
GET /de/people3/_search
{
"query": {
"match": {
"title": "shane"
}
}
}
Wir erhalten die folgenden Treffer:
"hits": [
{
"_index": "people3",
"_type": "_doc",
"_id": "1",
"_score": 0.16674294,
"_source": {
"title": "Shane"
}
},
{
"_index": "people3",
"_type": "_doc",
"_id": "6",
"_score": 0.10261105,
"_source": {
"title": "Shane Shane Shane Connelly Connelly Connelly"
}
},
{
"_index": "people3",
"_type": "_doc",
"_id": "2",
"_score": 0.102611035,
"_source": {
"title": "Shane C"
}
},
{
"_index": "people3",
"_type": "_doc",
"_id": "4",
"_score": 0.102611035,
"_source": {
"title": "Shane Connelly"
}
},
{
"_index": "people3",
"_type": "_doc",
"_id": "5",
"_score": 0.102611035,
"_source": {
"title": "Shane Shane Connelly Connelly"
}
},
{
"_index": "people3",
"_type": "_doc",
"_id": "3",
"_score": 0.074107975,
"_source": {
"title": "Shane P Connelly"
}
}
]
In people3 sehen wir, dass die relative Bewertung nur vom Verhältnis übereinstimmender Begriffe („shane“) zu nicht übereinstimmenden Begriffen beeinflusst wird. Daher hat Dokument 3 mit nur einem von drei übereinstimmenden Begriffen eine niedrigere Bewertung als 2, 4, 5 und 6, in denen jeweils genau die Hälfte der Begriffe übereinstimmt und die wiederum eine niedrigere Bewertung als Dokument 1 haben, das exakt mit dem Begriff übereinstimmt.
Auch hier sehen wir einen großen Unterschied zwischen den Dokumenten mit hoher Bewertung und den Dokumenten mit niedrigerer Bewertung in people2 und people3. Dies legt (erneut) an einem zu hohen Wert für k1. Als zusätzliche Aufgabe können Sie people2/people3 löschen und mit k1 = 0,01 erneut erstellen. Sie werden sehen, dass die Differenz zwischen Dokumenten mit weniger Vorkommnissen kleiner ausfällt. Angenommen, wir setzen b = 0 and k1 = 0,01:
- Die Differenz zwischen keinen Vorkommnissen unseres Suchbegriffs und dem ersten Vorkommnis ist 0,074107975.
- Die Differenz zwischen dem zweiten Vorkommnis unseres Suchbegriffs und dem ersten Vorkommnis ist 0,074476674 - 0,074107975 = 0,000368699.
- Die Differenz zwischen dem dritten Vorkommnis unseres Suchbegriffs und dem zweiten Vorkommnis ist 0,07460038 - 0,074476674 = 0,000123706.
Für k1 gleich 0,01 sehen wir, dass der Bewertungsbonus durch zusätzliche Vorkommnisse viel schneller abnimmt als für k1 = 5 oder k1 = 10. Das 4. Vorkommnis trägt viel weniger zur Bewertung bei als das 3. Vorkommnis, und so weiter. Die Bewertungen werden mit diesen kleinen Werten für k1 also viel schneller gesättigt. Genau wie erwartet!
Damit können wir hoffentlich besser verstehen, was diese Parameter in verschiedenen Dokumentensätzen bewirken. Mit diesem Wissen können wir jetzt passende Werte für b und k1 auswählen und uns ansehen, welche Elasticsearch-Tools uns helfen, die Bewertungen besser zu verstehen und unsere Herangehensweise zu verfeinern.
Lesen Sie weiter unter: Teil 3: Abwägungen für die Festlegung von b und k1 in Elasticsearch