RAG mit Kontext, dem Sie vertrauen können
KI-Anwendungen müssen präzise Ergebnisse im großen Maßstab liefern, um das Vertrauen der Nutzer aufzubauen. Verankern Sie große Sprachmodelle (LLMs) mit der Genauigkeit des Elasticsearch-Hybridabrufs und skalieren Sie Retrieval-Augmented Generation (RAG), die niedrige Latenz und hohe Effizienz bietet.
RAG wurde für unübertroffene Genauigkeit und effiziente Vektorskalierung entwickelt
Stellen Sie den richtigen Kontext mit der nötigen Vektorleistung, Kosteneffizienz und Sicherheit für die Produktion bereit.
Verleihen Sie Ihren RAG-Anwendungen den richtigen Kontext mit hybrider Suche, semantischem Reranking und integrierter Inferenz mithilfe erstklassiger Modelle von Drittanbietern oder nativen Jina AI-Modellen. Ersetzen Sie die naive Vektorsuche durch eine einzige Abfrage, die Schlüsselwörter, Vektoren und Filter kombiniert.

Skalieren Sie den Kontext über Milliarden von Dokumenten hinweg, die strukturierte, unstrukturierte und Vektordaten umfassen, ohne Kompromisse zwischen Trefferqualität und Speicherverbrauch eingehen zu müssen. Quantisierung und festplattenoptimierte Algorithmen wie DiskBBQ reduzieren den Speicherbedarf um bis zu 95 % und gewährleisten gleichzeitig eine hohe Ranking-Qualität bei geringer Latenz.

Vereinfachen Sie Ihre Pipeline mit einer einheitlichen Plattform, die Kontext aus Dokumenten sowie unstrukturierten und strukturierten Einträgen in einer einzigen Abfrage abruft. Setzen Sie dokumentenbasierte und RBAC durch, damit LLMs nur Daten offenlegen, die ein Nutzer sehen sollte.
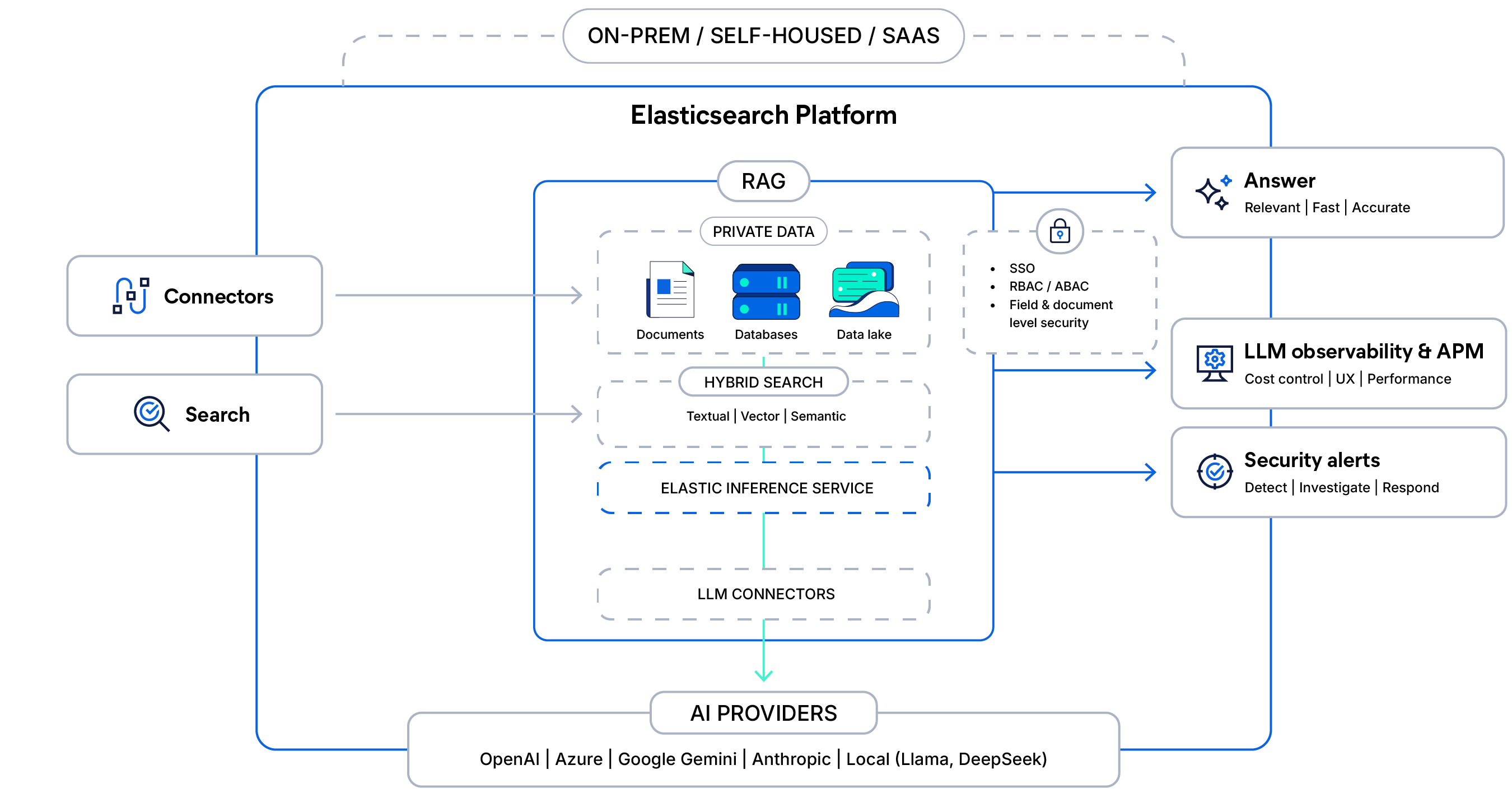
Die Architektur hinter kontextsensitivem RAG
Verbinden Sie Ihre privaten Daten mit sicherer Hybridsuche und verwalteter Inferenz, verankern Sie LLM-Reaktionen mit Zugriffskontrollen und liefern Sie schnelle, beobachtbare, produktionsbereite Antworten im großen Maßstab.
Was bauen Sie?
Erstellen Sie einen Chat, der auf Ihren Daten basiert und von Agenten unterstützt wird, die durch Kontext geleitet werden. Entdecken Sie unseren vollständigen Trainingskatalog oder folgen Sie unseren Tutorials auf Elasticsearch Labs.

Fragen und Antworten zu Ihren Daten. Erstellen Sie ein RAG-System mit Gemma, Hugging Face und Elasticsearch.

Entwickeln Sie mit LangGraph und Elasticsearch schneller agentische RAG-Apps.

Elastic hat einen GenAI Support Assistant entwickelt – entdecken Sie die Architektur, Techniken und Best Practices, um Ihren eigenen zu entwickeln.
Häufig gestellte Fragen
Was ist RAG in der KI?
Was ist RAG in der KI?
Retrieval Augmented Generation (allgemein als RAG bezeichnet) ist ein Muster für die Verarbeitung natürlicher Sprache, mit dem Unternehmen proprietäre Datenquellen durchsuchen und Kontext bereitstellen können, der die Grundlage für große Sprachmodelle bildet. Somit lassen sich bei generativen KI-Anwendungen (GenAI) genauere Antworten in Echtzeit liefern.
Was sind die Vorteile von RAG?
Was sind die Vorteile von RAG?
Bei optimaler Implementierung bietet RAG sicheren Zugriff auf relevante, domänenspezifische proprietäre Daten in Echtzeit. Es kann die Häufigkeit von Halluzinationen bei generativen KI-Anwendungen verringern und die Präzision der Antworten erhöhen.
Welche Vorteile bietet die Nutzung von Elastic für RAG-Workflows?
Welche Vorteile bietet die Nutzung von Elastic für RAG-Workflows?
Elastic macht RAG produktionsreif, indem es die größten Herausforderungen von vornherein löst: die Erfassung und Validierung hochwertiger Daten, die Bereitstellung präziser und effizienter Abfragen im großen Maßstab, die Durchsetzung von Sicherheit auf Rollen- und Dokumentenebene sowie die Sicherstellung der Quellenzuordnung für vertrauenswürdige Ergebnisse. Mit nativen Funktionen für Vektor-, lexikalische und hybride Abfrage, eigenen Modellen wie ELSER und flexiblen Integrationen von Drittanbietermodellen im gesamten Ökosystem generativer KI sowie bewährter Leistung im Unternehmensmaßstab unterstützt Elastic Teams beim Aufbau von RAG-Systemen, die schneller einsatzbereit, einfacher zu konfigurieren und im Produktivbetrieb zuverlässig sind.
Wie ermöglicht Elasticsearch Context Engineering?
Wie ermöglicht Elasticsearch Context Engineering?
Elasticsearch ist auf Relevanz im großen Maßstab ausgelegt, was die Grundlage des Context Engineering darstellt. Es vereint Vektor-, Schlüsselwort- und strukturierte Suche mit Analysen, Inferenz und Beobachtbarkeit in einer einzigen Plattform. Das erleichtert es Entwicklern, strukturierte und unstrukturierte Geschäftsdaten präzise zu speichern, abzurufen und zu bewerten, sodass Agenten immer den richtigen Kontext erhalten.
Mit Agent Builder geht Elasticsearch noch einen Schritt weiter, indem es Chat, Abruf, Tool-Erstellung und Orchestrierung direkt in die Plattform integriert. Entwickler können kontextgesteuerte Agenten in wenigen Minuten mit eigenen Daten, Modellen und Tools erstellen, testen und skalieren, die alle durch Relevanz, Sicherheit und Performance von Elasticsearch unterstützt werden.