Praktische Einführung in Logstash
Der Elastic Stack ist so konzipiert, dass sich das Einspeisen („Ingesting“) von Daten in Elasticsearch möglichst einfach gestaltet. Mit Filebeat steht ein leistungsfähiges Tool zur Überwachung von Dateien zur Verfügung, das über eine Reihe von Modulen verfügt, mit denen ohne viel Konfigurationsaufwand die verschiedensten Protokollformate verarbeitet werden können. Wenn es für Ihre konkreten Daten keine Module geben sollte, bieten die Logstash- und Elasticsearch-Ingest-Knoten eine flexible und leistungsfähige Möglichkeit, die meisten Arten von textbasierten Daten zu parsen und zu verarbeiten.
In diesem Blogpost geben wir Ihnen eine kurze Einführung in Logstash und zeigen anhand einiger Squid-Zugriffsprotokolle, wie Sie damit eine Konfiguration zum Parsen und Einspeisen der Protokolldaten in Elasticsearch entwickeln können.
Kurzer Überblick über Logstash
Logstash ist eine auf Plugins basierende Datenerfassungs- und Datenverarbeitungs-Engine. Ein großes Angebot an Plugins ermöglicht die einfache Konfiguration für die Erfassung, Verarbeitung und Weiterleitung von Daten in vielen verschiedenen Architekturen.
Die Verarbeitung erfolgt im Rahmen einer oder mehrerer sogenannter Pipelines. In jeder Pipeline gibt es ein oder mehrere Input-Plugins, die Daten erhalten oder erfassen und in eine interne Warteschlange stellen. Diese ist standardmäßig klein und wird im Arbeitsspeicher gehalten, kann aber bei Bedarf so konfiguriert werden, dass sie mehr Platz bietet und auf Platte gespeichert wird, um eine größere Zuverlässigkeit und Resilienz zu gewährleisten.
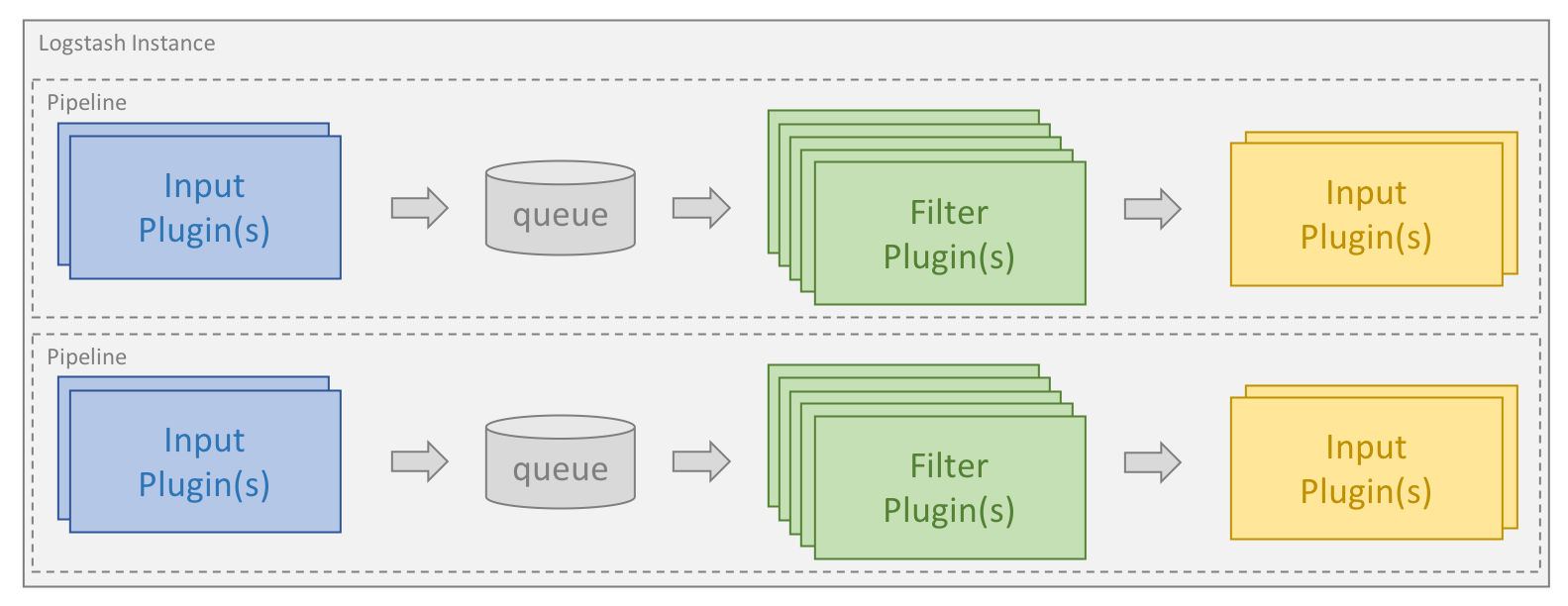
Verarbeitungs-Threads lesen Daten aus der Warteschlange in Mikro-Batches und verarbeiten sie nacheinander durch die konfigurierten Filter-Plugins. Logstash verfügt standardmäßig über eine große Zahl von Plugins, die die verschiedensten Verarbeitungsarten abdecken und dafür sorgen, dass die Daten geparst, verarbeitet und angereichert werden.
Nachdem die Daten verarbeitet wurden, werden sie von den Verarbeitungs-Threads an die entsprechenden Output-Plugins gesendet, wo sie formatiert und weitergeleitet werden, beispielsweise an Elasticsearch.
Input- und Output-Plugins können auch mit einem Codec-Plugin konfiguriert werden. Auf diese Weise lassen sich Daten parsen und/oder formatieren, bevor sie in die interne Warteschlange gestellt oder an ein Output-Plugin gesendet werden.
Logstash und Elasticsearch installieren
Damit Sie die Beispiele in diesem Blogpost ausführen können, müssen Sie zunächst Logstash und Elasticsearch installieren. Wählen Sie die Links, um zu erfahren, wie Sie bei Ihrem Betriebssystem vorgehen müssen. Wir nutzen die Elastic Stack-Version 6.2.4.
Pipelines festlegen
Logstash-Pipelines werden auf der Grundlage einer oder mehrerer Konfigurationsdateien erstellt. Bevor wir loslegen, zeigen wir Ihnen kurz die verschiedenen verfügbaren Optionen. Die in diesem Abschnitt beschriebenen Verzeichnisse sind abhängig vom jeweiligen Installationsmodus und Betriebssystem und werden in der Dokumentation näher beschrieben.
Einzelne Pipeline mit nur einer Konfigurationsdatei
Die einfachste Art, Logstash zu starten, besteht darin, eine einzelne Pipeline auf der Basis nur einer Konfigurationsdatei zu erstellen, die wir durch den Befehlszeilenparameter -f angeben. Dies ist auch die Herangehensweise, die wir in den Beispielen in diesem Blogpost verwenden.
Einzelne Pipeline mit mehreren Konfigurationsdateien
Logstash kann auch so konfiguriert werden, dass alle Dateien in einem bestimmten Verzeichnis als Konfigurationsdateien verwendet werden. Diese Einstellung kann entweder über die Datei logstash.yml oder durch Festlegen eines Verzeichnispfades mit dem Befehlszeilenparameter -f vorgenommen werden. Bei der Installation von Logstash als Service ist dies die Standardvorgabe.
Wenn ein Verzeichnis angegeben wird, werden alle Dateien in diesem Verzeichnis in lexikografischer Reihenfolge aneinandergehängt und dann als eine gemeinsame Konfigurationsdatei geparst. Bei dieser Vorgehensweise durchlaufen alle Daten aus allen Eingangsquellen alle Filter und werden an alle Ausgangsziele gesendet, sofern Sie den Datenfluss nicht mit Bedingungen steuern.
Mehrere Pipelines
Wenn Sie in Logstash mehrere Pipelines verwenden möchten, müssen Sie die Logstash-Datei pipelines.yml bearbeiten, die Sie im Verzeichnis „Settings“ finden. Das Verzeichnis enthält Konfigurationsdateien und -parameter für alle von der jeweiligen Logstash-Instanz unterstützten Pipelines.
Die Verwendung mehrerer Pipelines ermöglicht es Ihnen, unterschiedliche logische Abläufe voneinander zu trennen und so die Komplexität und Zahl der Bedingungen deutlich zu reduzieren. Das erleichtert die Feineinstellung und Pflege der Konfiguration. Und da die Daten, die gleichzeitig die Pipeline passieren, homogener sind, kann auch die Arbeitsgeschwindigkeit spürbar profitieren, weil die Output-Plugins effizienter genutzt werden können.
Erste Konfiguration erstellen
Jede Logstash-Konfiguration muss mindestens ein Input-Plugin und ein Output-Plugin enthalten. Die Verwendung von Filtern ist optional. Um ein erstes Beispiel für eine einfache Konfigurationsdatei zu geben, beginnen wir mit einer Konfigurationsdatei, die Testdaten aus einer Datei liest und diese in strukturierter Form an die Konsole ausgibt. Eine solche Konfigurationsdatei ist bei der Entwicklung einer Konfiguration sehr nützlich, erlaubt sie es Ihnen doch, die Konfiguration schnell zu iterieren und aufzubauen. In diesem Blogpost soll unsere Konfigurationsdatei stets test.conf heißen und zusammen mit der Datei, die unsere Testdaten enthält, im Verzeichnis „/home/logstash“ gespeichert sein:
input {
file {
path => ["/home/logstash/testdata.log"]
sincedb_path => "/dev/null"
start_position => "beginning"
}
}
filter {
}
output {
stdout {
codec => rubydebug
}
}
In diesem Beispiel sehen wir die drei übergeordneten Gruppierungen, die Bestandteil jeder Logstash-Konfiguration sind: input, filter und output. Im Abschnitt „input“ haben wir ein Input-Plugin „file“ angegeben und über die Anweisung path den Pfad unserer Testdatendatei bereitgestellt. Unter start_position haben wir mit „beginning“ festgelegt, dass das Plugin neu entdeckte Dateien jeweils vom Anfang lesen soll.
Um die Übersicht zu behalten, welche Daten in jeder Input-Datei bereits verarbeitet wurden, verwendet das Logstash-Input-Plugin „file“ eine Datei namens sincedb, die die aktuelle Position aufzeichnet. Da unsere Konfiguration für die Entwicklung bestimmt ist, soll die Datei immer wieder neu gelesen werden, weshalb es sinnvoll ist, die Verwendung der Datei „sincedb“ zu deaktivieren. Dazu ist für sincedb_path bei Linux-Systemen „/dev/null“ und bei Windows-Systemen „nul“ festzulegen.
Auch wenn das Logstash-Input-Plugin „file“ ein guter Ausgangspunkt für das Entwickeln von Konfigurationen ist, wird für die Protokollerfassung und den Weiterversand von Daten von den Hostservern aus empfohlen, Filebeat zu verwenden. Filebeat kann Protokolle an Logstash ausgeben und Logstash kann diese Protokolle mit dem Beats-Input empfangen und verarbeiten. Die in diesem Blogpost skizzierte Parsing-Logik bleibt in beiden Szenarien weiter gültig, aber Filebeat ist mehr Performance-optimiert und beansprucht weniger Ressourcen, womit es sich ideal für die Ausführung als Agent eignet.
Das Output-Plugin stdout sendet die Daten an die Konsole und der Codec rubydebug hilft, die Struktur aufzuzeigen, was das Debugging bei der Konfigurationsentwicklung erleichtert.
Logstash starten
Um das ordnungsgemäße Funktionieren von Logstash und unserer Konfigurationsdatei zu prüfen, erstellen wir im Verzeichnis „/home/logstash“ eine Datei namens „testdata.log“. Diese enthält die Zeichenfolge „Hello Logstash!“, gefolgt von einem Zeilenumbruch.
Wenn wir davon ausgehen, dass wir in unserem Pfad die Binärdatei „logstash“ haben, können wir mit dem folgenden Befehl Logstash starten:
logstash -r -f "/home/logstash/test.conf"
Zusätzlich zum oben bereits besprochenen Befehlszeilenparameter -f haben wir auch das Flag -r verwendet. Damit wird Logstash angewiesen, die Konfiguration automatisch neu zu laden, sobald eine Konfigurationsänderung festgestellt wurde. Dies ist sehr hilfreich, vor allem während der Entwicklungsphase. Da wir die Datei „sincedb“ deaktiviert haben, wird die Input-Datei bei jedem Neuladen der Konfiguration neu gelesen, sodass wir die Konfiguration beim Entwickeln immer mal wieder zwischendurch testen können.
Logstash gibt an die Konsole ein paar Protokolleinträge aus, die im Zusammenhang mit dem Logstash-Start stehen. Anschließend wird die Datei verarbeitet und Folgendes ausgegeben (Beispielausgabe):
{
"message" => "Hello Logstash!",
"@version" => "1",
"path" => "/home/logstash/testdata.log",
"@timestamp" => 2018-04-24T12:40:09.105Z,
"host" => "localhost"
}
Dies ist das Ereignis, das von Logstash verarbeitet wurde. Der Ausgabe ist zu entnehmen, dass die Daten im Meldungsfeld („message“) gespeichert werden und dass Logstash einige Metadaten für das Ereignis in Form des Zeitstempels für den Verarbeitungszeitpunkt und der Angabe der Herkunft hinzugefügt hat.
Das sieht alles sehr gut aus und zeigt, dass das Ganze funktioniert. Jetzt werden wir einige realitätsnähere Testdaten hinzufügen und zeigen, wie sie sich parsen lassen.
Wie parse ich meine Protokolle?
Idealerweise gibt es bereits einen perfekten Filter, der für das Parsen der Daten verwendet werden kann, wie zum Beispiel den json-Filter für Protokolle im JSON-Format. Oft müssen wir jedoch Protokolle in anderen Textformattypen parsen. In diesem Blogpost verwenden wir zur Illustration ein paar Zeilen aus Squid-Cachezugriffsprotokollen. Diese sehen wie folgt aus:
1524206424.034 19395 207.96.0.0 TCP_MISS/304 15363 GET http://elastic.co/android-chrome-192x192.gif - DIRECT/10.0.5.120 - 1524206424.145 106 207.96.0.0 TCP_HIT/200 68247 GET http://elastic.co/guide/en/logstash/current/images/logstash.gif - NONE/- image/gif
Jede Zeile enthält Informationen über eine Anfrage beim Squid-Cache und kann in mehrere getrennte Felder aufgeteilt werden, die geparst werden müssen.

Beim Parsen von Textprotokollen werden vor allem die folgenden beiden Filter häufig verwendet: „dissect“ parst Protokolle auf der Basis von Trennzeichen, während grok mit regulären Ausdrücken arbeitet.
Der Filter „dissect“ funktioniert sehr gut, wenn die Struktur der Daten gut definiert ist; dann kann er sehr schnell und effizient sein. Auch ist die Arbeit mit diesem Filter für Anfänger oft einfacher – speziell, wenn es an Erfahrungen mit regulären Ausdrücken fehlt.
„grok“ ist im Allgemeinen leistungsfähiger und kann eine größere Bandbreite von Daten verarbeiten. Der Abgleich regulärer Ausdrücke ist jedoch tendenziell ressourcenintensiver und langsamer, vor allem, wenn der Filter nicht korrekt optimiert wurde.
Bevor wir uns ans eigentliche Parsen machen, ersetzen wir den Inhalt der Datei testdata.log durch diese beiden Protokollzeilen und sorgen dafür, dass jede Zeile von einem Zeilenumbruch gefolgt wird.
Protokolle mit „dissect“ parsen
Wenn der Filter „dissect“ verwendet wird, müssen Sie eine Abfolge von zu extrahierenden Feldern und die zu berücksichtigenden Trennzeichen zwischen diesen Feldern angeben. Der Filter geht einmal über die Daten und gleicht die Trennzeichen im Muster ab. Gleichzeitig werden den angegebenen Feldern Daten zwischen den Trennzeichen zugeordnet. Eine Validierung der extrahierten Daten findet nicht statt.
In der folgenden Zeile sind die Trennzeichen, die beim Parsen dieser Daten mit dem Filter „dissect“ zum Einsatz kommen, pink unterlegt.

Das erste Feld enthält den Zeitstempel. Es wird, abhängig von der Länge des sich anschließenden Feldes mit der Dauer, von einem oder mehreren Leerzeichen gefolgt. Wir können das Zeitstempelfeld als „%{timestamp}“ angeben, aber damit es eine variable Zahl von Leerzeichen als Trennzeichen annimmt, müssen wir dem Feld das Suffix -> hinzufügen. Alle anderen Trennzeichen im Protokolleintrag bestehen jeweils aus einem einzelnen Zeichen. Daher können wir von hier aus das Muster weiterentwickeln und erhalten den folgenden Filterabschnitt:
{
"@version" => "1",
"message" => "1524206424.034 19395 207.96.0.0 TCP_MISS/304 15363 GET http://elastic.co/android-chrome-192x192.gif - DIRECT/10.0.5.120 -",
"@timestamp" => 2018-04-24T12:42:23.003Z,
"path" => "/home/logstash/testdata.log",
"host" => "localhost",
"duration" => "19395",
"timestamp" => "1524206424.034",
"rest" => "TCP_MISS/304 15363 GET http://elastic.co/android-chrome-192x192.gif - DIRECT/10.0.5.120 -",
"client_ip" => "207.96.0.0"
}
Jetzt können wir damit fortfahren, das Muster Schritt für Schritt weiterzuentwickeln. Nachdem wir erfolgreich alle Felder extrahiert haben, können wir das Feld „message“ entfernen, damit wir nicht zweimal dieselben Daten haben. Dazu kann die Anweisung „remove_field“ verwendet werden, die nur bei erfolgreichem Parsing ausgeführt wird und den folgenden Filterblock zum Ergebnis hat:
filter {
dissect {
mapping => {
"message" => "%{timestamp->} %{duration} %{client_address} %{cache_result}/%{status_code} %{bytes} %{request_method} %{url} %{user} %{hierarchy_code}/%{server} %{content_type}"
}
remove_field => ["message"]
}
}
Nach einem Abgleich mit den Beispieldaten sieht der erste Datensatz wie folgt aus:
{
"user" => "-",
"content_type" => "-",
"host" => "localhost",
"cache_result" => "TCP_MISS",
"@timestamp" => 2018-04-24T12:43:07.406Z,
"duration" => "19395",
"request_method" => "GET",
"url" => "http://elastic.co/android-chrome-192x192.gif",
"timestamp" => "1524206424.034",
"status_code" => "304",
"server" => "10.0.5.120",
"@version" => "1",
"client_address" => "207.96.0.0",
"bytes" => "15363",
"path" => "/home/logstash/testdata.log",
"hierarchy_code" => "DIRECT"
}
Die Dokumentation enthält ein paar gute Beispiele und dieser Blogpost gibt einen guten Überblick über Aufbau und Zweck des Filters.
Das war doch ganz einfach, oder? Wir werden das später noch etwas vertiefen, sehen uns aber zuerst an, wie wir dasselbe mit dem Filter „grok“ erreichen können.
Wie kann ich „grok“ am besten einsetzen?
„grok“ nutzt auf regulären Ausdrücken basierende Muster, um Felder und Trennzeichen zu finden. In der folgenden Abbildung sind die zu erfassenden Felder blau und die Trennzeichen pink unterlegt:

„grok“ beginnt mit dem Abgleich der konfigurierten Muster von oben und setzt diesen so lange fort, bis das gesamte Ereignis zugeordnet wurde oder der Filter feststellt, dass keine Übereinstimmung gefunden werden kann. Je nach verwendeten Mustertypen kann es vorkommen, dass „grok“ Teile der Daten mehrfach verarbeiten muss.
„grok“ bietet von Haus aus eine Vielzahl unterschiedlichster vordefinierter Muster. Einige der eher allgemeinen Muster werden hier vorgestellt, aber darüber hinaus enthält die Mustersammlung noch eine große Zahl weiterer, recht spezialisierter Muster für gängige Datentypen. Dazu gehört auch eines für das Parsen von Squid-Zugriffsprotokollen, aber statt es einfach direkt zu verwenden, zeigen wir Ihnen in diesem Tutorial, wie Sie das Muster ganz neu erstellen können. Allerdings ist es immer sinnvoll, in dieser Mustersammlung nachzuschauen, ob es nicht bereits ein passendes Muster gibt, bevor Sie sich daran machen, ein eigenes Muster zu erstellen.
Beim Erstellen einer „grok“-Konfiguration gibt es eine Reihe gebräuchlicher Standardmuster:
- WORD: Muster zur Suche nach einem Einzelwort
- NUMBER: Muster zur Suche nach einer positiven oder negativen Ganz- oder Gleitkommazahl
- POSINT: Muster zur Suche nach einer positiven Ganzzahl
- IP: Muster zur Suche nach einer IPv4- oder IPv6-IP-Adresse
- NOTSPACE: Muster zur Suche nach allem, das kein Leerzeichen ist
- SPACE: Muster zur Suche nach aufeinanderfolgenden Leerzeichen beliebiger Zahl
- DATA: Muster zur Suche nach einer begrenzten Menge beliebiger Daten
- GREEDYDATA: Muster zur Suche nach allen verbleibenden Daten
Dies sind die Muster, die wir für die Entwicklung unserer „grok“-Filterkonfiguration nutzen werden. Bei „grok“-Konfigurationen wird generell links begonnen und dann Schritt für Schritt das Muster erarbeitet, wobei hier die verbleibenden Daten mit dem Muster GREEDYDATA erfasst werden. Wir können folgendes Muster und folgenden Filterblock als Ausgangspunkt verwenden:
filter {
grok {
match => {
"message" => "%{NUMBER:timestamp}%{SPACE}%{GREEDYDATA:rest}"
}
}
}
Dieses Muster weist „grok“ an, nach einer Zahl am Beginn einer Zeichenfolge zu suchen und diese in einem Feld namens timestamp zu speichern. Dann findet es eine Anzahl von Leerzeichen, bevor der Rest der Daten in einem Feld namens rest gespeichert wird. Wenn wir hierfür zum „dissect“-Filterblock wechseln, wird der erste Datensatz wie folgt ausgegeben:
{
"timestamp" => "1524206424.034",
"rest" => "19395 207.96.0.0 TCP_MISS/304 15363 GET http://elastic.co/android-chrome-192x192.gif - DIRECT/10.0.5.120 -",
"path" => "/home/logstash/testdata.log",
"message" => "1524206424.034 19395 207.96.0.0 TCP_MISS/304 15363 GET http://elastic.co/android-chrome-192x192.gif - DIRECT/10.0.5.120 -",
"@timestamp" => 2018-04-24T12:45:11.026Z,
"@version" => "1",
"host" => "localhost"
}
Grok Debugger verwenden
Wir können zwar das gesamte Muster auf diese Weise entwickeln, aber in Kibana gibt es ein Tool, das helfen kann, die Erstellung von „grok“-Mustern zu vereinfachen: den Grok Debugger. Im folgenden Video zeigen wir, wie dieses Tool für die Entwicklung der Muster für die Beispielprotokolle in diesem Blogpost verwendet werden kann:
Nachdem die Konfiguration fertig erstellt wurde, können wir festlegen, dass das Feld „message“ im Anschluss an das erfolgreiche Parsen entfernt werden soll. Der Filterblock sieht dann so aus:
filter {
grok {
match => {
"message" => "%{NUMBER:timestamp}%{SPACE}%{NUMBER:duration}\s%{IP:client_address}\s%{WORD:cache_result}/%{POSINT:status_code}\s%{NUMBER:bytes}\s%{WORD:request_method}\s%{NOTSPACE:url}\s%{NOTSPACE:user}\s%{WORD:hierarchy_code}/%{NOTSPACE:server}\s%{NOTSPACE:content_type}"
}
remove_field => ["message"]
}
}
Das Ergebnis ähnelt zwar dem vordefinierten Muster, die beiden sind aber nicht identisch. Bei Anwendung auf die Beispieldaten wird der erste Datensatz genauso wie bei der Verwendung des Filters „dissect“ geparst:
{
"request_method" => "GET",
"cache_result" => "TCP_MISS",
"@timestamp" => 2018-04-24T12:48:15.123Z,
"timestamp" => "1524206424.034",
"user" => "-",
"bytes" => "15363",
"path" => "/home/logstash/testdata.log",
"hierarchy_code" => "DIRECT",
"duration" => "19395",
"client_address" => "207.96.0.0",
"@version" => "1",
"status_code" => "304",
"url" => "http://elastic.co/android-chrome-192x192.gif",
"content_type" => "-",
"host" => "localhost",
"server" => "10.0.5.120"
}
„grok“ auf Performance tunen
„grok“ ist ein sehr leistungsfähiges und flexibles Tool für das Parsen von Daten, aber wenn Muster nicht effizient genug angewendet werden, kann die Performance deutlich leiden. Wir empfehlen Ihnen daher, den Blogpost zum Optimieren der „grok“-Performance zu lesen, bevor Sie ernsthaft mit der Nutzung von „grok“ beginnen.
Für richtige Feldtypen sorgen
Wie Sie in den Beispielen oben gesehen haben, wurden alle Felder als String-Felder extrahiert. Bevor wir das in Form von JSON-Dokumenten an Elasticsearch senden, möchten wir die Werte der Felder bytes, duration und status_code in Ganzzahlen und den Wert des Feldes timestamp in eine Gleitkommazahl ändern.
Eine Möglichkeit, dies zu erreichen, wäre die Verwendung eines „mutate“-Filters und seiner Option convert.
mutate {
convert => {
"bytes" => "integer"
"duration" => "integer"
"status_code" => "integer"
"timestamp" => "float"
}
}
Dasselbe können wir aber auch direkt mit den Filtern „dissect“ und „grok“ bewerkstelligen. Im Filter „dissect“ verwenden wir dazu die Anweisung „convert_datatype“:
filter {
dissect {
mapping => {
"message" => "%{timestamp->} %{duration} %{client_address} %{cache_result}/%{status_code} %{bytes} %{request_method} %{url} %{user} %{hierarchy_code}/%{server} %{content_type}"
}
remove_field => ["message"]
convert_datatype => {
"bytes" => "int"
"duration" => "int"
"status_code" => "int"
"timestamp" => "float"
}
}
}
Bei Verwendung von „grok“ lässt sich der Typ im Muster direkt nach dem Feldnamen angeben:
filter {
grok {
match => {
"message" => "%{NUMBER:timestamp:float}%{SPACE}%{NUMBER:duration:int}\s%{IP:client_address}\s%{WORD:cache_result}/%{POSINT:status_code:int}\s%{NUMBER:bytes:int}\s%{WORD:request_method}\s%{NOTSPACE:url}\s%{NOTSPACE:user}\s%{WORD:hierarchy_code}/%{NOTSPACE:server}\s%{NOTSPACE:content_type}"
}
remove_field => ["message"]
}
}
Filter „date“ verwenden
Die aus dem Protokoll extrahierte Zeitstempelangabe liegt in Sekunden und Millisekunden seit Epoche vor. Wir möchten diese Angabe in ein Standard-Zeitstempelformat umwandeln und den Wert dann im Feld @timestamp speichern. Zu diesem Zweck verwenden wir das Filter-Plugin „date“ zusammen mit dem Muster UNIX, das für unsere Daten geeignet ist.
date {
match => [ "timestamp", "UNIX" ]
}
Für alle in Elasticsearch gespeicherten Standard-Zeitstempel gilt die Zeitzone UTC. Da dies auch auf unseren extrahierten Zeitstempel zutrifft, brauchen wir keine Zeitzone anzugeben. Wenn Sie einen Zeitstempel in einem anderen Format haben, können Sie ohne Weiteres statt des vordefinierten Musters UNIX dieses Format angeben.
Nachdem wir unserer Konfiguration dies und die Typumwandlungen hinzugefügt haben, sieht das erste Ereignis wie folgt aus:
{
"duration" => 19395,
"host" => "localhost",
"@timestamp" => 2018-04-20T06:40:24.034Z,
"bytes" => 15363,
"user" => "-",
"path" => "/home/logstash/testdata.log",
"content_type" => "-",
"@version" => "1",
"url" => "http://elastic.co/android-chrome-192x192.gif",
"server" => "10.0.5.120",
"client_address" => "207.96.0.0",
"timestamp" => 1524206424.034,
"status_code" => 304,
"cache_result" => "TCP_MISS",
"request_method" => "GET",
"hierarchy_code" => "DIRECT"
}
Wir haben also jetzt das gewünschte Format und sind bereit, mit dem Senden der Daten an Elasticsearch zu beginnen.
Wie kann ich Daten an Elasticsearch senden?
Bevor wir anfangen können, mithilfe des Elasticsearch-Output-Plugins Daten an Elasticsearch zu senden, müssen wir uns die Rolle von Zuordnungen ansehen und darauf eingehen, wie diese sich von den Typen unterscheiden, in die Daten in Logstash umgewandelt werden können.
Elasticsearch ist in der Lage, automatisch String- und numerische Felder zu erkennen, und die Zuordnung wird anhand des ersten Dokuments mit einem neuen Feld ausgewählt, auf das Elasticsearch stößt. Je nach Aussehen der Daten kann die Zuordnung korrekt sein oder auch nicht. Nehmen wir als Beispiel ein Feld, das üblicherweise eine Gleitkommazahl beherbergt, bei einigen Daten aber auch „0“ sein kann. Abhängig davon, welches Dokument zuerst verarbeitet wurde, könnte es sein, dass dieser Wert statt als Gleitkommazahl als Ganzzahl zugeordnet wird.
Elasticsearch ist zudem in der Lage, Datumsfelder zu erkennen, sofern diese sich in dem Standardformat befinden, das der Filter „date“ ausgibt.
Andere Feldtypen, wie geo_point und ip können nicht automatisch erkannt werden und müssen daher mithilfe einer Indexvorlage explizit definiert werden. Indexvorlagen können über eine API direkt in Elasticsearch verwaltet werden, aber Sie können auch Logstash anweisen, über das Elasticsearch-Output-Plugin dafür zu sorgen, dass die richtige Vorlage geladen wird.
Was unsere Daten anbelangt, reichen uns im Allgemeinen die Standardzuordnungen. Das Feld server kann einen Strich oder eine gültige IP-Adresse enthalten, sodass wir es nicht als IP-Feld zuordnen werden. Zu den Feldern, die manuelle Zuordnungen erforderlich machen, gehört das Feld client_address, das dem Typ „ip“ zugeordnet werden soll. Wir haben auch ein paar String-Felder, die herüberaggregiert werden sollen, die aber nicht für eine Freitextsuche zur Verfügung stehen müssen. Wir ordnen diese explizit als keyword-Felder zu. Es handelt sich dabei um die folgenden Felder: user, path, content_type, cache_result, request_method, server und hierarchy_code.
Wir möchten unsere Daten in zeitbasierten Indizes speichern, die mit dem Präfix squid- beginnen. Dabei wird für dieses Beispiel davon ausgegangen, dass Elasticsearch mit der Standardkonfiguration auf demselben Host wie Logstash läuft.
Wir können dann die folgende Vorlage erstellen, die in einer Datei namens squid_mapping.json gespeichert wird:
{
"index_patterns": ["squid-*"],
"mappings": {
"doc": {
"properties": {
"client_address": { "type": "ip" },
"user": { "type": "keyword" },
"path": { "type": "keyword" },
"content_type": { "type": "keyword" },
"cache_result": { "type": "keyword" },
"request_method": { "type": "keyword" },
"server": { "type": "keyword" },
"hierarchy_code": { "type": "keyword" }
}
}
}
}
Diese Vorlage ist so konfiguriert, dass sie für alle Indizes gilt, die dem Indexmuster squid-* entsprechen. Beim Dokumententyp doc (Standard in Elasticsearch 6.x) gibt sie als Zuordnungsziel für das Feld client_address „ip“ an, während den anderen angegebenen Feldern ein keyword-Feld zugeordnet werden soll.
Wir könnten das jetzt direkt zu Elasticsearch hochladen, zeigen aber stattdessen, wie Sie das Elasticsearch-Output-Plugin so konfigurieren können, dass es sich darum kümmert. Im Abschnitt „output“ unserer Logstash-Konfiguration fügen wir einen Block wie den folgenden hinzu:
elasticsearch {
hosts => ["localhost:9200"]
index => "squid-%{+YYYY.MM.dd}"
manage_template => true
template => "/home/logstash/squid_mapping.json"
template_name => "squid_template"
}
Wenn wir jetzt diese Konfiguration ausführen und die Beispieldokumente für den Import in Elasticsearch indexieren, erhalten wir beim Abruf der Zuordnungsergebnisse für den Index über die API zum Abrufen der Zuordnung Folgendes:
{
"squid-2018.04.20" : {
"mappings" : {
"doc" : {
"properties" : {
"@timestamp" : {
"type" : "date"
},
"@version" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
},
"bytes" : {
"type" : "long"
},
"cache_result" : {
"type" : "keyword"
},
"client_address" : {
"type" : "ip"
},
"content_type" : {
"type" : "keyword"
},
"duration" : {
"type" : "long"
},
"hierarchy_code" : {
"type" : "keyword"
},
"host" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
},
"path" : {
"type" : "keyword"
},
"request_method" : {
"type" : "keyword"
},
"server" : {
"type" : "keyword"
},
"status_code" : {
"type" : "long"
},
"timestamp" : {
"type" : "float"
},
"url" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
},
"user" : {
"type" : "keyword"
}
}
}
}
}
}
Wir können sehen, dass unsere Vorlage angewendet wurde und dass die von uns angegebenen Felder korrekt zugeordnet wurden. Da sich dieser Blogpost in der Hauptsache mit Logstash beschäftigt, haben wir hier das Thema „Zuordnungen und ihre Funktionsweise“ nur oberflächlich angekratzt. Weitere Informationen zu diesem wichtigen Thema finden Sie in der Dokumentation.
Fazit
In diesem Blogpost haben wir anhand der Entwicklung einer benutzerdefinierten Beispielkonfiguration, die anschließend erfolgreich an Elasticsearch gesendet wird, gezeigt, wie Sie optimal mit Logstash arbeiten können. Dabei wurde jedoch nur angerissen, was sich mit Logstash alles erreichen lässt. Sehen Sie sich die in diesem Blogpost verlinkten Dokumente und Blogposts an, aber vergessen Sie auch nicht, sich mit dem offiziellen „Erste Schritte“-Handbuch und all den Input-, Output- und Filter-Plugins zu beschäftigen, die zu Ihrer Verfügung stehen. Wenn Sie sich erst einmal einen Überblick darüber verschafft haben, was Logstash alles bietet, werden Sie es schnell nicht mehr missen möchten.
Wenn Sie Hilfe bei Problemen brauchen oder weitere Fragen haben, können Sie den Bereich „Logstash“ unseres Diskussionsforums nutzen. Und unter https://github.com/elastic/examples/ finden Sie weitere Beispieldaten und Logstash-Beispielkonfigurationen.
Happy Parsing!!!