事关呼吸:在 Elastic Cloud 上使用 Elasticsearch 分析空气质量数据
Elastic Stack 已经过验证,其能胜任数据收集、数据索引以及基于数据提取出有价值的信息等任务,然而这远非全部。集成信息管理不仅可行,而且正如我们在这一系列博文中所看到的,您轻轻松松便可搞定。我们将会带您完成整个过程,向您展示如何从毫无意义的原始数据得出所有现代城市居民均可用来改善日常生活的结论。
全球范围内主要城市的人口数量越来越大,这随之带来了很多问题。在这些问题中,空气污染可能算得上对居民健康有较大影响的问题之一了。为了对居民进行预警并采取紧急措施,某些公共机构已经部署了传感器场,这些传感器场会在全城各处收集不同污染物浓度的相关信息。
由于负责收集这些数据的是公共机构,所以通常这些数据会面向所有人发布,供大家使用。全球范围内很多城市都是这样做的,我们在此以欧洲最大城市之一(按人口计算,超过 300 万居民)举例进行说明,这座城市便是:马德里。
我们看一下,使用 Elasticsearch 来揭开这些神秘化学测量数据的面纱并了解马德里居民的日常习惯,竟然会如此简单。
将 CSV 文件转换为 Elasticsearch 文档
首先,我们需要看一下数据源。马德里市政厅目前维护着一个开源数据门户网站,访客在此网站上可找到按小时计的空气质量测量数据(西班牙语)。
我们在此可以找到一个提供 CSV 文件的 HTTP 接口,此文件每小时会更新一次,包含截至当天前一个小时的测量数据。
文件中的每一行对应一个(地点、化学污染物)键值对,并且包含全天逐小时的测量数据。每小时的测量值按列进行存储。
| ... | 监测站 | 化学污染物 | ... | 月 | 日 | 午夜 0 点 测量数据 | 午夜 0 点 是否有效? | ... | 晚上 11 点 测量数据 | 晚上 11 点 是否有效? |
| 数字(代码) | 代码(代码) | 数字 | 数字 | 数字 | “V”或“F”(真/伪) | 数字 | “V”或“F”(真/伪) |
诸如“监测站”和“化学污染物”等字段均为数值,分别对应着地理定位和化合物组成。彼此之间的关联详见数据源网站上的对照表。
另一方面,逐小时测量数据(上午/下午几点测量数据)和表明其是否有效的标记(上午/下午几点是否有效?)则提供的是原始值。单位在源网站上的另一个表格中提供,而验证标志的值可为“V”或“F”,分别代表“Verdadero”和“Falso”(西班牙语中的“真”和“伪”)。
化学污染物取样结果以特定地点特定时间的测量结果表示。这是不是让您想起了什么?对啦:空间活动的时序数据!这意味着数据表中的行并不表示活动。相反,每行最多包含 24 个活动,所有这些都是来自于同一地点且关于同一化学成分的活动。
如果我们将每个活动都编码成 JSON 文档,将会如下面的例子所示:
{
"timestamp":1532815200000,
"location": {
"lat":40.4230897,
"lon": -3.7160478
},
"measurement": {
"value":7,
"chemical":"SO2",
"unit": "μg/m^3"
}
}
我们还可以选择用世界卫生组织 (WHO) 限值来轻松地丰富数据,只需在测量数据子文档中添加一个额外字段即可。将 CSV 文件中的每行分解为单独的 JSON 文档之后,这些数据理解起来会简单一些,Elasticsearch 采集这些数据的过程也会变得更加轻松。
{
"timestamp":1532815200000,
"location": {
"lat":40.4230897,
"lon": -3.7160478
},
"measurement": {
"value":7,
"chemical":"SO2",
"unit": "μg/m^3",
"who_limit":20
}
}
与此结构匹配的所有文档集合可以使用另外一种 JSON 文档来描述。这是 Elasticsearch 中的一个映射表,我们会用其来描述文档在给定索引中的存储过程。
{
"air_measurements": {
"properties": {
"timestamp": {
"type": "date"
},
"location": {
"type": "geo_point"
},
"measurement": {
"properties": {
"value": {
"type": "double"
},
"who_limit": {
"type": "double"
},
"chemical": {
"type": "keyword"
},
"unit": {
"type": "keyword"
}
}
}
}
}
}
在 Elastic Cloud 上部署集群,秒秒钟搞定
现在,您既可在本地设置 Elasticsearch 集群,也可在 Elastic Cloud 上免费试用 14 天的 Elasticsearch Service。只需轻点几下鼠标,即可快速部署新集群,欢迎了解详情。在本演示中,我将会使用 Elastic Cloud。
登录到 Elastic Cloud 中后,您需要部署一个新集群。至于此用例的集群规模,鉴于单个月的 JSON 测量数据活动文件大约需要占用 34 MB 的磁盘空间(索引之前),我们可以使用提供的最小集群(1 GB 内存/24 GB 磁盘空间)。这个小型集群在初期应该足以容纳我们的数据。通过 Elastic Cloud,您可以轻松地进行扩展,所以您之后无论何时都可以根据需要扩大规模,也可以更改可用区域的数量,还可在集群上进行一些其他变更。
连用微波炉热个菜的时间都不到,我们便将 Elasticsearch 集群部署完毕了,可通过此集群接收测量活动数据集合并进行索引。
提取、转换和加载
在将原始 CSV 文件转换为 JSON 文档集合的过程中,相信没有人任何人希望手动对这些测量数据进行编码(这听起来有点像永远没有尽头的惩罚)。这项任务需要实现自动化。
为此,我们开始编写一个自动化脚本来将 CSV 表格转换为 JSON 文档吧。我们不妨使用 Scala 来进行转换,原因如下:
下面是 extractor.sc 脚本的片段,其中便浓缩了转换逻辑:
// Fetch the file from Madrid's city hall open data portal
lazy val sourceLines = scala.io.Source.fromURL(uri).getLines().toList
sourceLines.headOption foreach { head =>
/* The CSV first line contains the columns labels, it is not difficult
to compute a map from label to position thus making the rest of the code
more readable. */
lazy val label2pos = head.split(";").zipWithIndex.toMap
// For each line, we'll produce several events, that's easilt via flatMap
lazy val entries = sourceLines.tail flatMap { rawEntry =>
val positionalEntry = rawEntry.split(";").toVector
val entry = label2pos.mapValues(positionalEntry)
/* The first 8 positions are used to extract the information common to the
24 hourly measurements. */
val stationId = entry("ESTACION").toInt
val ChemicalEntry(chemical, unit, limit) = chemsTable(entry("MAGNITUD").toInt)
// Measurement values are contained in the 24 last columns
positionalEntry.drop(8).toList.grouped(2).zipWithIndex collect {
case (List(value, "V"), hour) =>
val timestamp = new DateTime(
entry("ANO").toInt,
entry("MES").toInt,
entry("DIA").toInt,
hour, 0, 0
)
// And there it go:The generated event as a case class!
Entry(
timestamp,
location = locations(stationId),
measurement = Measurement(value.toDouble, chemical, unit, limit)
)
}
}
- 获取最新发布的逐小时报告,此报告中包括最近一小时前采集的测量数据。
- 对于每行:
- 提取基于行数据而生成的全部活动的通用字段,即监测站 ID 和所测化学污染物。
- 提取与当天截至目前(最大为 24)所收集内容对应的测量数据。将未标记为有效的测量数据滤掉。
- 对于这些内容,生成测量数据时间戳,组成部分包括行日期和测量数据列的编号。将行通用字段、时间戳和注册值整合为一个单一活动对象(条目)。
脚本会继续将条目对象作为 JSON 文档进行序列化操作,并将其作为一系列独立的 JSON 进行打印。
当一次性上传全天的文件时,Extractor.sc 可以接收参数以指示其从诸如本地文件等其他数据源获取需转换的数据,或者指示其添加 Elasticsearch 的 Bulk API 所需的操作。
extractor --uri String (default http://www.mambiente.munimadrid.es/opendata/horario.csv) --bulkIndex --bulkType
将数据上传至 Elasticsearch
所以我们拥有了可以将 CSV 文件转换为文档列表的脚本。如何对它们进行索引呢?很简单,我们只需调用几次集群便可以了。
创建索引
重要的事情当然要先做:我们需要创建索引。我们已经针对文档映射编写了 JSON,所以可以将其嵌入到我们的索引定义中:./payloads/index_creation.json。
{
"settings" : {
"number_of_shards" :1
},
"mappings" : {
"air_measurements" : {
"properties" : {
"timestamp": { "type": "date" },
"location" : { "type" : "geo_point" },
"measurement": {
"properties": {
"value": { "type": "double" },
"who_limit": { "type": "double" },
"chemical": { "type": "keyword" },
"unit": { "type": "keyword" }
}
}
}
}
}
}
然后将其传输到我们集群的索引创建接口:
curl -u "$ESUSER:$ESPASS" -X PUT -H 'Content-type: application/json' \
"$ESHOST/airquality" \
-d "@./payloads/index_creation.json"
之后,我们就可以得到 airquality(空气质量)索引了。
批量上传
将数据上传至 Elasticsearch 的最快捷方法是使用 Bulk API。我们的想法是建立连接,上传文件包,并完成操作。 如果每次只上传一个文档,我们必须对 CSV 文件中每行的每个测量数据均建立 TCP 连接,发送文档,接收确认,并关闭连接,这工作量简直太大啦!对我来说,这效率有些太慢了。
如 Bulk API 文档所描述的那样,您需要上传一个 NDJSON 文件,其中每个文档包括两行命令:
- 第一行是需要在 Elasticsearch 中完成的操作
- 第二行则是该操作所影响的文档。我们现在感兴趣的操作是索引。
因此,extractor.sc 包括两个额外选项来控制索引操作以及控制是否让其直接出现在每个文档的前面。
- bulkIndex 索引 — 如果通过,其会通过索引到 INDEX (index into INDEX) 操作将提取脚本置于每个文档的前面。
- bulkType 类型 — 如果在 bulkIndex 之后通过,会针对文档应当匹配的类型完成索引操作。
/* The collection of events is then serialized and printed in the standard ouput.
That way, we can use them as a ndjson file.
*/
val asJsonStrings = entries flatMap { (entry:Entry) =>
Some(bulkIndex).filter(_.nonEmpty).toList.map { index =>
val entryId = {
import entry._
val id = s"${timestamp}_${location}_${measurement.chemical}"
java.util.Base64.getEncoder.encodeToString(id.getBytes)
}
/* Optionally, we can also serialize bulk actions to improve data transfer
performance. */
BulkIndexAction(
BulkIndexActionInfo(
_index = index,
_id = entryId,
_type = Some(bulkType).filter(_.nonEmpty)
)
).asJson.noSpaces
} :+ entry.asJson.noSpaces
}
asJsonStrings.foreach(println)
通过这种方式,我们能够使用全天的所有条目生成超大的 NDJSON 文件:
time ./extractor.sc --bulkIndex airquality --bulkType air_measurements > today_bulk.ndjson
仅用时 1.46 秒,其便生成了可发送到 Bulk API 的文件,如下所示:
time curl -u $ESUSER:$ESPASS -X POST -H 'Content-type: application/x-ndjson' \
$ESHOST/_bulk \
--data-binary "@today_bulk.ndjson" | jq '.'
完成上传请求仅用时 0.98 秒。
采用此方法的话,仅用时 2.44 秒(1.46 秒用来获取和转换数据,0.98 秒用来完成批量上传请求),相比每次只上传一个文档,速度快了 182 倍。没错,2.44 秒与 7 分 26 秒的差距!
这里需要记住的重点是:如需对较大数量的文档进行索引,请务必使用批量上传完成这一过程!
从数据转变为洞察
恭喜您!我们现在已经在 Elasticsearch 中成功建立了城市空气测量数据索引。这意味着,举例说明,相比下载、提取并手动搜索我们需要的信息,我们搜索和获取数据的过程会轻松得多。
以下面这件事为例进行说明,假设我们已经欣赏完西班牙名画《宫女》,接下来需要决定前往何处:
- 到马德里的户外享受灿烂晴空
- 继续在普拉多博物馆欣赏其他文物
我们可以询问 Elasticsearch 哪种方案更加有利于我们的健康,让它告诉我们附近 1 公里范围内最近的气象监测站最新测量的二氧化氮浓度是多少:./es/payloads/search_geo_query.json
{
"size":"1",
"sort": [
{
"timestamp": {
"order": "desc"
}
},
{
"_geo_distance": {
"location": {
"lat":40.4142923,
"lon": -3.6912903
},
"order": "asc",
"unit": "km",
"distance_type": "plane"
}
}
],
"query": {
"bool": {
"must": {
"match": {
"measurement.chemical":"NO2"
}
},
"filter": {
"geo_distance": {
"distance":"1km",
"location": {
"lat":40.4142923,
"lon": -3.6912903
}
}
}
}
}
}
curl -H "Content-type: application/json" -X GET -u $ESUSER:$ESPASS $ESHOST/airquality/_search -d "@./es/payloads/search_geo_query.json"
然后便会收到下面的答案:
{
"took":4,
"timed_out": false,
"_shards": {
"total":1,
"successful":1,
"skipped":0,
"failed":0
},
"hits": {
"total":4248,
"max_score": null,
"hits": [
{
"_index": "airquality",
"_type": "air_measurements",
"_id": "okzC5mQBiAHT98-ka_Yh",
"_score": null,
"_source": {
"timestamp":1532872800000,
"location": {
"lat":40.4148374,
"lon": -3.6867532
},
"measurement": {
"value":5,
"chemical":"NO2",
"unit": "μg/m^3",
"who_limit":200
}
},
"sort": [
1532872800000,
0.3888672868035024
]
}
]
}
}
告诉我们丽池公园 (El Retiro) 气象监测站报告的二氧化氮浓度为 5 μg/m^3。鉴于世界卫生组织 (WHO) 给出的限值是 200 μg/m^3,空气质量不错,所以我们出去吃点小菜吧!
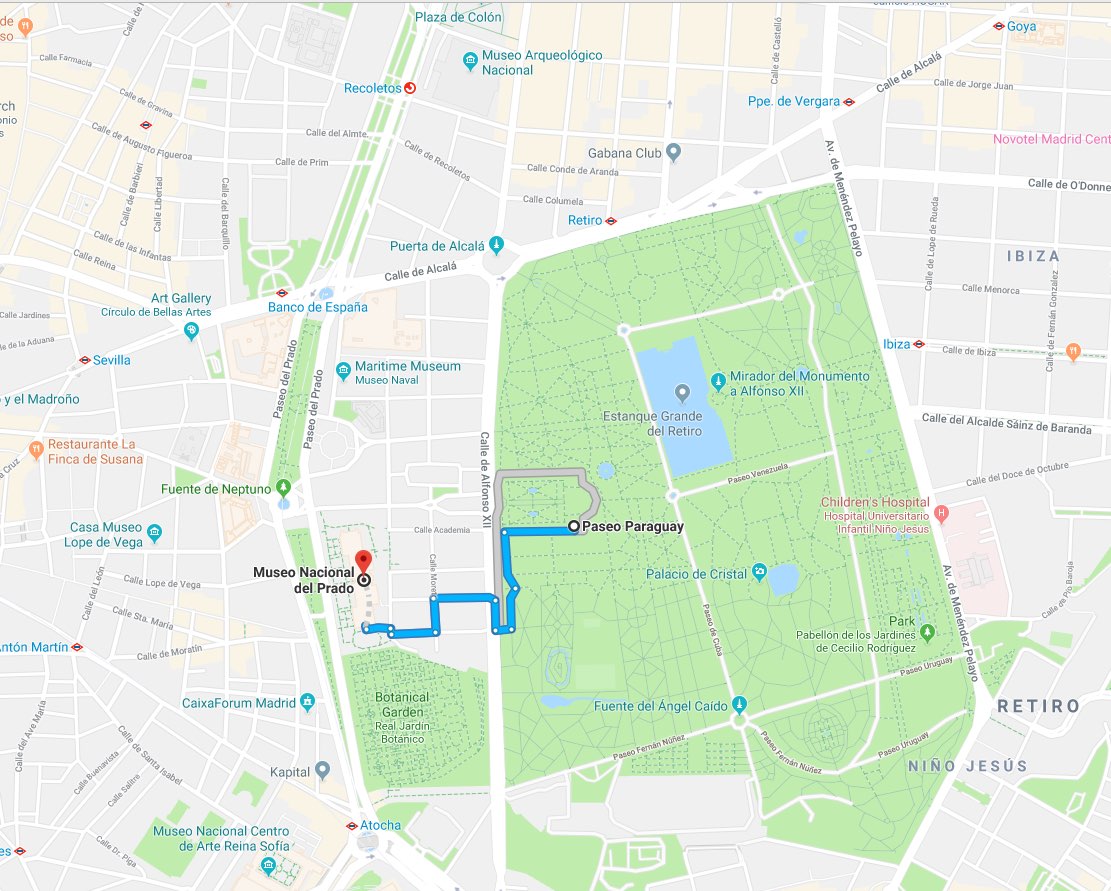
坦白讲,我还从没看到过有人在博物馆内拿出笔记本电脑并开始写 cURL 命令呢。但是不管怎么讲,由于可以无比轻松地对这些请求进行编码,而且几乎可以使用任何编程语言,所以在短短几天内便可推出前端应用程序。那也同时意味着,我们已经拥有完善的分析后端以及信息索引。
在 Kibana 中对隐形数据实现可视化
如果根本无需编写应用程序,该有多好啊!对于现有集群,如果只需一直点击鼠标便可开始探索数据并得出深刻洞见,又该有多好啊!借助 Kibana,这一切均完全有可能。我们可以前往集群管理 (cloud.elastic.co),然后点击链接即可获取 Kibana 部署的访问权限:
有了 Kibana,我们便可以基于 Elasticsearch 中所索引的文档创建综合性可视化图形和仪表板。
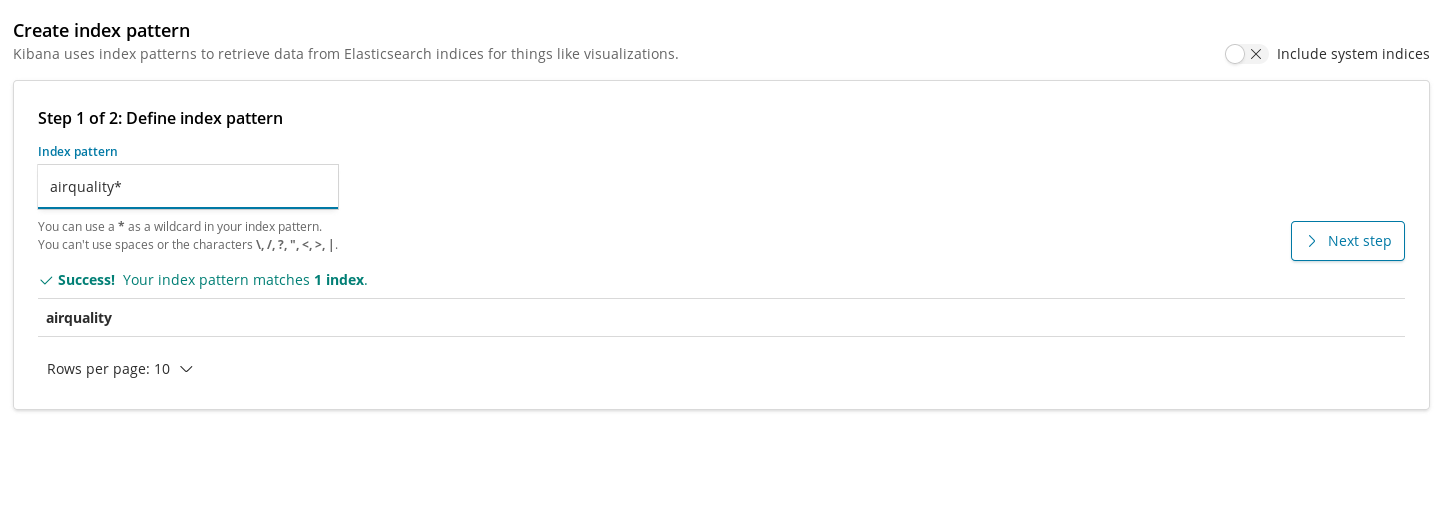
我们必须通过索引模式来将索引注册到 Kibana 中,进而可视化图形才可利用这些索引来抽取数据。因此,在为我们的 airquality (空气质量)索引创建图表之前,第一步是注册索引。
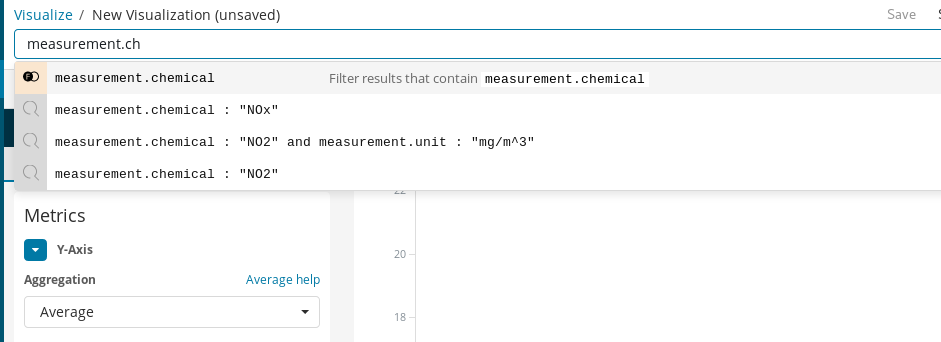
创建完后,我们便可添加第一个可视化图形。我们先从简单的图形开始:在全城范围内,画出某种化学污染物的平均浓度随时间变化的情况。我们这里以二氧化氮为例:
首先,我们需要创建一个线状图,其中 Y 轴是 measurement.value 字段的平均浓度,而 X 轴则是各个时段。要选择目标化学污染物,我们可以使用 Kibana 的搜索栏很轻松地筛选出二氧化氮的测量数据,然后通过启用 autocomplete(自动完成)功能,我们可以得到一系列建议来引导我们完成查询定义过程。
最后,我们通过时间范围来选择可视化数据的时间跨度。
点击几下之后,立即可得到下面的结果:
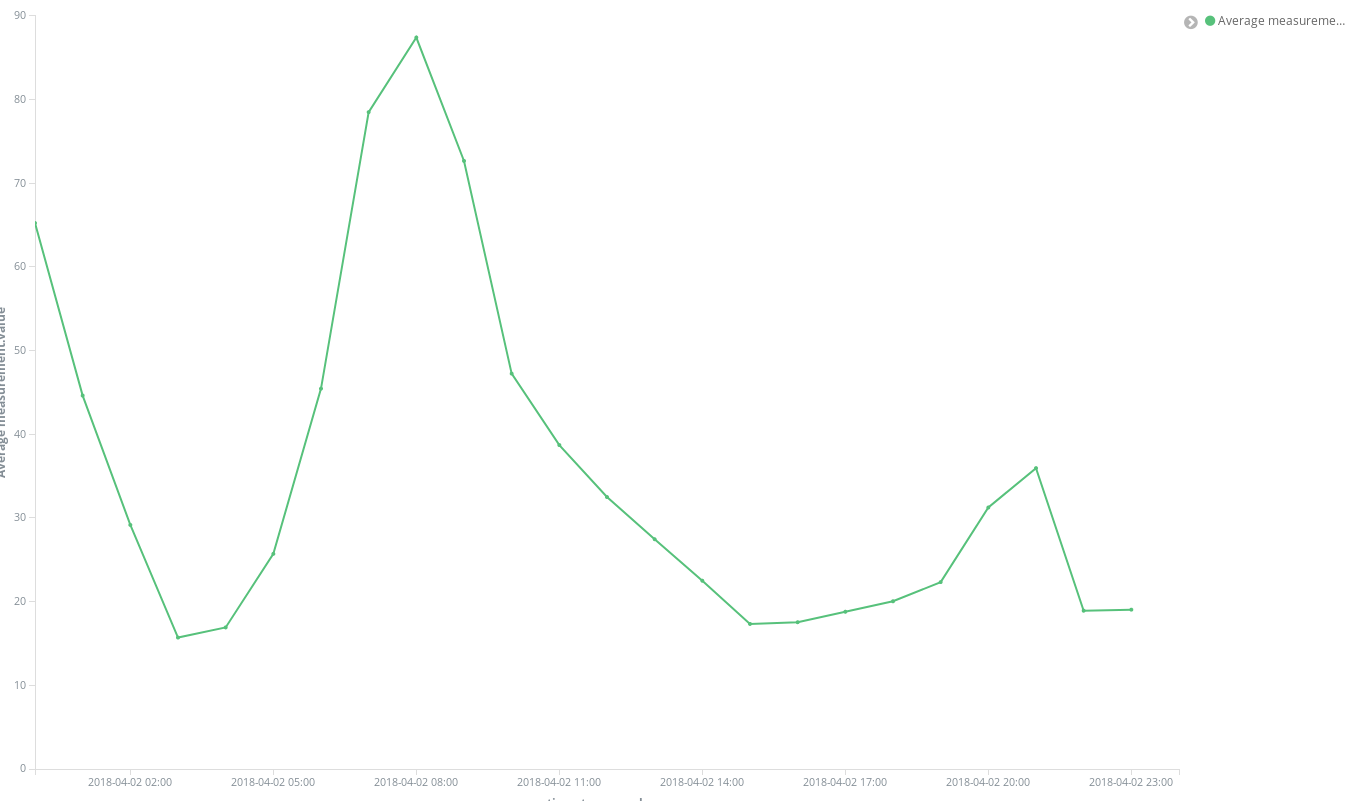
使用这一数据集我们还可以制作更加深入的图形,例如坐标地图。每个测量数据都提供了采集此数据的监测站的坐标,所以我们可以绘制出污染热点。也就是,我们需要从对各时段的空间条目取平均值转换为对各空间地点的时间条目取平均值。所以,存储桶现在为基于地点(包含测量点的字段)的 Geohash 汇总数据。
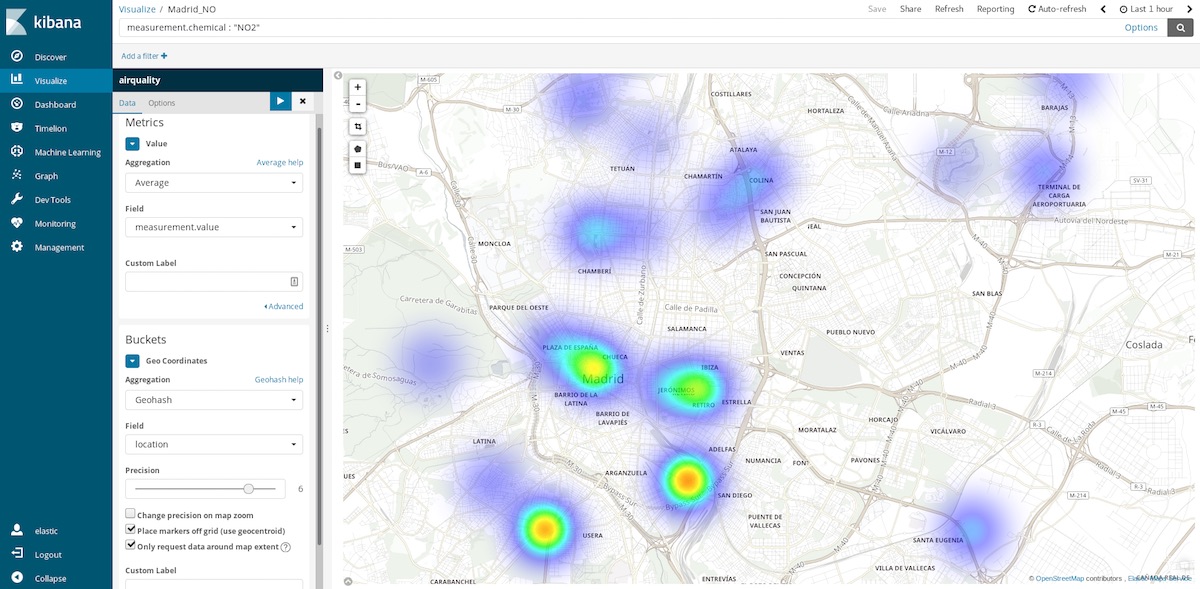
如果将时间范围确定为过去一个小时,我们便可以了解现在适宜前往哪些空气比较洁净的地方。如果将时间范围调整为每年,我们则可以知道哪些地方的空气平均而言更加洁净,从而帮助我们做出各项决定,例如在何处购房以享受更健康的生活。
脚本字段
因为我们的文档中还包括某些化学污染物的 WHO 推荐水平,所以我们还能够对空气的健康程度进行可视化。有多种方式可以实现这一效果,其中一种便是基于所测量水平与 WHO 限值之间的比值来绘制仪表盘可视化图形。但是,我们在上传数据时并不会进行这一除法运算。这完全不是问题,因为我们仍然能够使用 Painless 脚本语言在已索引字段的基础上生成新字段;对于使用过 Java 的任何用户而言,Painless 是一种十分容易理解和编写的语言(从 Kibana 6.4 开始,用户还能够预览 Painless 脚本所生成的结果)。
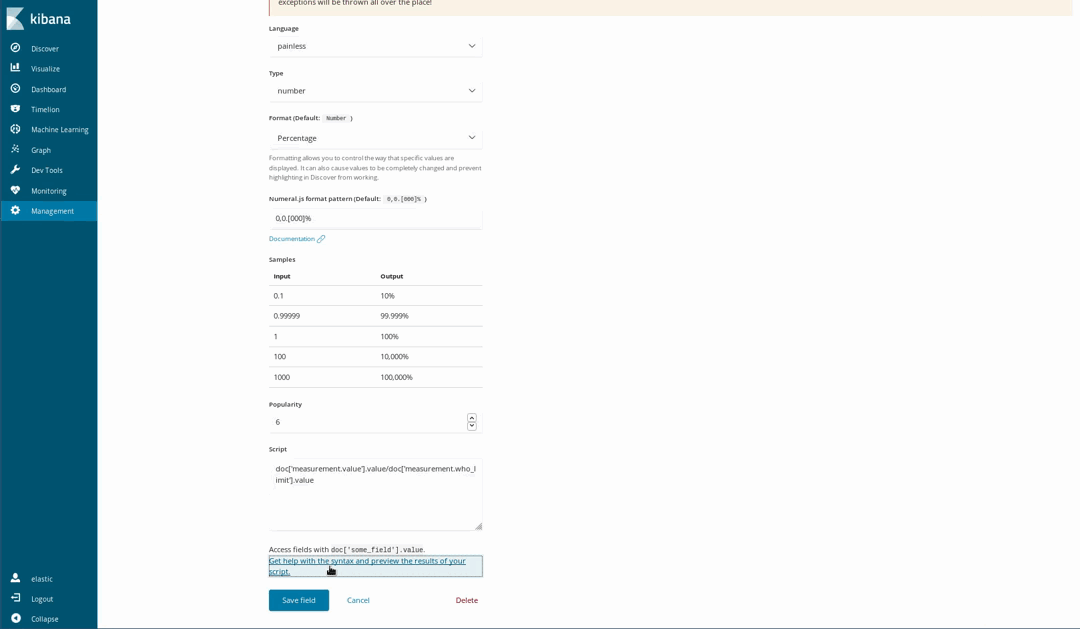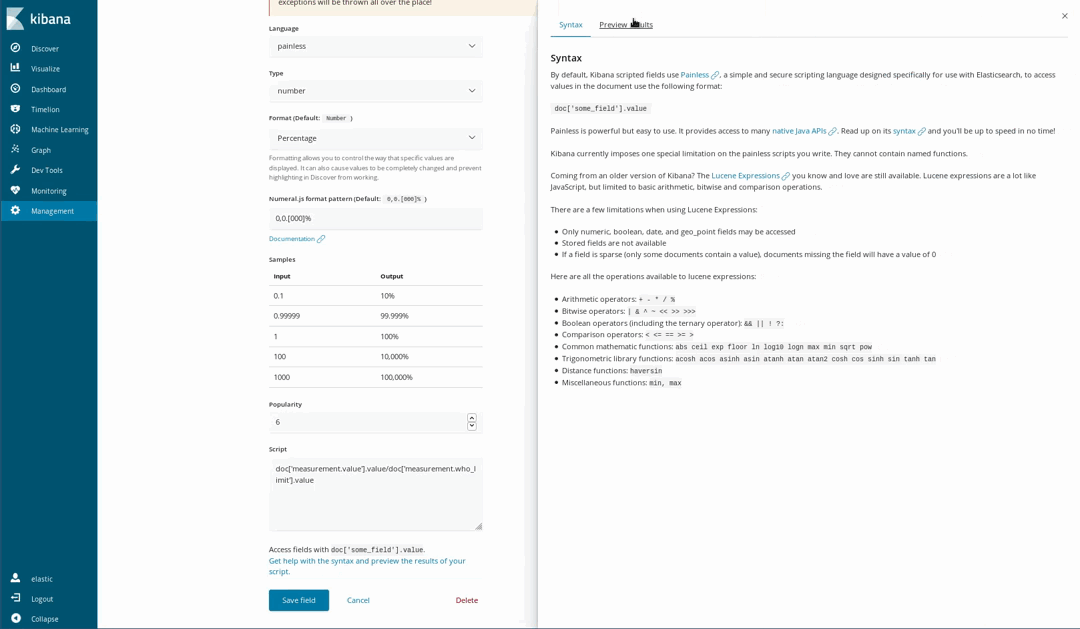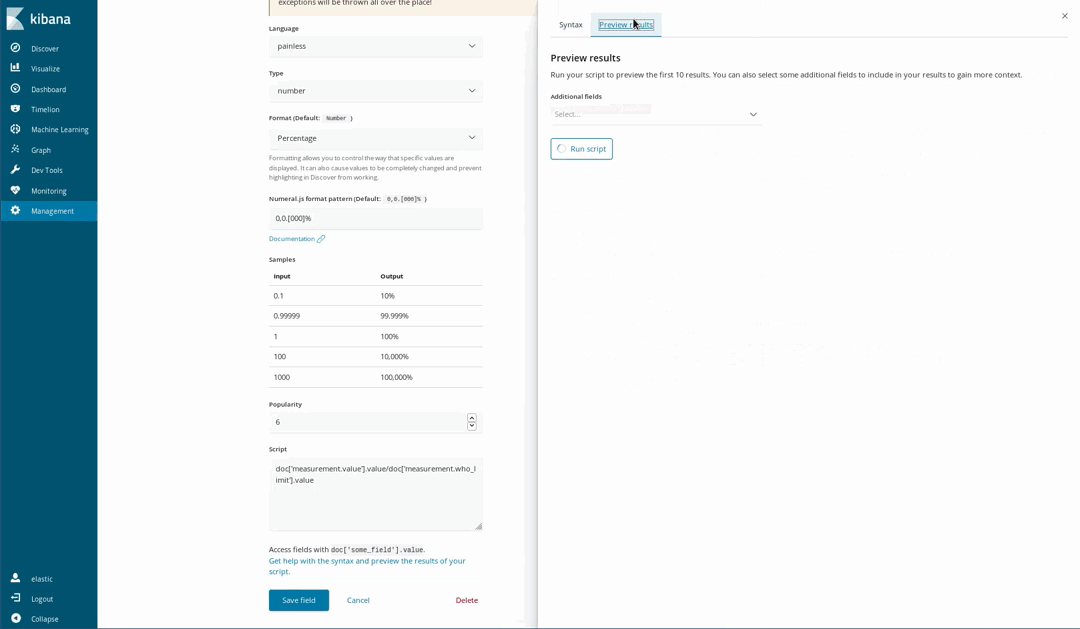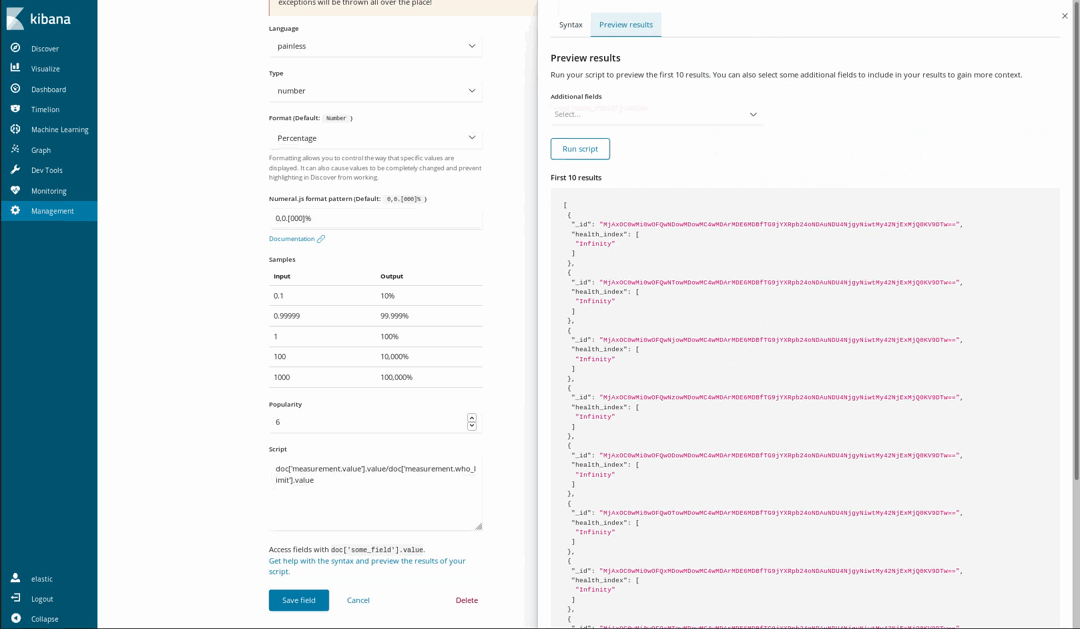
然后,我们便可在可视化图形中使用这些新生成的字段了,与使用其他已索引字段没有区别。
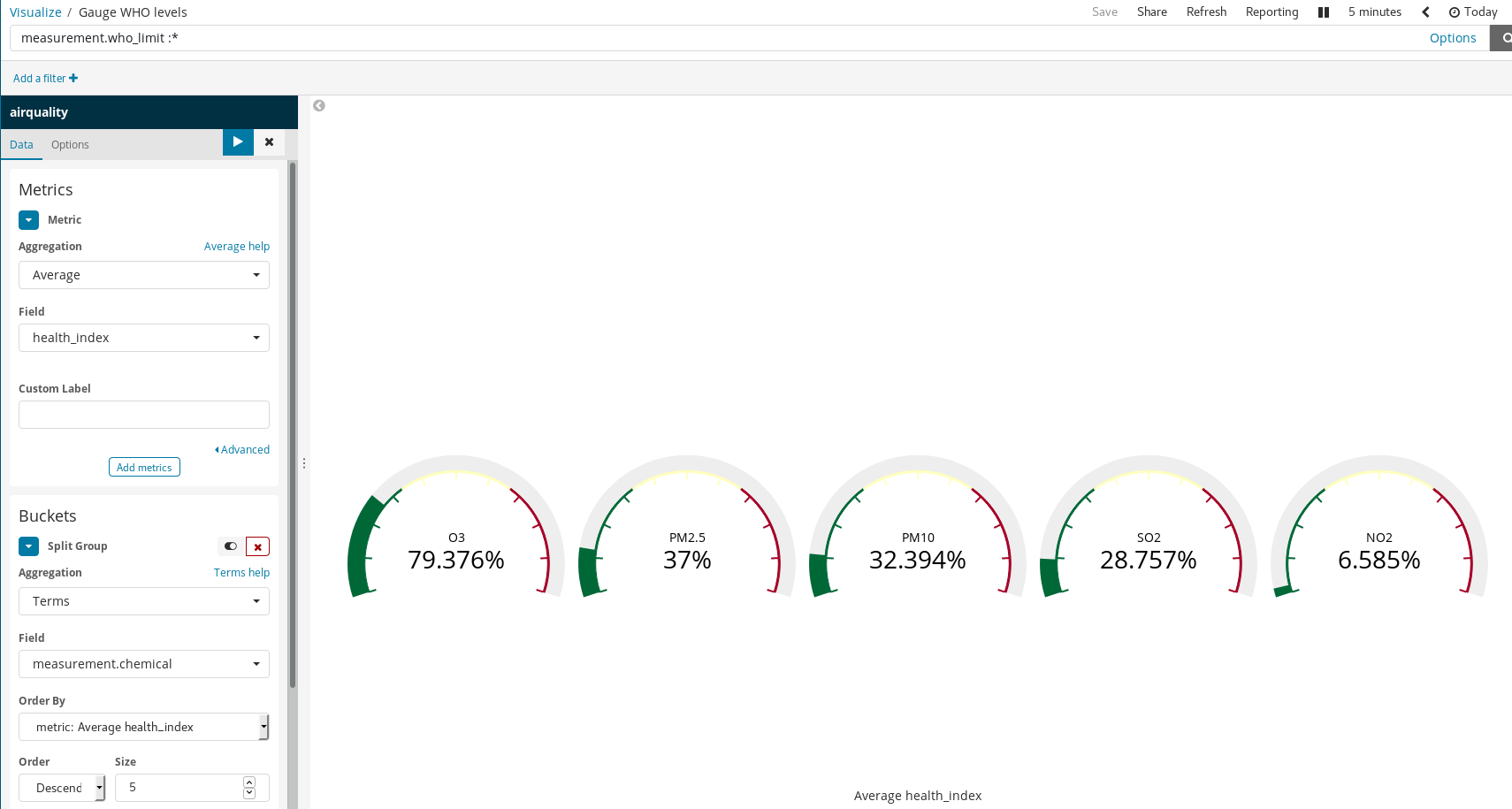
还有一点需要您注意,即如何使用简单规则在 Kibana 中生成丰富的可视化图形。在上面的示例中,我们进行了下列操作:
- 筛选了文档 — 仅选择有 WHO 限值的那些文档。
- 针对
measurement.chemical使用了“拆分群组”和“术语聚合”功能。
因此,便针对每种有 WHO 限值的化学污染物生成了仪表板图。
了解一下马德里的空气污染情况
我们可以使用 Kibana 可视化图形来创建仪表板,由于仪表板是可视化图形的聚合,所以是实时解读和理解系统状态的关键所在。这个例子所涉及的系统是大气组成以及其与人类活动之间的相互关系。
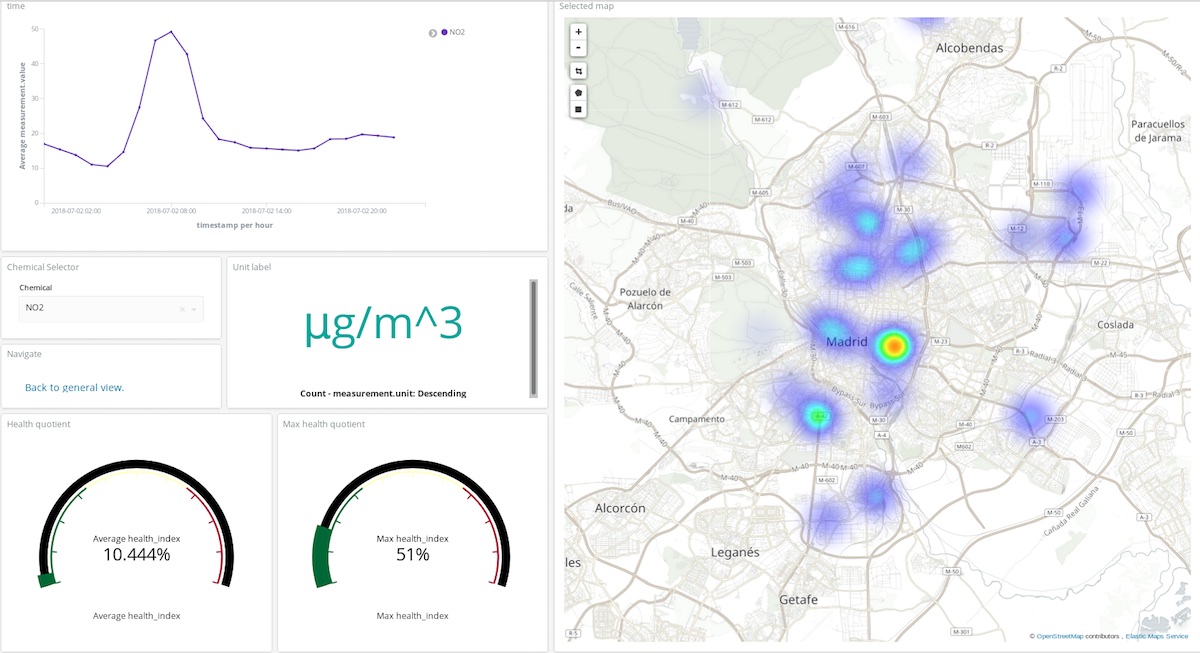
在上面的仪表板中,用户可以选择任何化学污染物和时间段,以便充分了解此种污染大气的复合物在任何地方的浓度。赶快来亲自动手尝试一下吧!(用户名:test;密码:madrid_air)
我们还能够从整体上了解(仍是上面的用户名和密码)马德里的空气质量。
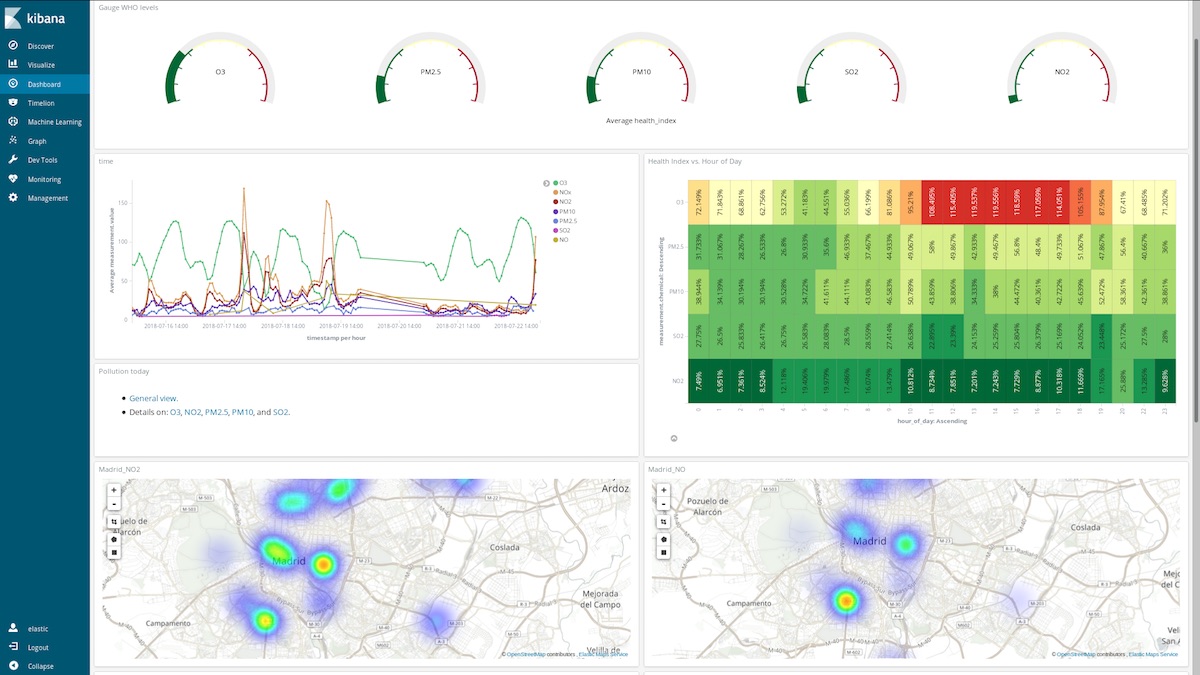
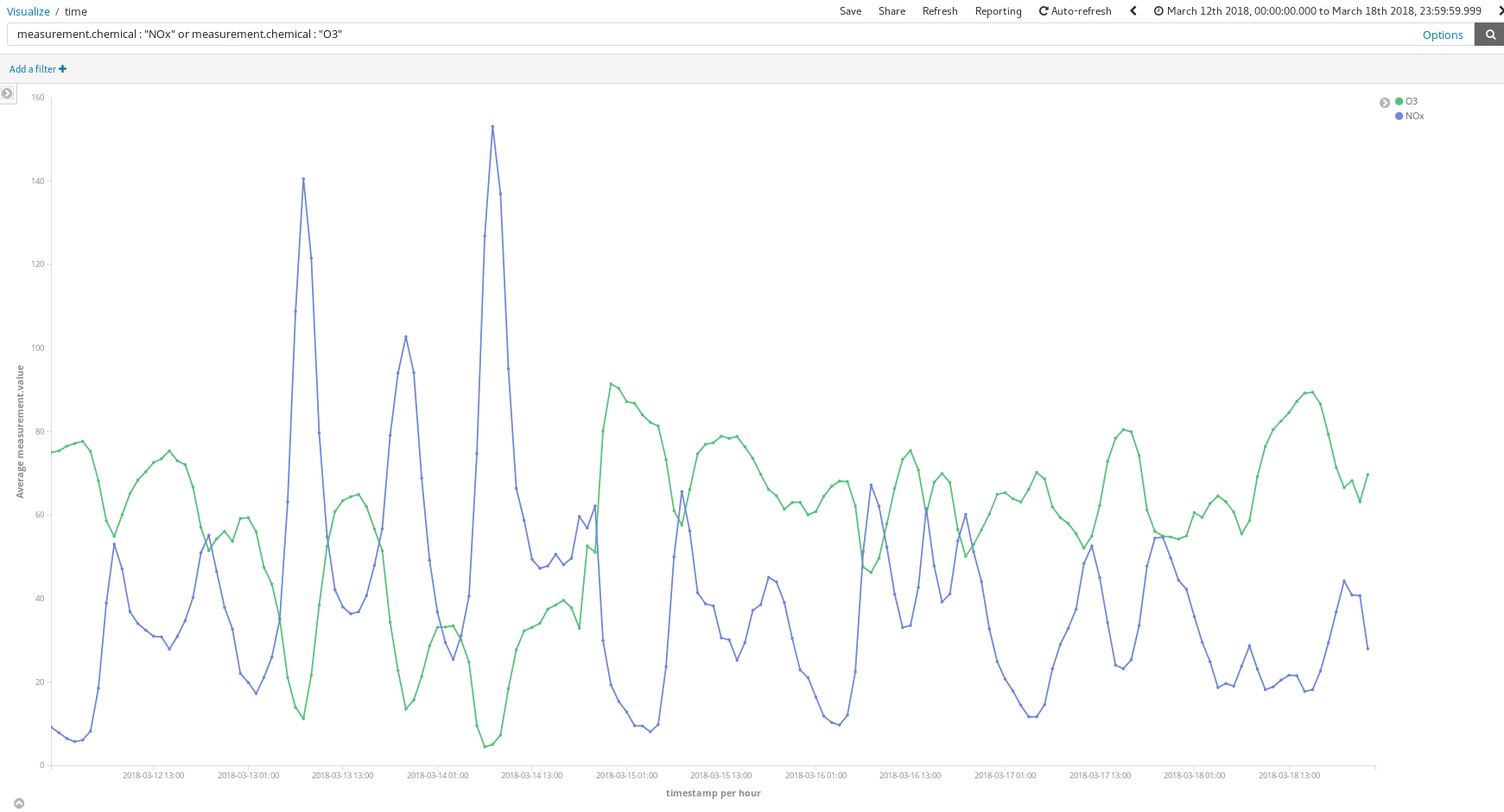
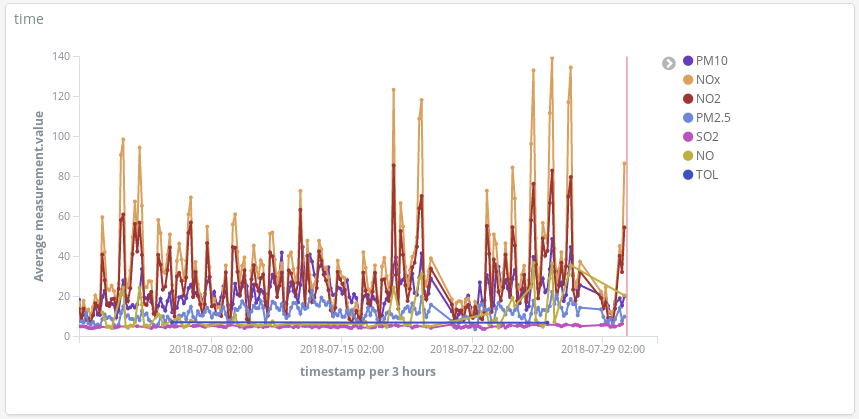
这些仪表板有哪些帮助作用呢?让我们随便看一下 3 月份某一周的数据(从 3 月 12 日到 3 月 18 日):
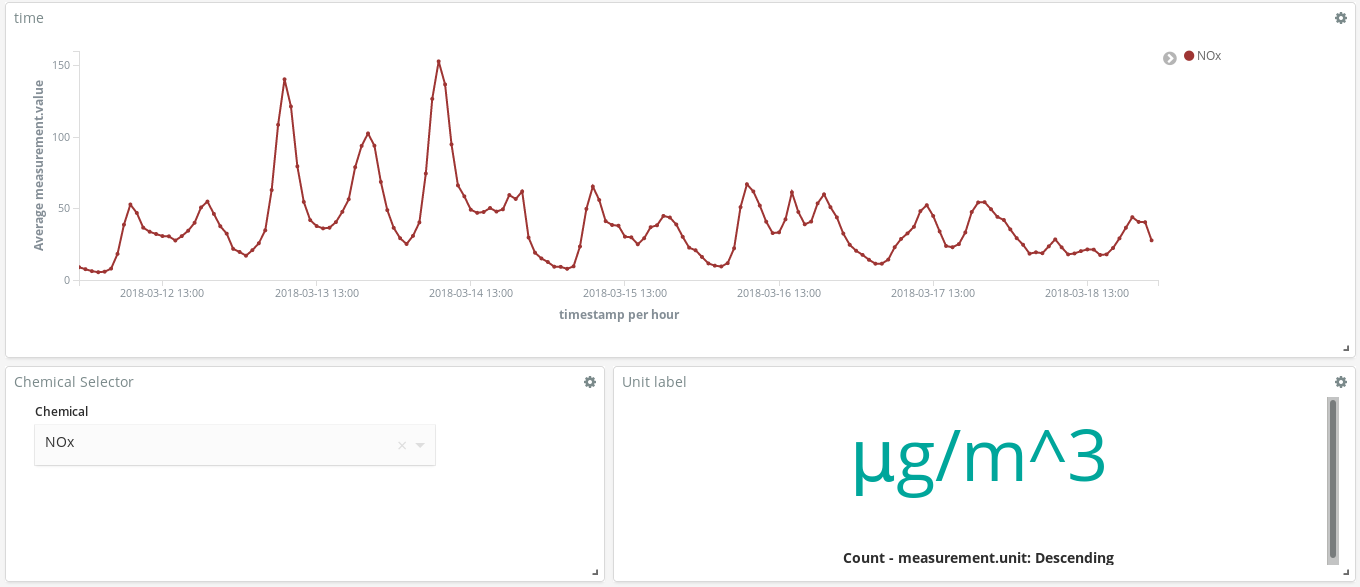
这些氮氧化物(柴油内燃机产生的一种化合物)波峰是否能够告诉我们马德里市民的一些生活习惯呢?是的,它们的确能。它们每天出现两次……
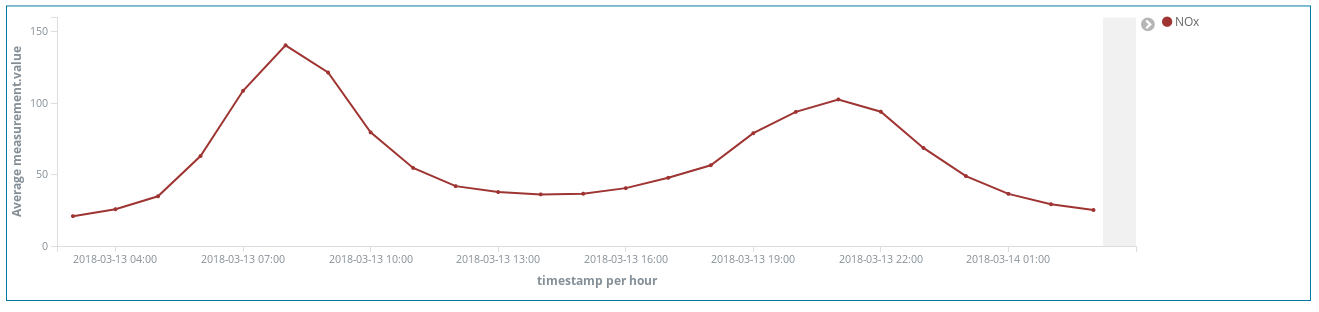
第一次是在早上 8 点(欧洲中部夏令时间),第二次是在晚上 9 点(欧洲中部夏令时间)。我们从这里可以看出,在人们早上上班的时候,全城柴油车的使用数量增加。但在正常工作时间内,却几乎没人使用柴油车,当人们结束一天的工作往家赶时,又出现了一个雾霾高峰。
还有一点很有意思,就是臭氧浓度提高的同时,氮氧化物的浓度会下降。臭氧是氮氧化物和有机化合物在阳光作用下经过化学反应生成的一种副产物,所以氮氧化物和臭氧之间的相关性也就不足为奇了。
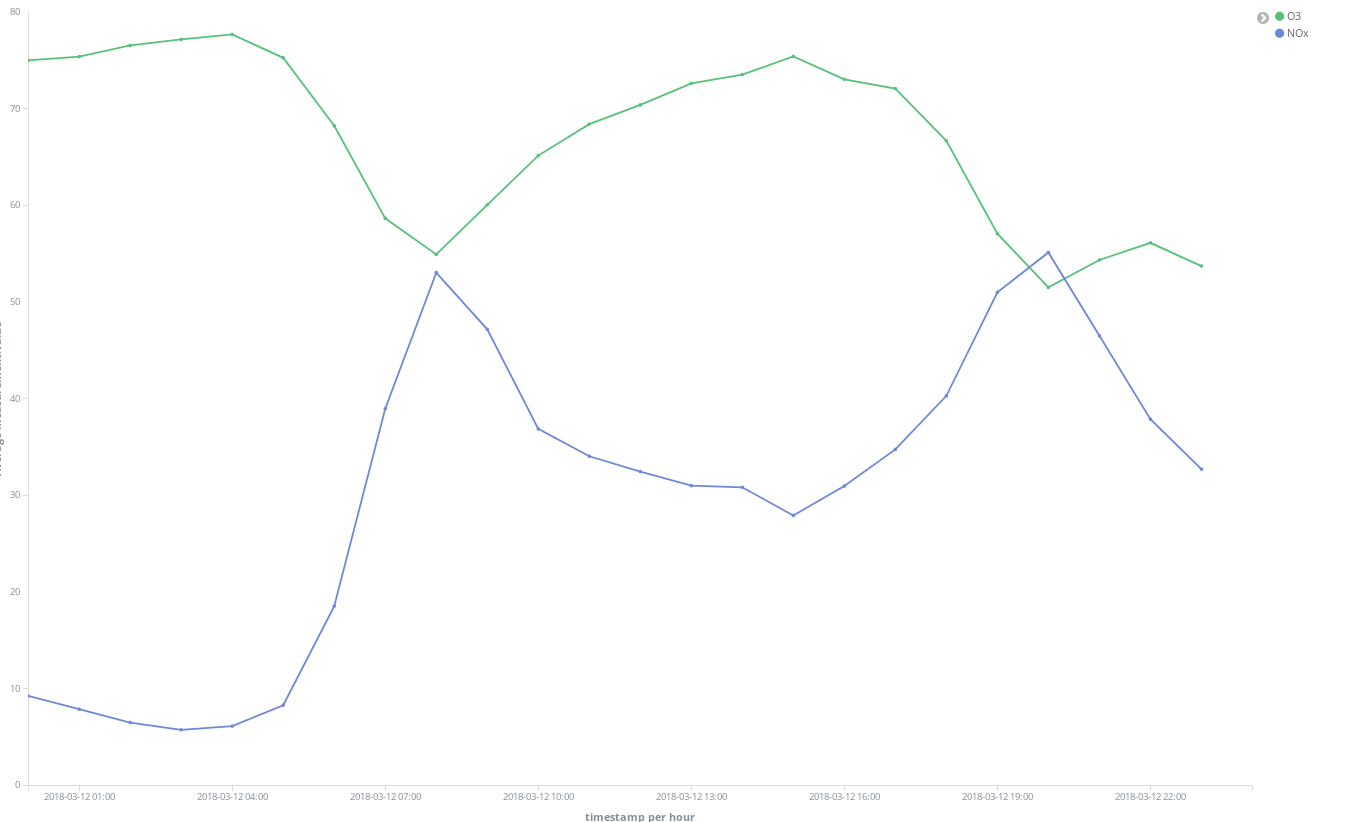
我们还可以看到周末的整体情况会有所改善。
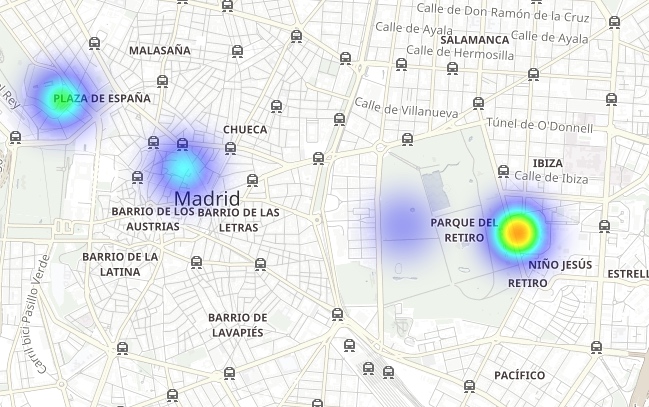
看一下丽池公园(El Retiro,马德里市中心一片巨大的绿化区域),尽管公园周围有很多氮氧化物排放热点,但是公园地区的排放量却较低,这是因为公园附近植被繁茂,且车流量少。
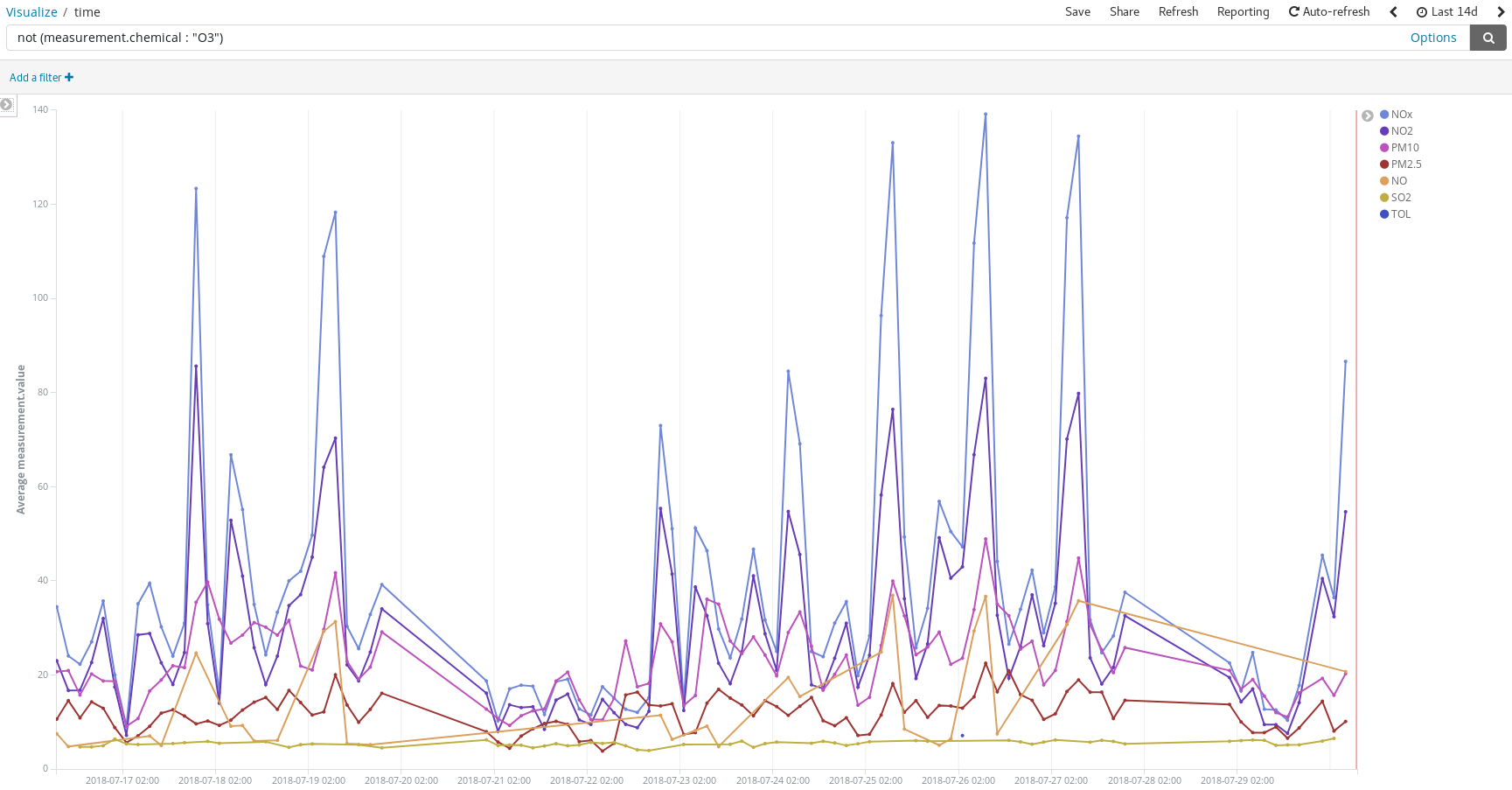
在人们通常驾车出外度假的日子检测污染物峰值:
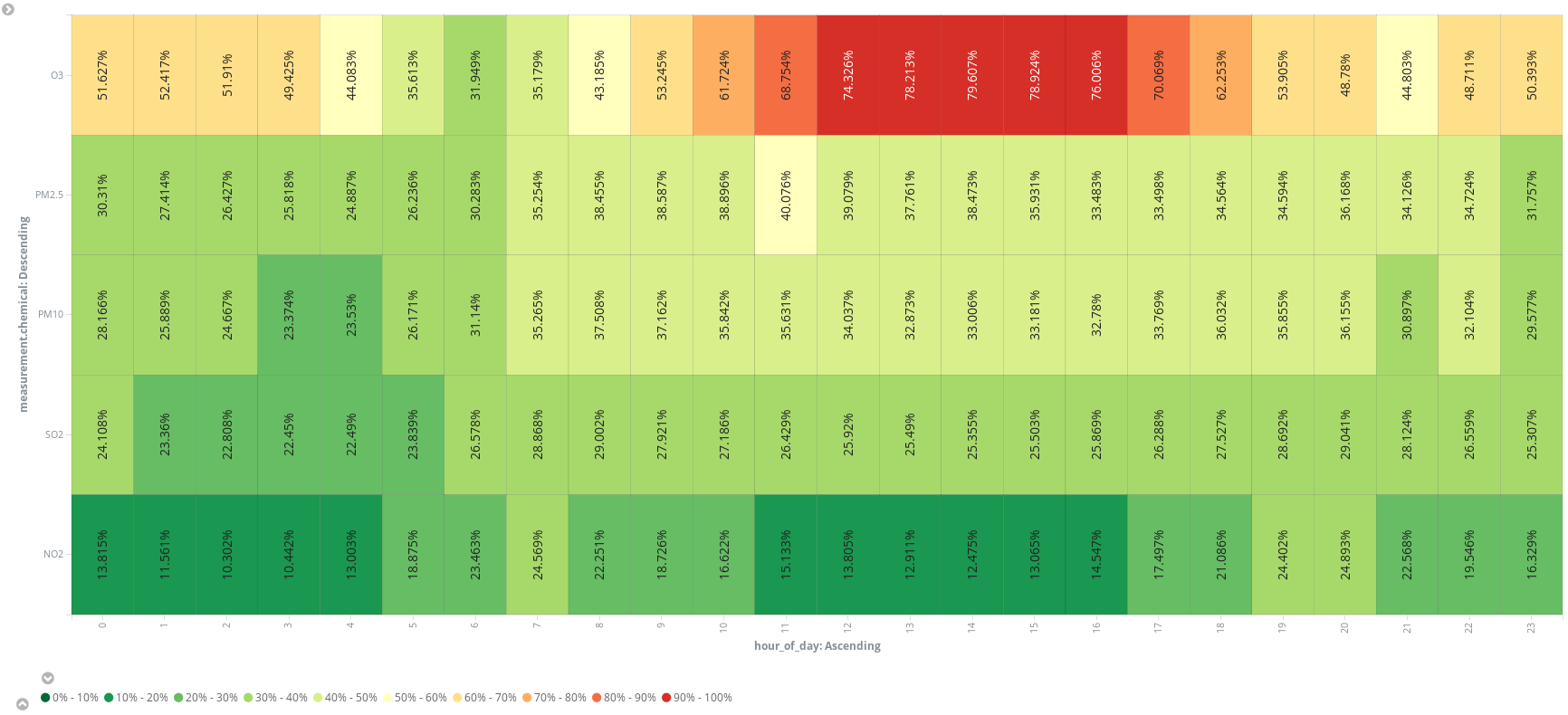
或者再添加一个脚本字段 (hour_of_day),将各个小时的条目均添加到存储桶中,从而在热点图上按照化学污染物显示平均测量数据。我们可以看出,早上 6 点是跑步的最佳时间段。
最后,我们十分确信,空气中不只有氮气、氧气、二氧化碳、氩气和水分。绝对不是!当我们徜徉于马德里格兰大道 (Gran Via) 时,我们呼入身体的不仅仅是空气。在曼哈顿游览时很可能也是这样的情形,是不是想亲自确认一下了呢?您现在已经知道怎么做了,只要有开放数据源,便能开始着手啦。
结论
如果我们是数据工程师,现在有人要求我们为公司的数据科学工作者提供一款工具来帮助他们分析马德里的空气污染水平,我们只需要在 Kibana 内注册空气质量 索引模式,将访问链接通过电子邮件发送给他们,让他们随心所欲地发挥创意,便大功告成啦!Elastic Stack 提供全套的分析堆栈,能够让您在分分钟内获得答案,而且使用特别直观,您需要编写的唯一代码就是脚本化字段(而且只在必要时才需编写哦)。
有了 Elastic Cloud,作为数据工程师,我们的任务得到了大大简化,只需点击几下鼠标,并编写提取、转换和加载 (ETL) 服务,便万事大吉了。但是,我们真的需要编写 ETL 才能获取数据并将数据添加到 Elasticsearch 中吗?下一篇博文中我们将会向您展示 Elastic Stack 也可以胜任这部分工作。