将 Spring Boot 与 Elastic App Search 结合使用


 Share on Twitter
Share on Twitter在 Twitter 上分享

 Share on LinkedIn
Share on LinkedIn在 LinkedIn 上分享

 Share on Facebook
Share on Facebook在 Facebook 上分享

 Share by Email
Share by Email通过邮件分享

 Print this page
Print this page打印
在本文中,我们将介绍如何从零开始构建完全运行的 Spring Boot 应用程序来查询已事先爬取网站内容的 Elastic App Search。我们将逐步启动集群并配置该应用程序。
快速启动集群
为了遵循示例,最简单的方法是克隆示例 GitHub 存储库。它可以让您直接运行 terraform,从而立即就能完成部署并开始运行。
git clone https://github.com/spinscale/spring-boot-app-search为部署并运行示例,我们必须按照 Terraform 提供程序设置中所述,在 Elastic Cloud 中创建一个 API 密钥。
这些准备工作完成后,运行以下代码:
terraform init
terraform validate
terraform apply然后在正式工作开始前喝杯咖啡。几分钟后,您应该会看到您的实例在 Elastic Cloud UI 中完成部署并运行起来,如下图所示:
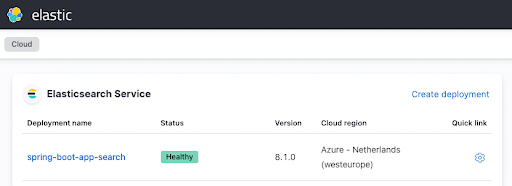
配置 Spring Boot 应用程序
在继续之前,我们先来确保可以构建并运行该 Java 应用程序。您只需要安装 Java 17,就可以继续运行以下代码:
./gradlew clean check此操作会下载所有依赖项并运行测试,然后失败。这是意料之中的,因为我们还没有将任何数据编入 App Search 实例的索引中。
在此之前,我们必须更改配置并为一些数据编制索引。首先,通过编辑 src/main/resources/application.properties 文件来更改配置(下面的代码片段只显示需要更改的参数!):
appsearch.url=https://dc3ff02216a54511ae43293497c31b20.ent-search.westeurope.azure.elastic-cloud.com
appsearch.engine=web-crawler-search-engine
appsearch.key=search-untdq4d62zdka9zq4mkre4vv
feign.client.config.appsearch.defaultRequestHeaders.Authorization=Bearer search-untdq4d62zdka9zq4mkre4vv如果您不想输入任何密码来登录 Kibana,可以通过 Elastic Cloud UI 登录 Kibana 实例,然后前往 Enterprise Search > App Search
您可以从 App Search 中的 Credentials 页面中提取 appsearch.key 和 feign... 搜索参数。同样的方法也适用于右上角显示的 Endpoint。
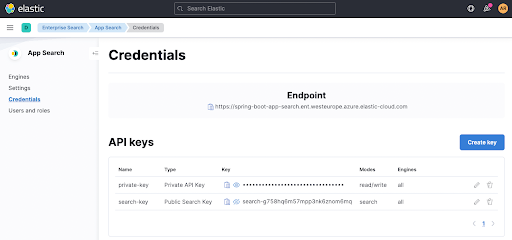
现在,当运行 ./gradlew clean check 时,会命中正确的 App Search 终端,
但测试仍会失败,因为我们仍然没有为任何数据编制索引。我们现在就来为数据编制一些索引吧!
配置网络爬虫
在设置网络爬虫之前,需要为文档创建一个容器。现在我们叫它 engine,我们来创建一个吧。将引擎命名为 web-crawler-search-engine,使其与 application.conf 文件相匹配。
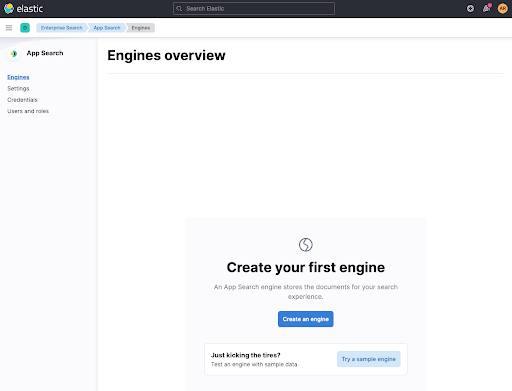
然后,点击 Use The Crawler 即可配置网络爬虫
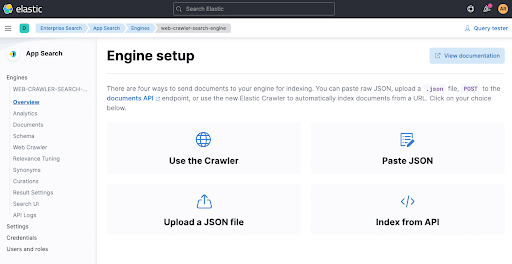
现在添加一个域。您可以在这里添加自己的域,我使用的是我的个人博客 spinscale.de,这样就不会踩到任何人的雷区。
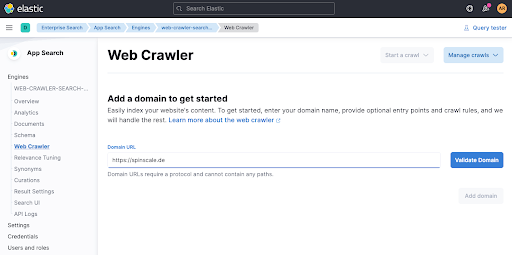
点击 Validate Domain 会执行几项检查,然后将域添加到引擎中。
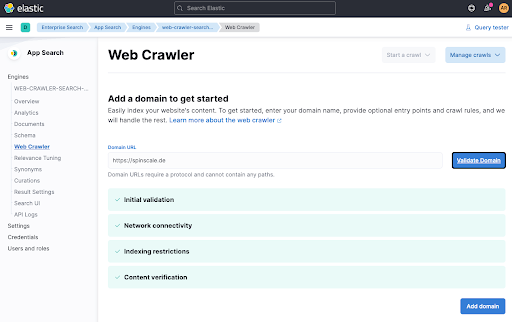
最后一步是手动触发爬取,以便立即对数据进行索引。点击 Start a crawl。
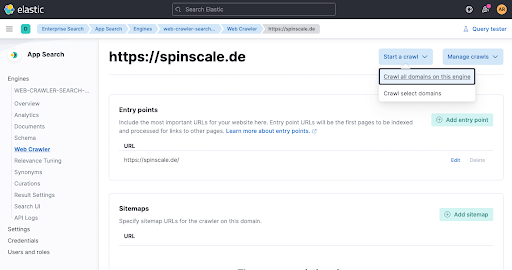
现在等待一分钟,然后查看引擎概览,确认是否已添加文档。
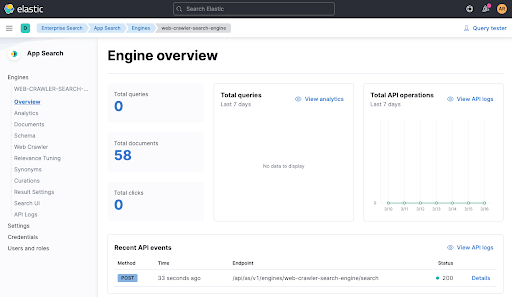
现在数据已经索引到引擎中,我们通过 ./gradlew check 重新运行一下测试,看看这次是否通过。它现在应该通过了,您还可以在引擎概览中看到最近来自测试的 API 调用(见上图底部)。
在启动应用之前,我们快速浏览一下测试代码
@SpringBootTest(classes = SpringBootAppSearchApplication.class, webEnvironment = SpringBootTest.WebEnvironment.NONE)
class AppSearchClientTests {
@Autowired
private AppSearchClient appSearchClient;
@Test
public void testFeignAppSearchClient() {
final QueryResponse queryResponse = appSearchClient.search(Query.of("seccomp"));
assertThat(queryResponse.getResults()).hasSize(4);
assertThat(queryResponse.getResults().stream().map(QueryResponse.Result::getTitle))
.contains("Using seccomp - Making your applications more secure",
"Presentations",
"Elasticsearch - Securing a search engine while maintaining usability",
"Posts"
);
assertThat(queryResponse.getResults().stream().map(QueryResponse.Result::getUrl))
.contains("https://spinscale.de/posts/2020-10-27-seccomp-making-applications-more-secure.html",
"https://spinscale.de/presentations.html",
"https://spinscale.de/posts/2020-04-07-elasticsearch-securing-a-search-engine-while-maintaining-usability.html",
"https://spinscale.de/posts/"
);
}
}这个测试会在不绑定端口的情况下启动 spring 应用程序,自动注入 AppSearchClient 类并运行一个搜索 seccomp 的测试。
启动应用程序
现在就启动并运行应用程序,并检查它们能否启动
./gradlew bootRun您应该会看到一些日志消息,最重要的是您的应用程序已经启动,具体如下:
2022-03-16 15:43:01.573 INFO 21247 --- [ restartedMain] d.s.s.SpringBootAppSearchApplication : Started SpringBootAppSearchApplication in 1.114 seconds (JVM running for 1.291)您现在可以在浏览器中打开应用并查看,但我想先看一下 Java 代码。
仅为我们的搜索客户端定义界面
为了能够在 Spring Boot 中查询 App Search 终端,我们只需要实现一个界面,因为它使用了 Feign。我们不必关心 JSON 序列化或创建 HTTP 连接,我们可以只处理 POJO。这是我们对 App Search 客户端的定义
@FeignClient(name = "appsearch", url="${appsearch.url}")
public interface AppSearchClient {
@GetMapping("/api/as/v1/engines/${appsearch.engine}/search")
QueryResponse search(@RequestBody Query query);
}客户端对 url 和 engine 使用 application.properties 定义,因此无需在 API 调用中指定任何内容。此外,这个客户端使用 application.properties 文件中定义的标头。这样,应用程序代码就不会包含 URL、引擎名称或定制 auth 标头。
唯一需要更多实现的类是用于对请求主体进行建模的 Query 和可对请求响应进行建模的 QueryResponse。尽管响应通常包含更多的 JSON 字段,但我选择只对其中绝对需要的字段进行建模。每当我需要更多数据时,我就可以将其添加到 QueryResponse 类中。
查询类目前仅包含 query 字段
public class Query {
private final String query;
public Query(String query) {
this.query = query;
}
public String getQuery() {
return query;
}
public static Query of(String query) {
return new Query(query);
}
}最后,让我们在应用程序中运行一些搜索。
服务器端查询和渲染
示例应用程序实现了三种查询 App Search 实例的模型,并将其集成到 Spring Boot 应用程序中。第一个将搜索词发送到 Spring Boot 应用,后者将查询发送到 App Search,然后通过 thymeleaf(Spring Boot 中的标准渲染依赖项)渲染结果。以下是控制器示例
@Controller
@RequestMapping(path = "/")
public class MainController {
private final AppSearchClient appSearchClient;
public MainController(AppSearchClient appSearchClient) {
this.appSearchClient = appSearchClient;
}
@GetMapping("/")
public String main(@RequestParam(value = "q", required = false) String q,
Model model) {
if (q != null && q.trim().isBlank() == false) {
model.addAttribute("q", q);
final QueryResponse response = appSearchClient.search(Query.of(q));
model.addAttribute("results", response.getResults());
}
return "main";
}
}在 main() 方法中,有一个 q 参数检查。如果 q 存在,会将查询发送到 App Search,并使用结果扩充 model。然后渲染 main.html thymeleaf 模板,如下所示:
<!DOCTYPE html>
<html xmlns:th="http://www.thymeleaf.org"
xmlns:layout="http://www.ultraq.net.nz/thymeleaf/layout"
layout:decorate="~{layouts/base}">
<body>
<div layout:fragment="content">
<div>
<form action="/" method="get">
<input autocomplete="off" placeholder="Enter search terms..."
type="text" name="q" th:value="${q}" style="width:20em" >
<input type="submit" value="Search" />
</form>
</div>
<div th:if="${results != null && !results.empty}">
<div th:each="result : ${results}">
<h4><a th:href="${result.url}" th:text="${result.title}"></a></h4>
<blockquote style="font-size: 0.7em" th:text="${result.description}"></blockquote>
<hr>
</div>
</div>
</div>
</body>
</html>这个模板将检查 results 变量,如果这个变量已设置好,会遍历该列表。每个结果渲染的模板都相同,如下所示:
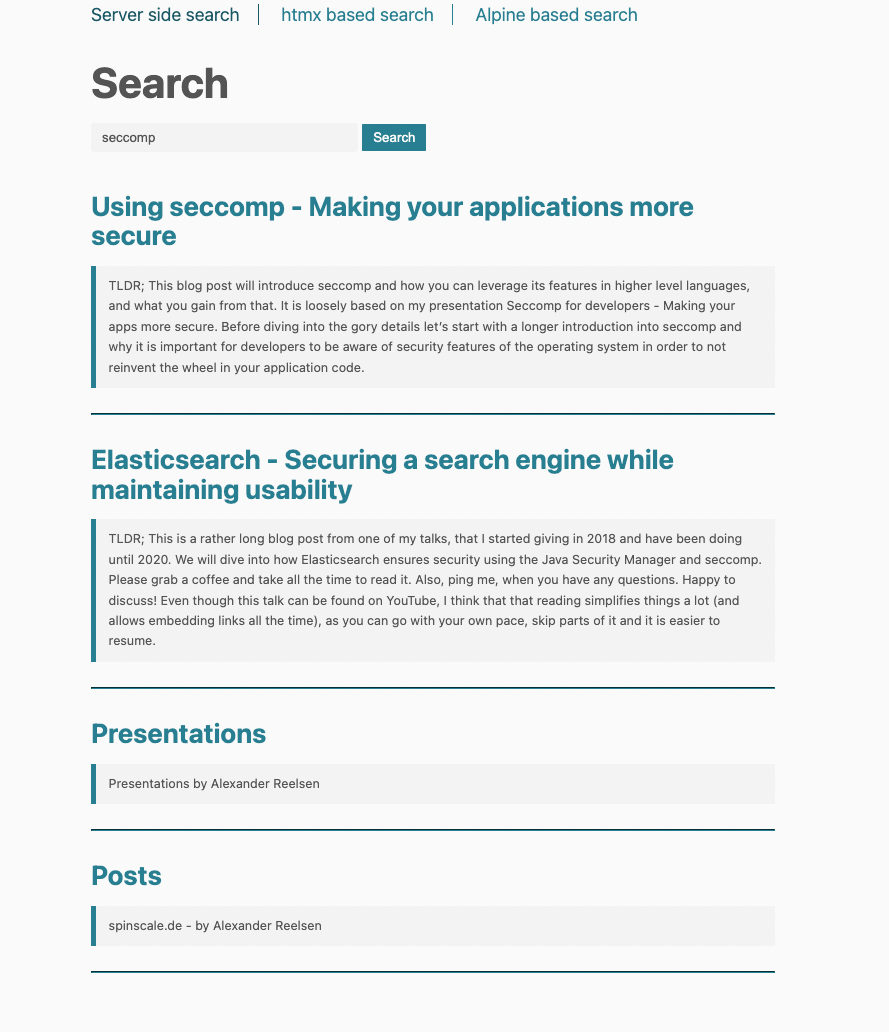
使用 htmx 进行动态页面更新
正如您在顶部导航栏中看到的,我们可以在三个选项之间更改搜索方式。当点击第二个名为基于 htmx 的搜索时,执行模型略有变化。
只有包含结果的部分会被替换为服务器返回的内容,而不是重新加载整个页面。这样做的好处是,无需编写任何 JavaScript 即可完成。这要归功于超强的 htmx 库。引用其中的一句描述:htmx 让您可以使用属性直接在 HTML 中访问 AJAX、CSS 过渡、WebSockets 和服务器发送事件,这样您就可以借助超文本的简洁特性和强大功能来构建现代风格的用户界面
在这个例子中,只使用了 htmx 的一小部分。我们先看一下这两个终端定义。一个用于渲染 HTML,另一个用于仅返回更新页面部分所需的 HTML 代码片段。
htmx 让您可以使用属性直接在 HTML 中访问 AJAX、CSS 过渡、WebSockets 和服务器发送事件,这样您就可以借助超文本的简洁特性和强大功能来构建现代风格的用户界面
第一个终端渲染 htmx-main 模板,第二个终端则渲染结果。htmx-main 模板如下所示:
<!DOCTYPE html>
<html xmlns:th="http://www.thymeleaf.org"
xmlns:layout="http://www.ultraq.net.nz/thymeleaf/layout"
layout:decorate="~{layouts/base}">
<body>
<div layout:fragment="content">
<div>
<form action="/search" method="get">
<input type="search"
autocomplete="off"
id="searchbox"
name="q" placeholder="Begin Typing To Search Articles..."
hx-post="/htmx-search"
hx-trigger="keyup changed delay:500ms, search"
hx-target="#search-results"
hx-indicator=".htmx-indicator"
style="width:20em">
<span class="htmx-indicator" style="padding-left: 1em;color:red">Searching... </span>
</form>
</div>
<div id="search-results">
</div>
</div>
</body>
</html>神奇之处在于 <input> HTML 元素的 hx- 属性。大声念出咒语,就会出现如下转化
- 如果 500 毫秒内没有键入活动,则仅触发 HTTP 请求
- 然后向 /htmx-search 发送 HTTP POST 请求
- 在等待过程中,显示 .htmx-indicator 元素。
- 响应应该渲染到 ID 为 #search-results 的元素中
只需考虑一下与键侦听器、等待响应或发送 AJAX 请求时显示元素有关的所有逻辑所需的 JavaScript 的数量。
另一个很大的优点是可以使用您喜欢的服务器端渲染解决方案来创建要返回的 HTML。这意味着,我们可以留在 thymeleaf 生态系统中,而不必实现一些客户端模板语言。这使得 htmx-search-results 模板非常简单,只需遍历结果即可:
<div th:each="result : ${results}">
<h4><a th:href="${result.url}" th:text="${result.title}"></a></h4>
<blockquote style="font-size: 0.7em" th:text="${result.description}"></blockquote>
<hr>
</div>与第一个示例的一个不同之处在于,此搜索的 URL 永远不会更改,因此您不能将其加入书签。尽管 htmx 中有历史记录支持,但为了这个示例,我没有使用,因为它需要一些更仔细的实现才能正确地执行。
通过浏览器对 App Search 进行搜索
现在来看最后一个示例。这个示例截然不同,因为它根本不涉及 Spring Boot 服务器端。一切都在浏览器中进行。这个示例使用 Alpine.js 完成。服务器端终端尽可能看起来简单:
@GetMapping("/alpine")
public String alpine() {
return "alpine-js";
}alpine-js.html 模板需要更多解释,但我们可以先看一下:
<!DOCTYPE html>
<html
xmlns:layout="http://www.ultraq.net.nz/thymeleaf/layout"
layout:decorate="~{layouts/base}">
<body>
<div layout:fragment="content" x-data="{ q: '', response: null }">
<div>
<form @submit.prevent="">
<input type="search" autocomplete="off" placeholder="Begin Typing To Search Articles..." style="width:20em"
x-model="q"
@keyup="client.search(q).then(resultList => response = resultList)">
</form>
</div>
<template x-if="response != null && response.info.meta != null && response.info.meta.request_id != null">
<template x-for="result in response.results">
<template x-if="result.data != null && result.data.title != null && result.data.url != null && result.data.meta_description != null ">
<div>
<h4><a class="track-click" :data-request-id="response.info.meta.request_id" :data-document-id="result.data.id.raw" :data-query="q" :href="result.data.url.raw" x-text="result.data.title.raw"></a></h4>
<blockquote style="font-size: 0.7em" x-text="result.data.meta_description.raw"></blockquote>
<hr>
</div>
</template>
</template>
</template>
<script th:inline="javascript">
var client = window.ElasticAppSearch.createClient({
searchKey: [[${@environment.getProperty('appsearch.key')}]],
endpointBase: [[${@environment.getProperty('appsearch.url')}]],
engineName: [[${@environment.getProperty('appsearch.engine')}]]
});
document.addEventListener("click", function(e) {
const el = e.target;
if (!el.classList.contains("track-click")) return;
client.click({
query: el.getAttribute("data-query"),
documentId: el.getAttribute("data-document-id"),
requestId: el.getAttribute("data-request-id")
});
});
</script>
</div>
</body>
</html>第一个主要区别是实际使用 JavaScript 来初始化 ElasticAppSearch 客户端,即使用 application.properties 文件中配置的属性。初始化该客户端后,我们可以在 HTML 属性中使用它。
以下代码会初始化两个要使用的变量
<div layout:fragment="content" x-data="{ q: '', response: null }">q 变量将包含输入表单的查询,而响应将包含来自搜索的响应。接下来,表单定义部分也很有趣
<form @submit.prevent="">
<input type="search" autocomplete="off" placeholder="Search Articles..."
x-model="q"
@keyup="client.search(q).then(resultList => response = resultList)">
</form>使用 <input x-model="q"...> 将 q 变量绑定到输入,并在用户键入时更新。`keyup` 也有一个使用 client.search() 执行搜索并将结果赋值给 response 变量的事件。因此,一旦客户端搜索返回结果,响应变量将不再为空。最后,使用 @submit.prevent="" 确保表单没有被提交。
接下来,
<div>
<h4><a class="track-click"
:data-request-id="response.info.meta.request_id"
:data-document-id="result.data.id.raw"
:data-query="q"
:href="result.data.url.raw"
x-text="result.data.title.raw">
</a></h4>
<blockquote style="font-size: 0.7em"
x-text="result.data.meta_description.raw"></blockquote>
<hr>
</div>上述渲染与两个服务器端渲染实现略有不同,因为它包含用于跟踪点击链接的附加功能。渲染模板的重要部分是 :href 和 x-text 属性。用于设置链接和链接的文本。其他 :data 参数用于跟踪链接。
跟踪点击情况
那么,为什么要跟踪链接点击情况呢?很简单,这是通过衡量用户是否点击搜索结果来判断这些结果是否有用的一种可行方法。这也解释了为什么这个 HTML 代码片段中包含了更多 JavaScript。我们先来看看 Kibana 中的点击情况跟踪。
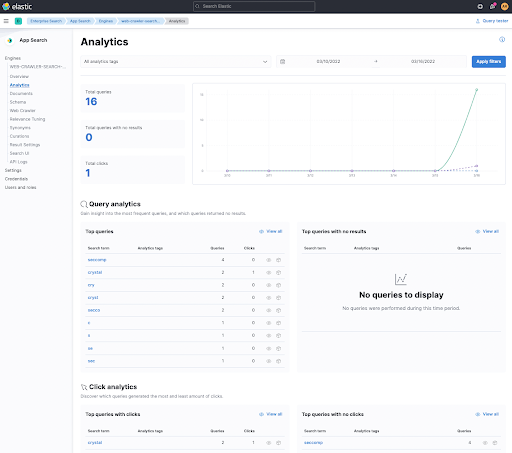
您可以在底部看到 Click analytics,用于跟踪我在点击的第一个链接中搜索 crystal 之后的点击情况。点击这个词后,您可以看到哪个文档被点击了,并且基本上可以跟踪用户的点击轨迹。
那么,在我们的小应用中如何实现这一功能呢?对某些链接使用 click JavaScript 侦听器就可以了。以下是 JavaScript 代码片段
document.addEventListener("click", function(e) {
const el = e.target;
if (!el.classList.contains("track-click")) return;
client.click({
query: el.getAttribute("data-query"),
documentId: el.getAttribute("data-document-id"),
requestId: el.getAttribute("data-request-id")
});
});如果点击的链接具有 track-click 类,则使用 ElasticAppSearch 客户端发送一个点击事件。此事件包含原始查询词以及 documentId 和 requestId,它们是搜索响应的一部分,在上面的模板中渲染为 元素。
我们还可以在用户点击链接时提供这类信息,将这一功能添加到服务器端渲染中,因此这根本不是浏览器所独有的。为了简单起见,我在这里跳过了实现环节。
总结
希望您喜欢从开发人员的角度了解 Elastic App Search,以及将其集成到应用程序中的各种可能性。请务必查看 GitHub 存储库并按照示例进行操作。
您可以将 Terraform 与 Elastic Cloud 提供程序结合使用,以便在 Elastic Cloud 中立即启动并运行。
分享
- Share on Twitter
在 Twitter 上分享
- Share on LinkedIn
在 LinkedIn 上分享
- Share on Facebook
在 Facebook 上分享
- Share by Email
通过邮件分享
- Print this page
打印